Python函数(从入门到进阶)
Python函数(从入门到进阶)
- 一、函数的概念
- 二、函数的定义及调用
-
- 1. 函数的定义
- 2. 函数的调用
-
- 1) 调用方式
- 2)参数的传递方式
- 3)返回值
- 三、函数的执行环境
-
- 四、函数的参数
-
- 1. 常规参数
- 2. 可变长参数
- 3. KeyWord-only参数
- 4. 默认参数
- 5. 参数的高级调用方式
- 6. 总结
- 五、函数的高级话题
-
- 1. 匿名函数
- 2. 递归函数
-
- 1)基本概念
- 2)尾递归
- 3. 其他
-
- 1)函数对象
- 2)函数注释
一、函数的概念
函数本质上就是一段具有指定功能、可以反复使用的代码段, 它是对代码段的一个抽象,如果说变量是对值的抽象,那函数就是对代码段的抽象,比如下面一段代码:
#判断n是否为素数
n=413
for i in range(2, int(n**0.5)+1):
if n%i == 0:
print('{}不是素数!'.format(n))
break
else:
print('{}是素数!'.format(n))
这段代码有一个独立的功能:判断n是素数,我们希望重用这段代码,于是定义了一个函数,你可以理解成给这段代码取了个名字isPrime, 于是当我们在程序中使用isPrime()时就相当于在程序中复制了如上的代码段
def is_prime():
n=413
for i in range(2, int(n**0.5)+1):
if n%i == 0:
print('{}不是素数!'.format(n))
break
else:
print('{}是素数!'.format(n))
显然,上面的函数功能太单一,他永远只能判断n=413时的情况,为了让上面的代码更灵活,于是我们对代码中的一些变量进行了抽象,抽象成了函数的参数
def is_prime(n):
for i in range(2, int(n**0.5)+1):
if n%i == 0:
print('{}不是素数!'.format(n))
break
else:
print('{}是素数!'.format(n))
至此,isPrime(n)这个函数具备了判断一个数n是否为质数的功能,你需要判断某个数时,只需要在使用函数的时候,传入相应的值就可以了,比如想判断13483是否是质数,只需要调用isPrime(13483)即可。
当然这样提炼的函数还是不够好,稍后会提到。
当在实际项目开发中,函数的定义显得格外重要,我们在定义函数时,一般要遵循如下的一些原则,当然,这需要经验的积累,而不是一蹴而就的事。
函数要遵守的基本原则:
-
函数名,望文生义
-
独立性、通用性,设计良好的函数,应超越当前开发的程序
-
聚合性,函数的目标应尽量单一
-
函数代码不要过长,过长时,考虑拆分
函数的作用非常重要,这里简单的归纳几点,当然,它们的这些作用需要你在实际的开发过程中才能完全体会。
函数的意义:
- 代码重用、缩短程序
- 结构清晰、便于维护
- 分解问题、分工合作
二、函数的定义及调用
1. 函数的定义
下面整体看一下函数的定义语法
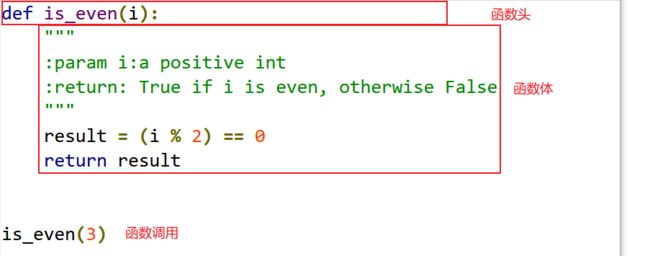
函数包括函数头和函数体两部分:
- 函数头
- 内容:包含定义函数的关键字
def、函数名is_even、参数列表(i)- 函数名按标识符的规则命名,应简短而有意义
- 如果有多个参数,参数之间用逗号
,隔开,比如有参数i和j,则参数列表写成(i,j) - 如果函数没有参数,空括号不能省
()
- 书写规范:函数头以冒号
:结尾
- 内容:包含定义函数的关键字
- 函数体
- 内容:包含文档字符串和函数功能代码
- 文档字符串在初学习阶段可以不用写,但在实际项目开发中是必不可少的内容。
- 函数的返回值使用
return语句返回,无return语句时,返回默认值None - 定义空函数时,函数体可以使用
pass语句占位
- 书写规范:函数体需要有缩进
- 内容:包含文档字符串和函数功能代码
注意:函数定义后,要调用函数才会执行,函数的定义只是定义了一个功能,要让其代码运行,必须要对函数进行调用
附:文档字符串的格式约定如下:
一般以三引号开始和结束
第一行是函数的简要描述
接下来是详情和示例
查看方式:函数的
__doc__属性, 比如想查看print函数的文档字符串,可以在python交互界面打印print函数的__doc__属性print(print.__doc__)print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) Prints the values to a stream, or to sys.stdout by default. Optional keyword arguments: file: a file-like object (stream); defaults to the current sys.stdout. sep: string inserted between values, default a space. end: string appended after the last value, default a newline. flush: whether to forcibly flush the stream.`
2. 函数的调用
字义函数后只是定义了一个功能,当需要使用这个功能时就需要调用该函数。
1) 调用方式
- 有参函数的调用:
函数名(参数1,参数2,...), 例如:pow(2,10) - 无参函数的调用:
函数名(), 例如:dir()。特别注意,函数没有参数时,圆括号也不能省
2)参数的传递方式
函数在调用过程中,参数的传递方式是按引用传递
示例1:

函数add有两个参数,x,y分别是1,2的引用, 当调用add函数时,此时相当于把a,b分别指向了1,2, 此时1的引用有两个:x和a; 2的引用有两个:y和b
示例2:
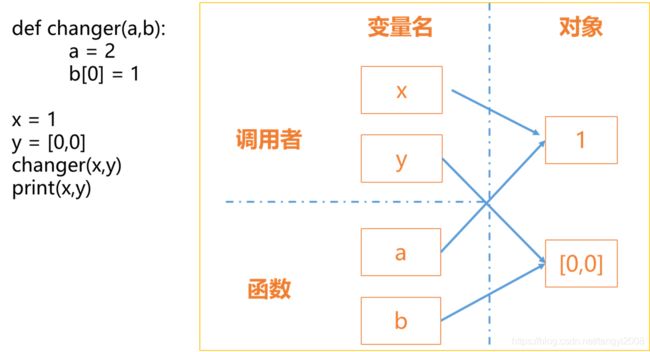
先来看一下上面代码运行的结果
1 [1, 0]
会发现x还是1,但是y的值发生了变化,如果理解了这个代码,也就理解了什么是按引用传递参数,下面简单解释一下:
- 当传递x,y到函数changer时,实际上相当于把a指向了1,把b指向了[0,0]
- 当运行a=2时,实际相当于将a重新指向了2,x还是指向的1,所以x不会发生变化
- 当运行b[0] = 1时,相当于把b指向的列表[0,0]的第一个元素修改为1了,注意,这时y还是指向的是同一个列表,当然y的值就发生了变化。
3)返回值
调用函数后得到的值叫函数的返回值,对有return返回的函数,调用的值为return语句后面的表达式值,无return返回值的函数返回None
注意:避免对函数名赋值, 如果不小心对内置函数名赋值,可以
del该函数名,将其恢复print = 2 del print print('hello')
三、函数的执行环境
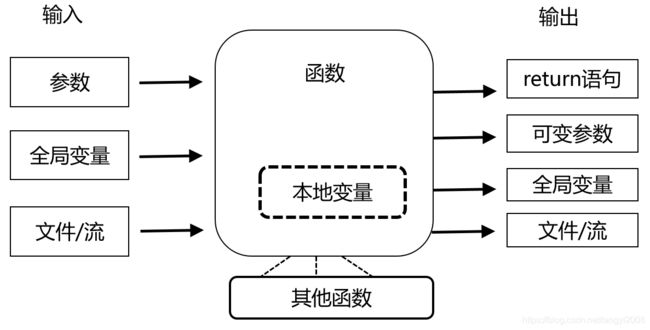
函数的整个执行环境包括函数的输入、函数体、输出
- 输入在通常意义上是使用参数的形式,但实际上全局变量、文件/流等也可以说是函数的一种输入方式
- 输出在通常意义上指的是使用return返回的值,但实际上对可变参数、全局变量的修改以及以文件或者流的方式输出都是函数的一种输出方式
函数的副作用,指除返回值外,函数以其他任何方式所做的修改,比如:
- 打印
- 写文件
- 下载网页
- 对全局变量的修改
- 对可变参数的修改
- …
会发现我们前面定义的is_primer是有副作用的,这里给出一个更好的改进
def is_prime(n): ''' 判断整数n是否为素数 :param n: 要判断的整数 :return: 当是素数时返回True,不是素数时返回False ''' result = True for i in range(2, int(n ** 0.5) + 1): if n % i == 0: result = False break return result # 调用时 n = int(input('请输入要判断的数字:')) if is_prime(n): print('{}是素数!'.format(n)) else: print('{}不是素数!'.format(n))
四、函数的参数
Python中函数的参数有很多的形式,对初学者来说,掌握起来还是比较困难的,尤其是每本书上对参数的叫法可能还不一样,要不想被它困扰,唯一的办法就是理解它。
其实参数的各种名称都不重要,但要能相互沟通,又不得不给他取个名字。这里我先给出Python中各个参数的名称,然后具体讲解各个的用法和定义,最后讲一下各种定义形式如何综合应用。
-
函数定义时参数的称呼:
-
常规参数
-
可变长参数
-
包裹(packing)位置参数
- 包裹(packing)关键字参数
-
KeyWord-only参数
-
默认参数
-
-
函数调用时参数的传递方式:
- 按位置传递, 调用函数时只传入参数的值,与形参的对应关系按位置来确定
- 按关键字传递,调用函数时,传入了参数的名称和值,与形参的对应关系按参数名确定
接下来分别讲解各个形式的参数如何定义,以及调用时的注意事项
1. 常规参数
- 定义: 常规参数在定义时没有其他特殊的修饰形式,比如前面示例中的参数就是常规形式
def greet(name, greeting):
print(greeting, name + '!')
-
调用:常规参数的调用形式可以按关键值传递,也可以按位置传递
-
按位置传递
-
参数根据定义时的位置进行传递
-
参数的顺序必须一一对应,且参数个数要一致
greet('Bob', 'Good afternoon') #将打印 Good afternoon Bob! greet('Bob') #报TypeError错误,TypeError: greet() missing 1 required positional argument: 'greeting' greet('Bob', 'Good afternoon', 'hi') #报TypeError错误,TypeError: greet() takes 2 positional arguments but 3 were given
-
-
按关键字传递
- 调用时,根据形式参数的名称来指示为哪个形式参数传递什么值
- 好处:函数参数传递更加清晰、容易使用
- 有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序
-
greet(greeting='Good afternoon', name='Bob') #打印Good afternoon Bob!
greet('Bob', greeting='Good afternoon') #打印Good afternoon Bob!
greet(name='Bob', 'Good afternoon') #报SyntaxError错误,SyntaxError: positional argument follows keyword argument
2. 可变长参数
在定义函数时不确定调用的时候会传递多少个参数,那根据调用方式的不同,不确定个数的参数可能带有关键字,也可以没带关键字:
- 如果调用时不确定个数的参数不带关键字的,我们定义时称为包裹位置参数。反之,如果定义的是包裹位置参数,那么在调用时只能按位置方式传递参数
- 如果调用时不确定个数的参数都带有关键字的,我们定义时称为包裹关键字参数。反之,如果定义的是包裹关键字参数,那么在调用时只能按关键字方式传递参数
接下来我们来分别看一下两种形式的参数如果定义及调用
-
包裹位置参数
-
定义形式:
*identifier -
调用时,传进去的所有位置参数被
args收集,合并成一个元组def fun(*args): print('类型:',type(args), '值:', args) fun() # 将打印: 类型:值: () fun(1) # 将打印: 类型:值: (1, ) fun('a',1) # 将打印: 类型:值: ('a', 1)
-
-
包裹关键字参数
-
定义形式:
**identifier -
调用时,传进去的所有关键字参数被
kargs收集,合并成一个字典def kfunc(**kargs): print('类型:',type(kargs), '值:', kargs) kfunc() #打印: 类型:值: {} kfunc(a=1, b=2, c=3) #打印: 类型:值: {'a': 1, 'b': 2, 'c': 3}
-
3. KeyWord-only参数
如果我们定义一个函数,要求调用者必须以指定的关键字来传递参数时,我们称为KeyWord-only参数。
- 定义:Keyword-only参数出现在包裹位置参数后面,如果没有包裹位置参数,可以在其前单用一个
*的无名参数 - 调用:参数必须用带有关键参数的名字来传递
def fun(*, a,b):
pass
def fun_1(x,*args,a,b):
pass
fun(1) #报TypeError错误: TypeError:fun() takes 0 positional arguments but 1 was given
fun(a=1,b=2)
fun(b=2,a=1)
fun_1(1,a=1,b=2)
fun_1(1,2,3,b=2,a=1)
4. 默认参数
-
定义函数时,为参数提供默认值
-
调用时,可传可不传该默认参数的值
-
默认值参数的位置
- 对常规参数,带有默认值的参数必须出现在没有默认值参数的后面
# 调用时,greeting的参数可传可不传 def greet(name, greeting='Hello'): print(greeting, name + '!') #下面这种方式定义会报语法错误,SyntaxError: non-default argument follows default argument def greet(name='Bob', greeting): print(greeting, name + '!')- 对KeyWord-Only参数,可以任意赋默认值,不受顺序影响,以下两种方式的默认值参数都是可以的。
def fun(*,a=1,b): pass def fun_1(x,*args,a=1,b): pass -
当且仅当默认参数所在的
def语句执行的时候,默认参数才会进行计算def fun( tmpl=[]): tmpl.append(1) print(id(tmpl),tmpl) #id()函数返回一个对象的唯一标识 fun() # 1680845413448 [1] fun() # 1680845413448 [1, 1]会发现调用两次fun()后,id值都是同一个,这就是我们说默认参数只在def语句执行时进行过计算
这样的话,第一次调用函数时,tmpl指向一个空列表,第二次调用时,tmpl指向的列表已经追加了一个1,所以会以[1]的基础上再追加一个1变成了[1,1]
5. 参数的高级调用方式
针对前面讲的可变长参数,当我们想要将一个元组的所有值传递给一个包裹位置参数,或者想要将一个字典的所有值传递给一个包裹关键字参数时怎么做呢?下面就给出一个简便方法:
*和**,也可以在函数调用的时候使用,称之为解包裹(unpacking)- 传递元组时,让元组的每一个元素对应一个位置参数,实际上,传递的不一定是一个元组,只要是可迭代对象都可以
- 传递字典时,让字典的每个键值对作为一个关键字参数传递给函数
def func(*args):
print(args)
def kfunc(**kargs):
print(kargs)
func(*(1,2)) # (1, 2)
func(*range(10)) # (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
func(*'hello') # ('h', 'e', 'l', 'l', 'o')
kfunc(**{'a':1, 'b':2}) # {'a': 1, 'b': 2}
6. 总结
在实际应用中,会有多种参数形式同时出现的情况,这里对前面的参数做一次总结:
- 先后顺序:常规参数,包裹位置,Keyword-only参数,包裹关键字
- 调用时,位置参数应该在关键字参数前面
*位置参数,可接受任意数量的位置参数(元组)- Keyword-only参数只能以关键字形式调用
**关键字参数,可接受任意数量的关键字参数(字典)- 常规参数的默认值参数应该在没有默认值参数的后面
- Keyword-only参数的默认值没有顺序要求
- 默认参数的赋值只会在函数定义的时候绑定一次,默认值不会再被修改,所以默认值不要使用可变对象
五、函数的高级话题
1. 匿名函数
在python中,除了使用def关键字定义函数外,还有一种使用lambda关键字定义的匿名函数。这种函数可以用在任何普通函数可以使用的地方,但在定义时被严格限定为单一表达式(不能是语句块),匿名函数的返回值即为该表达式所返回的对象。
基本语法
lambda arg1,arg2,...argn: expression using arguments
如果想定义两个数的加法,按def方式定义如下:
def add(x,y):
return x+y
如果写成匿名函数形式,可以写成lambda x,y: x + y。显然,当写成lambda表达式后,代码会更加的优雅。
匿名函数同样支持默认参数,请看如下示例代码
>>>(lambda x, y: x + y)(3,4)
>>>func = lambda x, y=4: x + y
>>>func(3)
lambda可以省去定义函数的过程,让代码更加精简,而且不用考虑命名问题,但是在PEP8规范里面是不推荐用lambda这种方式的。
2. 递归函数
1)基本概念
递归函数是一种程序设计的技术:函数调用自身, 即定义的函数体内调用被定义的函数自身。
示例1:数字列表求和
m y s u m ( L ) = { 0 当 L 为空列表时 L [ 0 ] + m y s u m ( L [ 1 : ] ) 当 L 不为空时 mysum(L)= \begin {cases} 0 & \text当L为空列表时 \\ L[0] + mysum(L[1:]) & \text当L不为空时 \end{cases} mysum(L)={0L[0]+mysum(L[1:])当L为空列表时当L不为空时
可定义递归函数为:
def mysum(L):
if not L:
return 0
else:
return L[0] + mysum(L[1:])
示例2:Fibonacci数列
F_0 = 0
F_1 = 1
...
F_n = F_(n-1) + F_(n-2) 当n>1时
可定义递归函数为:
def fib(n):
if n < 1:
return 0
if n == 1:
return 1
return fib(n-1) + fib(n-2)
注意:上面定义的函数在调用时参数不要超过40,否则会运行很长很长时间,或者抛异常
下面请看fib(5)的运行情况:
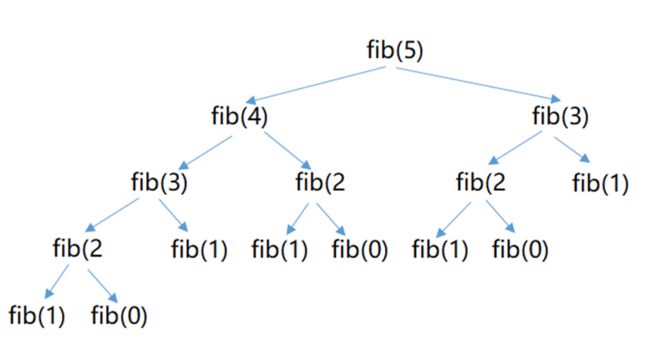
如何改进呢?
改进1,换成循环方式定义
def fib_iter(n): f1,f2 = 0,1 for i in range(n): f1,f2 = f2,f1+f2 return f1改进2,改成尾递归方式:
def fib_x(n,_k=1,_f1=0,_f2=1): if _k > n: return _f1 else: return fib_x(n, _k+1, _f2, _f1+_f2)可以自行对比
fib、fib_x和fib_iter运行速度
示例3:Hanoi塔问题
Hanoi塔问题是一个经典的递归案例,该问题的描述如下:
相传印度有座大寺庙,它曾被认为是宇宙的中心。神庙中放置了一块上面插有三根长木钉的木板,在其中的一根木钉上,由上至下放了64片直径由小至大的圆环形金属片。古印度教的天神指示他的僧侣们将64片金属片全部移至另一根木钉上。移动规则只有两个:
1.在每次的移动中,只能移动一片金属片
2.过程中任意时刻必须保证金属片小的在上,大的在下
直到有那么一天,僧侣们能将64片金属片按规则从指定的木钉上全部移至另一根木钉上,那么,世界末日即随之来到,世间的一切终将被毁灭,万物都将至极乐世界。

求解问题的思路如下:
假设有A、B、C三个柱子,所有金属片在A柱子上,现在借助于B柱子将A上的所有金属片移动到C上
-
如果只有一个金属片,直接将金属片从A移动到C
-
如果多于一个金属片,假设为n片时
- 首先将n-1片金属片借助于C柱子从A移动到B
- 然后将剩下的一个金属片从A移动到C
- 再将n-1片金属片先借助于A柱子从B移动到C
围绕上面的思路,可以完成如下的代码,以打印移动过程 :
def towers(n, A, B, C):
if n == 1:
print_move(A, C)
else:
towers(n-1, A, C, B)
towers(1, A, B, C)
towers(n-1, B, A, C)
2)尾递归
尾递归要求递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分,要提高递归的性能,尾递归是必须掌握的内容。在一些编程语言中,所有的循环都采用递归的方式进行,而没有循环语句,比如Erlang
在上面的Fibonacci数列求解中,fib_x函数的定义就是采用的尾递归思想。
需要注意的是,在Python中使用尾递归可以提高代码的性能,但是Python未对尾递归进行优化,运行如下代码:
fib_x(1000)
会报错RecursionError: maximum recursion depth exceeded in comparison,这是因为Python中为了防止栈溢出,对递归层数作了限制,可通过sys.getrecursionlimit()获取最大递归层;通过sys.setrecursionlimit()设置最大递归层(前提是要确定不会产生栈溢出)
在程序运行中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小是有限的,所以,递归调用的次数过多,会导致栈溢出。
对尾递归而言,一旦进入下一次递归调用,其实原函数的相关环境便失去了意义,所谓的尾递归优化,其实就是在调用下一层递归时,回收掉原函数的栈空间,这样的话,尾递归优化的运行便类似于循环。
3. 其他
1)函数对象
在Python中,处处皆对象,函数也是一个对象,所以可以将函数间接调用、查看函数属性、给函数添加属性等。
-
将函数对象赋值给变量,然后调用改变量
x = print; x(‘hello world’) -
将函数作为参数传入其他函数
#将abs函数传入map函数,对列表的每个元素求绝对值 map(abs, [-1,-2,2]) -
将函数作为返回值返回
import time def sta_time(fun): def i_fun(): start_time = time.time() fun() print(time.time() - start_time) return i_fun -
查看函数属性
dir(print) -
给函数添加属性
def func(): pass func.count = 1 print(func.count)
2)函数注释
在Python3.x中,增加了一个新特性–函数注释(Function Annotations), 即为函数添加额外的注释
函数注释的作用是提高代码的可读性,暗示传入参数及返回值的类型及相关说明,关于函数注释的详细说明参见PEP-3107
函数注释包括:
-
参数注释:以冒号
:标记,建议传入的参数类型或者其它相关说明 -
返回值注释:以
->标记,建议函数返回的类型或者其它相关说明
函数注释的语法如下:
def fun(a: expression, b:expression = 5) -> expression:
pass
函数注释示例:
def my_sum(a: int, b: int, c: 'The default value is 0' = 0) -> 'int: return the sum of a,b,c':
return a + b + c
函数注释可通过函数的__annotations__属性查看
print(my_sum.__annotations__)
注意:
当注释内容有多个时,可以使用元组、列表、字典等作为注释内容,比如函数
my_sum,对参数c而言,即想说明其默认值是0,又想说明其类型为int,则可以定义成:def my_sum(a: int, b: int, c: {'type':int, 'default':0} = 0) -> 'int: return the sum of a,b,c': return a + b + c函数注释只是一种说明,而非强制,比如上面定义的函数
my_sum,按注释说明,参数a,b,c都要是int类型,但在调用时,你完全可以按如下方式调用函数,结果将输入ABCprint(my_sum('A','B','C'))