Python快速刷题网站——牛客网 数据分析篇(六)
一个帅气的boy,你可以叫我Love And Program
⌨个人主页:Love And Program的个人主页
如果对你有帮助的话希望三连支持一下博主

python是目前非常火爆的语言,其在人工智能、数据分析领域都占有一席之地,无论是学习还是工作,都会给你带来相当大的帮助。我在这给大家 推荐一个快速提升自己的网站 牛客网,他们现在的IT题库内容很丰富,属于国内做的很好的了,可以在下图中看见里面试题应有尽有,最最最重要的里面的资源全部免费!!!(亲测全免费,写题解还可以得小礼物)欢迎大家自助练习
系列专栏链接:
Python快速刷题网站——牛客网 数据分析篇专栏
前言
今天我们继续巩固 数据索引 相关知识。
Python用户的成就值
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
假如你正在学习Python,你想知道牛客网的Python用户的成就值都有多高,请问该如何输出?
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。

通过读题,我们提取关键信息:输出 Python、成就值 ,首先想到什么?直接查找python列或是用query函数查找Python列,我们把方式逐一列下:
- 直接查找Python列
-
query函数查找Python列
首先我们直接查找Python列,然后再去搜索成就值列:
import numpy as np
import pandas as pd
data= pd.DataFrame({
"Nowcoder_ID":['first','second','third','fourth'],
"Level":[1,2,3,2],
"Language":['Python','CPP','Python','C/C#'],
"Achievement_value":[8711,13,999999,2],
"Num_of_exercise":[500,2,32,222],
"Graduate_year":[np.nan,np.nan ,np.nan,'7']
})
print(print(data.loc[data['Language']=='Python'].Achievement_value))

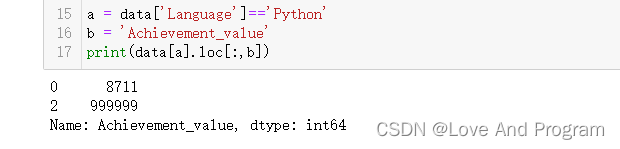
当然,我们还有很多种输出方式也可以实现对应的输出结果,比如下面这种分开输出的方式:
a = data['Language']=='Python'
b = 'Achievement_value'
print(data[a].loc[:,b])
# 也就是
print(data[data['Language']=='Python'].loc[:,'Achievement_value'])
接下来我们用query函数查找Python列,原理上与上述是相同,只是使用的函数是不一样的,需要在实际应用中看情况选择使用(结果是一样的):
import numpy as np
import pandas as pd
data= pd.DataFrame({
"Nowcoder_ID":['first','second','third','fourth'],
"Level":[1,2,3,2],
"Language":['Python','CPP','Python','C/C#'],
"Achievement_value":[8711,13,999999,2],
"Num_of_exercise":[500,2,32,222],
"Graduate_year":[np.nan,np.nan ,np.nan,'7']
})
print(data.query('Language=="Python"').loc[:,'Achievement_value'])

最终代码整理如下:
DA7 牛客网Python用户的成就值 答案
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',')
# a=Nowcoder['Language']=='Python'
# b='Achievement_value'
# print(Nowcoder[a].loc[:,b])
print(Nowcoder.query('Language=="Python"').loc[:,'Achievement_value'])
文件最后用户的部分数据
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
假设你想查看该文件最后5行用户的用户ID、等级、成就值、常用语言,请尝试输出。
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。

读题:查看文件最后五行用户的用户ID、等级、成就值、常用语言->Nowcoder_ID、Level、Achievement_value、Language
- 通过
loc/iloc函数查找对应位置并输出 - 使用
head/tail函数 - 两者混合使用
首先是直接使用iloc函数输出:
import numpy as np
import pandas as pd
data= pd.DataFrame({
"Nowcoder_ID":['first','second','third','fourth'],
"Level":[1,2,3,2],
"Language":['Python','CPP','Python','C/C#'],
"Achievement_value":[8711,13,999999,2],
"Num_of_exercise":[500,2,32,222],
"Graduate_year":[np.nan,np.nan ,np.nan,'7']
})
data.iloc[-5:,[0,1,2,3]]
我们接下来再使用tail/head函数来实现看看:
print(data[['Nowcoder_ID','Level','Achievement_value','Language']].tail(5))
# 注意,因为我上面使用的数据量只有四条,所以自己测试时使用head(-5)会无法显示,
# 因此我们只需把数据加到>=5即可使用此函数得出结果
print(data[['Nowcoder_ID','Level','Achievement_value','Language']].head(-5))

这两个函数大家应该也理解了
head()返回前n行tail()返回最后n行
最后是两者混合使用,个人比较喜欢混一块使用:
print(Nowcoder.loc[:,['Nowcoder_ID','Level','Achievement_value','Language']].tail(5))
print(Nowcoder[['Nowcoder_ID','Level','Achievement_value','Language']].head(-5))
其结果完全相同!这就是编程很有魅力的地方之一,你可以选择多种方式向最终目的进行编程,想炫技也好,想省事也罢,等你有着这种想法的时候恭喜你,成功入门…
最终代码整理如下:
DA8 文件最后用户的部分数据 答案
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
# print(Nowcoder.loc[:,['Nowcoder_ID','Level','Achievement_value','Language']].tail(5))
# print(Nowcoder.iloc[-5:,[0,1,2,5]])
print(Nowcoder[['Nowcoder_ID','Level','Achievement_value','Language']].head(-5))
趁暑假还没结束,大家一起卷起来