Python回归预测汇总-线性回归(实例:美国波士顿地区房价预测)
目录
- 什么是线性回归
- 模型介绍
- 美国波士顿地区房价预测
-
- 数据
- 数据分割
- 标准化处理
- 预测
- 性能检测
- 总结
什么是线性回归
在统计学中,线性回归是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。一个带有一个自变量的线性回归方程代表一条直线。我们需要对线性回归结果进行统计分析。
只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。
模型介绍
在线性回归问题中,由于预测目标直接是实数域上的数值,因此优化目标更为简单,及最小化预测结果和真实值之间的差异。
当使用一组m个用于训练的特征向量 X = < x 1 , x 2 , . . . , x m > X=
和其对应的回归目标 y = < y 1 , y 2 , . . . , y m > y=
a r g m i n ( w , b ) L ( w , b ) = a r g m i n ( w , b ) ∑ m k = 1 ( f ( w , x , b ) − y k ) 2 argmin_(w,b)L(w,b)=argmin_(w,b)\sum_{m}^{k=1}(f(w,x,b)-y^k)^2 argmin(w,b)L(w,b)=argmin(w,b)∑mk=1(f(w,x,b)−yk)2
当m=1时,该模型为简单线性回归,当m>1时,该模型为多元回归模型。现为了学习到决定模型的参数,即系数w和截距b,仍然可以使用一种精确计算的解析算法和快速的随机梯度下降估计算法。
美国波士顿地区房价预测
以下,我只介绍多元回归的实例(简单回归只需要把数据更改为二维得即可),我们利用美国波士顿地区的房价数据进行练习:
数据
#线性回归
#直接从sklearn.datasets导入波士顿房价数据读取器
from sklearn.datasets import load_boston
#数据存储在变量boston中
boston=load_boston()
#输出数据描述
print(boston.DESCR)

该数据一共有506条,每条数据包括对房屋的13项数值型特征描述和目标房价,且该数据中未含有缺失值。
数据分割
from sklearn.model_selection import train_test_split
import numpy as np
x=boston.data
y=boston.target
#随机采样,将25%的数据作为测试样本
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=33,test_size=0.25)
#分析回归目标值的差异
print("最大值为:\n",max(boston.target))
print("最小值为:\n",min(boston.target))
print("平均值为:\n",np.mean(boston.target))
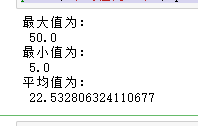
可以看出,预测房价之间的差异较大,需要对特征以及目标值进行标准化处理。
标准化处理
from sklearn.preprocessing import StandardScaler
ss_x=StandardScaler()
ss_y=StandardScaler()
#分别对训练和测试数据的特征以及目标值进行标准化处理
x_train=ss_x.fit_transform(x_train)
x_test=ss_x.transform(x_train)
y_train=ss_y.fit_transform(y_train.reshape(-1,1))
y_test=ss_y.transform(y_test.reshape(-1,1))
预测
下面,我们分别使用线性回归模型LinerRegression和SGDRegression进行预测。
from sklearn.linear_model import LinearRegression
lr=LinearRegression()
#使用哪个训练数据进行参数估计
lr.fit(x_train,y_train)
#测试数据回归预测
lr_y_pred=lr.predict(x_test)
from sklearn.linear_model import SGDRegressor
sgdr=SGDRegressor()
sgdr.fit(x_train,y_train)
sgdr_y_pred=sgdr.predict(x_test)
性能检测
最为直观的评价指标包括,平均绝对误差(MAE)以及均方误差(MSE),因为这也是模型需要优化的目标。
下面使用三种回归评价机制以及两种R-squared评价模块的方法对模型进行评价。
#LinearRegression模型自带评估模块
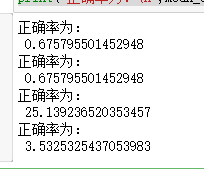
print("正确率为:\n",lr.score(x_test,y_test.reshape(-1,1)))
#
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
#使用r2_score模块评估
print("正确率为:\n",r2_score(y_test,lr_y_pred))
#用mean_squared_error模块评估
print("正确率为:\n",mean_squared_error(ss_y.inverse_transform(y_test.reshape(-1,1)),ss_y.inverse_transform(lr_y_pred)))
#用mean_absolute_error模块评估
print("正确率为:\n",mean_absolute_error(ss_y.inverse_transform(y_test.reshape(-1,1)),ss_y.inverse_transform(lr_y_pred)))
#模型自带评估模块
print("正确率为:\n",sgdr.score(x_test,y_test.reshape(-1,1)))
#
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
#使用r2_score模块评估
print("正确率为:\n",r2_score(y_test,sgdr_y_pred))
#用mean_squared_error模块评估
print("正确率为:\n",mean_squared_error(ss_y.inverse_transform(y_test.reshape(-1,1)),ss_y.inverse_transform(sgdr_y_pred)))
#用mean_absolute_error模块评估
print("正确率为:\n",mean_absolute_error(ss_y.inverse_transform(y_test.reshape(-1,1)),ss_y.inverse_transform(sgdr_y_pred)))

我们可以看出随机梯度下降方法在性能上不及使用解析方法的LinearRegression。但是根据官网建议,当数据规模十分庞大时,随机梯度下降法不论是分类还是回归问题上都表现得十分高效,在不损失过多性能的情况下,节省大量计算时间。
总结
线性回归器是最为简单、易用的回归模型。正是因为其对特征与回归目标之间的线性假设,从某种程度上说也局限了其应用范围。特别是,现实生活中的许多实例数据的各个特征与回归目标之间,绝大多数不能保证严格的线性关系。尽管如此,在不清楚特征之间关系的前提下,我们仍然可以使用线性回归模型作为大多数科学试验的基线系统( Baseline system)。