Python 爬虫---初窥门径
: 原出处
入门爬虫小实例。
本次实验先爬一个豆瓣电影top250的小页面。–得到250个电影的名称。麻雀虽小,五脏俱全。从这一个小小的例子中领略爬虫原理。
要爬寻得网址: 豆瓣/top250
编写爬虫之前,我们需要先思考爬虫需要干什么,目标网站有什么特点,以及根据目标网站的数据数量和数据结构特点选择合适的架构。
- F12 查看页面信息
- 右键单击某一电影–>查看元素
都可以得到相应的信息。:
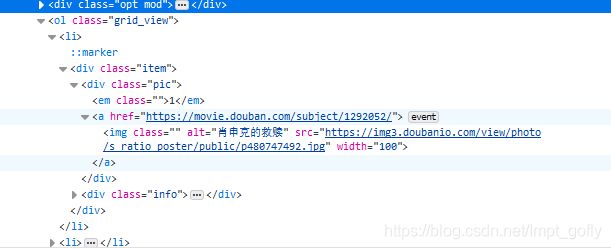
---->
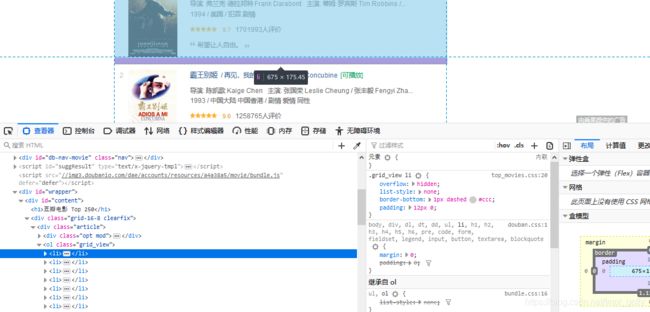
得到的信息有:
- 每页有25个电影;一共10页。
- 电影列表在页面上的位置为一个class为grid_view的ol标签中
- 每条电影信息放在这个ol标签中的li标签中
至此,可以编写代码了。
#需要导入requests库
import requests
#要爬取得页面
DOWNLOAD_URL = 'https://movie.douban.com/top250'
def download_page(url):
"""
下载一个网页的文本;并返回这个文本内容
:arg: 需要下载得网址
:return: 该网页得文本内容
"""
#用requests发送一个get请求,并获取其中的文本内容
data = requests.get(url).content
return data
def main():
#调用download_page函数,并将其返回结果打印。
print(download_page(DOWNLOAD_URL))
if __name__ == '__main__':
main()
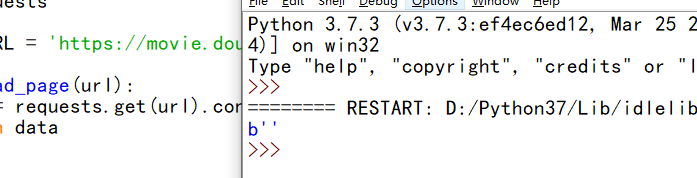
发现得到的结果不是我们想要的;一般,浏览器在向服务器发送请求的时候,会有一个请求头—User_Agent,它用来标识浏览器的类型。 当我们用requests来发送请求的时候,默认的User_Agent是python-requests/3.7.1。应该被服务器人为是爬虫而不返还信息。我们试试伪装这个请求头。
#需要导入requests库
import requests
#要爬取得页面
DOWNLOAD_URL = 'https://movie.douban.com/top250'
def download_page(url):
"""
下载一个网页的文本;并返回这个文本内容
:arg: 需要下载得网址
:return: 该网页得文本内容
"""
#伪装的请求头
headers = {
'User-Agent' :
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0'
}
#用requests发送一个get请求,并伪装请求头,并获取其中的文本内容
data = requests.get(url, headers = headers).content
return data
def main():
#调用download_page函数,并将其返回结果打印。
print(download_page(DOWNLOAD_URL))
if __name__ == '__main__':
main()
上面我们把自己浏览器的请求头加入到get请求中。
请求头的获取方法:F12在网络这一栏中的请求信息中。

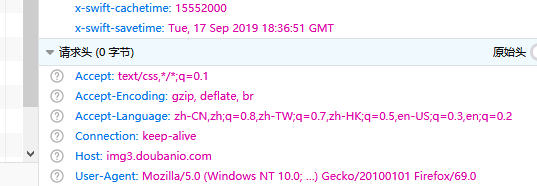
上面代码中,伪装请求头之后,再次访问就得到了真实网页的源码。服务器通过请求的U-A来识别爬虫,这算是最简单的一种反爬虫机制了。
当我们拿到源码之后,需要解析HTML源码了。
我们使用BeautifulSoup来搞定这件事。(requests与beautifulsoup4都属于第三方库,需要下载。)
from bs4 import BeautifulSoup
def parse_html(html):
soup = BeautifulSoup(html)
movie_list_soup = soup.find('ol', attrs = {'class' : 'grid_view'})
for movie_li in movie_list_soup.find_all('li'):
detail = movie_li.find('div', attrs = {'class' : 'hd'})
movie_name = detail.find('span', attrs = {'class' : 'title'}).getText()
print(movie_name)
这段代码干的事情:先用import导入BeautifulSoup;然后定义了解析函数parse_html,它接收html源码作为参数,将电影名称打印。然后我们创建了一个BeautifulSoup对象(缺少参数,会产生一个警告。不过无关紧要);然后用刚刚创建的对象搜索这个html文档中class为grid_view的ol标签(即存放电影的那个ol)。这个时候已经从整个html文档中将标签为ol的整个内容存放到了movie_list_soup变量中,然后用find_all()方法得到’li’的集合,通过迭代把每个li标签中class为hd的div标签内容存放到detail变量中,这个div标签中的class为title的span标签中的文本保存到movie_name变量。(对于for循环其实就是解析每个li标签,它的结构可以通过查看器获得。)
至此,我们已经得到了这一页中所有的电影名称。
import requests
from bs4 import BeautifulSoup
DOWNLOAD_URL = 'https://movie.douban.com/top250'
def download_page(url):
headers = {
'User-Agent' :
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0'
}
data = requests.get(url, headers = headers).content
return data
def parse_html(html):
soup = BeautifulSoup(html)
movie_list_soup = soup.find('ol', attrs = {'class' : 'grid_view'})
for movie_li in movie_list_soup.find_all('li'):
detail = movie_li.find('div', attrs = {'class' : 'hd'})
movie_name = detail.find('span', attrs = {'class' : 'title'}).getText()
print(movie_name)
def main():
html = download_page(DOWNLOAD_URL)
print(parse_html(html))
if __name__ == '__main__':
main()

但是一共有10页内容,怎么处理翻页问题呢?我们可以让它找到页码导航中的下一页的链接。:

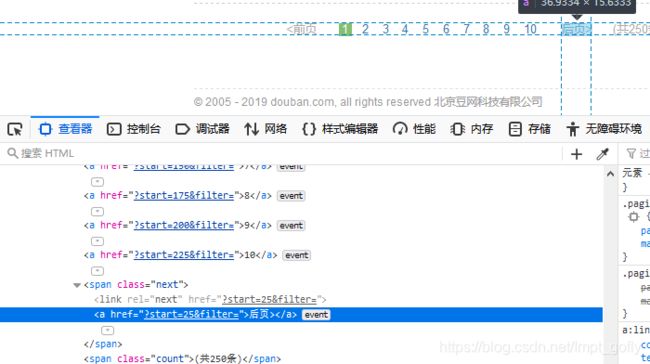
我们找到下一页的链接放置在一个span标签中,这个标签的class为next,具体链接在这个span标签的a标签中,但是到了最后一页后,这个span中的a标签消失了,不需要再翻页了。根据这段逻辑,我们可以对parse_html稍作修改。:
def parse_html(html):
soup = BeautifulSoup(html)
movie_list_soup = soup.find('ol', attrs = {'class' : 'grid_view'})
#用来存放全部页面的电影名称
movie_name_list = []
for movie_li in movie_list_soup.find_all('li'):
detail = movie_li.find('div', attrs = {'class' : 'hd'})
movie_name = detail.find('span', attrs = {'class' : 'title'}).getText()
#将每个电影名称添加到列表中
movie_name_list.append(movie_name)
#找到span标签中下一页的a标签内容
next_page = soup.find('span', attrs = {'class' : 'next'}).find('a')
if next_page:
"""如果不到最后一页的话,就返回已经存储过的列表,并将下一页a链接中的链接地址添加到D_URL之后返回"""
return movie_name_list, DOWNLOAD_URL + next_page['href']
return movie_name_list, None
至此,大部分代码已经完成,我们将其组成一个完整的程序即可。
import codecs
def main():
url = DOWNLOAD_URL
with codecs.open('movies_name_list', 'wb', encoding = 'utf-8') as fobj:
while url:
html = download_page(url)
movies, url = parse_html(html)
fobj.write(u'{movies}\n'.format(movies = '\n'.join(movies)))
以上代码完成了对代码的拼装,并将结果输出到一个文件中,使用codecs包是为了更方便处理中文编码。
小结:
这篇文章总结了最简单的反爬虫机制,以及简单的BeautifulSoup的使用,最后完成了将结果写入到文件中。麻雀虽小,五脏俱全,程序虽然简单,但却算是一个完整的爬虫程序了。
完整代码如下:
import codecs
import requests
from bs4 import BeautifulSoup
DOWNLOAD_URL = 'https://movie.douban.com/top250'
def download_page(url):
headers = {
'User-Agent' :
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0'
}
return requests.get(url , headers = headers).content
def parse_html(html):
soup = BeautifulSoup(html)
movie_list_soup = soup.find('ol', attrs = {'class' : 'grid_view'})
movie_name_list = []
for movie_li in movie_list_soup.find_all('li'):
details = movie_li.find('div', attrs = {'class' : 'hd'})
movie_name = details.find('span', attrs = {'class' : 'title'}).getText()
movie_name_list.append(movie_name)
next_page = soup.find('span', attrs = {'class' : 'next'}).find('a')
if next_page:
return movie_name_list, DOWNLOAD_URL + next_page['href']
return movie_name_list, None
def main():
url = DOWNLOAD_URL
with codecs.open('movies', 'wb', encoding = 'utf-8') as fobj:
while url:
html = download_page(url)
movies, url = parse_html(html)
fobj.write(u'{movies}\n'.format(movies='\n'.join(movies)))
if __name__ == '__main__':
main()
运行完之后,可在此文件路径下找到一个文件:movies。