elasticsearch集群搭建与理论ES(ElasticSerach)
一、历史背景(秃子都厉害么?)

ES的起源,Shay Banon说当年他还是一个待业工程师,跟随自己的新婚妻子来到伦敦,妻子想在伦敦学习做一名厨师,而自己则想为妻子开发一个方便搜索菜谱的应用,所以才接触到 Lucene。直接使用 Lucene 构建搜索有很多问题,包含大量重复性的工作,所以 Shay Banon 便在 Lucene 的基础上不断地进行抽象,让 Java 程序嵌入搜索变得更容易,经过一段时间的打磨便诞生了他的第一个开源作品“Compass”,中文即“指南针”的意思。之后,他找到了一份面对高性能分布式开发环境的新工作,在工作中他渐渐发现越来越需要一个易用的、高性能、实时、分布式搜索服务,于是决定重写 Compass,将它从一个库打造成了一个独立的 server,并创建了Elasticsearch。
Shay Banon 在 2004 年创造了 Elasticsearch的前身,称为 Compass。在考虑 Compass 的第三个版本时,他意识到有必要重写 Compass 的大部分内容,以 “创建一个可扩展的搜索解决方案”。因此,他创建了 “一个从头构建的分布式解决方案”,并使用了一个公共接口,即 HTTP 上的 JSON,它也适用于 Java 以外的编程语言。Shay Banon 在 2010 年 2 月发布了 Elasticsearch 的第一个版本。
Elasticsearch BV 成立于 2012 年,主要围绕 Elasticsearch 及相关软件提供商业服务和产品。2014 年 6 月,在成立公司 18 个月后,该公司宣布通过 C 轮融资筹集 7000 万美元。这轮融资由新企业协会(NEA)牵头。其他投资者包括 Benchmark Capital 和 Index Ventures。这一轮融资总计 1.04 亿美元。
2015 年 3 月,Elasticsearch 公司更名为 Elastic。
在 2018 年 6 月,Elastic 提交了首次公开募股申请,估值在 15 亿到 30 亿美元之间。公司于 2018 年 10 月 5 日在纽约证券交易所挂牌上市。一些组织将 Elasticsearch 作为托管服务提供。这些托管服务提供托管、部署、备份和其他支持。大多数托管服务还包括对 Kibana 的支持。
Elasticsearch 自从诞生以来,其的应用越来越广泛,特别是大数据领域,功能也越来越强大,但是如何有效的监控管理 Elasticsearch 一直是公司所面对的难题,由于 Elasticsearch 集群的稳定性,决定了其业务发展的高度,对于一个应用来说其稳定是第一目标,所以完善的监控体系是必不可少的。此外,Elasticsearch 写入和查询对资源的消耗都很大,如何合理有效地控制资源,既能满足写入和查询的需求,又能满足资源充分利用,这是公司必须面对的问题。
在国内,还没较为完善的面向 Elasticsearch 的监控管理平台,很多企业往往只关注搭建一套简单分布式的集群环境,而对这个集群的缺乏监控和管理,元数据混乱,写入和查询耦合,缺乏监控一旦集群出现问题,就会导致数据丢失,甚至很容易导致线上应用故障。相比于小公司,中大型公司的资金较为充足,所以中大型公司,会选择为每个应用去维护一套集群,但是这每当资源不够需要扩容或者缩容时,极其不方便,需要增加删除节点,其运维成本过高。
而且对每个应用来说,可能不能够充分利用资源,但是如果和其他应用混合部署,但是又涉及到复杂的资源分配问题,而且随着应用的发展,资源经常需要变动。在国外,ELasticsearch 的应用也很广泛,也有对 Elasticsearch 进行很好的监控和管理,Amazon AWS 中也有基于 Elasticsearch 构建的平台服务,帮助电商应用程序,网站等提供安全,高可靠,低成本,低延时,高吞吐的量的个性化搜索。
二、使用场景
记录和日志分析
围绕 Elasticsearch 构建的生态系统使其成为最容易实施和扩展日志记录解决方案之一。从 Beats,Logstash 到 Ingest Nodes,Elasticsearch 为您提供了大量的选项,可以在任何地方获取数据并将其索引化。然后,使用 Kibana 工具使您能够创建丰富的仪表板和分析,而 Curator 使得您自动化管理索引的生命周期。采集和组合公共数据,与日志数据一样,Elastic Stack 拥有大量工具,可以轻松抓取和索引远程数据。此外,与大多数文档存储一样,非严格的模式使 Elasticsearch 可以灵活地接收多个不同的数据源,并能使得这些数据可以管理和搜索。
全文搜索
毫无疑问,作为 Elasticsearch 的核心功能,全文搜索在此列表中占据重要位置。很多事实已经证明 Elasticsearch 的搜索功能强大,灵活,并且包含大量工具以使搜索更容易; Elasticsearch 有自己的查询 DSL、内置的自动补全功能等等。
事件数据和指标
Elasticsearch 还可以很好地处理时间序列数据,如指标(metrics )和应用程序事件。这是另一个巨大的 Beats 生态系统允许您轻松获取常见应用程序数据的区域。无论您使用何种技术,Elasticsearch 都有很好的机会获取开箱即用的指标和事件,添加该功能非常简单。
数据可视化
凭借大量的图表选项,地理数据的平铺服务和时间序列数据的 TimeLion,Kibana 是一款功能强大且易于使用的可视化工具。对于上面的每个用例,Kibana 都会处理一些可视化组件。
考虑使用ES场景:
响应时间:
MySQL当数据库中的文档数仅仅上万条时,关键词查询就比较慢了。如果一旦到企业级的数据,响应速度就会更加不可接受。原因是 在数据库做模糊查询时,如LIKE语句,它会遍历整张表,同时进行字符串匹配。这个步骤不高效,而且随着数据量的增大,消耗的资源和时间都会线性的增长。
ES搜索服务后,这个问题被很好解决,TB级数据在毫秒级就能返回检索结果,很好地解决了痛点。
分词方面:
MySQL在做中文搜索时,组合词检索在数据库是很难完成的。例如,当用户在搜索框输入“中国足球”时,数据库通常只能把这四个字去进行全部匹配。可是在文本中,可能会出现“推荐中国足球的赛事”,这时候就没有结果了。因为数据库并不支持分词。如果人工去开发分词功能,费时费精力。ES搜索服务后,就不用太过于关注分词了,因为Elasticsearch支持中文分词插件,很好地解决了问题。因为当用户使用Elasticsearch时进行搜索时,Elasticsearch就自动帮他分好词了。例如输入“中国足球”时,Elasticsearch会自动做下面两件事 (1) 将“中国足球”分词成“中国”和“足球” (2) 查找包含这两个词的文档
相关性方面:
MySQL在用数据库做搜索时,结果经常会出现一系列不匹配的文档,需求: · 到底什么文档是用户真正想要的呢? · 怎么才能把用户想看的文档放在搜索列表最前面呢?
数据库并不支持相关性搜索。例如,当用户搜索“咖啡厅”的时候,他很可能更想知道附近哪里可以喝咖啡,而不是怎么开咖啡厅。ES搜索服务后能很好地支持相关性评分。通过合理的优化,ES搜索服务能够返回精准的结果,满足用户的需求。因为Elasticsearch支持全文搜索和相关度评分。这样在返回结果就会根据分数由高到低排列。分数越高,意味着和查询语句越相关。例如,当用户搜索“星巴克咖啡”,带有“星巴克咖啡”的信息就要比只包含“咖啡”的信息靠前。
三、ES优缺点
优点:
-
分布式:节点对外表现对等,加入节点自动均衡
-
elasticsearch 完全支持 Apache Lucene 的接近实时的搜索
-
各节点组成对等的网络结构,当某个节点出现故障时会自动分配其他节点代替期进行工作
-
横向可扩展性,如果你需要增加一台服务器,只需要做点配置,然后启动就ok了
-
高可用:提供复制(replica)机制,一个分片可以设置多个复制,使得某台服务器宕机的情况下,集群仍旧可以照常运行,并会把由于服务器宕机丢失的复制恢复到其它可用节点上;这点也类似于 HDFS 的复制机制(HDFS 中默认是 3 份复制)
缺点:
-
不支持事物
-
相对吃内存
ES不是数据库,它适合于海量数据、更新频率很低的数据(ES没有事务也不适合处理并行更改数据)。
四、整体架构
1. Gateway是ES用来存储索引的文件系统,支持多种类型。 2. Gateway的上层是一个分布式的lucene框架。 3. Lucene之上是ES的模块,包括:索引模块、搜索模块、映射解析模块等 4. ES模块之上是 Discovery、Scripting和第三方插件。Discovery是ES的节点发现模块,不同机器上的ES节点要组成集群需要进行消息通信,集群内部需要选举master节点,这些工作都是由Discovery模块完成。支持多种发现机制,如 Zen 、EC2、gce、Azure。Scripting用来支持在查询语句中插入javascript、python等脚本语言,scripting模块负责解析这些脚本,使用脚本语句性能稍低。ES也支持多种第三方插件。 5. 再上层是ES的传输模块和JMX.传输模块支持多种传输协议,如 Thrift、memecached、http,默认使用http。JMX是java的管理框架,用来管理ES应用。 6. 最上层是ES提供给用户的接口,可以通过RESTful接口和ES集群进行交互。
五、核心概念

Near Realtime (NRT)近实时:数据提交索引后,立马就可以搜索到。 Cluster集群:一个集群由一个唯一的名字标识,默认为“elasticsearch”。集群名称非常重要,具体相同集群名的节点才会组成一个集群。集群名称可以在配置文件中指定。集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。ElasticSearch的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看ElasticSearch集群,在逻辑上是个整体,你与任何一个节点的通信和与整个ElasticSearch集群通信是等价的。 Node 节点:存储集群的数据,参与集群的索引和搜索功能。像集群有名字,节点也有自己的名称,默认在启动时会以一个随机的UUID的前七个字符作为节点的名字,你可以为其指定任意的名字。通过集群名在网络中发现同伴组成集群。一个节点也可是集群。每一个运行实例称为一个节点,每一个运行实例既可以在同一机器上,也可以在不同的机器上。所谓运行实例,就是一个服务器进程,在测试环境中可以在一台服务器上运行多个服务器进程,在生产环境中建议每台服务器运行一个服务器进程。 Index 索引(): 一个索引是一个文档的集合(等同于solr中的集合)。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引。索引作动词时,指索引数据、或对数据进行索引。Type 类型:指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从6.0.0 版本起已废弃,一个索引中只存放一类数据。Elasticsearch里的索引概念是名词而不是动词,在elasticsearch里它支持多个索引。 一个索引就是一个拥有相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来 标识(必须全部是小写字母的),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,你能够创建任意多个索引。 Document 文档:被索引的一条数据,索引的基本信息单元,以JSON格式来表示。一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档、某一个产品的一个文档、某个订单的一个文档。文档以JSON格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index/type里面,你可以存储任意多的文档。注意,一个文档物理上存在于一个索引之中,但文档必须被索引/赋予一个索引的type。 Shard 分片:在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上(分片数创建索引时指定,创建后不可改了。备份数可以随时改)。索引分片,ElasticSearch可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。分片的好处: - 允许我们水平切分/扩展容量 - 可在多个分片上进行分布式的、并行的操作,提高系统的性能和吞吐量。 Replication 备份: 一个分片可以有多个备份(副本)。备份的好处: - 高可用扩展搜索的并发能力、吞吐量。 - 搜索可以在所有的副本上并行运行。 primary shard:主分片,每个文档都存储在一个分片中,当你存储一个文档的时候,系统会首先存储在主分片中,然后会复制到不同的副本中。默认情况下,一个索引有5个主分片。你可以在事先制定分片的数量,当分片一旦建立,分片的数量则不能修改。 replica shard:副本分片,每一个分片有零个或多个副本。副本主要是主分片的复制,其中有两个目的: - 增加高可用性:当主分片失败的时候,可以从副本分片中选择一个作为主分片。 - 提高性能:当查询的时候可以到主分片或者副本分片中进行查询。默认情况下,一个主分配有一个副本,但副本的数量可以在后面动态的配置增加。副本必须部署在不同的节点上,不能部署在和主分片相同的节点上。 term索引词:在elasticsearch中索引词(term)是一个能够被索引的精确值。foo,Foo几个单词是不相同的索引词。索引词(term)是可以通过term查询进行准确搜索。 text文本:是一段普通的非结构化文字,通常,文本会被分析称一个个的索引词,存储在elasticsearch的索引库中,为了让文本能够进行搜索,文本字段需要事先进行分析;当对文本中的关键词进行查询的时候,搜索引擎应该根据搜索条件搜索出原文本。 analysis:分析是将文本转换为索引词的过程,分析的结果依赖于分词器,比如: FOO BAR, Foo-Bar, foo bar这几个单词有可能会被分析成相同的索引词foo和bar,这些索引词存储在elasticsearch的索引库中。当用 FoO:bAR进行全文搜索的时候,搜索引擎根据匹配计算也能在索引库中搜索出之前的内容。这就是elasticsearch的搜索分析。 routing路由:当存储一个文档的时候,他会存储在一个唯一的主分片中,具体哪个分片是通过散列值的进行选择。默认情况下,这个值是由文档的id生成。如果文档有一个指定的父文档,从父文档ID中生成,该值可以在存储文档的时候进行修改。 type类型:在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组相同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台 并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。 template:索引可使用预定义的模板进行创建,这个模板称作Index templatElasticSearch。模板设置包括settings和mappings。 mapping:映射像关系数据库中的表结构,每一个索引都有一个映射,它定义了索引中的每一个字段类型,以及一个索引范围内的设置。一个映射可以事先被定义,或者在第一次存储文档的时候自动识别。 field:一个文档中包含零个或者多个字段,字段可以是一个简单的值(例如字符串、整数、日期),也可以是一个数组或对象的嵌套结构。字段类似于关系数据库中的表中的列。每个字段都对应一个字段类型,例如整数、字符串、对象等。字段还可以指定如何分析该字段的值。 source field:默认情况下,你的原文档将被存储在_source这个字段中,当你查询的时候也是返回这个字段。这允许您可以从搜索结果中访问原始的对象,这个对象返回一个精确的json字符串,这个对象不显示索引分析后的其他任何数据。 id:一个文件的唯一标识,如果在存库的时候没有提供id,系统会自动生成一个id,文档的index/type/id必须是唯一的。 recovery:代表数据恢复或叫数据重新分布,ElasticSearch在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。 River:代表ElasticSearch的一个数据源,也是其它存储方式(如:数据库)同步数据到ElasticSearch的一个方法。它是以插件方式存在的一个ElasticSearch服务,通过读取river中的数据并把它索引到ElasticSearch中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的,river这个功能将会在后面的文件中重点说到。 gateway:代表ElasticSearch索引的持久化存储方式,ElasticSearch默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。当这个ElasticSearch集群关闭再重新启动时就会从gateway中读取索引数据。ElasticSearch支持多种类型的gateway,有本地文件系统(默认), 分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。 discovery.zen:代表ElasticSearch的自动发现节点机制,ElasticSearch是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。 Transport:代表ElasticSearch内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
六、工作原理
启动过程
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示
在集群中,一个节点被选举成主节点(master node)。这个节点负责管理集群的状态,当群集的拓扑结构改变时把索引分片分派到相应的节点上。
探测失效节点
在正常工作时,主节点会监控所有的节点,查看各个节点是否工作正常。如果在指定的时间里面,节点无法访问,该节点就被视为出故障了,接下来错误处理程序就会启动。集群需要重新均衡——由于该节点出现故障,分配到该节点的索引分片丢失。其它节点上相应的分片就会把工作接管过来。换句话说,对于每个丢失的主分片,新的主分片将从剩余的分片副本(Replica)中选举出来。重新安置新的分片和副本的这个过程可以通过配置来满足用户需求。 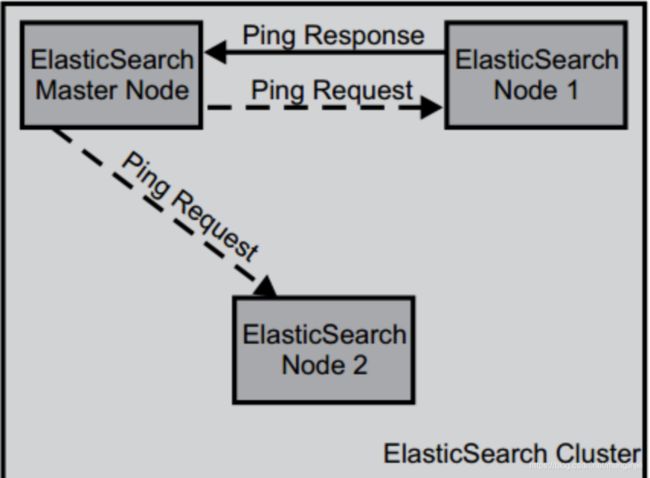
文档写入原理
1.选择任意一个DataNode发送请求,例如:node2。此时,node2就成为一个coordinating node(协调节点)
2.计算得到文档要写入的分片 'shard = hash(routing) % number_of_primary_shards' routing 是一个可变值,默认是文档的 _id
3.coordinating node会进行路由,将请求转发给对应的primary shard所在的DataNode(假设primary shard在node1、replica shard在node2)
4.node1节点上的Primary Shard处理请求,写入数据到索引库中,并将数据同步到Replica shard
5.Primary Shard和Replica Shard都保存好了文档,返回client
查询原理
查询的时候操作系统会将磁盘文件里的数据自动缓存到 filesystem cache。Elasticsearch 严重依赖于底层的 filesystem cache,如果给 filesystem cache 很大,可以容纳所有的 index、segment 等文件,那么搜索的时候就基本都是走内存的,性能会非常高;反之,搜索速度并不会很快。
-
client发起查询请求,某个DataNode接收到请求,该DataNode就会成为协调节点(Coordinating Node)
-
协调节点(Coordinating Node)将查询请求广播到每一个数据节点,这些数据节点的分片会处理该查询请求
-
每个分片进行数据查询,将符合条件的数据放在一个优先队列中,并将这些数据的文档ID、节点信息、分片信息返回给协调节点
-
协调节点将所有的结果进行汇总,并进行全局排序
-
协调节点向包含这些文档ID的分片发送get请求,对应的分片将文档数据返回给协调节点,最后协调节点将数据返回给客户端
七、集群搭建
我初始写的是个md文件,文档可能格式会乱,贴一下md的百度云连接
链接: https://pan.baidu.com/s/1TrJdhonnTaTDXFXPyqNPpA?pwd=mezf 提取码: mezf 复制这段内容后打开百度网盘手机App,操作更方便哦
1.下载地址
#es下载地址,我使用的是7.4.1版本
Past Releases of Elastic Stack Software | Elastic
#分词器下载地址 我使用的是7.4.1的zip包
https://github.com/medcl/elasticsearch-analysis-ik/releases

2.新建用户
#创建用户
useradd es
#设置密码
passwd es
#查看用户(看不看都行)
cut -d : -f 1 /etc/passwd#查看属组(看不看都行)
cut -d : -f 1 /etc/group
3.创建文件夹&授权
#所有节点操作一样,除了配置文件略有不同
#解压
tar -zxvf elasticsearch-7.4.1-linux-x86_64.tar.gz -C /opt/
#授权
chown -R es:es /opt/elasticsearch-7.4.1
#创建目录
mkdir -p /var/lib/elasticsearch
mkdir -p /var/log/elasticsearch
依次进入/var/lib 和 /var/log
#授权
chown -R es:es ./elasticsearch/
4.配置
vi /etc/sysctl.conf
vm.max_map_count = 262144#校验是否生效
sysctl -p
#设置es在系统中的文件数量
vi /etc/security/limits.conf
elastic soft nofile 65536 elastic hard nofile 65536 elastic soft memlock unlimited elastic hard memlock unlimited#修改配置文件,其中network.host填写实际本机ip,node.name分别填写master或slave
vi /opt/elasticsearch-7.4.1/config/elasticsearch.yml
#mater节点配置示例 cluster.name: TEST_ES_CLUSTER node.name: master network.host: 192.168.72.140 # 可以配置多个master cluster.initial_master_nodes: ["master"] path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true # 有多少个服务器就配多少个,可以横向扩展,很方便 discovery.zen.ping.unicast.hosts: ["192.168.72.140", "192.168.72.141", "192.168.72.142","192.168.72.143","192.168.72.144","192.168.72.145"] discovery.zen.minimum_master_nodes: 2 gateway.recover_after_nodes: 2 #slave节点配置示例 cluster.name: TEST_ES_CLUSTER node.name: slave1 network.host: 192.168.72.141 # 可以配置多个master cluster.initial_master_nodes: ["master"] path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true # 有多少个服务器就配多少个,可以横向扩展,很方便 discovery.zen.ping.unicast.hosts: ["192.168.72.140", "192.168.72.141", "192.168.72.142","192.168.72.143","192.168.72.144","192.168.72.145"] discovery.zen.minimum_master_nodes: 2 gateway.recover_after_nodes: 2
5.启动准备
vi /usr/lib/systemd/system/elasticsearch.service
[Unit] Description=ElasticSearch Requires=network.service After=network.service [Service] User=es Group=es LimitNOFILE=65536 LimitMEMLOCK=infinity Environment=/opt/elasticsearch-7.4.1/jdk ExecStart=/opt/elasticsearch-7.4.1/bin/elasticsearch SuccessExitStatus=143 [Install] WantedBy=multi-user.target
6.启动命令
systemctl daemon-reload systemctl start elasticsearch systemctl status elasticsearch systemctl restart elasticsearch //开机自启 systemctl enable elasticsearch //取消开机自启 systemctl disable elasticsearch
7.安装分词器
cd /opt/elasticsearch-7.4.1/plugins
mkdir ik
拷贝ik分词器.zip包到/opt/elasticsearch-7.4.1/plugins/ik目录下
upzip elasticsearch-analysis-ik-7.4.1.zip
systemctl restart elasticsearch
如果重启报权限问题,配置jdk的策略
vi /opt/elasticsearch-7.4.1/jdk/lib/security/default.policy
在最后一个 "}" 前追加下面一行
permission java.net.SocketPermission ":","accept,connect,resolve";
八、使用插件
Cerebro是一个集群管理工具,比Kibana轻量很多,很适用与生产和测试等环境的es集群管理。它是kopf的升级版本,更改了个名字,包含kopf的功能(监控工具,并包含head插件的部分功能,可图形化的进行新建索引等操作。
https://github.com/lmenezes/cerebro/releases
访问如下,其中该工具的conf下的配置文件可以定义集群路径
bin目录下启动该工具
cd /root/
nohup ./cerebro -Dhttp.port=9000 > /dev/null 2>&1 &
http://192.168.72.140:9000/#/overview?host=ning%20cluster
elasticsearch-head
需要node、git环境
git clone git://github.com/mobz/elasticsearch-head.git cd elasticsearch-head npm install npm run start
九、性能优化
1. 硬件选择 目前公司的物理机机型在CPU和内存方面都满足需求,建议使用SSD机型。原因在于,可以快速把 Lucene 的索引文件加载入内存(这在宕机恢复的情况下尤为明显),减少 IO 负载和 IO wait以便CPU不总是在等待IO中断。建议使用多裸盘而非raid,因为 ElasticSearch 本身就支持多目录,raid 要么牺牲空间要么牺牲可用性。
2. 系统配置 ElasticSearch 理论上必须单独部署,并且会独占几乎所有系统资源,因此需要对系统进行配置,以保证运行 ElasticSearch 的用户可以使用足够多的资源。生产集群需要调整的配置如下: 1. 设置 JVM 堆大小; 2. 关闭 swap; 3. 增加文件描述符; 4. 保证足够的虚存; 5. 保证足够的线程; 6. 暂时不建议使用G1GC;
3. 设置 JVM 堆大小 ElasticSearch 需要有足够的 JVM 堆支撑索引数据的加载,对于公司的机型来说,因为都是大于 128GB 的,所以推荐的配置是 32GB(如果 JVM 以不等的初始和最大堆大小启动,则在系统使用过程中可能会因为 JVM 堆的大小调整而容易中断。 为了避免这些调整大小的暂停,最好使用初始堆大小等于最大堆大小的 JVM 来启动),预留足够的 IO Cache 给 Lucene(官方建议超过一半的内存需要预留)。
4. 关闭 swap & 禁用交换 必须要关闭 swap,因为在物理内存不足时,如果发生 FGC,在回收虚拟内存的时候会造成长时间的 stop-the-world,最严重的后果是造成集群雪崩。公司的默认模板是关闭的,但是要巡检一遍,避免有些机器存在问题。设置方法:
Step1. root 用户临时关闭 # swapoff -a # sysctl vm.swappiness=0 Step2. 修改 /etc/fstab,注释掉 swap 这行 Step3. 修改 /etc/sysctl.conf,添加: vm.swappiness = 0 Step4. 确认是否生效 # sysctl vm.swappiness
也可以通过修改 yml 配置文件的方式从 ElasticSearch 层面禁止物理内存和交换区之间交换内存,修改 ${PATH_TO_ES_HOME}/config/elasticsearch.yml,添加: bootstrap.memory_lock: true
释放内存
POST /${INDEX_NAME}/_forcemerge?max_num_segments=1&only_expunge_deletes=true&wait_for_completion=true
POST /${INDEX_PATTERN}/_forcemerge?max_num_segments=1&only_expunge_deletes=true&wait_for_completion=true
十、参考网站
官方地址
十一、postman测试json文件,复制json,导入postman
{
"info": {
"_postman_id": "113c7f6e-b1bc-4926-97af-5d768cd1ce73",
"name": "存储请求集合ES",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "ES返回cat开头的api",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://192.168.72.140:9200/_cat",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"_cat"
]
}
},
"response": []
},
{
"name": "创建ES索引index",
"request": {
"method": "PUT",
"header": [],
"body": {
"mode": "raw",
"raw": "{\r\n \r\n}",
"options": {
"raw": {
"language": "json"
}
}
},
"url": {
"raw": "http://192.168.72.140:9200/index",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"index"
]
},
"description": "http://192.168.72.140:9200/index"
},
"response": []
},
{
"name": "查询单条索引信息index",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://192.168.72.140:9200/index",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"index"
]
}
},
"response": []
},
{
"name": "ES查看节点状态",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://192.168.72.140:9200/_cat/nodes?pretty",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"_cat",
"nodes"
],
"query": [
{
"key": "pretty",
"value": null
}
]
}
},
"response": []
},
{
"name": "ES查看集群状态",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://192.168.72.140:9200/_cluster/state?pretty",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"_cluster",
"state"
],
"query": [
{
"key": "pretty",
"value": null
}
]
}
},
"response": []
},
{
"name": "ES查看集群健康状态",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://192.168.72.140:9200/_cluster/health",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"_cluster",
"health"
]
}
},
"response": []
},
{
"name": "ES查询开放的索引",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://192.168.72.140:9200/_cat/indices",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"_cat",
"indices"
]
}
},
"response": []
},
{
"name": "ES的ik分词器测试两种策略,ik_smart,ik_max_word",
"protocolProfileBehavior": {
"disableBodyPruning": true
},
"request": {
"method": "GET",
"header": [],
"body": {
"mode": "raw",
"raw": "{\r\n \"analyzer\":\"ik_max_word\",\r\n \"text\":\"中华人民共和国国歌\"\r\n}",
"options": {
"raw": {
"language": "json"
}
}
},
"url": {
"raw": "http://192.168.72.140:9200/_analyze",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"_analyze"
]
}
},
"response": []
},
{
"name": "ES批量新增记录",
"request": {
"method": "POST",
"header": [],
"body": {
"mode": "raw",
"raw": "{\"index\":{\"_index\":\"index_ning\",\"_type\":\"type_ning\",\"_id\":\"1\"}}\r\n{\"name\":\"i am test 1\",\"age\":\"10\"}\r\n{\"index\":{\"_index\":\"index_ning\",\"_type\":\"type_ning\",\"_id\":\"2\"}}\r\n{\"name\":\"i am test 2\",\"age\":\"11\"}\r\n",
"options": {
"raw": {
"language": "json"
}
}
},
"url": {
"raw": "http://192.168.72.140:9200/_bulk",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"_bulk"
]
}
},
"response": []
},
{
"name": "ES检索批量新增的记录",
"request": {
"method": "POST",
"header": [],
"body": {
"mode": "raw",
"raw": "{\r\n \"query\": { \"match\": { \"name\": \"i am\" } }\r\n}",
"options": {
"raw": {
"language": "json"
}
}
},
"url": {
"raw": "http://192.168.72.140:9200/index_ning/_search",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"index_ning",
"_search"
]
}
},
"response": []
},
{
"name": "一、ES分词器演示,指定分词策略",
"request": {
"method": "PUT",
"header": [],
"body": {
"mode": "raw",
"raw": "\r\n{\r\n\t\"mappings\": {\r\n\t\t\"properties\": {\r\n\t\t\t\"id\": {\r\n\t\t\t\t\"type\": \"long\"\r\n\t\t\t},\r\n\t\t\t\"title\": {\r\n\t\t\t\t\"type\": \"text\",\r\n\t\t\t\t\"analyzer\": \"ik_max_word\"\r\n\t\t\t}\r\n\t\t}\r\n\t}\r\n}\r\n",
"options": {
"raw": {
"language": "json"
}
}
},
"url": {
"raw": "http://192.168.72.140:9200/ik_index",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"ik_index"
]
}
},
"response": []
},
{
"name": "二、ES分词器演示,查看索引详情",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://192.168.72.140:9200/ik_index/_mapping",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"ik_index",
"_mapping"
]
}
},
"response": []
},
{
"name": "三、ES分词器演示,录入一条数据",
"request": {
"method": "POST",
"header": [],
"body": {
"mode": "raw",
"raw": "\r\n{\r\n\t\"id\": 1,\r\n\t\"title\": \"大兴庞各庄的西瓜\",\r\n\t\"desc\": \"大兴庞各庄的西瓜真是好吃,脆沙瓤,甜掉牙\"\r\n}",
"options": {
"raw": {
"language": "json"
}
}
},
"url": {
"raw": "http://192.168.72.140:9200/ik_index/_doc/1",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"ik_index",
"_doc",
"1"
]
}
},
"response": []
},
{
"name": "四、ES分词器演示,检索数据",
"request": {
"method": "POST",
"header": [],
"body": {
"mode": "raw",
"raw": "{\r\n \"query\": { \"match\": { \"title\": \"西瓜\" } }\r\n}",
"options": {
"raw": {
"language": "json"
}
}
},
"url": {
"raw": "http://192.168.72.140:9200/ik_index/_search",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"ik_index",
"_search"
]
}
},
"response": []
},
{
"name": "五、ES分词器演示,验证分词器分词策略",
"request": {
"method": "POST",
"header": [],
"body": {
"mode": "raw",
"raw": "{\r\n \"query\": { \"match\": { \"title\": \"西\" } }\r\n}",
"options": {
"raw": {
"language": "json"
}
}
},
"url": {
"raw": "http://192.168.72.140:9200/ik_index/_search",
"protocol": "http",
"host": [
"192",
"168",
"72",
"140"
],
"port": "9200",
"path": [
"ik_index",
"_search"
]
}
},
"response": []
}
]
}