数据结构【C语言版】六千字长文带你了解!堆增删查改,应用,及其时间复杂度的计算
文章目录
-
- 1.二叉树的概念
- 2.特殊二叉树
- 3.二叉树的性质
- 堆的概念:
-
- 1.堆的性质
-
- 堆的难点!
- 2.堆的结构
- 3.堆的初始化
- 4.堆的插入
-
- 向上调整算法的时间复杂度
- 5.堆的创建
-
- 从上面的堆的插入可以看出如果我们将第一个逻辑结构为完全二叉树的数组,一个个进行堆的插入到另一个数组中,这样子就可以创建出一个堆出来!
- 6.堆的判空
- 7.取堆顶的值!
- 8.堆的销毁
- 9.堆的删除
- 10.建堆的时间复杂度
- 11.堆的应用
-
- 1.堆排序
- 分为两步
- 2.topk问题
1.二叉树的概念
1.一棵二叉树是结点的一个有限集合该集合:
2.或者为空 ,由一个根节点加上两棵别称为左子树和右子树的二叉树组成

-
由图可知二叉树的每个节点的度不超过2
-
二叉树分为左子树和右子树,二叉树是有序树
任意的二叉树都由基本的几个情况复合而来

2.特殊二叉树
满二叉树:一个二叉树,如果每个层的结点数达到最大值那么这就是一个满二叉树。
也就是说如果一个树k层的话,这个树有2k-1个结点数,那么这就是满二叉树
完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K 的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对 应时称之为完全二叉树。满二叉树是一种特殊的完全二叉树
完全二叉树的节点都要是连续的!

这就是一颗完全二叉树!每个结点都是联系的!

这就不是一颗完全二叉树因为结点不连续!
完全二叉树是钱k-1层是满的,最后K层不一定满所以节点的数量为==[2k-1,2k-1]==
关于二叉树的层数,有的是从0开始,有的是从1开始,一般都是从1开始,这样子空树就规定为0,若是从0开始,则空树就要规定为-1。
3.二叉树的性质
-
若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有2(i-1)个结点.
-
若规定根节点的层数为1,则深度为h的二叉树的最大结点数是 2h-1
-
对任何一棵二叉树, 如果度为0其叶结点个数为n0, 度为2的分支结点个数为n2,则有 n0= n2+1
这是一个很重要的性质!对于二叉树而言叶子节点的个数永远比度为2的节点的个数+1.
-
若规定根节点的层数为1,具有n个结点的满二叉树的深度,h= log2(n+1). (ps: 是log以2 为底,n+1为对数)
-
对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则对 于序号为i的结点有:
-
若i>0,i位置节点的双亲序号:(i-1)/2;i=0,i为根节点编号,无双亲节点
-
2i+1
2i+1>= n意味着超过了最大的序号数
-
2i+2
-
堆的概念:
如果有一个关键码的集合K = {k0 ,k1 ,k2 ,k3,…, kn-1},把它的所有元素按完全二叉树的顺序存储方式存储 在一个一维数组中,并满足:Ki <= K2*i+1且 Ki<=K2*i+2 (Ki >=K2*i+1 且 Ki>= K2*i+2) i = 0,1, 2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
1.堆的性质
- 堆中的某个节点的值总是不大于或者不小于父节点的值(大堆或者小堆)
- 堆总是一颗完全二叉树
堆的难点!

堆的逻辑结构和堆的物理存储结构是完全不一样的!操作的是数组,但是表示出来的却是二叉树!
2.堆的结构
typedef int HPdataType;
typedef struct Heap
{
HPdataType* data;//堆的存储结构本质就是一个数组
int size;//用来表示数组内的元素的多少
int capacity;//用来表示数组的内存大小!
}//堆的结构与顺序表相同,但是因为操作方式的不同导致了堆与顺序表完全不同的性质!
堆的创建后面进行阐述,因为堆的创建有两种方式一种是将一个非堆的数组通过调整变成堆,另一种是通过数组插入的方式获得一个堆,两种的本质其实都是相同的!
3.堆的初始化
void HeapIint(Heap* php)//堆刚创建的堆进行初始化!
{
php->data = NULL;
php->size = php->capacity = 0;
}
4.堆的插入
//堆插入的重点在于在插入后仍要保持堆的基本结构!保持大堆或者小堆!
//思路是先插入到最后面,然后进行向上调整算法
typedef int HPdataType;
void AdjustUp(HPdataType* a,int child);
typedef struct Heap
{
HPdataType* data;
int size;
int capacity;
}
void HeapPush(Heap* php,HPdataType x)
{
assert(php);
if(php->size == php->capacity)//先检查容量是否足够!不够则进行扩容
{
int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;
HPdataType temp* = (HpdataType*)realloc(php->data,
sizeof(HPdataType)*newcapacity);
if(temp == NULL)//检查是否扩容成功!
{
perror("realloc fail!");
return;
}
php->data = temp;
php->capacity = newcapacity;
}
php->data[php->size++] = x;
AdjustUp(php->a,php->size-1);
//插入尾部,现在开始进行向上调整!将其调整为堆!
//传过去最后一个插入的数据的位置和数组
}
void swap(HPdataType* x,HPdataType* y)
{
HPdataType temp = *x;
*x = *y;
*y = temp;
}
void AdjustUp(HPdataType* a,int child)
{
int parent = (child-1) / 2;//找到父节点
while(child > 0)//child不用等于0因为,到0这个位置上面也就没有父节点了
{
if(a[child] > a[parent])//这里以大堆为例!
{ swap(&a[child],&a[parent]);
child = parent;
parent = (child -1)/2;
}
else
{
break;//遇到比child大的那么久跳出循环
}
}
//这里如果使用parent>0,那么因为子节点还在下一个位置,则无法调整根节点
//如果是parent>=0 因为parent =(0-1)/2 仍然为0,则就会出现死循环!
}
//向上调整算法的核心是对比父节点和子节点,如果是大堆,那么子节点大于父节点那么就进行互换位置
//如果是小堆那么则相反过来

向上调整算法的时间复杂度
为了方便计算我们以h层的满二叉树为例:
总结点数 N = 2h-1;
则 h = log2(N+1) ≈ logN;
所以向上调整算法的时间复杂度为logN。
5.堆的创建
从上面的堆的插入可以看出如果我们将第一个逻辑结构为完全二叉树的数组,一个个进行堆的插入到另一个数组中,这样子就可以创建出一个堆出来!
void HeapCreat(Heap* php,HPdataType* a,int size)
{
for(int i = 0;i < size;i++)
{
HeapPush(php->data,a[i]);
}
}
但是如果是这样的话有点浪费空间,如果我们将数组的值一个个进行向上调整算法,从第一个到最后一个,那么就可以直接将一个数组变成堆!
typedef int HPdataType;
typedef struct Heap
{
HPdataType* data;
int size;
int capacity;
}
HPdataTpye a[] = {10,2,6,8,1,6,87,12,68,44};
void void HeapCreat(HPdataType* a,int size)
{
for(int i = 0;i<size;i++)
{
AdjustUp(a,i);
}
}
6.堆的判空
bool HeapEmpty(Heap* php)
{
return php->size == 0 ? ture : false;
}
7.取堆顶的值!
int HeapTop(Heap* php)
{
assert(php);
assert(!eapEmpty(php));
return php->data[0];
}
8.堆的销毁
void HeapDestroy(Heap* php)
{
php->size = 0;
php->capacity = 0;
free(php->data);
php->a = NULL;//防止出野指针
}
9.堆的删除
堆的删除也与堆的插入一样要删除后仍保持堆的结构!
删除的难点在于,如何找到次大/次小的结点,然后将其移动到根节点的位置!
所以堆删除的真正意义在于找打次大/次小节点!
思路:将堆的根结点与最后一个节点互换位置,删除最后一个节点,然后将放在根节点,当做是一个新插入的节点,进行向下调整,最后重新获得一个新的堆!
向下调整算法的使用前提:左右子树必须同时都是大(小)堆,
typedef int HPdataType;
typedef struct Heap
{
HPdataType* data;
int size;
int capacity;
}
void AdjustDown(HPdataType* a,int size);
void swap(HPdataType* x,HPdataType* y)
{
HPdataType temp = *x;
*x = *y;
*y = temp;
}
void HeapPop(Heap* php)
{
assert(php);
assert(!Heapempty(php));//判断不是空堆!
swap(&php->data[0],&php->data[php->size-1]);
php->size--;//删除最后一个值
AdjustDown(php->data,0,php->size);//进行向下调整!
}
void AdjustDown(HPdataType* a,int parent,int size)
{
int child = parent*2+1;//默认是左孩子
while(child < size)//不可用parent
{
if(child +1 < size && a[child] < a[child+1])//这里仍然以大堆为例,首先找到最大的那个孩子
{
child++;
}
if(a[parent] < a[child])//比孩子还要小,进行互换
{
swap(&a[parent],&a[child]);
parent = child;
child = parent*2+1;
}
else
{
break;
}
}
}

我们此时又学习到了另一个调整算法,那么既然可用向上调整算法建堆,那么我们是否可用使用向下调整算法建堆呢?答案是可行的!但是这两种算法之间是否存在什么区别呢?那么就让我们先来了解一下建堆的时间复杂度吧!
10.建堆的时间复杂度
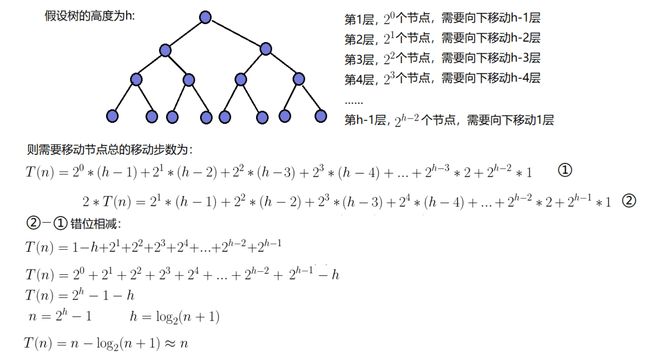
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的 就是近似值,多几个节点不影响最终结果):
而且我们可用看出假设假设树的高度为h,那么最后一层就会有2h-1个节点,而前h-1层的节点总数为
20+21+22+…+2h-2 = 2h-1-1
我们可以看出最后一层的节点数占了总节点数的1/2!
这个时候我们可以来看一下向下调整算法来建堆的代码
typedef int HPdataType;
typedef struct Heap
{
HPdataType* data;
int size;
int capacity;
}
void AdjustDown(HPdataType* a,int parent,int size)
{
int child = parent*2+1;
while(child < size)
{
if(child +1 < size && a[child] < a[child+1])
{
child++;
}
if(a[parent] < a[child])
{
swap(&a[parent],&a[child]);
parent = child;
child = parent*2+1;
}
else
{
break;
}
}
}
//这个建堆方法要求从最后一个非叶子节点开始!
void HeapCreat(HPdataType* a,int parent,int size)
{
for(int i = (size-1-1)/2;i>=0;i--)//size-1是最后一个节点的位置,(size-1-1)/2是求出该节点的父节点
{
AdjustDown(a,i,size);
}
}
相比向上调整建堆发我们可以发现,因为向下调整建堆法是从最后一个非叶子节点开始调整的!而向上调整算法是从第一个到最后一个节点。也就意味着向下调整算法的循环次数在满二叉树的情况下可以比向上调整算法建堆几乎少了一半的循环次数!具有更优秀的时间复杂度!向下调整是越多越快!向上调整是越多越慢!
所以我们建堆一般推荐使用向下调整算法!
11.堆的应用
1.堆排序
堆排序就是使用堆的思想来进行排序。
分为两步
第一步建堆
- 升序:建大堆
- 降序:建小堆
为什么要降序建大堆呢?我们一般的想法不是,将小的放在前面吗?那不是应该是小堆吗?
由图我们可以看出来,当我们把最小的找到时候,剩下的数组父子关系已经全乱了!
如果要继续使用它找到次小的,我们就得重新建堆!这样是十分的麻烦的!
这样算起来的时间复杂度为n+(n-1)+…+1 = n+(n2-n)/2
则时间复杂度为O(N2)但是如果使用的是大堆:
我们先将最后一个与堆顶交换,然后将数组的范围缩小,因为左右的父子关系都是不变的,所以我们可以使用向下调整算法,将第一个到倒数第二个位置(右图中4的位置)范围开始进行向下调整算法,从新找到次大的放在堆顶,然后继续上一步的过程!这我们就完成了升序!
这样计算log(n)+log(n-1)+…log(1)
时间复杂度为 O(N*logN),明显优于小堆算法!
- 所以就是第二步利用堆删除思想来进行排序!



//代码演示
typedef int HPdataType;
typedef struct Heap
{
HPdataType* data;
int size;
int capacity;
}
void AdjustDown(HPdataType* a,int parent,int size)
{
int child = parent*2+1;
while(child < size)
{
if(child +1 < size && a[child] < a[child+1])
{
child++;
}
if(a[parent] < a[child])
{
swap(&a[parent],&a[child]);
parent = child;
child = parent*2+1;
}
else
{
break;
}
}
}
void swap(HPdataType* x,HPdataType* y)
{
HPdataType temp = *x;
*x = *y;
*y = temp;
}
int main()
{
HPdataType a[] = {1,4,19,15,7,34,65,25,27,8};
int size = sizeof(a)/sizeof(a[0]);
for(int i = (size-2)/2;i>=0;i--)//i>0的话无法调整到顶部!
{
AdjustDown(a,i,size);
}//完成建堆
for(int i = 0;i<size;i++)
{
swap(&a[0],&a[size-1-i]);//为什么要-i呢,因为把该堆最大(小)的放在最后面,然后就不要动他,开始放次大(小)
AdjustDown(a,0,size-i);//然后开始进行调整!
}
return 0;
}
2.topk问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。 比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
一般我们看到这种问题的时候,我们可能会立刻想到排序!但是如果数据量非常大,排序就不太可取了(可能 数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
先建堆
topk和堆排序的有点不一样
- 找最大的前k个,排小堆
- 找最小的前k个,排大堆
用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
为什么要找前k个最大不用大堆,而是小堆呢?
如果是使用大堆!我们需要先建堆,然后每次都从堆顶取出一个值,然后pop掉进行一次向下调整算法重新变回一个堆,总共pop K次即可。就可以选出最大前k个
建堆的时间复杂度为O(N),每次pop的时间复杂度为logN 则所以总的时间复杂度为O(N+K*logN),空间复杂度为O(N)
但是这样的也不是完全没有问题的!当数据量过大的时候,内存无法装的下,建大堆的方法就不可行了!如果建的是小堆呢?我们可以用前K个的值,建一个K大小的小堆!我们可以保证每次最小的都在堆顶,遇到比它还大的就与堆顶替换进堆,然后进行向下调整,到最后,堆内的就会是前K个最大的!
此时的时间复杂为O(K+(N-K)*logK),空间的复杂度为O(K)
相比之下我们可以得到更优秀的时间,空间复杂度!//代码演示 void AdjustDown(HPdataType* a,int parent,int size)//这是小堆的向下调整 { int child = parent*2+1; while(child < size) { if(child +1 < size && a[child] > a[child+1]) { child++; } if(a[parent] > a[child]) { swap(&a[parent],&a[child]); parent = child; child = parent*2+1; } else { break; } } } void PrintTopK(int* a, int n, int k)// { int* maxheap; int* temp = (int*)malloc(sizeof(int)*k); if(temp == NULL) { perror("perror fail"); return; } for(int i = 1;i<=k;i++) { maxheap[i] = a[i]; } for(int i = (k-2)/2;i>=0;i++) { AdjustDown(maxheap,i,k); }//建堆 for(int i = k;i<n;i++) { if(maxheap[0] < a[i]) { maxheap[0] = a[i]; AdjustDown(maxheap,0,k); } } free(maxheap); } void TestTopk() { int n = 10000; int* a = (int*)malloc(sizeof(int)*n); srand(time(0)); for (size_t i = 0; i < n; ++i) { a[i] = rand() % 1000000; } a[5] = 1000000 + 1; a[1231] = 1000000 + 2; a[531] = 1000000 + 3; a[5121] = 1000000 + 4; a[115] = 1000000 + 5; a[2335] = 1000000 + 6; a[9999] = 1000000 + 7; a[76] = 1000000 + 8; a[423] = 1000000 + 9; a[3144] = 1000000 + 10; PrintTopK(a, n, 10); } //当然其实不止上面一种写法 void PrintTopK2(int* a, int n, int k) { HP b; HeapIint(&b); HeapCreat(&b, a, k); for (int i = k; i < n; i++) { if (b.a[0]< a[i]) { b.a[0] = a[i]; AdjustDown(b.a, 0, k); } } HeapPrint(&b); HeapDestroy(&b); } void PrintTopK3(int* a, int n, int k) { for (int i = 0; i < k; i++) { AdjustDown(a, i, k); } for (int i = k; i < n; i++) { if (a[0] < a[i]) { a[0] = a[i]; AdjustDown(a, 0, k); } } for (int i = 0; i < k; i++) { printf("%d ", a[i]); } }