Kafka分布式流处理平台基础概念学习
kafka学习官网:https://kafka.apachecn.org/intro.html
kafka的架构和基础概念

5个部分组成:
-
topic是对数据记录和分类的地方,包括key value 和一个timestamp
-
数据库DB是数据库,Connector是连接数据库 将数据写入到Kafka集群系统。
-
producer是可以产生数据的应用程序,将数据产生存储写到topic中
-
consumer是消费者 读取topic里面的数据
-
stream数据处理器,可以处理topic里面的数据
消息的传递是订阅者模式,消费者组会订阅某个生产者的信息。
topic结构
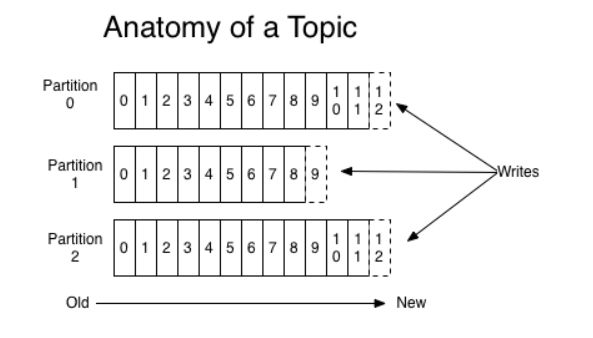
每个topic对数据进行划分,对应有一个分区日志,每个分区叫做partition,每个partition里面每条记录都有一个序号用来标记,这个序号叫offset。
每条记录可通过设置保留期参数,保留数据存储的时间。
分区是没有顺序的,只有每个分区partition内数据是有序的。
生产者发布数据道topic的partition是顺序的,比如M1和M2记录由相同生产者产生,M1先发送的话,存储在partition中的offset偏移量也会更小。
kafka的分布式
分区日志分布在kafka集群服务器上,每个服务器处理数据请求时都会共享分区。日志还会被存储在多个服务器上确保容错性。
集群服务器通过zookeeper来管理,使用leader-follwer方式来管理,确保多个服务器之间数据的一致性。leader处理一切数据的读写请求,follwer被动同步leader数据。
当leader宕机,某个follwer会自动成为leader。
生产者Producer
生产者producer可以将数据分配到所有的topic主题中,还负责将数据分配到topic的哪一个分区partition中。
消费者Consumer
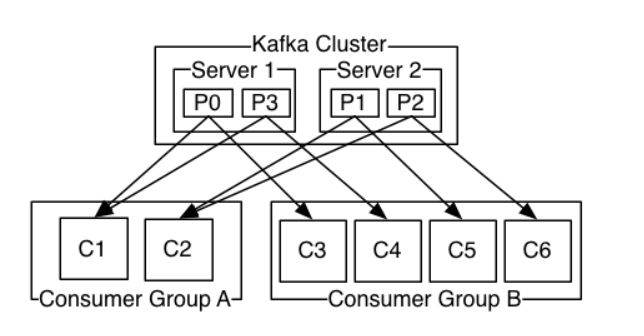
消费者通过消费者组名 对消费者划分。发布给topic中的每条记录会被订阅给消费者组中某个消费者实例。
所有消费者在一个消费者组,消息记录会负载均衡到每个消费者。
所有消费者在不同消费组,每条消息记录会广播道所有消费组。
Kafka相比传统消息系统的优势
传统的消息系统(队列方式):
优点:队列 方式。允许将队列中的数据处理过程分给不同的消费者实例,可以有效拓展处理。
缺点:队列不是多订阅者模式,一旦某个进程读取了数据,数据会丢失,其他进程读取不了数据。
Kafka作为消息系统:
优点:队列方式+发布订阅模式 结合。
队列模式,允许将数据处理过程给 消费组中所有的消费者实例。
发布订阅模式:允许将数据广播给所有消费组。
kafka中的topic中partition是并行的概念,每个分区partition都有一个消费者实例来读取数据,这样保证了多个消费者实例的负载均衡。消费者的实例不能多于topic中的分区数量。

Kafka作为存储系统
Kafka是一种高性能、低延迟、具备日志存储、备份和传播功能的分布式文件系统。
生产者发布数据写到topic,写入的是磁盘,采用磁盘的结构写入,因此不管是500GB和50TB都是一样的,具有很好的拓展性。
写数据并且有备份,直到备份完成,才会被认为数据写入完成。
写入失败会确保继续写入。
Kafka作为流处理
kafak作为一个分布式流处理平台,最大的特性就是流处理。
流处理器Stream可以不断读取输入的topic数据,经过流处理之后,再写数据到topic。

Kafka与HDFS分布式文件系统对比
HDFS是分布式存储静态文件的,用于存储历史数据。
传统的消息系统处理订阅后到达的数据或者将要到达的数据。
Kafka结合了两种特性,作为流数据管道以及流应用程序。