torch的一些函数
1.https://zhuanlan.zhihu.com/p/288541909
2. .detach()
y=tensor.detach()
创建一个常量,名字是y, 注意它没有梯度
3. .normal()
torch.normal(means,std,out=None)
效果:返回一个张量,包含从给定参数means,std的离散正态分布中抽取随机数。 均值means是一个张量,包含每个输出元素相关的正态分布的均值。 std是一个张量,包含每个输出元素相关的正态分布的标准差。 均值和标准差的形状不须匹配,但每个张量的元素个数须相同 。。out,这里实际上是指输出的形状
3. required_grad
源自: https://blog.csdn.net/sazass/article/details/116668755

4. .matmul()
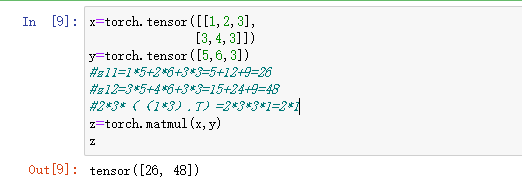
`如果都是 2D,就是普通的矩阵乘法

`如果 a是1D,b是2D,则还是普通的矩阵乘法

·如果 a是2D,b是1D,(如果a,b的行数相同)将b转置后再进行普通的乘法
5.with torch.no_grad():
在使用pytorch时,并不是所有的操作都需要进行计算图的生成(计算过程的构建,以便梯度反向传播等操作)。而对于tensor的计算操作,默认是要进行计算图的构建的,在这种情况下,可以使用 with torch.no_grad():,强制之后的内容不进行计算图构建。
也可以用来避免‘nonetye’的出现,这一般是对0求梯度而导致的
6. .to(device)
这两行代码放在读取数据之前。
mytensor = my_tensor.to(device)
这行代码的意思是将所有最开始读取数据时的tensor变量copy一份到device所指定的GPU上去,之后的运算都在GPU上进行
典例
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#整个模型的计算将由gpu负责
model.to(device)
下面是查看gpu的一些信息用的
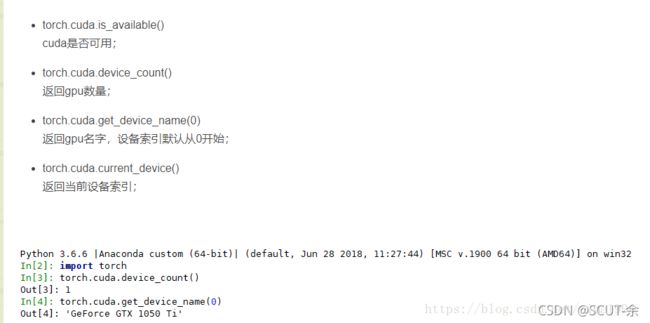
https://blog.csdn.net/nima1994/article/details/83001910
7. nn.ReLU()与F.ReLU()
nn.ReLu只能在网络的容器中使用,比如nn.Sequential()里面
而 F.ReLu()可以在任意地方使用,比如forward函数里面

8. torch.cat()
torch.cat((a,b,c,d),dim=num)
表示将a,b,c,d在第num个维度上拼接起来
# 通道数*深度*长*宽,dim=1表示在深度上拼接
torch.cat((p1,p2,p3,p4),dim=1)
reference:
https://blog.csdn.net/sazass/article/details/116668755
https://blog.csdn.net/shaopeng568/article/details/95205345
https://blog.csdn.net/nima1994/article/details/83001910