【西瓜书】part1:机器学习基础知识
目录
0 食用指南
1. 绪论
1.1 引言
1.2 基本术语
1.3 假设空间
1.4 归纳偏好
1.5 发展历程
1.6 应用现状
2. 模型评估与选择
2.1 经验误差与过拟合
2.2 评估方法
2.2.1 留出法
2.2.2 交叉验证法
2.2.3 自助法
2.2.4 调参与最终模型
2.3 性能度量
2.4 比较检验
0 食用指南
第一部分(1~3章):机器学习基础知识
第二部分(4~10章):经典常用的机器学习方法
第三部分(11~16章):进阶知识

1. 绪论
1.1 引言
人类看到乌云就知道可能会下雨,是因为我们看过很多次乌云,基本都会下雨,这是我们基于经验做出的判断,那么计算机是否也能利用经验判断呢?
在计算机中,“经验”以“数据”形式存在,是否能够把“经验”和用于判断的“模型”联系在一起?这样习得的模型就是“学习算法”
模型:全局性结果(eg一棵决策树)(模型也可称作学习器)
模式:局部性结果(eg一条规则)
1.2 基本术语
样本表示术语
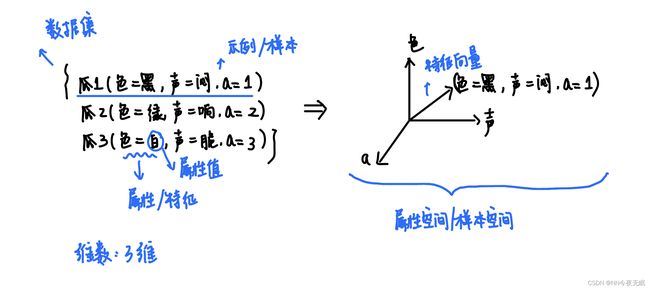
维数:色 、声、a三个属性,所以三维
学习/训练过程术语
在这个过程中使用 训练数据、训练样本、训练数据集(就是加上训练二字而已)
学得的规律叫“假设”,真实的规律叫“真相”、“真实”。(我们希望假设逼近真相)
要得到好坏西瓜的预测模型,需要给一些数据标记,有了标记的瓜就是“样例”,一般有着这样的对应(xi,yi)表示第i个加了标记的瓜,所有的标记y的集合称作标记空间or输出空间
学习/训练任务术语
分类(预测是好瓜还是坏瓜,得到的就是离散值-好or坏)
回归(预测瓜的成熟度,得到的是连续值0.95、0.37)
二分类任务:两个类分别叫“正类”、“反类”
多分类任务:多个类别
预测任务就是建立一个x->y的映射(输入空间到输出空间的映射),这个映射就是模型
测试,测试样本:学得模型后再用测试样本测试
聚类:把瓜分为好几组,一组就是一簇(组别可以为深色瓜、浅色瓜两组)
监督学习(分类、回归)
无监督学习(聚类)
学习/训练效果术语
泛化能力:学得的模型适用于新样本的能力(我们希望训练好的模型有强泛化能力)
样本都服从于某个分布,可以说他们是独立同分布的(相互独立,又都服从于同一个分布)
1.3 假设空间
归纳(泛化:特殊到一般,特殊情况归纳出原理)--->归纳学习---->黑箱模型
演绎(特化:原理到具体情况,用原理推导/演绎出结果)
概念学习中有布尔概念学习,就是得出0/1的布尔值
eg. 好瓜<-->(色=?)&&(声=?)&&(a=?) ,把这个问号确定下来,得出布尔表达式
仅仅是记住训练样本就是“机械学习”,可是我们希望归纳出泛化能力强的模型,来预测我们没有见过的瓜
假设空间
那么所有可能出现的瓜,就是假设空间(就是色、声、a的所有可能出现的属性的组合)
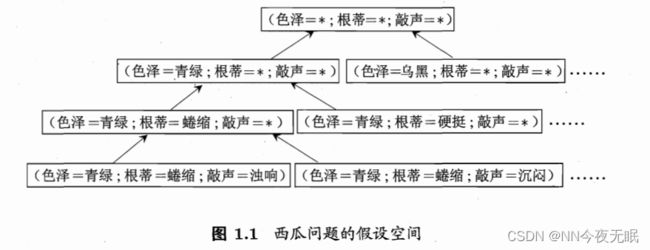 这样一棵树的最下面,就是瓜的假设空间的所有情况,假设空间就是(色=*;根=*;声=*)
这样一棵树的最下面,就是瓜的假设空间的所有情况,假设空间就是(色=*;根=*;声=*)
通配符*:(色=*,声=*,a=1)就是所有a为1,色声所有组合的瓜
版本空间
流程:用某种策略搜索假设空间,边搜索,边删掉肯定不对的反例,剩下的就是正例或者可能是对的的样本,这就是版本空间
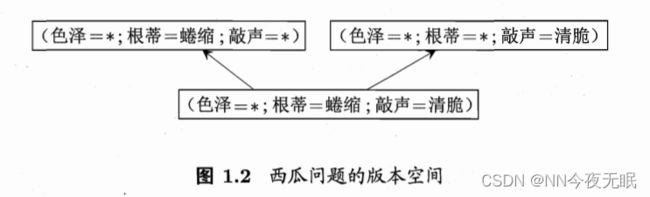
经过了上面边走边删的流程,最终剩下的就是,版本空间,一共三个假设,都符合训练集里的好瓜
1.4 归纳偏好
刚才的版本空间有三个假设,放一个瓜进去,这几个假设出来的结果可能不一样,有的假设说是好瓜,有的假设说是坏瓜
所以说我们训练出来的算法,要看归纳偏好,如果偏好特殊的算法,那会选择,根和声都明确,色泽不明确的(色=*;根=蜷缩;声=清脆),如果更偏好一般的,就会选其他
所以!一定要明确一个归纳偏好,不然的话没有一个明确的答复,有时候说好有时候说坏的
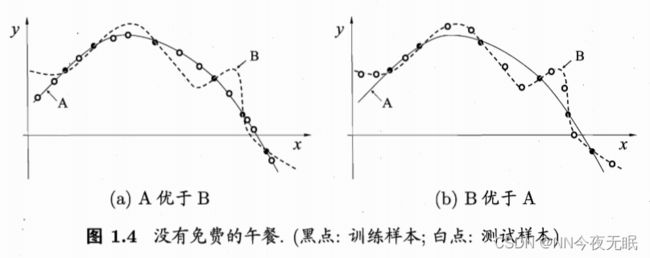
只要穿过训练样本的线,都是合格的版本,这些线组成版本空间,所有版本空间里的假设,那都是对的,但是我们总要选一条线作为我们的结果,也就是说,要从版本空间里选择一个合适的假设,那以上这两条线,我喜欢平滑的那条,所以归纳偏好就偏向了一般的。
but!如何选择正确的归纳偏好?
“奥卡姆剃刀”法:若有多个假设与观察一致,则选择最简单的那个(所以选最平滑的,当然,这条曲线的泛化能力也更强)
归纳偏好=选择更好的模型,but A线一定比B线好吗?
(略过期望性能计算)
计算过后发现A和B的期望性能是一样的,这就是“没有免费的午餐”定理(NFL定理)
但是呢,实际情况里,虽然B这样扭来扭去的线可以穿过一些测试样本,但是实际上大部分情况下,大部分的瓜还是遵从A的,不要脱离实际,为了让所有的训练样本和测试样本都穿过模型,而选择B。
1.5 发展历程
1.6 应用现状
2. 模型评估与选择
2.1 经验误差与过拟合
经验误差
精度=1-错误率,错误率=分错的个数/总个数,精度=分对的个数/总个数
我们将学习器对样本的实际预测结果与样本的真实值之间的差异成为:误差(error)。定义:
- 在训练集上的误差称为训练误差(training error)或经验误差(empirical error)。
- 在测试集上的误差称为测试误差(test error)。
- 学习器在所有新样本上的误差称为泛化误差(generalization error)
(这个误差究竟指什么???
误差是各个点误差的期望,也就是各个误差平均出来的,比如说,实际上西瓜成熟度本应该是0.36,但是我通过预测模型预测出来,在这样的属性值情况下,西瓜成熟度将会是0.38,那么这里的误差是0.38-0.36=0.02,这是一个点的误差,将所有样本预测后,对预测结果的每一个误差求一个期望,的出来的就是我们所说的误差error)
我们希望泛化误差小一点,这样新样本的预测会准确,但是泛化误差不可估量,所以我们将在经验误差上,下手。
过拟合
过拟合(过配):拟合得太好了,每个训练样本都刚刚好符合,那泛化能力太差了
欠拟合(欠配):拟合得太差了
2.2 评估方法
使用测试集测试评估学习器的泛化误差,使用得出的测试误差,近似等同于泛化误差,所以我们希望测试误差越小越好(测试集的测试样例不要和训练集重复了!)
那么我们需要自行划分出测试集,变成训练集S和测试集T,划分的办法如下
测试误差就是,测试出的结果错误的10个,测试集T100个,那么测试误差就是10/100=10%
2.2.1 留出法
直接拆分成两个互斥的集合
注意:
1. 划分时要保持数据分布的一致性,请分层采样
(分层采样:在正例里和反例里分别采样,S和T内部正例和反例的比例是一样的!)
2. 随机划分:在从正例反例里面采样的时候,请随机采样!
(如果采样的时候,按照大小排序,小的放T,大的放S,影响也很大!所以要随机且多次实验,然后取误差平均值,才是真正的测试误差)
3. 留2/3~4/5的训练集(如果训练集太大的话,那模型非常契合训练集,此时测试集测试的时候,就会误差很大,因为这个模型是训练集训练出来的模型,和测试集没啥关系)
2.2.2 交叉验证法
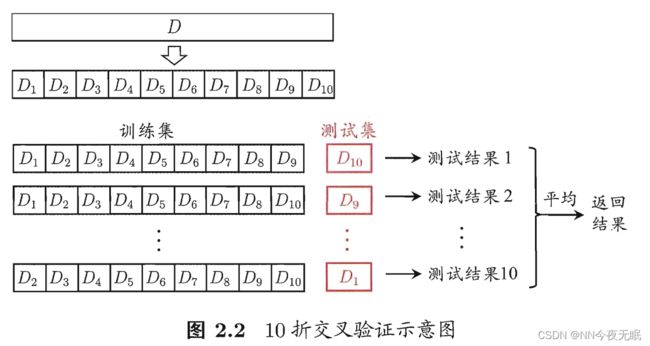
分成k个子集,每次拿一个出来当测试集,然后k次运算后,平均一下这个k个结果,得到的就是测试误差
k通常用10,称之为10折交叉验证(5折交叉验证和20折交叉验证也有时会使用)
注意:
1. 分子集时请分层采样
2. 重复多次(比如10次10折交叉验证)
留一法:就是如果有100个样本,留1个验证,99个训练,就是只留一个出来测试啦。
(留一法很准确,因为大部分都用来训练了,能够训练出相对准确的模型,但是100个样本需要做100次计算测试误差,那么1000?10000?1000000000个呢?计算量太大了!)
2.2.3 自助法
在前两个方法中,训练集和原来的数据集个数不一样,会有因个数不同导致的误差,而留一法虽然个数差不多,但是计算量太大
自助法:从原数据集D中随机采样,采样m个(并且每次采样都是在原有的m个数据的数据集采样,采样后原数据集的个数不变),这样会获得新数据集D'(可能会出现重复采样,但是没关系)

D'用于训练,这36.8%用于测试(这样D'也有m个数据)---->这样的测试结果就叫包外估计
该方法优劣:
1. 数据集小的时候很好用(大了要一个个采样很麻烦)不知道怎么划分S和T时可以使用
2. 对集成学习很有帮助
3. 改变了数据集的分布,引入估计偏差
初始数据量足够的时候,请使用留出法、交叉验证法
2.2.4 调参与最终模型
算法的参数需要调整--->调参