大数据_Flink_Java版_Table API 和 Flink SQL(1)_基本介绍和简单示例---Flink工作笔记0081

然后我们再来看table api 以及 flink sql

我们看,table api 和flink sql我们来看看是什么东西,首先
我们之前说过ProcessFunction,这个是处理一些底层的数据会用到这个,之前我们知道
processFunction,可以对事件时间,做更精细的处理.
然后中间的DataStream这个我们也说过了,可以读入数据流,然后进行map,flatMap等的处理对吧
然后我们现在看再上一层的API,可以看到这里有个High-level Analytics API 这个SQL/Table API
可以看到这个是,上层的API,他把我们之前写的代码实现的功能,做了进一步的封装,提供给我们用
这样用起来会方便很多.
比如Table api用的时候,直接.select这样类似于就可以了.
至于flink sql,就相当于写个字符串的sql,执行就可以了.

然后我们自己去写个例子去,用一下table api,首先在
com.atguigu.apitest.tableapi下创建Example类
写一个main方法

然后去看一下这里,首先创建执行环境,然后,设置并行度是1,然后
我们首先去文件中读取文本流

然后我们再去,把输入流转换成.map,SensorReading流对吧
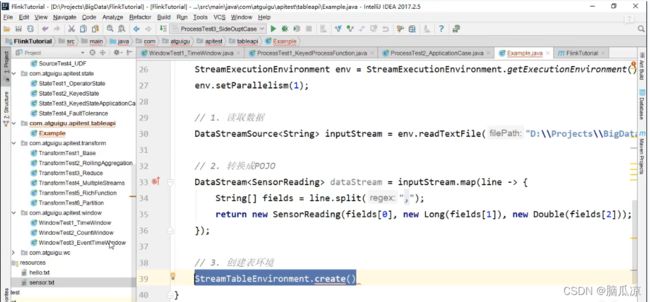
然后我们再去创建一个Table api的执行环境
可以看到这里,使用的是StreamTableEnvironment对吧.

这里我们需要引入上面两个依赖,可以看到一个是
flink-table-planner_2.12
然后version是1.10.1 这里2.12 是scala的版本,然后
1.10.1 是flink的版本

然后可以看到还有一个桥接器,这里
flink-table-api-java-bridge_2.12
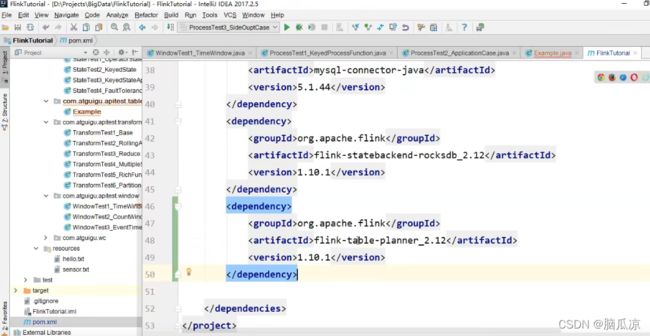
首先我们去引入计划器:
flink-table-planner_2.12 然后version是1.10.1

然后我们去看一下引入的依赖,可以看到,这个
org.apache.flink这里
flink-table-planner 这个计划器可以看到里面包含了
table-api-java-bridge了对吧,包含桥接器了,然后同时,可以看到除了包含java的桥接器
还包含了scala的桥接器对吧.
这个计划器就可以为我们生成执行计划,然后执行了.

然后我们再看这里
flink-table-planner-blink_2.12 这个blink的版本会比较新,上面我们引入的那个
flink-table-planner_2.12这个是旧版本的,现在我们引入了两个以后

我们来看我们引入以后,可以看到下面又多了一个org.apache.Flink...blink的一个包对吧.
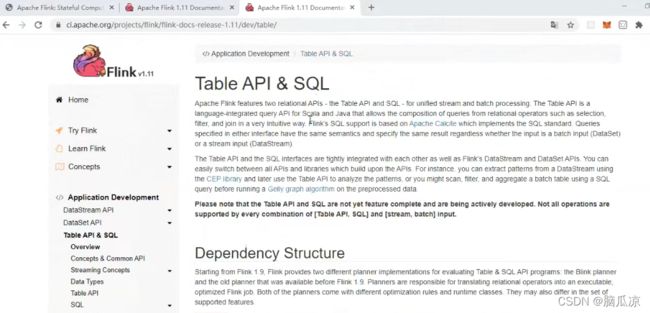
我可以去官网去看这里说,现在虽然我们引入了两个planner-table,但是他会用哪个呢?
注意这里,他会用不带blink的这个旧的,可以看到上面1.11这个版本的可以看到官网也说了

如果你是用的1.10以及以前的,他会默认用1.10的版本的,不带blink的,如果是1.11开始的版本
他就会使用blink版本的了.
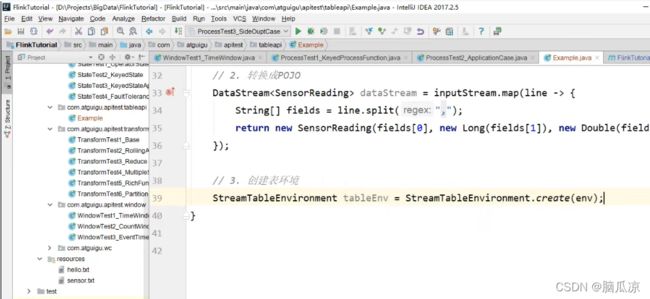
可以看到,上面第一个值是fields[0]是id,然后第二个是时间戳,第三个是温度值.
然后我们先去创建一个StreamTableEnvironment 这个Table的运行环境.
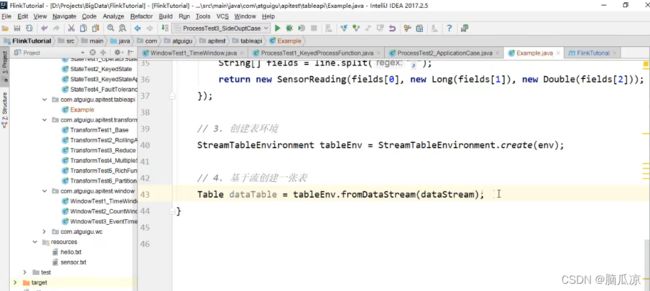
创建了以后,然后我们再去,tableEnv.fromDataStream(dataStream)
这里是基于流,来创建一张表对吧.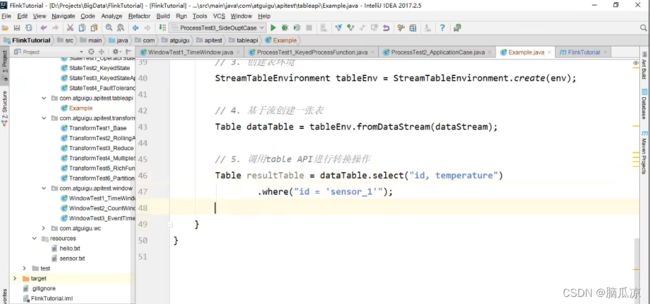
然后我们直接通过创建的这张表,调用.select,从里面,获取id,temperature这两个值,然后
我们还可以添加条件,可以看到.where("id = sensor_1") 我们只取第一个传感器的值.
上面这里,就是用table api来进行数据的查询了,可以看到简单多了.

然后我们再看,这里我们怎么用执行SQL来查询
这个时候,首先我们需要注册,我们的table,可以看到通过,tableEnv.createTemporaryView("sensor",dataTable);
这里,创建以后,然后,我们就可以去写一个sql,可以看到跟以前写sql一样对吧.
然后我们再去执行sqltableEnv.sqlQuery(sql),这里执行以后,返回:
resultSqlTable 这个表.

返回以后,我们可以跟以前直接stream.print那样打印结果吗?
不可以,可以看到这里表,只能直接printSchema()打印结构对吧.

然后,我们再去看这里,我们可以把表,转换成流,然后把流再进行打印输出对吧.

然后我们去执行看看结果,没问题对吧.