Deformable DETR模型学习记录
引言
Deformable-DETR的主要贡献:
1,结合可变形卷积的稀疏空间采用和Transformer的全局关系建模能力,提出可变形注意力机制模型,使其计算量降低,收敛加快。
2,使用多层级特征,但不使用FPN,对小目标有较好效果。
改进与创新
可变形注意力
可变形注意力提出的初衷是为了解决Transformer的Q,K的运算数据量巨大问题。作者认为Q没必要与所有的K都计算内积,而是只需要选择几个重要的K即可。
如下图,在该论文中,作者设定找4个K即可,而4个K的位置可以不断进行偏移,偏移过程如下图所示:
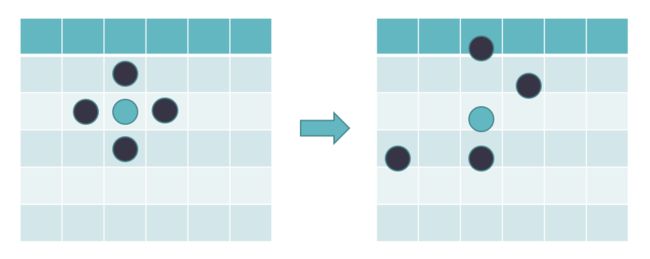
因此要解决的问题就是:(1)确定reference point(参考点)。(2)确定每个reference point的偏移量(offset)。(3)确定注意力权重矩阵 Amqk,其中在Encoder和Decoder中实现方法不太一样。Deformable的计算方式如下:
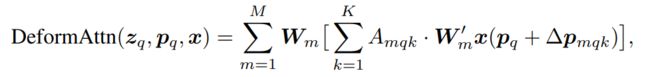
在Encoder部分,输入的Query Feature ( zq )为加入了位置编码的特征图(src+pos), value(x)的计算方法只使用了src而没有位置编码(value_proj函数)。
- reference point确定方法为用了torch.meshgrid方法,调用函数 get_reference_points,有一个细节就是参考点归一化到0和1之间,因此取值的时候要用到双线性插值的方法。而在Decoder中,参考点的获取方法为object queries通过一个nn.Linear得到每个对应的reference point。
def get_reference_points(spatial_shapes, valid_ratios, device):
reference_points_list = []
for lvl, (H_, W_) in enumerate(spatial_shapes):
# 从0.5到H-0.5采样H个点,W同理 这个操作的目的也就是为了特征图的对齐
ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H_ - 0.5, H_, dtype=torch.float32, device=device),
torch.linspace(0.5, W_ - 0.5, W_, dtype=torch.float32, device=device))
ref_y = ref_y.reshape(-1)[None] / (valid_ratios[:, None, lvl, 1] * H_)
ref_x = ref_x.reshape(-1)[None] / (valid_ratios[:, None, lvl, 0] * W_)
ref = torch.stack((ref_x, ref_y), -1)
reference_points_list.append(ref)
reference_points = torch.cat(reference_points_list, 1)
reference_points = reference_points[:, :, None] * valid_ratios[:, None]
return reference_points
(2)计算offset的方法为对 zq 过一个nn.Linear,得到多组偏移量,每组偏移量的维度为参考点的个数,组数为注意力头的数量。
(3)计算注意力权重矩阵 Amqk 的方法为 zq 过一个nn.Linear和一个F.softmax,得到每个头的注意力权重。
如下图所示:

如上图所示:分头计算完的注意力最终会拼接到一起,然后最后过一个nn.Linear得到输入x 的最终输出。
多层级特征融合(Multi-Scale Deformable Attention Module)

多尺度的Deformable Attention模块也是在多尺度特征图上计算的。多尺度的特征融合方法则是取了骨干网(ResNet)最后三层的特征图C3,C4,C5,并且用了一个Conv3x3 Stride2的卷积得到了一个C6构成了四层特征图。随后会通过卷积操作将通道数量统一为256(也就是token的数量),然后在这四个特征图上运行Deformable Attention Module并且进行直接相加得到最终输出。其中
Deformable Attention Module算子的pytorch实现如下:
def ms_deform_attn_core_pytorch(value, value_spatial_shapes, sampling_locations, attention_weights):
# for debug and test only,
# need to use cuda version instead
N_, S_, M_, D_ = value.shape # batch size, number token, number head, head dims
# Lq_: number query, L_: level number, P_: sampling number采样点数
_, Lq_, M_, L_, P_, _ = sampling_locations.shape
# 按照level划分value
value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes], dim=1)
# [0, 1] -> [-1, 1] 因为要满足F.grid_sample的输入要求
sampling_grids = 2 * sampling_locations - 1
sampling_value_list = []
for lid_, (H_, W_) in enumerate(value_spatial_shapes):
# N_, H_*W_, M_, D_ -> N_, H_*W_, M_*D_ -> N_, M_*D_, H_*W_ -> N_*M_, D_, H_, W_
value_l_ = value_list[lid_].flatten(2).transpose(1, 2).reshape(N_*M_, D_, H_, W_)
# N_, Lq_, M_, P_, 2 -> N_, M_, Lq_, P_, 2 -> N_*M_, Lq_, P_, 2
sampling_grid_l_ = sampling_grids[:, :, :, lid_].transpose(1, 2).flatten(0, 1)
# N_*M_, D_, Lq_, P_
# 用双线性插值从feature map上获取value,因为mask的原因越界所以要zeros的方法进行填充
sampling_value_l_ = F.grid_sample(value_l_, sampling_grid_l_,
mode='bilinear', padding_mode='zeros', align_corners=False)
sampling_value_list.append(sampling_value_l_)
# (N_, Lq_, M_, L_, P_) -> (N_, M_, Lq_, L_, P_) -> (N_, M_, 1, Lq_, L_*P_)
attention_weights = attention_weights.transpose(1, 2).reshape(N_*M_, 1, Lq_, L_*P_)
# 不同scale计算出的multi head attention 进行相加,返回output后还需要过一个Linear层
output = (torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights).sum(-1).view(N_, M_*D_, Lq_)
return output.transpose(1, 2).contiguous()
Two-Stage Deformable DETR
这里的两阶段是受two-stage object detectors的启发,当然这里的改动其实很小:将Encoder输出的memory送入了FFN(前馈神经网络负责类别预测与box预测)将其进行修正后再送入Decoder。
其他改进
其他方面,Deformable相较于DETR修改了query-num的数量,改为300,但在推理过程中其会仍使用top100的预测框,此外在匈牙利匹配的cost矩阵构建时class的损失由原本的softmax简单运算变为了Focus loss。
模型结构
Encoder
Encoder加入了参考点计算,,此外改动了DerormableAttention计算。
class DeformableTransformerEncoderLayer(nn.Module):
def __init__(self,
d_model=256, d_ffn=1024,
dropout=0.1, activation="relu",
n_levels=4, n_heads=8, n_points=4):
super().__init__()
# self attention
self.self_attn = MSDeformAttn(d_model, n_levels, n_heads, n_points)
self.dropout1 = nn.Dropout(dropout)
self.norm1 = nn.LayerNorm(d_model)
# ffn
self.linear1 = nn.Linear(d_model, d_ffn)
self.activation = _get_activation_fn(activation)
self.dropout2 = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ffn, d_model)
self.dropout3 = nn.Dropout(dropout)
self.norm2 = nn.LayerNorm(d_model)
@staticmethod
def with_pos_embed(tensor, pos):
return tensor if pos is None else tensor + pos
def forward_ffn(self, src):
src2 = self.linear2(self.dropout2(self.activation(self.linear1(src))))
src = src + self.dropout3(src2)
src = self.norm2(src)
return src
def forward(self, src, pos, reference_points, spatial_shapes, level_start_index, padding_mask=None):
# self attention
src2 = self.self_attn(self.with_pos_embed(src, pos), reference_points, src, spatial_shapes, level_start_index, padding_mask)
src = src + self.dropout1(src2)
src = self.norm1(src)
# ffn
src = self.forward_ffn(src)
return src
class DeformableTransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
@staticmethod
def get_reference_points(spatial_shapes, valid_ratios, device):
reference_points_list = []
for lvl, (H_, W_) in enumerate(spatial_shapes):
# 从0.5到H-0.5采样H个点,W同理 这个操作的目的也就是为了特征图的对齐
ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H_ - 0.5, H_, dtype=torch.float32, device=device),
torch.linspace(0.5, W_ - 0.5, W_, dtype=torch.float32, device=device))
ref_y = ref_y.reshape(-1)[None] / (valid_ratios[:, None, lvl, 1] * H_)
ref_x = ref_x.reshape(-1)[None] / (valid_ratios[:, None, lvl, 0] * W_)
ref = torch.stack((ref_x, ref_y), -1)
reference_points_list.append(ref)
reference_points = torch.cat(reference_points_list, 1)
reference_points = reference_points[:, :, None] * valid_ratios[:, None]
return reference_points
def forward(self, src, spatial_shapes, level_start_index, valid_ratios, pos=None, padding_mask=None):
output = src
reference_points = self.get_reference_points(spatial_shapes, valid_ratios, device=src.device)
for _, layer in enumerate(self.layers):
output = layer(output, pos, reference_points, spatial_shapes, level_start_index, padding_mask)
return output
Decoder
详细代码注释如下,这里要控制是否使用iterative bounding box refinement和two stage技巧。iterative bounding box refinement其实就是对参考点的位置进行微调。two stage方法其实就是通过参考点直接生成anchor但是只取最高置信度的前几个,然后再送入decoder进行调整。intermediate数组是一个trick,每层Decoder都是可以输出bbox和分类信息的,如果都利用起来算损失则成为auxiliary loss。
class DeformableTransformerDecoderLayer(nn.Module):
def __init__(self, d_model=256, d_ffn=1024,
dropout=0.1, activation="relu",
n_levels=4, n_heads=8, n_points=4):
super().__init__()
# cross attention
self.cross_attn = MSDeformAttn(d_model, n_levels, n_heads, n_points)
self.dropout1 = nn.Dropout(dropout)
self.norm1 = nn.LayerNorm(d_model)
# self attention
self.self_attn = nn.MultiheadAttention(d_model, n_heads, dropout=dropout)
self.dropout2 = nn.Dropout(dropout)
self.norm2 = nn.LayerNorm(d_model)
# ffn
self.linear1 = nn.Linear(d_model, d_ffn)
self.activation = _get_activation_fn(activation)
self.dropout3 = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ffn, d_model)
self.dropout4 = nn.Dropout(dropout)
self.norm3 = nn.LayerNorm(d_model)
@staticmethod
def with_pos_embed(tensor, pos):
return tensor if pos is None else tensor + pos
def forward_ffn(self, tgt):
tgt2 = self.linear2(self.dropout3(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout4(tgt2)
tgt = self.norm3(tgt)
return tgt
def forward(self, tgt, query_pos, reference_points, src, src_spatial_shapes, level_start_index, src_padding_mask=None):
# self attention
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q.transpose(0, 1), k.transpose(0, 1), tgt.transpose(0, 1))[0].transpose(0, 1)
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
# cross attention
tgt2 = self.cross_attn(self.with_pos_embed(tgt, query_pos),
reference_points,
src, src_spatial_shapes, level_start_index, src_padding_mask)
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# ffn
tgt = self.forward_ffn(tgt)
return tgt
class DeformableTransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, return_intermediate=False):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.return_intermediate = return_intermediate
# hack implementation for iterative bounding box refinement and two-stage Deformable DETR
self.bbox_embed = None
self.class_embed = None
def forward(self, tgt, reference_points, src, src_spatial_shapes, src_level_start_index, src_valid_ratios,
query_pos=None, src_padding_mask=None):
output = tgt
# 用来存储中间decoder输出的 可以考虑是否用auxiliary loss
intermediate = []
intermediate_reference_points = []
for lid, layer in enumerate(self.layers):
if reference_points.shape[-1] == 4:
reference_points_input = reference_points[:, :, None] \
* torch.cat([src_valid_ratios, src_valid_ratios], -1)[:, None]
else:
assert reference_points.shape[-1] == 2
reference_points_input = reference_points[:, :, None] * src_valid_ratios[:, None]
output = layer(output, query_pos, reference_points_input, src, src_spatial_shapes, src_level_start_index, src_padding_mask)
# hack implementation for iterative bounding box refinement
# iterative refinement是对decoder中的参考点进行微调,类似cascade rcnn思想
if self.bbox_embed is not None:
tmp = self.bbox_embed[lid](output)
if reference_points.shape[-1] == 4:
new_reference_points = tmp + inverse_sigmoid(reference_points)
new_reference_points = new_reference_points.sigmoid()
else:
assert reference_points.shape[-1] == 2
new_reference_points = tmp
new_reference_points[..., :2] = tmp[..., :2] + inverse_sigmoid(reference_points)
new_reference_points = new_reference_points.sigmoid()
reference_points = new_reference_points.detach()
if self.return_intermediate:
intermediate.append(output)
intermediate_reference_points.append(reference_points)
if self.return_intermediate:
return torch.stack(intermediate), torch.stack(intermediate_reference_points)
return output, reference_points
Deformable Transformer
class DeformableTransformer(nn.Module):
def __init__(self, d_model=256, nhead=8,
num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=1024, dropout=0.1,
activation="relu", return_intermediate_dec=False,
num_feature_levels=4, dec_n_points=4, enc_n_points=4,
two_stage=False, two_stage_num_proposals=300):
super().__init__()
self.d_model = d_model
self.nhead = nhead
self.two_stage = two_stage
self.two_stage_num_proposals = two_stage_num_proposals
encoder_layer = DeformableTransformerEncoderLayer(d_model, dim_feedforward,
dropout, activation,
num_feature_levels, nhead, enc_n_points)
self.encoder = DeformableTransformerEncoder(encoder_layer, num_encoder_layers)
decoder_layer = DeformableTransformerDecoderLayer(d_model, dim_feedforward,
dropout, activation,
num_feature_levels, nhead, dec_n_points)
self.decoder = DeformableTransformerDecoder(decoder_layer, num_decoder_layers, return_intermediate_dec)
self.level_embed = nn.Parameter(torch.Tensor(num_feature_levels, d_model))
if two_stage:
self.enc_output = nn.Linear(d_model, d_model)
self.enc_output_norm = nn.LayerNorm(d_model)
self.pos_trans = nn.Linear(d_model * 2, d_model * 2)
self.pos_trans_norm = nn.LayerNorm(d_model * 2)
else:
self.reference_points = nn.Linear(d_model, 2)
self._reset_parameters()
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
for m in self.modules():
if isinstance(m, MSDeformAttn):
m._reset_parameters()
if not self.two_stage:
xavier_uniform_(self.reference_points.weight.data, gain=1.0)
constant_(self.reference_points.bias.data, 0.)
normal_(self.level_embed)
def get_proposal_pos_embed(self, proposals):
num_pos_feats = 128
temperature = 10000
scale = 2 * math.pi
dim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=proposals.device)
dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)
# N, L, 4
proposals = proposals.sigmoid() * scale
# N, L, 4, 128
pos = proposals[:, :, :, None] / dim_t
# N, L, 4, 64, 2
pos = torch.stack((pos[:, :, :, 0::2].sin(), pos[:, :, :, 1::2].cos()), dim=4).flatten(2)
return pos
def gen_encoder_output_proposals(self, memory, memory_padding_mask, spatial_shapes):
N_, S_, C_ = memory.shape
base_scale = 4.0
proposals = []
_cur = 0
for lvl, (H_, W_) in enumerate(spatial_shapes):
mask_flatten_ = memory_padding_mask[:, _cur:(_cur + H_ * W_)].view(N_, H_, W_, 1)
valid_H = torch.sum(~mask_flatten_[:, :, 0, 0], 1)
valid_W = torch.sum(~mask_flatten_[:, 0, :, 0], 1)
grid_y, grid_x = torch.meshgrid(torch.linspace(0, H_ - 1, H_, dtype=torch.float32, device=memory.device),
torch.linspace(0, W_ - 1, W_, dtype=torch.float32, device=memory.device))
grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1)
scale = torch.cat([valid_W.unsqueeze(-1), valid_H.unsqueeze(-1)], 1).view(N_, 1, 1, 2)
grid = (grid.unsqueeze(0).expand(N_, -1, -1, -1) + 0.5) / scale
wh = torch.ones_like(grid) * 0.05 * (2.0 ** lvl)
proposal = torch.cat((grid, wh), -1).view(N_, -1, 4)
proposals.append(proposal)
_cur += (H_ * W_)
output_proposals = torch.cat(proposals, 1)
output_proposals_valid = ((output_proposals > 0.01) & (output_proposals < 0.99)).all(-1, keepdim=True)
output_proposals = torch.log(output_proposals / (1 - output_proposals))
output_proposals = output_proposals.masked_fill(memory_padding_mask.unsqueeze(-1), float('inf'))
output_proposals = output_proposals.masked_fill(~output_proposals_valid, float('inf'))
output_memory = memory
output_memory = output_memory.masked_fill(memory_padding_mask.unsqueeze(-1), float(0))
output_memory = output_memory.masked_fill(~output_proposals_valid, float(0))
output_memory = self.enc_output_norm(self.enc_output(output_memory))
return output_memory, output_proposals
def get_valid_ratio(self, mask):
_, H, W = mask.shape
valid_H = torch.sum(~mask[:, :, 0], 1)
valid_W = torch.sum(~mask[:, 0, :], 1)
valid_ratio_h = valid_H.float() / H
valid_ratio_w = valid_W.float() / W
valid_ratio = torch.stack([valid_ratio_w, valid_ratio_h], -1)
return valid_ratio
def forward(self, srcs, masks, pos_embeds, query_embed=None):
assert self.two_stage or query_embed is not None
# prepare input for encoder
src_flatten = []
mask_flatten = []
lvl_pos_embed_flatten = []
spatial_shapes = []
for lvl, (src, mask, pos_embed) in enumerate(zip(srcs, masks, pos_embeds)):
# 得到每一层feature map的batch size 通道数量 高宽
bs, c, h, w = src.shape
spatial_shape = (h, w)
spatial_shapes.append(spatial_shape)
# 将每层的feature map、mask、位置编码拉平,并且加入到相关数组中
src = src.flatten(2).transpose(1, 2)
mask = mask.flatten(1)
pos_embed = pos_embed.flatten(2).transpose(1, 2)
# 位置编码和可学习的每层编码相加,表征类似 3D position
lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)
lvl_pos_embed_flatten.append(lvl_pos_embed)
src_flatten.append(src)
mask_flatten.append(mask)
# 在hidden_dim维度上进行拼接,也就是number token数量一样的那个维度
src_flatten = torch.cat(src_flatten, 1)
mask_flatten = torch.cat(mask_flatten, 1)
lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
spatial_shapes = torch.as_tensor(spatial_shapes, dtype=torch.long, device=src_flatten.device)
# 记录每个level开始的索引以及有效的长宽(因为有mask存在,raw image的分辨率可能不统一) 具体查看get_valid_ratio函数
# prod(1)计算h*w,cumsum(0)计算前缀和
level_start_index = torch.cat((spatial_shapes.new_zeros((1, )), spatial_shapes.prod(1).cumsum(0)[:-1]))
valid_ratios = torch.stack([self.get_valid_ratio(m) for m in masks], 1)
# encoder
memory = self.encoder(src_flatten, spatial_shapes, level_start_index, valid_ratios, lvl_pos_embed_flatten, mask_flatten)
# prepare input for decoder
bs, _, c = memory.shape
# 是否使用两阶段模式
if self.two_stage:
output_memory, output_proposals = self.gen_encoder_output_proposals(memory, mask_flatten, spatial_shapes)
# hack implementation for two-stage Deformable DETR
enc_outputs_class = self.decoder.class_embed[self.decoder.num_layers](output_memory)
enc_outputs_coord_unact = self.decoder.bbox_embed[self.decoder.num_layers](output_memory) + output_proposals
topk = self.two_stage_num_proposals
topk_proposals = torch.topk(enc_outputs_class[..., 0], topk, dim=1)[1]
topk_coords_unact = torch.gather(enc_outputs_coord_unact, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, 4))
topk_coords_unact = topk_coords_unact.detach()
reference_points = topk_coords_unact.sigmoid()
init_reference_out = reference_points
pos_trans_out = self.pos_trans_norm(self.pos_trans(self.get_proposal_pos_embed(topk_coords_unact)))
query_embed, tgt = torch.split(pos_trans_out, c, dim=2)
else:
# 这是非双阶段版本的Deformable DETR
# 将query_embed划分为query_embed和tgt两部分
query_embed, tgt = torch.split(query_embed, c, dim=1)
# 复制bs份
query_embed = query_embed.unsqueeze(0).expand(bs, -1, -1)
tgt = tgt.unsqueeze(0).expand(bs, -1, -1)
# nn.Linear得到每个object queries对应的reference point, 这是decoder参考点的方法!!!
reference_points = self.reference_points(query_embed).sigmoid()
init_reference_out = reference_points
# decoder
hs, inter_references = self.decoder(tgt, reference_points, memory,
spatial_shapes, level_start_index, valid_ratios, query_embed, mask_flatten)
inter_references_out = inter_references
if self.two_stage:
return hs, init_reference_out, inter_references_out, enc_outputs_class, enc_outputs_coord_unact
return hs, init_reference_out, inter_references_out, None, None
Deformable DETR效率高并且收敛快,核心是Multi-Scale Deformable Attention Module。解决了DETR中收敛慢以及小目标性能低的问题。