zookeeper分布式协调
zookeeper分布式协调
安装笔记
准备 node01~node04
1、所有虚拟机安装jdk,并设置javahome
3、下载zookeeper zookeeper.apache.org
3、tar xf zookeeper.*.tar.gz
4、mkdir /opt/mashibing
5、mv zookeeper /opt/mashibing
6、vi /etc/profile
export ZOOKEEPER_HOME=/mashibing/apache-zookeeper-3.7.0-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
7、cd zookeeper/conf
8、cp zoo.sem*.cfg zoo.cfg
9、vi zoo.cfg
dataDir=配置持久化目录,尽量不要使用默认配置
//有几台写几台
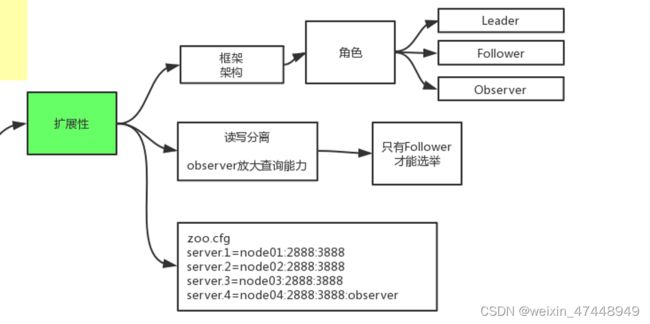
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
server.4=node4:2888:3888
node1去vim /etc/hosts 中设置映射关系,格式为198.168.134.25:node1
如果想设置那台机器角色为observer,只需在后面加上:observer即可
10、mkdir -p /var/mashibing/zk
11、echo 1> /var/mashibing/zk/myid
12、cd /opt && scp -r ./mashibing/ node02:`pwd`
13、node02~node04 创建myid,在dataDir的设置目录下创建
14、启动顺序 1,2,3,4
15、zkServer.sh start-foreground
集群模式
zookeeper表面上看上去是一种主从集群,主为leader,从为follower

增删改,只能发生在leader身上,查询可以发生在所有节点
zookeeper有两种运行状态
1、可以状态
2、不可用状态
3、不可用状态恢复到可用状态应该越快越好

分层命名
与节点的相似
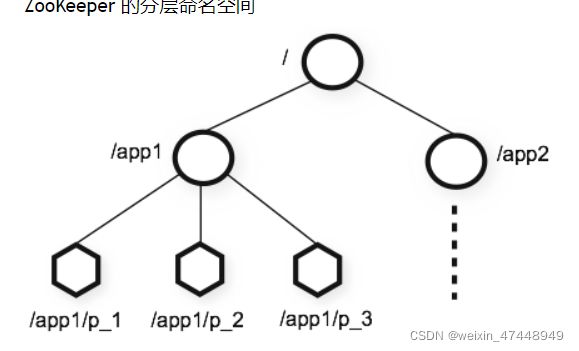
节点和临时节点
类似于文件夹,但是与文件夹的不同,实际为节点的,节点既可以放下一个节点,又可以存放数据,只能存放少量数据,大概为1M
节点划分
持久节点
临时节点:create-e
client通过代码可以实现分布式锁,场景:一个线程拿到了临时节点,其他线程获取该线程的信息就可以,不需要想redis一样需要设置过期时间和通过第二个线程刷新过期时间
序列节点:create-s
如果锁依托与父节点,且具备-s,代表父节点下可以有多把锁,并且如果后面的锁根据前面的锁才能运行,可以是事务所或者队列锁
zookeeper理论上可以当数据库用,但是不要把zookeeper当数据库
特征/保障
顺序一致性:客户端的更新将按发送顺序应用,因为leader只有一个,会一次请求leader
原子性:更新要么成功或要么失败,没有部分结果
统一视图:无论服务器连接到那个服务器,客户端都将看到相同的服务视图
可靠性:一单应用了更新,它将从那时起持续到客户端覆盖更新
及时性:系统的客户视图保证在特定时间范围内是最新的
命令:
ls:查看所有节点
get children:检索所有子节点
create:创建节点,可以在节点后面跟上数据值
-e:创建一个临时节点,一个客户端创建的时候会创建一个sessionid,而这个临时节点归属于连接的session,且session是会消耗事务id的(因为其他zookeeper也需要看到session的临时节点,所以其他zookeeper在该zookeepersession创建的时候,消耗一个事务id来创建该session的id),当该session消失,那么这个临时节点就会过期
-s:创建一个序列节点,防止同时操作一个节点的值导致覆盖,会在后面添加序列值,该序列值为递增
get:获取节点中的值
set:设置节点中的值
czxid:0X200000002的表示顺序值,16进制,后面表示你是第几个leader
ctime:创建时间
mzxid:修改的id
mtime:修改时间
pzid:当前节点下创建最后那个节点的czxid
ptime:当前节点下创建的下个节点
exists:监测该节点是否变化,产生新的事务
quit:退出命令行模式
sync:等待数据传播
stat:查看当前目录状态
| 状态属性 | 说明 |
|---|---|
| cZxid | 数据节点创建时的事务ID |
| ctime | 数据节点创建时的时间 |
| mZxid | 数据节点最后一次更新时的事务ID |
| mtime | 数据节点最后一次更新时的时间 |
| pZxid | 数据节点的子节点列表最后一次被修改(是子节点列表变更,而不是子节点内容变更)时的事务ID |
| cversion | 子节点的版本号 |
| dataVersion | 数据节点的版本号 |
| aclVersion | 数据节点的ACL版本号 |
| ephemeralOwner | 如果节点是临时节点,则表示创建该节点的会话的SessionID;如果节点是持久节点,则该属性值为0 |
| dataLength | 数据内容的长度 |
| numChildren | 数据节点当前的子节点个数 |
zookeeper的原理
zk的数据状态不在内存,用磁盘来保存日志
扩展性
observer仅仅是为了放大查询能力设计的,并不参与选举
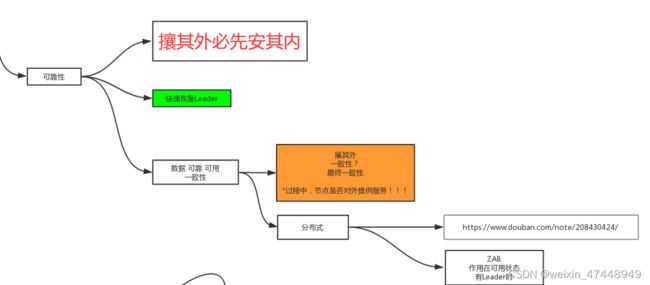
可靠性
可靠性可以快速恢复leader,当一个leader挂掉,并没有新的leader确定的时候,并不能对外提供服务,防止错误的数据提供给client,并且其中的底层中用到了paxos算法,和zab广播算法。
paxos算法
分布式必用到的算法。保证的是在分布式情况下数据的正确与可靠。
https://blog.csdn.net/cnh294141800/article/details/53768464?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164568287516780366582083%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=164568287516780366582083&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-2-53768464.first_rank_v2_pc_rank_v29&utm_term=paxos&spm=1018.2226.3001.4187
paxos算法是通过事务id与投票机制来确定
ZAB广播
通过广播和分阶段两次提交的形式,来保证过半的人是最新数据,来达到效率更高的效果

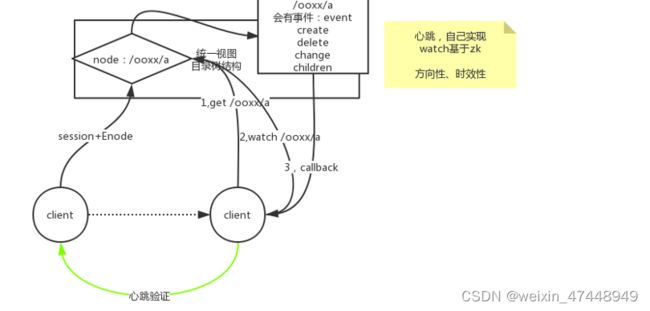
Watch手表监控观察
两个client可以通过心跳的方式来确保对方是否还在连接,但是会比较多慢
更快的方法就是通过监控对方的临时节点来确定对方是否正常连接
Zookeeper的分布式锁
什么情况下使用锁
多个线程多同意资源的访问,要保证在该资源下,同步执行(只能执行一个)
zookeeper分布式锁的各种情况
1、多个线程争抢锁,只有一个人能获取锁
2、获得锁的人出现问题保证不死锁,需要设置基于session的临时节点,这样当获取锁的人挂掉了,锁会随着session的消失而消失
3、获取锁的人没有出现问题,释放锁
4、锁被释放,删除,别人怎么知道的?
4.1、主动轮询,心跳,每一秒进行一次获取锁的操作
弊端:a、锁可能有延迟 b、假设一千个每一秒进行一次轮询,会对zookeeper造成压力
4.2、watch:解决延迟问题
弊端:当过期还是会有多个同时争抢锁,还会造成压力
4.2、sequen(序列节点)+watch:watch自己的前一个序列节点,最小的序列节点获取锁,当它释放锁,只有他的下一个会watch到,同时获取锁
优势:zk只给他的下一个线程产生回调
5、重入锁