关系特定指代注意力增强的文档级关系抽取
每天给你送来NLP技术干货!
来自:知识工场
作为实现认知智能的关键技术,知识图谱具有规模巨大、语义丰富、结构友好等特点。为了实现大规模知识图谱的自动化构建,关系抽取一直以来都是学术界与工业界共同关注的研究热点。然而传统的关系抽取将范围限制在抽取一个句子内单个实体对的关系,难以满足实际应用场景的需求。因此,文档级关系抽取近些年来受到了越来越多的关注。
与传统的句子级关系抽取相比,文档级关系抽取主要面临如下挑战:(1)大量的关系三元组需要通过综合多个句子的信息进行抽取;(2)同一个实体可能参与多个关系三元组中,并且不同的关系可能是通过该实体在文档中的不同指代表达的。
现有的文档级关系抽取研究针对这种多指代问题,通常只采用简单的池化操作(如平均池化),将同一实体的所有指代表示聚合成为一个固定的实体表示来进行关系分类。然而,这种做法忽视了同一实体的不同指代可能包含着不同的语义信息,简单的池化操作可能会混淆不同提及的语义。
下图是采用BERT对一篇文档中的实体指代进行编码后,再运用t-SNE算法进行可视化展示的结果:

可以看到,在图中即便是属于同一实体的不同指代,它们的表示也是分散在特征空间中的各处,代表着它们并不是语义相近的。
并且,在抽取同一实体的不关系时,实体的不同指代起着不同的作用,如下图所示:
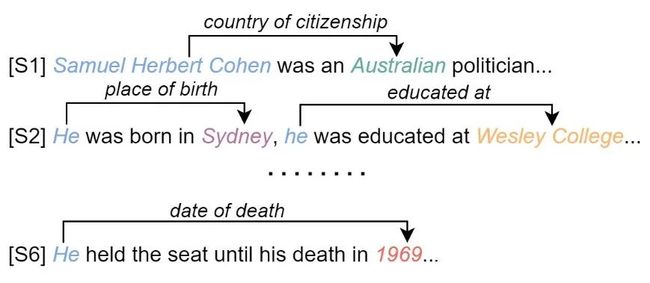 为了解决这一问题,本文提出了RSMAN,一种关系特定的指代注意力网络(Relation-Specific Mention Attention Network),针对不同的候选关系,对实体的指代表示进行注意力机制的计算,以此来增强现有文档级关系抽取模型效果。
为了解决这一问题,本文提出了RSMAN,一种关系特定的指代注意力网络(Relation-Specific Mention Attention Network),针对不同的候选关系,对实体的指代表示进行注意力机制的计算,以此来增强现有文档级关系抽取模型效果。
本文研究成果已被自然语言处理领域国际顶级学术会议NAACL 2022主会接收,文章和代码链接如下:
Paper:https://openreview.net/forum?id=r3fMN8oZHZ5

![]()
网络结构
![]()
RSMAN作用于一个backbone模型以提升其文档级关系抽取性能,backbone模型在通过特定的模型算法得到实体的指代表示后,往往只采用简单的平均池化得到对应的实体表示,即:
其中ei表示第i个实体的特征表示,mij表示第个实体的第j个指代的表示。
得到头实体与尾实体的表示后,再通过一个双线性分类器来计算关系r的概率:
而RSMAN根据待判断关系的不同,对同一实体的指代表示采取不同的选择性注意力机制,从而得到灵活的实体表示,具体网络结构如下图所示:
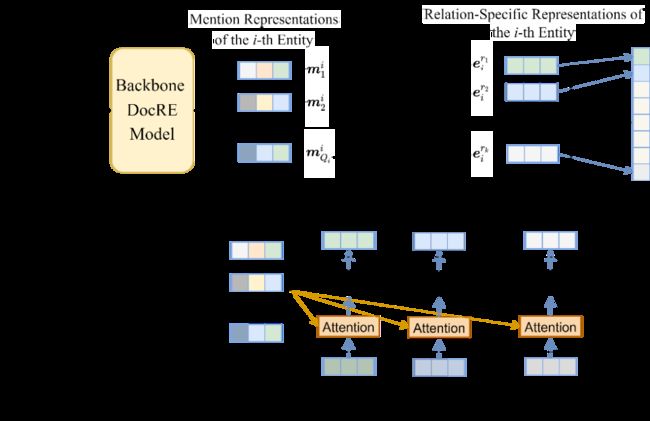
我们首先对于每种关系生成对应的关系原型表示pr,其在后续训练中作为网络参数也会被不断优化。通过backbone模型得到实体的指代表示后,我们将它们与每个关系原型表示进行注意力机制的计算,即:
其中,g表示用于计算向量之间相似度的函数,之后我们再通过softmax函数得到关系r对于同一实体所有指代表示的注意力权重:
该注意力权重代表着对于当前关系的判断,实体的不同指代所体现出的不同信息价值。因此,我们采用加权和的方式来得到特定于当前关系的实体表示:
eri即表示第i个实体特定于关系r的特征表示。
最终,根据得到的特定于关系的实体特征表示,只需将分类器中的概率计算公式修改为:
即可。可以看到,RSMAN具有即插即用的特性,可以轻松地运用到其它文档级关系抽取模型中,并且只引入很少的参数,保持和原始分类器相同的参数量级。
![]()
实验结果
![]()
我们在DWIE和DocRED两个具有代表性的文档级关系抽取数据集上进行了实验,采用官方的F1和Ign F1作为评价指标。并且,我们选取CorefBERT与SSAN这两个具有代表性的文档级关系抽取模型作为RSMAN的backbone模型。具体结果如下表所示:
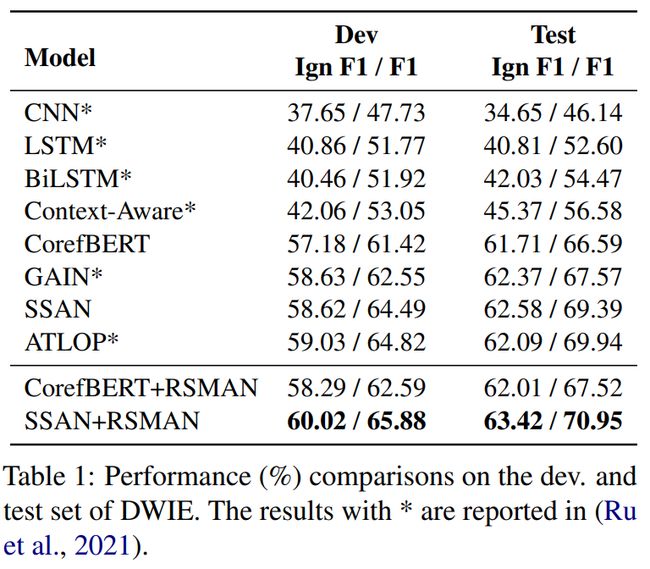
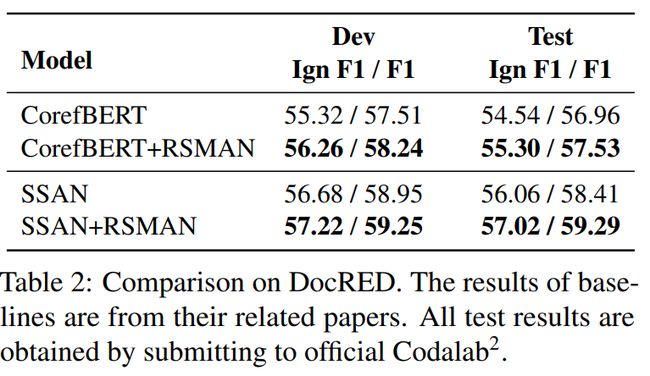
从结果中可以看到,在加入RSMAN后CorefBERT与SSAN的性能均有明显提升,并且SSAN+RSMAN的组合在DWIE数据集上的所有指标均显著优于其它基准模型,体现出RSMAN的优势以及较好的泛化能力。
![]()
实体指代数效应分析
![]()
注意到RSMAN给backbone模型带来的提升相对来说在DWIE数据集上要比DocRED数据集上更为显著,我们猜测这可能与DocRED数据集上的平均每个实体包含的指代数较少有关。因此我们将其中的验证集部分重构为三个不同的子集:第一个包含原始所有的实体对,记为M0;第二个只包含头实体或者尾实体的指代数大于1的实体对,记为M1;最后一个只包含头实体或者尾实体的指代数大于2的实体对,记为M2。在这三个不同的子集上的实验结果如下:

可以看到RSMAN对于不论是CorefBERT模型还是SSAN模型的提升,从M0到M2都随着实体平均包含的指代数的增加变得越来越显著。这意味着我们的模型对于文档中包含较多多指代实体的关系抽取更有优势,而这种多指代实体的文档级关系抽取在很多真实场景中也更为常见,更具挑战性。
![]()
指代注意力可视化分析
![]()
为了探究RSMAN是如何关注到同一个实体的不同指代信息的,我们收集了 RSMAN 中所有关系对同一实体的不同指代的归一化注意力分数,并绘制了相应的热力图进行可视化分析:
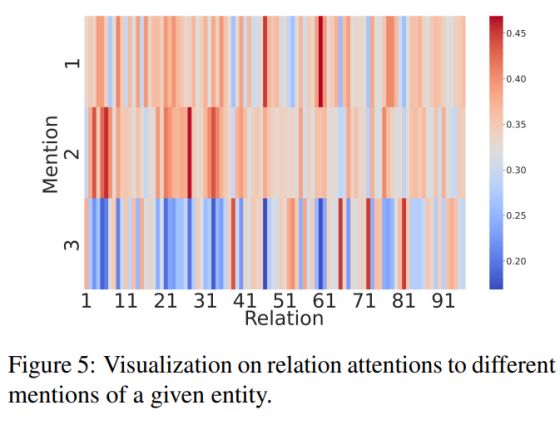
从图中我们可以观察到关系的注意力分布在不同指代上差别很大,对于不同的关系,每个指代的重要程度有所区别,这主要反应在不同的指代注意力权重上。因此,相比于普通的池化操作,通过关系特定的指代注意力来聚合指代特征是更为合理的。
![]()
总结
![]()
本文针对文档级关系抽取中的多指代问题,创新性地提出了关系特定的指代注意力网络RSMAN来增强现有文档级关系抽取性能。实验结果证实了RSMAN的有效性,特别是对于文档中的实体含有较多指代场景下的巨大潜力。
END
论文&文稿作者
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
为什么回归问题不能用Dropout?
Bert/Transformer 被忽视的细节
中文小样本NER模型方法总结和实战
一文详解Transformers的性能优化的8种方法
DiffCSE: 将Equivariant Contrastive Learning应用于句子特征学习
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~