SegFormer程序调试记录
环境配置
首先是cuda环境配置:
conda create -n seg python=3.8
随后激活环境:
source activate seg
pytorch安装
安装pytorch版本,博主使用的是pytorch1.7.0
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch
执行完上面的安装命令在运行时会报错,这是由于pytorch与cuda版本不符造成的,可以使用下面的pip方式安装,因此这里安装pytorch时建议使用pip的方式安装(但这种方法安装很慢),否则会报如下错误:
libcublas.so.11: symbol free_gemm_select version libcublasLt.so.11 not
defined in file libcublasLt.so.11 with link time reference
pip install torch==1.7.0+cu110 torchvision==0.8.0+cu110 torchaudio==0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
但这种方法下载实在是太过缓慢了,但博主发现在本地下载whl文件后在上传到服务器上速度更快:
这个服务器也不知是怎么了,可能是由于广州的原因,先前使用硅谷的服务器时速度就很快。
下载完成后我们直接执行安装whl命令:
pip install torch-1.7.0+cu110-cp38-cp38-linux_x86_64.whl
mmcv安装
根据pytorch版本与python版本确定mmcv-full版本:
pip install mmcv-full==1.2.7 -f https://download.openmmlab.com/mmcv/dist/cu110/torch1.7.0/index.html
其他依赖安装
随后切换到segformer目录下执行安装requirement.txt中指定的依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
然后就是一些没有在requirement中指定的依赖安装:
pip install IPython
pip install timm
安装完成后继续配置,注意一定要在segformer目录下
pip install -e . --user
权重文件下载
此时基本已经完成环境配置过程,下载一个权重文件进行简单测试
权重文件
博主下载的是这个:

代码调试
简单demo(推理)
随后进入demo文件夹,修改下配置文件
from argparse import ArgumentParser
from mmseg.apis import inference_segmentor, init_segmentor, show_result_pyplot
from mmseg.core.evaluation import get_palette
def main():
parser = ArgumentParser()
parser.add_argument('--img', default="/data/programs/SegFormer-master/demo/demo.png", help='Image file')
parser.add_argument('--config',
default="/data/programs/SegFormer-master/local_configs/segformer/B1/segformer.b1.512x512.ade.160k.py",
help='Config file')
parser.add_argument('--checkpoint', default="segformer.b1.512x512.ade.160k.pth", help='Checkpoint file')
parser.add_argument(
'--device', default='cuda:0', help='Device used for inference')
parser.add_argument(
'--palette',
default='cityscapes',
help='Color palette used for segmentation map')
args = parser.parse_args()
# build the model from a config file and a checkpoint file
model = init_segmentor(args.config, args.checkpoint, device=args.device)
# test a single image
result = inference_segmentor(model, args.img)
# show the results
show_result_pyplot(model, args.img, result)
if __name__ == '__main__':
main()
输出结果如下:
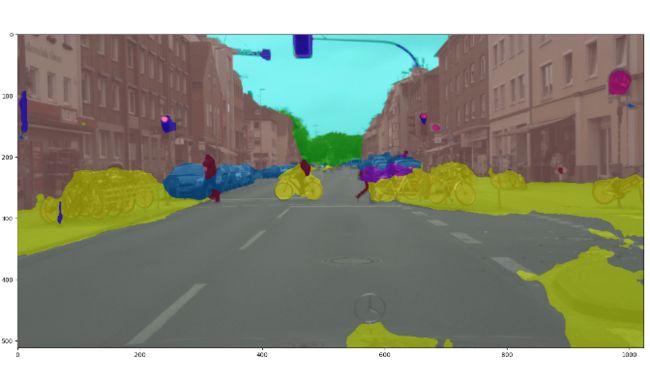
测试过程
随后运行test.py文件,修改配置参数:
parser.add_argument('--config', default="/data/programs/SegFormer-master/local_configs/segformer/B1/segformer.b1.512x512.ade.160k.py",help='test config file path')
parser.add_argument('--checkpoint',default="/data/programs/SegFormer-master/demo/segformer.b1.512x512.ade.160k.pth", help='checkpoint file')
随后修改local_configs/base中datasets的路径:


随后将所需的数据集放到指定位置即可。需要注意的是,该项目中使用的数据集默认是DEChallengeData2016,我们也要尽量使用该数据集,毕竟更换数据集要比修改数据集读取文件更容易
ADEChallengeData2016
annotation
training(存放所有训练标签png图片)
validation(存放所有验证标签png图片)
images
training(存放所有训练jpg图片)
validation(存放所有验证jpg图片)

训练过程
训练过程如法炮制,首先修改train.py文件的配置
parser.add_argument('--config', default="/data/programs/SegFormer-master/local_configs/segformer/B1/segformer.b1.512x512.ade.160k.py",help='train config file path')
parser.add_argument('--work-dir',default='/data/programs/SegFormer-master/work_dir/logs', help='the dir to save logs and models')
然后在根目录下新建pretrained文件夹,并将下载的权重放入:
权重文件
修改下权重文件地址:

随后运行时报错,这是由于分分布式训练采用了分布式训练设置导致的
AssertionError: Default process group is not initialized
在train.py中添加如下代码:
import torch.distributed as dist
dist.init_process_group('gloo', init_method='file:///tmp/somefile', rank=0, world_size=1)
或者找到这段代码,将type改为BN即可,但博主试过失败了
norm_cfg = dict(type='BN', requires_grad=True)

修改完成后开启训练:
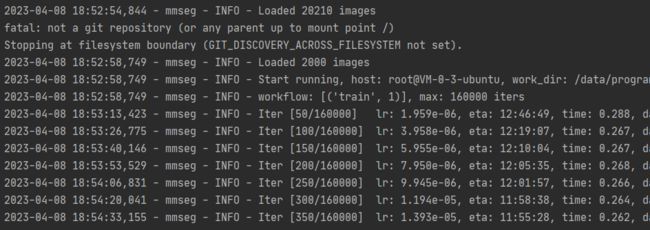
此时的GPU使用率很低:

我们尝试修改batch-size,发现该项目中并没有指定batch-size,而是设计每张gpu的图片数,其实这也就相当于是batch-size
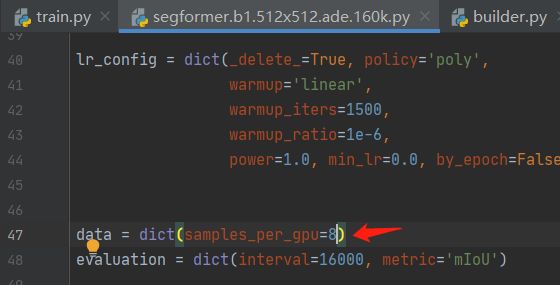
将其修改为8后,GPU占用情况:
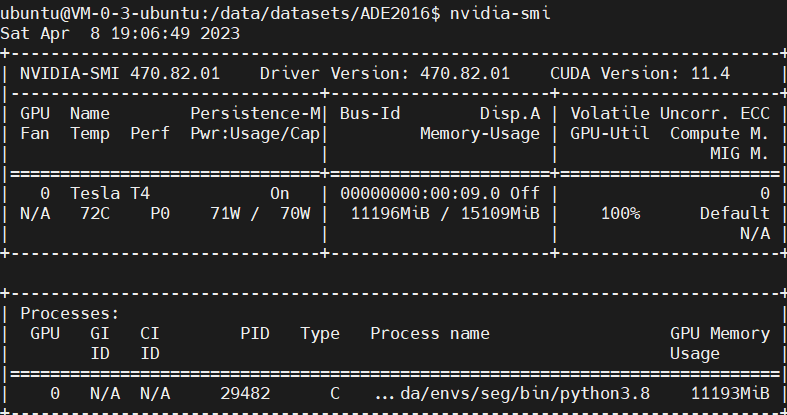
至此,便慢慢等着其训练吧。