1.mysql基本操作
目录
1.数据库的基本理解和使用
什么是数据库
主流数据库
mysql基本使用
2.数据库的操作
3.表的操作
1.数据库的基本理解和使用
什么是数据库
文件的安全性问题文件不利于数据查询和管理文件不利于存储海量数据文件在程序中控制不方便
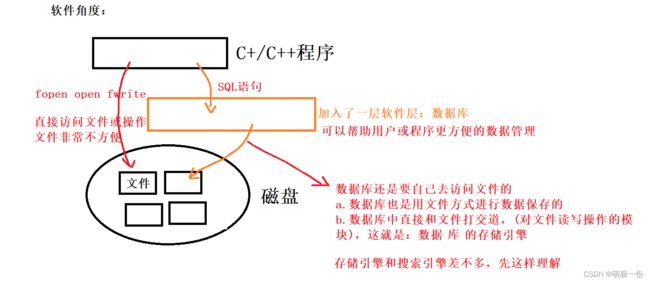
文件角度:
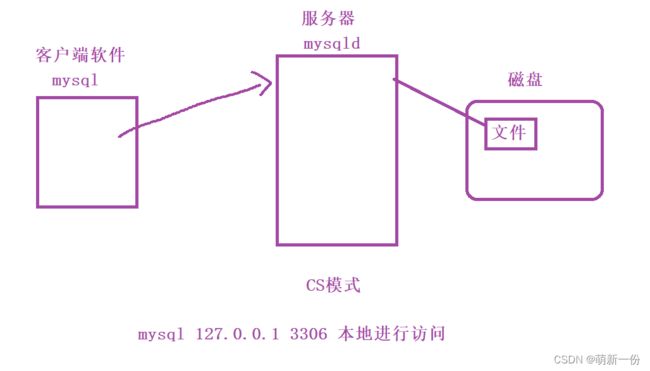
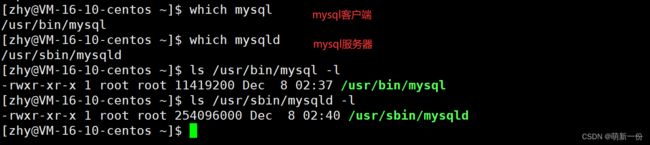
其实在安装mysql,实际在安装mysql(客户端)和mysqld(服务器)。mysql是可以跨网络的。
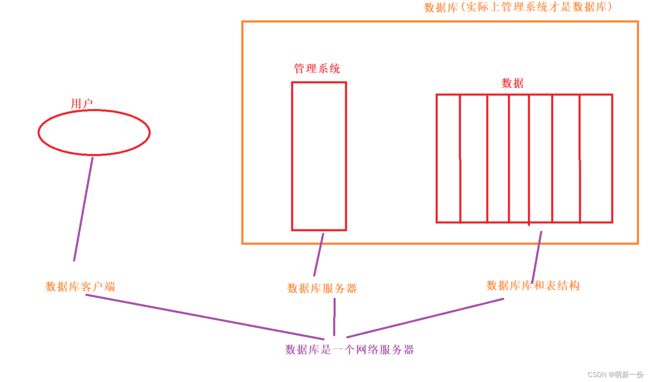
数据库就是一个服务器软件,不需要我们直接维护文件,而是通过数据库进行维护。通过mysql客户端向服务器发送sql请求,根据请求进行数据的增删查改。mysql或数据库属于应用层的软件。mysql并不是OS内置的,而是需要我们自己安装,底层一定是直接或间接访问OS的文件接口。mysql就是一个网络服务,应用层协议。
主流数据库
SQL Sever : 微软的产品, .Net 程序员的最爱,中大型项目。Oracle : 甲骨文产品,适合大型项目,复杂的业务逻辑,并发一般来说不如 MySQL 。MySQL :世界上最受欢迎的数据库,属于甲骨文,并发性好,不适合做复杂的业务。主要用在电商, SNS ,论坛。对简单的SQL 处理效果好。PostgreSQL : 加州大学伯克利分校计算机系开发的关系型数据库,不管是私用,商用,还是学术研究使用,可以免费使用,修改和分发。SQLite : 是一款轻型的数据库,是遵守 ACID 的关系型数据库管理系统,它包含在一个相对小的 C 库中。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K 的内存就够了。H2 : 是一个用 Java 开发的嵌入式数据库,它本身只是一个类库,可以直接嵌入到应用项目中。
mysql基本使用
运行了mysql:

mysql是一个网络服务:

都是动态连接,都是可执行程序,我们这里的客户端是命令行客户端,还有图形化界面客户端。

2.连接服务器
mysql -h 127 .0.0.1 -P 3306 -u root -p-h 相当于host,本主机-P 端口号-u 用谁登陆-p 输入密码
输入密码登陆成功 ,本地登陆:

本地通信使用的不是TCP协议,而是域间套接:知道就行
退出:quit

注意:
如果没有写-h 127.0.0.1默认是连接本地
如果没有写-P 3306 默认是连接3306端口号
所以一般这样登陆:

总结:我们想要访问mysql本质是:登陆mysql客户端连接到服务器。
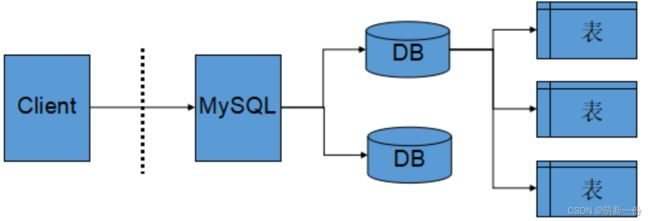
3.服务器、数据库、表关系
查看mysql相关的配置:

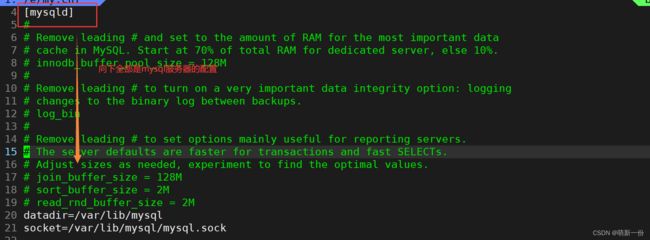
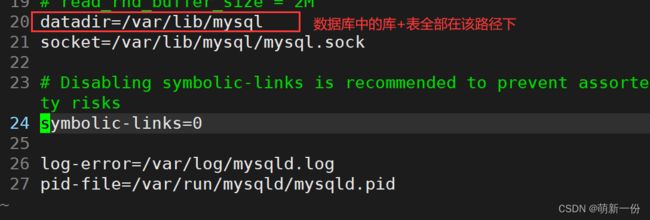
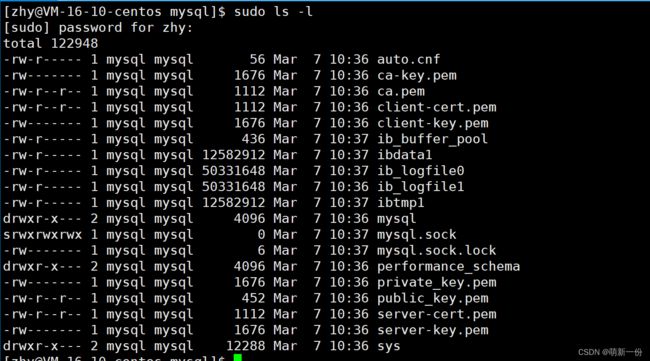
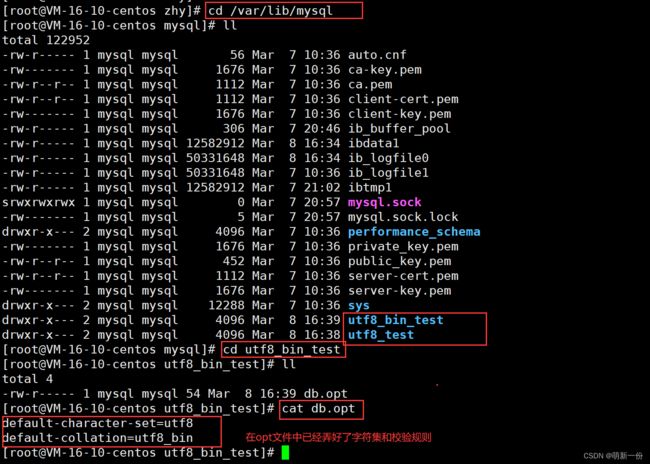
该路径下的内容:(我们可以切换到root用户下,方便观察,要不一直需要sudo)
展示数据库:
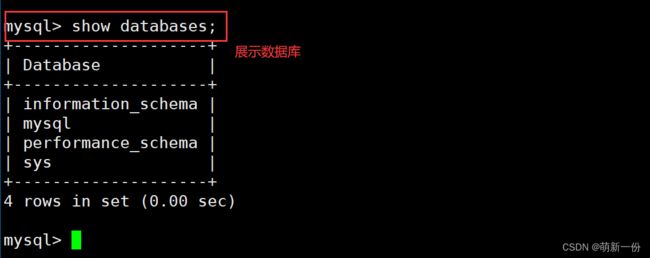
创建数据库:

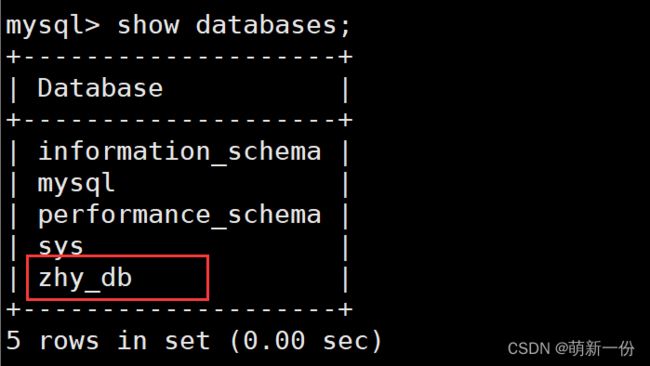
在该路径的目录下创建了数据库:
zhy_db目录下只有一个文件:
总结:所以创建数据库本质就是在Linux下创建一个目录。
使用数据库,就相当于linux cd 一个目录:

创建数据库表:先会用就行
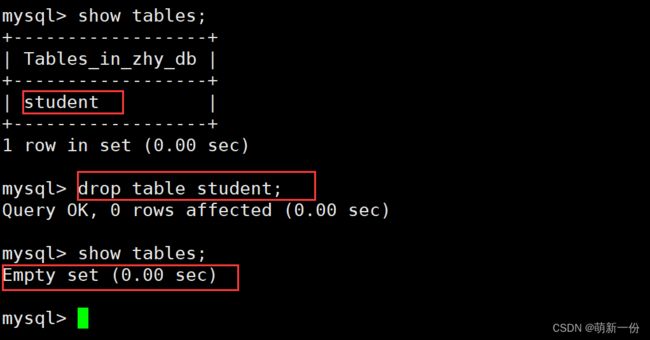
Tables_in_:表在那个库中 (show tables查看zhy_db库中的表)

我们看下 zhy_db目录下:先了解,一个表结构对应辆个文件

结论:所谓的创建数据库表,本质就是在特定目录下创建特定的文件
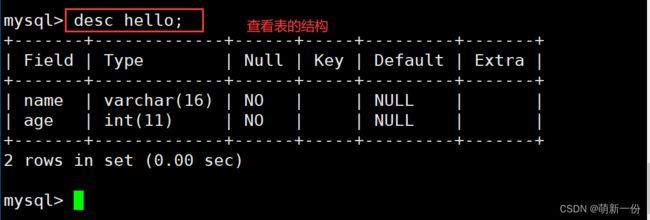
查看表的结构:
mysql命令必须以;作为结尾(输入结束)
插入数据和查询表中的数据:

查询表中的数据:
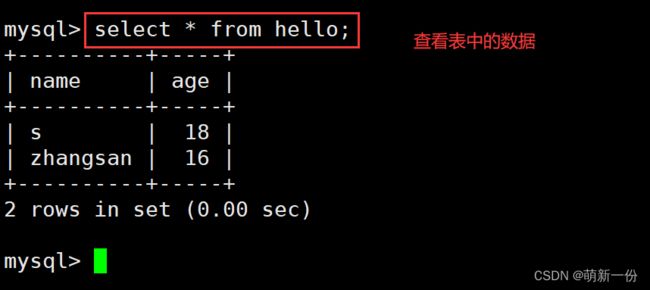
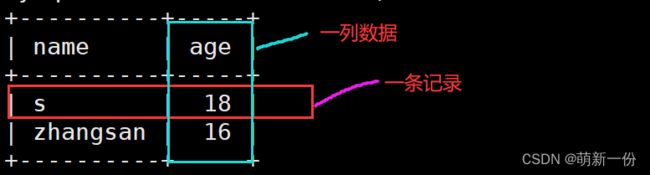
mysql数据逻辑存储:
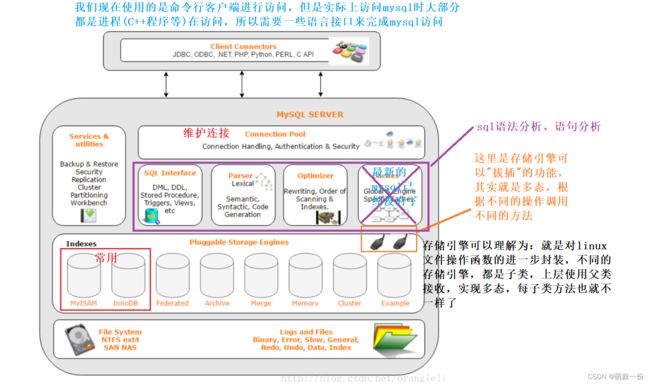
mysql架构
MySQL 是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如 Unix/Linux、Windows、Mac 和Solaris。各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性。
SQL语句分类
为什么会有不同的SQL语句分类:SQL也有种类的不同,因为使用sql的人,他们的需求不一样。
1.DDL【data definition language】 数据定义语言,用来维护存储数据的结构 。代表指令: create, drop, alter。(就好比定义链表节点、struct或者class)
2.DML【data manipulation language】 数据操纵语言,用来对数据进行操作 。代表指令: insert,delete,update。(就好比,你向链表中插入数据)
DML中又单独分了一个DQL,数据查询语言,代表指令: select
3.DCL【Data Control Language】 数据控制语言,主要负责权限管理和事务 。代表指令: grant,revoke,commit。(相当于管理员,我允许谁能插入数据)
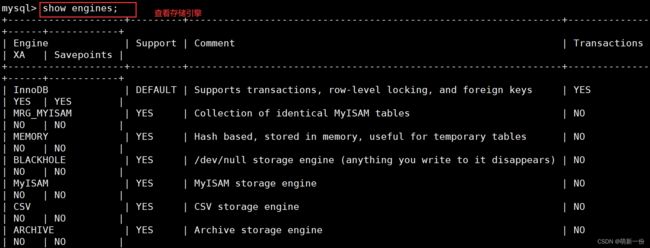
存储引擎
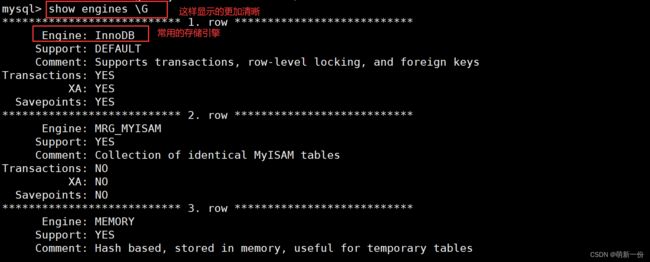

2.数据库的操作
1.创建数据库的语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] ...]create_specification:[DEFAULT] CHARACTER SET charset_name[DEFAULT] COLLATE collation_name大小都是一样的,我们下面都使用小写。[ ] 是可选项,可以省略CHARACTER SET: 指定数据库采用的字符集COLLATE: 指定数据库字符集的校验规则IF NOT EXISTS 如果不存在就创建
create database db1;
create database db2 charset=utf8;
create database db3 charset=utf8 collate utf8_general_ci;
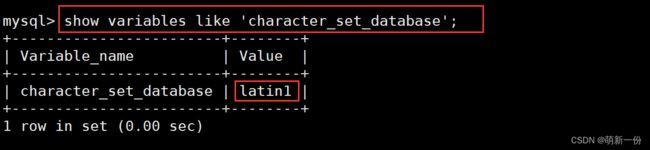
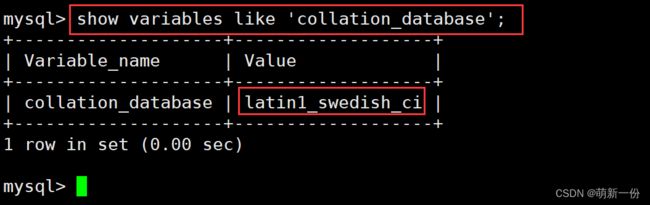
show variables like 'character_set_database' ;show variables like 'collation_database' ;
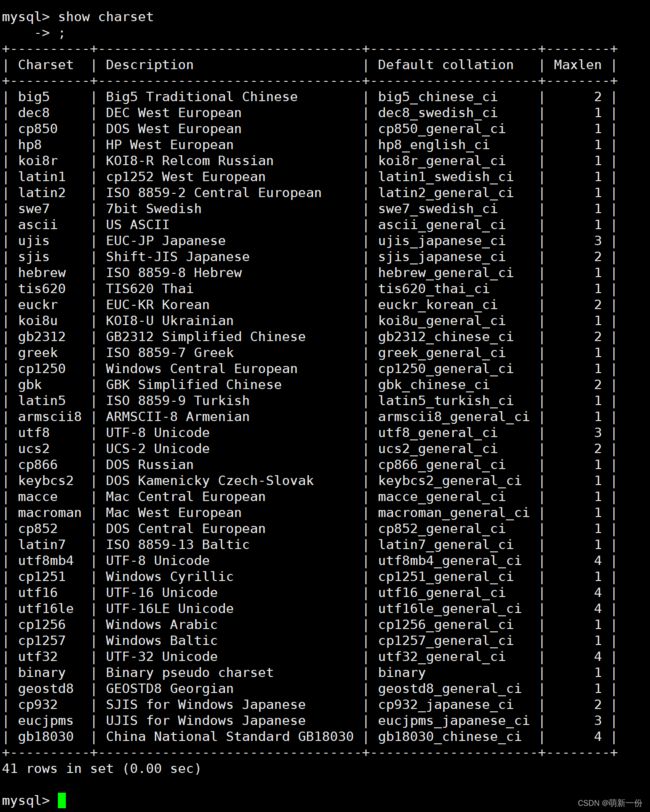
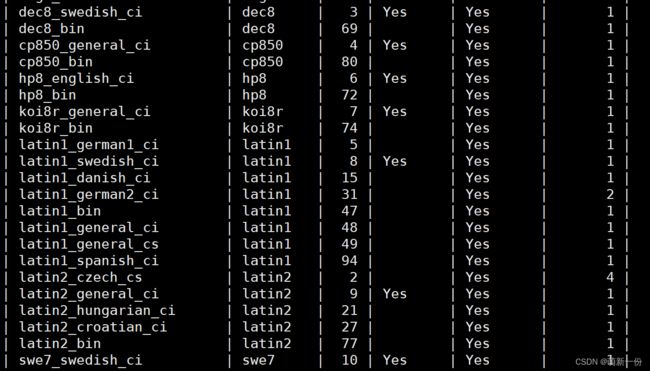
查看数据库支持的字符集:
show charset;
编码对应的校验规则:
查看数据库支持的字符集校验规则:
show collation;
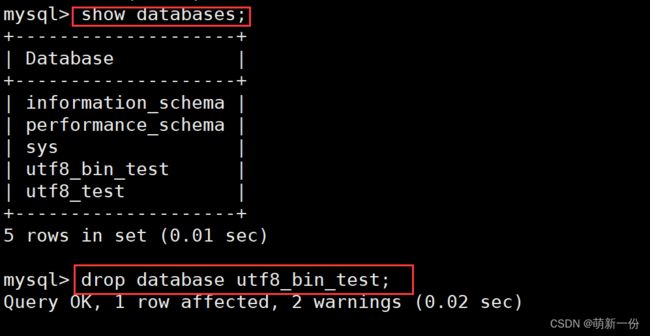
删除数据库:就是删除对应的目录
drop database +数据库名字
校验规则对数据库的影响
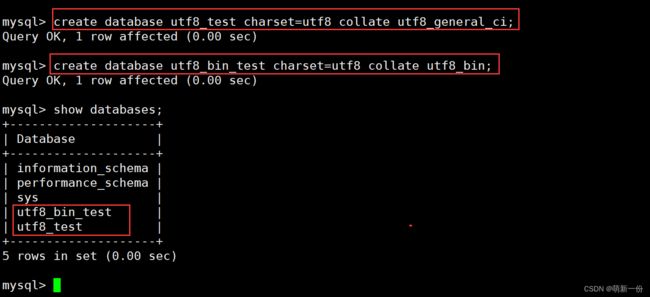
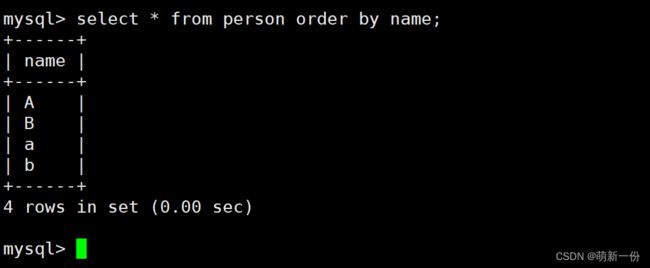
校验规则使用utf8_ general_ ci[不区分大小写]:
我们在一个数据库中建表,没有写表的编码和校验规则,默认会继承数据库规则。
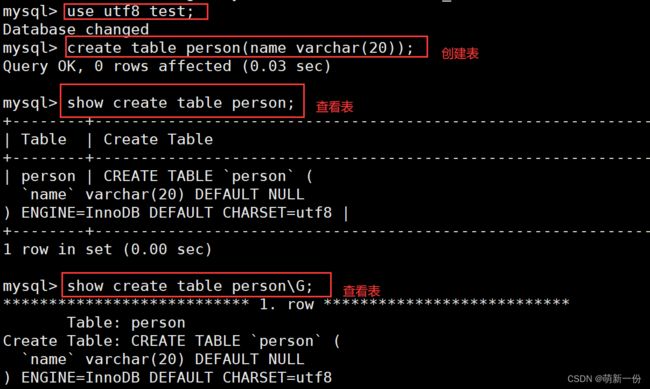
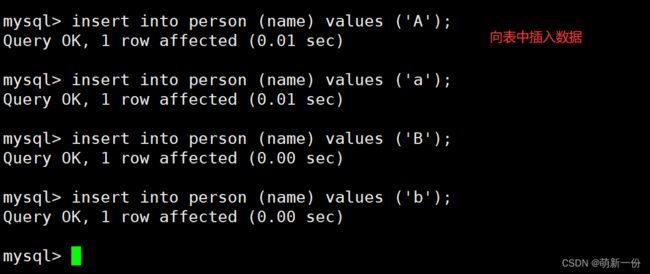
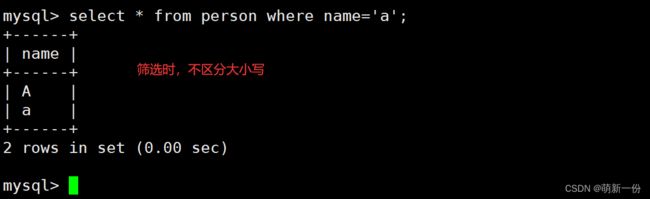
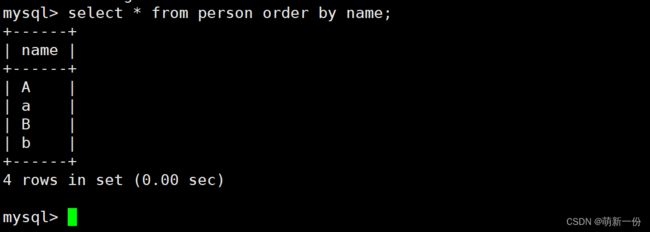
筛选对应的数据:不区分大小写
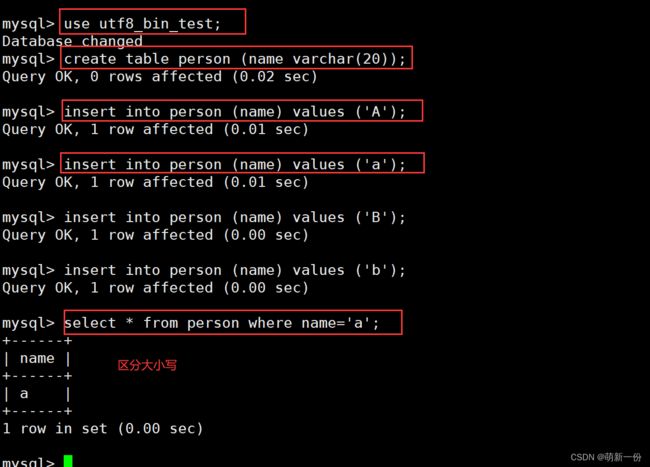
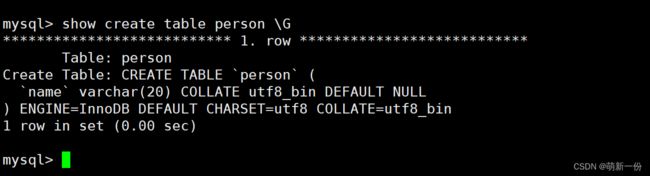
总结:不同的校验规则,给我们不同的结果
mysql登陆使用的root(mysql内部的管理员),和linux的root没有关系。仅仅是用一下这个root用户而已。
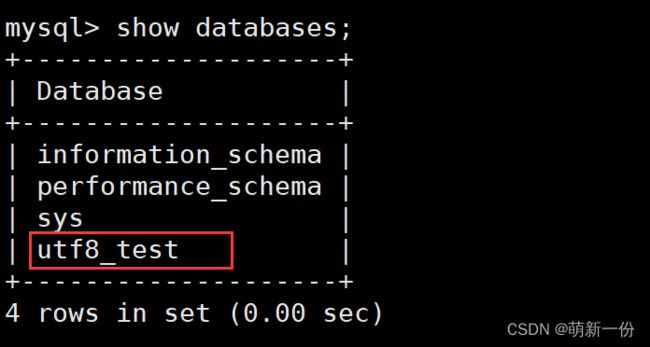
查看数据库:
show databases;
show create database 数据库名; 可以带上 \G 查看更详细内容
 这里没带;
这里没带;
说明:
MySQL 建议我们关键字使用大写,但是不是必须的。
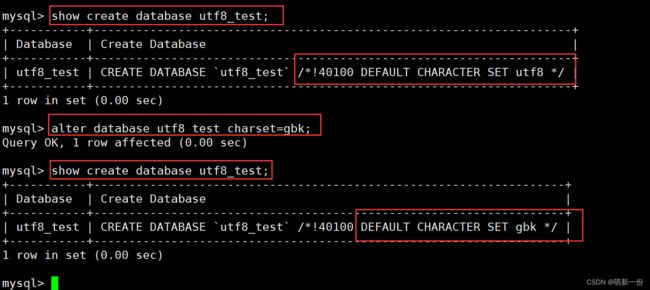
修改数据库
最好不要改。
语法:
ALTER DATABASE db_name[alter_spacification [,alter_spacification]...]alter_spacification:[DEFAULT] CHARACTER SET charset_name[DEFAULT] COLLATE collation_name
DROP DATABASE [IF EXISTS] db_ name;
重启mysqld:配置文件:/etc/my.cnf ,配置好需要重启
service mysqld restart;
system clear; 其他操作 system ls等 需要带system
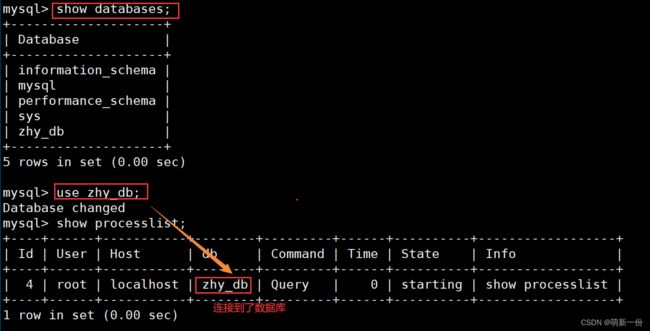
show processlist

3.表的操作
CREATE TABLE table_name (field1 datatype,field2 datatype,field3 datatype) character set 字符集 collate 校验规则 engine 存储引擎 ;
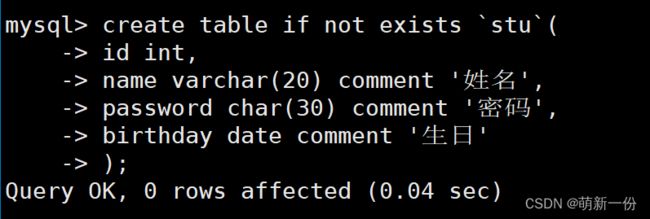
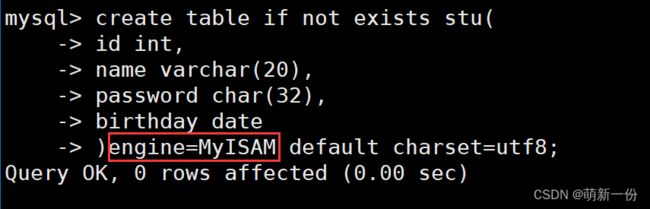
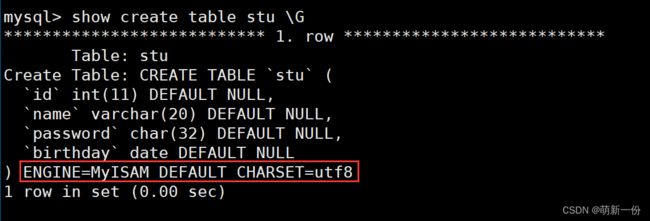
create table users (id int ,name varchar ( 20 ) comment ' 用户名 ' ,password char ( 32 ) comment ' 密码是 32 位的 md5 值 ' ,birthday date comment ' 生日 ') character set utf8 engine MyISAM;

使用该库,再创建表:
comment相当于是说明,没有实际的意义,仅仅说明
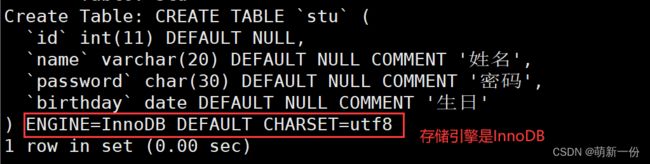
默认存储引擎就是InnoDB
 发现在对应的库目录下,多了两个文件
发现在对应的库目录下,多了两个文件
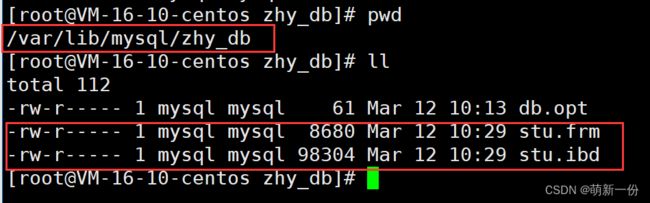
删除该表:

再创建一个存储引擎是:MyISAM
 查看对应的目录下:
查看对应的目录下:
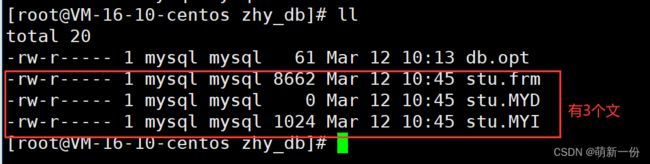
不同的存储引擎,创建表的文件不一样。stu 表存储引擎是 MyISAM ,在数据目中有三个不同的文件,分别是:stu.frm :表结构stu.MYD :表数据stu.MYI :表索引
如果表没有明确这些格式,默认和库的opt一样,或者和my.cnf中设置的格式一样。
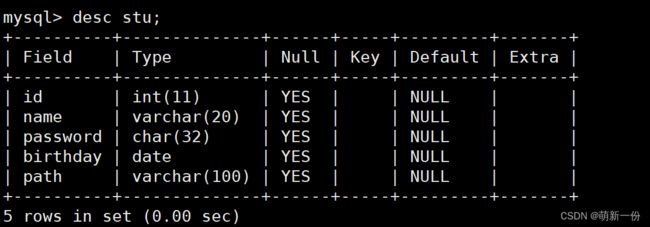
desc 表名 ;
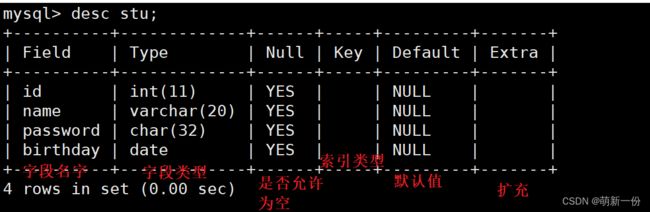
修改表
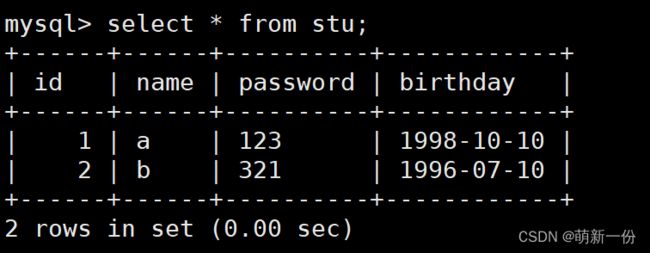
还是不建议修改,在建表之前一定要商量好表的结构等等,尽量不要修改。
在项目实际开发中,修改某个表的结构,比如字段名字,字段大小,字段类型,表的字符集类型,表的存储引擎等等。我们还有需求,添加字段,删除字段等等。这时我们就需要修改表。

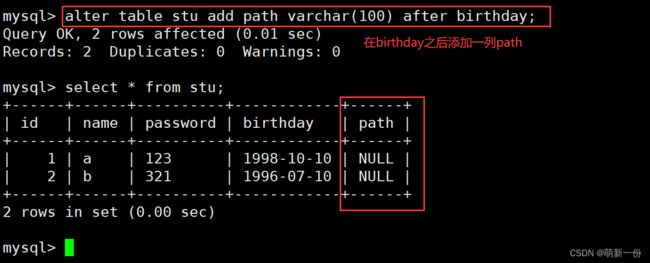
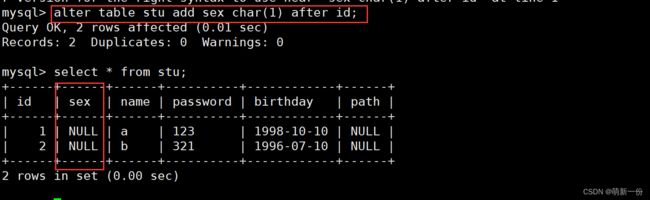
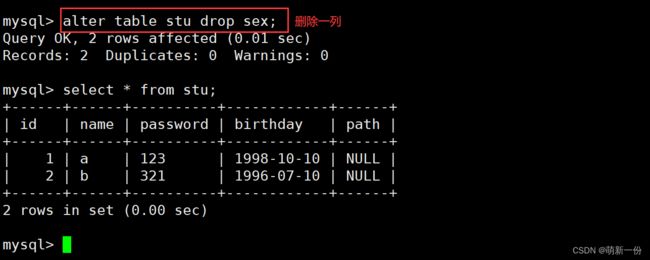
在id之后添加一列: 不建议这样,建议默认的在最后面插入,因为这样会改变原来表中列的顺序,导致上层逻辑可能出现问题,本来id后边是name,现在变成了sex。
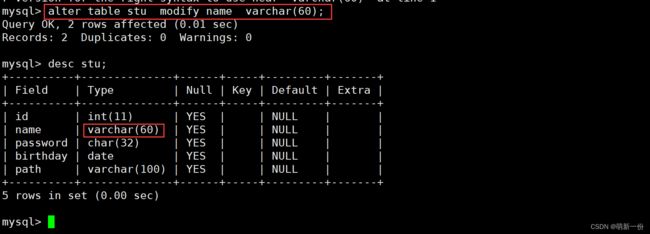
修改name,将其长度改成60
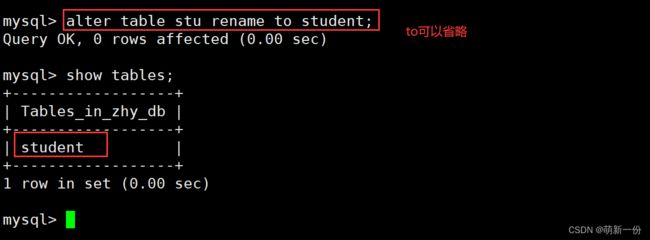
修改表的名字:
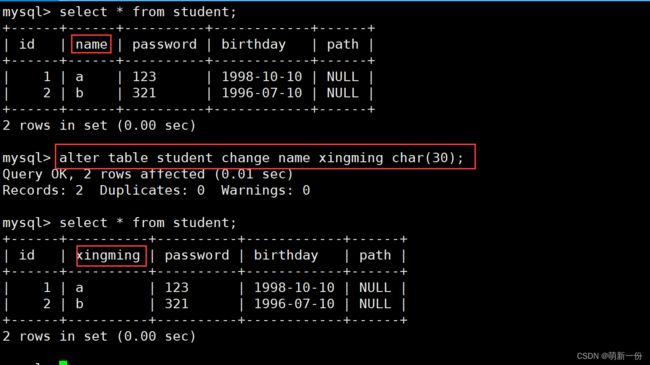
将name列修改为xingming,

DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ...drop table t1;