Unified Named Entity Recognition as Word-Word Relation Classification

Abstract
最近,人们对统一NER产生了越来越大的兴趣,用一个单一的模式同时处理flat、nested、不连续三项工作。目前性能最好的方法主要包括基于SPAN的模型和序列到序列模型,但遗憾的是,前者只关注边界识别,而后者可能会受到曝光偏差的影响。
本文提出了一种新的替代方案,通过将统一的NER建模为word-word关系分类,即 W 2 N E R W^2NER W2NER。
- 该体系结构通过有效地对实体词之间的邻接关系(NNW)和Tail-Head-Word-*(THW-*)关系进行建模,解决了统一NER的核心瓶颈问题。
- 在 W 2 N E R W^2NER W2NER方案的基础上,本文开发了一个神经网络框架,其中统一的NER被建模为由word-pairs组成的2D网格。
- 然后,本文提出了多粒度2D卷积,以更好地细化网格表示。
- 最后,使用联合预测因子对词与词之间的关系进行充分推理。
在14个广泛使用的基准数据集(8个英文和6个中文)上对flat、重叠和不连续的NER进行了广泛的实验,本文的模型击败了目前所有表现最好的基线,推动了统一NER的最先进性能。
Introduction

如图1所示:可以毫不费力的找到flat mention :【aching in legs】,因为它的构成词都是自然相邻的,如果要检测不连续实体:【aching in shoulders】,有效的捕捉【aching in】和【shoulders】这两个相邻片段之间的语义关系是必不可少的。
本文提出了一种新的word-word关系分类体系的统一NER形式化方法 W 2 N E R W^2NER W2NER(通过有效地对实体边界识别和实体词之间的邻接关系进行建模)。具体来说预测两种类型的关系:1)下一个相邻单词Next-Neighboring-Word(NNW)和尾部单词-* Tail-Head-Word-*(THW-*)
NNW 关系处理实体词识别,指示两个论元词在是实体中是否相邻(eg:aching ——>in)
THW-* 考虑实体边界和类型检测,揭示了两个论元词是否分别是*实体的尾部和首部(eg:legs——>aching, Symptom)。
Model
给定由N个tokens或words组成的句子 X = { x 1 , x 2 , . . . , x N } X =\{x_1, x_2, ..., x_N\} X={x1,x2,...,xN},目的:提取每个tokens pairs ( x i , x j ) (x_i, x_j) (xi,xj)之间的关系R,R是预定义的。
该关系包括:
- None:该词对与本文中定义的没有任何关系
- Next-Neighboring-Word:该Word pair 属于所提及的实体,且该网格中某行的词在该网格的某一列中有连续的词。
- Tail-Head-Word-*:网格中某行的单词为提及实体的尾部,网格某列中的单词为提及实体的头部。“*”表示实体类型。

通过NNW关系预测(aching——>in),(in——>legs),(in——>shoulders) 通过THW关系预测(legs——>aching, Symptom),(shoulers——>aching, Symptom)可以解码出两个实体。
该模型由3个部件组成:BERT和BiLSTM用于编码器,从输入句子中产生上下文词表示;卷积层来构建和提炼word pair网格的表示,用于后续的word-word关系分类;co-predictor layer(包括双仿射分类器和多层感知机),联合推理所有word-pairs之间的关系。
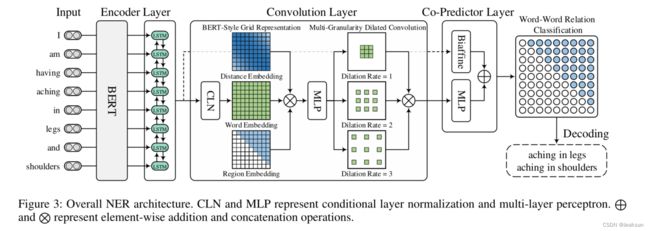
Encoder Layer
使用BERT+LSTM进行编码,生成最终的词表示: H = { h 1 , h 2 , . . . , h N } ∈ R N × d h H = \{h_1,h_2,...,h_N\}\in R^{N\times d_h} H={h1,h2,...,hN}∈RN×dh, d h d_h dh表示词表示的维度。
Convolution Layer
采用CNN作为精化器,包括三个模块:条件归一化层、用于丰富word pair网格的表示的BERT风格的网格表示构建、以及用于捕获近距离单词之间的交互的多粒度膨胀卷积。
Conditional Layer Normalization
由于本文框架的目标是预测word pair之间的关系,因此重要的是生成word pair网格的高质量表示,它可以视为一个三维矩阵 B ∈ R N × N × d h B \in R^{N\times N\times d_h} B∈RN×N×dh,其中 V i , j V_{i,j} Vi,j表示word pair ( x i , x j ) (x_i,x_j) (xi,xj)的表示。由于NNW和THW关系都是方向性的,如图2所示,从特定行中的单词 x i x_i xi到特定列中的单词 x j x_j xj,(eg:aching——>in 和legs——>aching)。
采用条件层归一化机制计算 V i , j V_{i,j} Vi,j: V i j = C L N ( h i , h j ) = γ i j ⊙ ( h j − μ σ ) + λ i , j V_{ij}=CLN(h_i,h_j)=\gamma _{ij}\odot (\frac{h_j-\mu}{\sigma})+ \lambda_{i,j} Vij=CLN(hi,hj)=γij⊙(σhj−μ)+λi,j。
BERT-Style Grid Representation Build-Up BERT样式的网格表示构建
在BERT的启发下,本文利用类似的死死昂丰富了word pair网格的表示:
- V ∈ R N × N × d h V\in R^{N\times N\times d_h} V∈RN×N×dh表示单词信息
- V ∈ R N × N × d h V\in R^{N\times N \times d_h} V∈RN×N×dh表示每对单词之间的相对位置信息
- E t ∈ R N × N × d E t E^t \in R^{N\times N \times d_{E_t}} Et∈RN×N×dEt表示网格中区分下三角局域和上三角局域的区域信息
本文将三种嵌入方式连接起来,采用MLP对齐降维,得到网格 C ∈ R N × × N × d c C\in R^{N\times \times N\times d_c} C∈RN××N×dc的位置区域感知表示: C = MLP 1 ( [ V ; E d ; E t ] ) C=\text{MLP}_1([V;E^d;E^t]) C=MLP1([V;Ed;Et])
Multi-Granularity Dilated Convoluion多粒度膨胀卷积
采用不同扩张率的多个二维膨胀卷积卷积来捕获不同距离的词之间的相互作用。膨胀卷积中的计算: Q l = σ ( D C o n v l ( C ) ) Q^l=\sigma(DConv_l(C)) Ql=σ(DConvl(C)),其中 Q l ∈ R N × N × d c Q^l\in R^{N\times N \times d_c} Ql∈RN×N×dc表示具有具有扩张速率 l l l的扩张卷积的输出。得到最终的词对网格表示: Q = [ Q 1 , Q 2 , Q 3 ] ∈ R N × N × 3 d c Q = [Q^1,Q^2,Q^3]\in R^{N\times N \times 3d_c} Q=[Q1,Q2,Q3]∈RN×N×3dc。
Co-predictor Layer
Biaffine Predictor
双仿射预测器的输入是编码器的输出 H = { h 1 , h 2 , . . . , h N } ∈ R N × d h H=\{h_1,h_2,...,h_N\}\in R^{N\times d_h} H={h1,h2,...,hN}∈RN×dh,给定单词表示 H H H,本文使用两个MLP分别计算主语 x i x_i xi和宾语 x j x_j xj的单词表示 s i s_i si和 o j o_j oj。然后,使用双仿射分类器来计算一对subject and object word ( x i , x j ) (x_i,x_j) (xi,xj)之间的关系分数:
s i = MLP 2 ( h i ) s_i=\text{MLP}_2(h_i) si=MLP2(hi)
o j = MLP 3 ( h j ) o_j=\text{MLP}_3(h_j) oj=MLP3(hj)
y i j ′ = s i T U o j + W [ s i ; o j ] + b y_{ij}^{'}=s_i^TUo_j+W[s_i;o_j]+b yij′=siTUoj+W[si;oj]+b
MLP Predictor
基于word-pair网格表示Q,采用MLP来计算使用 Q i j Q_{ij} Qij的word pair ( x i , x j ) (x_i,x_j) (xi,xj)的关系分数: y i j ′ ′ = MLP ( Q i j ) y_{ij}^{''}=\text{MLP}(Q_{ij}) yij′′=MLP(Qij)
其中 y i j ′ ′ ∈ R ∣ R ∣ y_{ij}^{''}\in R^{|R|} yij′′∈R∣R∣是在R中预定义的关系分数。word pair ( x i , x j ) (x_i, x_j) (xi,xj)的最终关系概率 y i , j y_{i,j} yi,j通过组合来自双仿射和MLP预测器的分数来计算:
y i j = Softmax ( y i j ′ + y i j ′ ′ ) y_{ij}=\text{Softmax}(y_{ij}^{'}+y_{ij}^{''}) yij=Softmax(yij′+yij′′)
Experimental Result
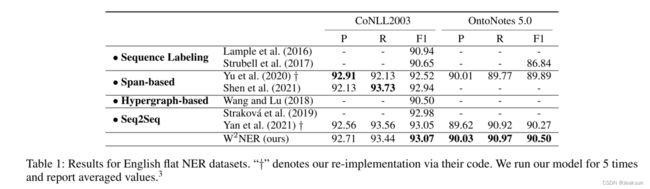
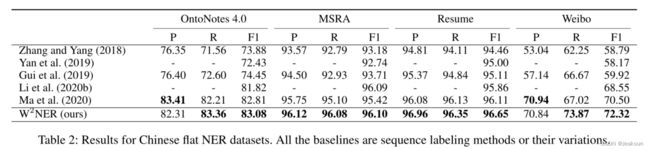
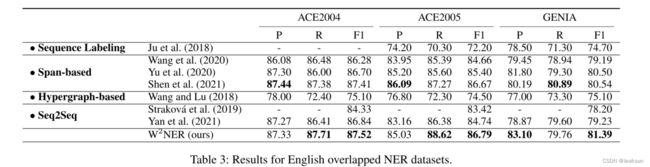
不连续实体数据集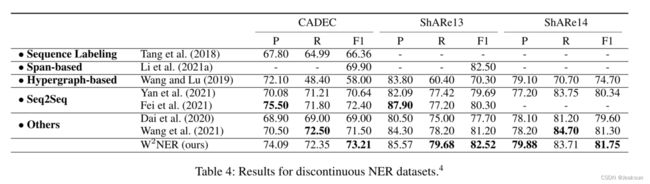
消融试验
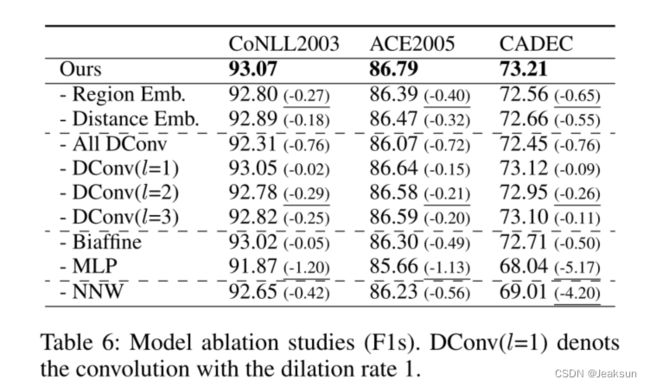
启示
- 网格表示法占用 N 2 N^2 N2的空间,如果算力资源不足还是放弃吧,这个着实不适合我
- 通过层归一化之后由经过了三个矩阵,总感觉是为了凑创新点,直接消融试验的结果来看,起到的作用还很大,可以尝试引入BERT-Style Grid Representation Build-Up作为创新点