《大数据》Hive分布式数据仓库(2023-03-26)
- 启动集群
start-all.sh
元数据:说明信息
物理数据:具体的表
- 启动 hive
hive
- 展示所有的表

- 创建一个数据表

create table lxl (
on int,
name string,
gender string)
row format delimited,
fields terminated by '\t';

6. 查看结构
desc lxl;

- 查看内容
select * from lxl;

- 导入数据
gedit ll
输入以下数据:

导入数据:
load data local inpath '/home/zkpk/ll' overwrite into table lxl;

再次查询:

hadoop fs -ls /
hadoop fs -ls /user
hadoop fs -ls /user/hive
hadoop fs -ls /user/hive/warehouse


增加一个字段age
alter table lxl add columns (age int);
desc lxl;


修改表字段

修改字段类型、位置
alter table lxl change nianling nianling int after name;
alter table lxl change nianling nianling string after name;
为什么第一个失败了?因为只有string类型的字段可以移动

删除字段

复制数据表
create table lxl1 as select * from lxl;
复制以后展示表结构

加了限定条件后的表复制
create table lxl2 as select * from lxl where 1 = 0;


清空表



删完以后:

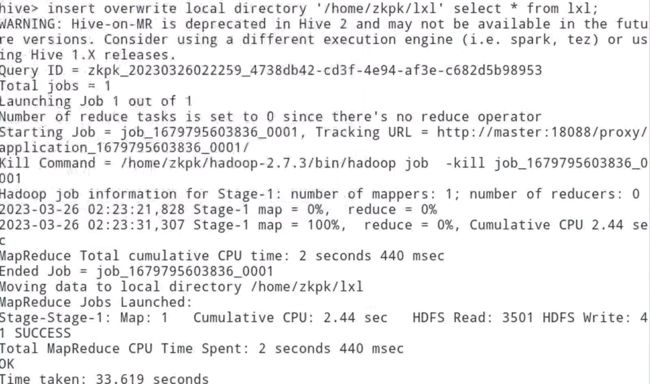
insert overwrite local directory '/home/zkpk/lxl' select * from lxl;
cd lxl
gedit 000000_0

创建外部表
create external table exlxl(no int);
hadoop fs -ls /user/hive/warehouse

删表:
drop table exlxl;

再去hadoop查一下:
![]()
没有被删除,所以结论是:外部表只删除元数据,但是hdfs的数据还是在的 删不掉
分区表创建:
create table palxl(no int, name string)
partitioned by(gender string)
row format delimited
fields terminated by '\t';

show tables
select * from palxl;

insett overwrite table palxl partition(gender)

直接输入会报错,所以我们先要把“严格模式”关掉
![]()
开启动态分区功能
set hive.exec.dynamic.partition=true;
所有分区都是动态的
set hive.exec.dynamic.partition.mode=nostrict;
最大动态分区个数
set hive.exec.max.dynamic.partitions.pernode=10;
然后再执行,就可以啦:
select * from palxl;
检验一下是否为三个 fff,是的话就对啦

再去hadoop的命令行看一眼:

查看文件内容:

桶表(对分区表的进一步划分):
create table clupalxl(no int, name string, gender string)
clustered by(no) sorted by(no) into 3 buckets
row format delimited
fields terminated by '\t';

![]()
向桶表输入数据,
set hive.enforce.bucketing=true;
![]()
insert into table clupalxl select no, name, gender from palxl distribute by(no) sort by(no);

再去hadoop看


复杂类型
create table stu(
no int,
province string,
city array<city: string, area: string>)
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':';


编写数据文件:
gedit st
1 nmg hs,bt en:90,cm:89 hs,sh
2 sd qd,yt en:80,cm:80 qd,sb

load data local inpath '/home/zkpk/st' overwrite into table stu;


[] 包裹的是 array
{} 包裹的是map或者struct
视图:
![]()






删除数据库:
hive不允许用户删除一个包含有表的数据库
加cascade关键字强制
drop database l cascade;



