项目日记:学成在线(第三天P35~p46)
1、面试:树型表的标记字段是什么?如何查询MySQL树型表?
树型表的标记字段是parentid即父结点的id。
查询一个树型表的方法:
1)当层级固定时可以用表的自链接进行查询。
2)如果想灵活查询每个层级可以使用mysql递归方法,使用with RECURSIVE 实现。
2、面试:#{} 和 ${} 有什么区别?(sql注入是啥)
#{}是标记一个占位符,可以防止sql注入。
${} 用于在动态 sql中拼接字符串,可能导致sql注入。
关于sql注入:
SQL注入(SQL Injection)是一种常见的Web安全漏洞
原因:注入产生的原因是后台服务器在接收相关参数时未做好过滤直接带入到数据库中查询,导致可以拼接执行SQL语句
Sql 注入带来的威胁主要有如下几点:
猜解后台数据库,这是利用最多的方式,盗取网站的敏感信息。
绕过认证,列如绕过验证登录网站后台。
注入可以借助数据库的存储过程进行提权等操作
①猜解后台数据库
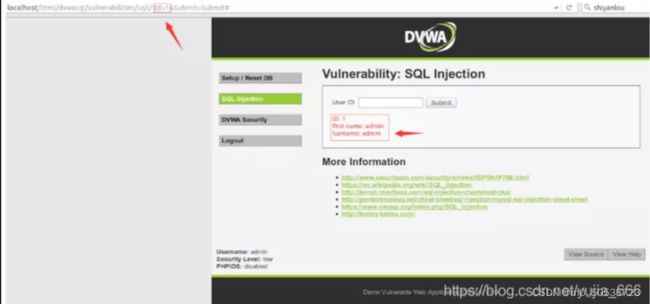
在输入框中输入 1’ order by 1#,其中#后面的内容会被注释掉,因为#的原因。
所以sql语句相当于:SELECT first_name, last_name FROM users WHERE user_id = ‘1’ order by 1#`;
#就把最后多余的单引号注释掉了,避免产生错误
这个sql语句的意思就是查询users表中user_id为1的数据并按第一字段排行
如果再次输入:1’ order by 2#正常,然后输入1’ order by 3#报错,说明users表中只有两个字段,数据为两列。
接下来我们使用 union select联合查询继续获取信息。
union 运算符可以将两个或两个以上 select 语句的查询结果集合合并成一个结果集合显示,即执行联合查询。需要注意在使用 union 查询的时候需要和主查询的列数相同,而我们之前已经知道了主查询列数为 2,接下来就好办了。
输入1’ union select database(),user()#进行查询 :
database()将会返回当前网站所使用的数据库名字.
user()将会返回执行当前查询的用户名.
实际的sql语句是:SELECT first_name, last_name FROM users WHERE user_id = '1' union select database(),user()#`;
第一部分是查询user表中id为1的内容,第二部分是查询到的数据库名(dvwa)和当前用户名(root@localhost )
②绕过验证
在用户名中输入 123’ or 1=1 #, 密码同样输入 123’ or 1=1 # :
会发现登陆成功,因为执行的sql语句是:select * from users where username='123' or 1=1 #' and password='123' or 1=1 #'由于判断语句 or 1=1 恒成立,所以结果当然返回真,成功登录。
其余知识见:sql注入基础原理(超详细)


3、@ResponseStatus作用,里面的参数有几种HttpStatus.INTERNAL_SERVER_ERROR,什么时候用
HttpStatus.INTERNAL_SERVER_ERROR是http的一种状态,其余的状态参考: http状态详解
@ResponseStatus 是标记一个方法或异常类在返回时响应的http状态
@ResponseStatus注释可指定下表所示属性:
@ResponseStatus注解有两种用法,一种是加载自定义异常类上,一种是加在目标方法中,当修饰一个类的时候,通常修饰的是一个异常类。
注解在方法上:@ResponseStatus(HttpStatus.BAD_REQUEST) public Response globalException(HttpServletRequest request, Throwable ex) { return new Response(400,"1 / 0",null); }结果:
1 / 0 出现异常被我们捕获之后返回我们自定义的状态码400,和自定义的结果(即response中的内容)
如果使用reason属性:@RequestMapping(path = "/401") @ResponseStatus(value = HttpStatus.UNAUTHORIZED,reason = "no no no") public Response unauthorized() { return new Response(401, "Unauthorized", null); }结果:
如果@ResponseStatus有reason属性,@RequestMapping方法返回值都不处理了,直接返回(也就是response中内容都没有在浏览器上返回)



4、@ExceptionHandler参数中方的是要处理的异常信息的类吗
@ExceptionHandler可以用来统一处理方法抛出的异常。使用这个@ExceptionHandler注解时,我们需要定义一个异常的处理方法,这个方法就会处理类中其他方法抛出的异常
@ExceptionHandler注解中可以添加参数,参数是某个异常类的class,代表这个方法专门处理该类异常
就近原则:当异常发生时,Spring会选择最接近抛出异常的处理方法。比如现在有NumberFormatException,这个异常有父类RuntimeException,RuntimeException还有父类Exception。如果抛出的是NumberFormatException,就会优先选择处理类型是NumberFormatException.class注解的方法,如果没有,会先找类型是RuntimeException.class(直接父类),然后再找间接父类。
注意:使用@ExceptionHandler时尽量不要使用相同的注解参数(就是不要在两个不同的方法上都处理同一类的异常,不然出现该异常类型时会报错):@ExceptionHandler(NumberFormatException.class) @ResponseBody public String handleExeption(Exception ex) { System.out.println("抛异常了:" + ex); ex.printStackTrace(); String resultStr = "异常:NumberFormatException"; return resultStr; } @ExceptionHandler(NumberFormatException.class) @ResponseBody public String handleExeption2(Exception ex) { System.out.println("抛异常了:" + ex); ex.printStackTrace(); String resultStr = "异常:默认"; return resultStr; }
5、面试:系统如何处理异常?
我们自定义一个统一的异常处理器去捕获并处理异常。
使用控制器增加注解@ControllerAdvice和异常处理注解@ExceptionHandler来实现。
- 处理自定义异常
程序在编写代码时根据校验结果主动抛出自定义异常类对象,抛出异常时指定详细的异常信息,异常处理器捕获异常信息记录异常日志并响应给用户。- 处理未知异常
接口执行过程中的一些运行时异常也会由异常处理器统一捕获,记录异常日志,统一响应给用户500错误。
在异常处理器中还可以针对某个异常类型进行单独处理。
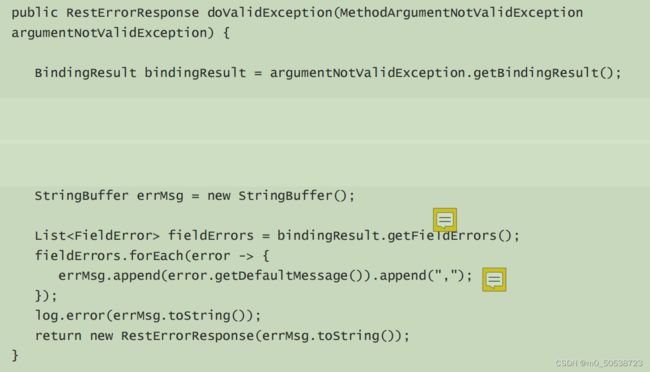
6、getBindingResult方法、getFieldErrors方法作用
BindingResult:
BindingResult对象的作用是将所有的异常信息存起来。
作用:用于对前端穿进来的参数进行校验,省去了大量的逻辑判断操作
BingdingResult是要与@Validated同时使用的
getBindingResult方法是获得BindingResult对象,getFieldErrors是获得BindingResult中包含的错误信息。
7、面试:请求参数的合法性校验如何做?
使用基于JSR303的校验框架实现,SpringBoot提供了JSR-303的支持,它就是spring-boot-starter-validation,它包括了很多校验规则,只需要在模型类中通过注解指定校验规则,然后在controller方法上开启校验。
8、swagger文档中的:@ApiModelProperty(value = “课程名称”, required = true)里的value和required作用
@ApiModelProperty:使用在被 @ApiModel 注解的模型类的属性上
value是对属性的简要说明,required是说明这个参数是否可以为空,默认值是false
@ApiModel:在实体类上边使用
9、如果设置是分组校验,那没设置分组的校验代码还能起作用吗
总结:如果这个属性的校验没有被分组,那么如果不是相对应的分组数据传入时,出现了没被分组的属性较严重的错误,会不通过(简单来说,就是没被分组的属性校验对无分组的数据起作用,对分了组的不起作用);
如果属性被分组了,那只对对应分组的数据起作用(分组1的校验只对分组1的数据起作用,对分组2的不起作用,对未分组的也不起作用)
例子:分组校验(看分组校验章节)
可以看出,属性的分组情况是:
未被分组的属性:性别、地址
被分为1组的属性:用户名、年龄
被分为2组的属性:年龄、邮箱、手机号
结果:
未分组的数据传输时,如果姓名、年龄为空——通过
未分组的数据传输时,如果性别为空——不通过
分组1的数据传输时,如果性别为空——通过
分组1的数据传输时,如果姓名、年龄、性别为空——不通过(提示:姓名、年龄不能为空)
分组2的数据传输时,如果姓名、年龄、性别、地址为空——通过
分组2的数据传输时,如果邮箱、手机号为空——不通过
10、为啥有@Data还要有@ToString?
@Data:注解在类上;提供类所有属性的 get 和 set方法,此外还提供了equals、canEqual、hashCode、toString 方法;
虽然@Data注解提供了重写toString,但在某些时候会出现问题,建议和@ToString一起使用
@ToString:重写tostring方法,权重比@Data高
@Data整合了@ToString的注解,不过两者之间还有区别,比如:
@Data public class People { private String height; private String weight; }@Data public class Student extends People { private String name; }public class Test { public static void main(String[] args) { Student student = new Student(); student.setHeight("180cm"); student.setWeight("65kg"); student.setName("Jack"); System.out.println(student.toString()); } }打印结果:Student(name=Jack)
如果想要将其父类的属性结果也打印出来,应该——子类加上@Data和@ToString(callSuper = true)两个注解, 父类也使用注解@Data@Data @ToString(callSuper = true) public class Student extends People { private String name; }打印结果:Student(super=People(height=180cm, weight=65kg), name=Jack)
说明:通过设置callSuper为true,可以将父类实现toString的输出包含到子类的输出中,默认值是false
11、order by的顺序,先按什么后按什么?
ORDER BY 关键字可以使查询返回的「结果集」按照指定的列进行排序,可以按照某「一列」排序或者同时按照「多列」进行排序,排序的顺序可以是「升序」或者「降序」。
默认按照升序排列,如果使用降序需要用DESCSELECT column_name,column_name FROM table_name ORDER BY column_name,column_name ASC|DESC;使用方法:
①按照字段名排序
②按照字段的索引排序(第一列是1,第二列是2……)
③按照多列进行排序,如果数据的第一列值相同,则按照第二列排序……