4.7-4.9学习总结
一、异常
1.异常的概述
Java语言中,将程序执行中发生的不正常情况称为“异常”。(开发过程中的语法错误和逻辑错误不是异常)
执行过程中所发生的异常事件可分为两类:
- Error(错误):Java虚拟机无法解决的严重问题。如:JVM系统内部错误、资源耗尽等严重情况。比如:StackOverflowError[栈溢出]和OOM(out ofmemory),Error 是严重错误,程序会崩溃。
- Exception:其它因编程错误或偶然的外在因素导致的一般性问题,可以使用针对性的代码进行处理。例如空指针访问,试图读取不存在的文件,网络连接中断等等,Exception分为两大类: 运行时异常[ 程序运行时, 发生的异常 ] 和 编译时异常[ 编程时 , 编译器检查出的异常 ]。
Java将异常分为两种:Checked 异常和 Runtime 异常
Java将Checked异常都是在编译阶段可以被处理的异常,它强制程序处理所有的Checked异常
Runtime异常无需处理,它有一个默认的处理机制
增加了异常处理机制后的程序有更好的容错性,更加健壮!
- 错误处理机制的两个缺点:
- 无法穷举所有的异常情况。异常情况总比可以考虑到的情况“多”,总有“漏网之鱼”的异常情况,导致程序总是不够健壮。
- 错误处理代码和业务实现代码混杂。这种错误处理和业务实现混杂的代码可能眼中影响程序的可读性,会增加程序维护的难度。
2.异常处理机制
Java的异常处理机制可以让程序具有极好的容错性,让程序更加健壮。
1.try-catch-finally

不管代码块是都处于 try 块中,甚至包括 catch 块中的代码,只要执行该代码块时出现了异常,系统总会自动生成一个异常对象。如果程序员没有为这段代码定义任何的 catch 块,则Java运行时环境无法找到处理该异常的 catch 块,程序就会在这里退出。
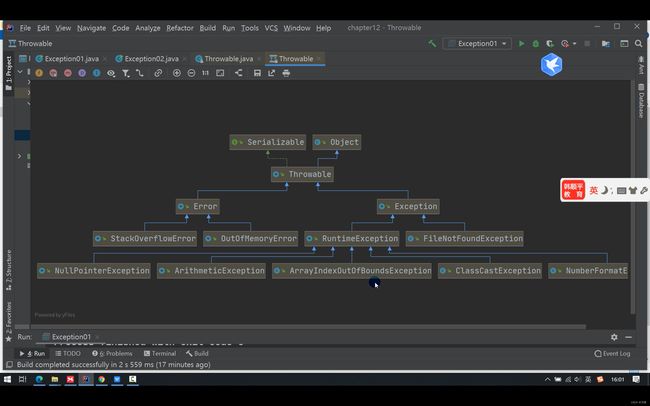
2.异常类的继承体系:
try 块后面可以有多个 catch 块,这是为了针对不同的异常类提供不同的异常处理方式。
如果try块被执行一次,则try块后只有一个catch块会被执行,绝对不可能有多个catch块被执行。除非在循环中使用了continue开始下一次循环,下一次循坏又重新运行try块,这才可能导致多个catch块被执行。
- try 语句跟 if 语句不一样,try块后的花括号({...})不可以省略,即使 try 块里只有一行代码,也不可以省略这个花括号。catch 块后面的花括号({...})也不可以省略。
- try 块里声明的变量是代码块内局部变量,它只在 try 块里面有效,在catch 中不能访问该变量。
Java提供了丰富的异常类:它们之间有严格的继承关系!
package homework;
public class Homework1 {
public static void main(String[] args) {
try{
if (args.length!=2)
{
throw new ArrayIndexOutOfBoundsException("参数不对");
}
int n1 = Integer.parseInt(args[0]);
int n2 = Integer.parseInt(args[1]);
double ans = divide(n1,n2);
System.out.println("得数是 " + ans );
}catch(ArrayIndexOutOfBoundsException e)
{
System.out.println(e.getMessage());
}
catch(NumberFormatException e)
{
System.out.println("参数转换有误,输入的不是整数");
}
catch (ArithmeticException e)
{
System.out.println("除数不能为0");
}
catch (Exception e)
{
System.out.println("未知异常");
}
}
public static double divide(int a ,int b)
{
double n1 = a*1.0;
double n2 = b*1.0;
return n1/n2;
}
}
捕获异常的时候,一定要记住先捕获小异常,再捕获大异常!
3.多异常捕获
- Java7以前,每个 catch 块只能捕获一种类型的异常
- Java7开始,一个 catch 块可以捕获多种类型的异常
使用一个 catch 块捕获多种类型的异常时需要注意:
- 捕获多种类型的异常时,多种异常类型之间用竖线 (|)隔开
- 捕获多种类型的异常时,异常变量有隐式的 final 修饰,程序不能对异常变量重新赋值。
常见的运行时异常:


4.访问异常信息
访问异常信息包含的几个常用方法
- getMessge() : 返回该异常的详细描述字符串
- printStackTrace() : 将该异常的跟踪栈信息输出到标准输出错误
- printStackTrace(PrintStream s) : 将该异常的跟踪栈信息输出到指定输出流
- getStackTrace() : 返回该异常的跟踪栈信息
package process;
import java.io.FileInputStream;
import java.io.IOException;
public class AccessExceptionMsg {
public static void main(String[] args) {
try{
FileInputStream fis = new FileInputStream("a.txt");
}
catch(IOException ioe)
{
System.out.println(ioe.getMessage());
ioe.printStackTrace();
}
}
}

由上面的图片就可以看见异常的详细描述信息:“a.txt(系统找不到指定的文件)”,这就是调用异常的getMessage() 方法返回的字符串。
5.finally回收资源
有些时候,程序在try块里面打开了一些物理资源(例如数据库连接、网络连接和磁盘文件等),这些物理资源都必须显式回收。
Java的回收就只不会回收任何物理资源,垃圾回收机制只能回收堆内存中对象所占用的内存
try-catch-finally 编写注意事项;
- try 块时必需的,没有try块,就没有 catch 块和 finally 块
- catch 块或者 finally 块都是可选的 ,但是 catch 块和 finally 块至少出现其中之一,也可以同时出现
- 可以有多个 catch 块,但是捕捉父类异常的 catch 块必须位于捕捉子类异常的后面
- 不能只有 try 块,既没有catch 块,也没有 finally 块
- 多个 catch 块必须位于 try 块后面,但是 finally 块必须位于所有的 catch块 后面
- 除非在 try 块、catch 块中调用了退出虚拟机的方法,否则不管在 try 块、catch块中执行怎样的代码,出现怎样的情况,异常处理的 finally 总会被执行
- 尽量避免在 finally 块里使用 return 或着 throw 等导致方法终止的语句,否则可能会出现一些很奇怪的情况。
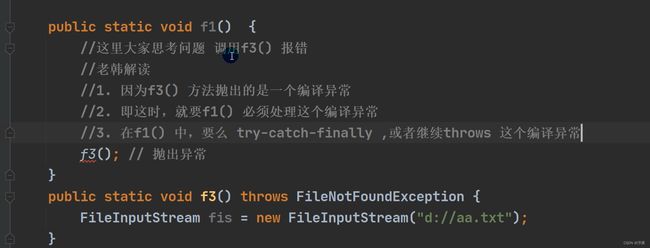
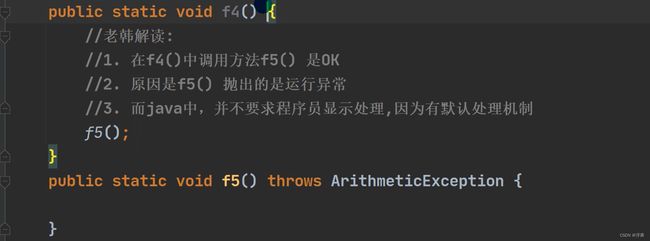
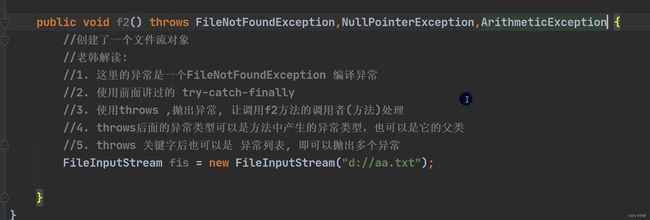
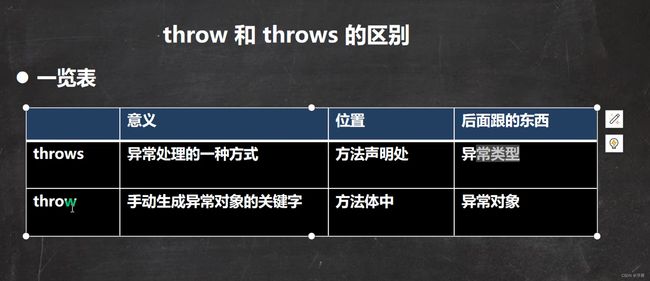
3.throw异常
- 如果一个方法(中的语句执行时)可能生成某种异常,但是并不能确定如何处理这种异常,则此方法应显示地声明抛出异常,表明该方法将不对这些异常进行处理,而由该方法的调用者负责处理。
- 在方法声明中用throws语句可以声明抛出异常的列表,throws后面的异常类型可以是方法中产生的异常类型,也可以是它的父类。
package homework;
public class ThrowTest {
public static void main(String[] args) {
try{
throwChecked(-3);
}
catch (Exception e)
{
System.out.println(e.getMessage());
}
throwRuntime(3);
}
public static void throwChecked(int a) throws Exception{
if(a>0)
{
throw new Exception("a的值大于0,不符合要求");
}
}
public static void throwRuntime(int a)
{
if(a>0)
{
throw new RuntimeException("a的值大于0,不符合要求");
}
}
}

3.自定义异常
自定义异常的步骤
- 定义类:自定义异常类名(程序员自己写)继承Exception或RuntimeException
- 如果继承Exception,属于编译异常
- 如果继承RuntimeException,属于运行异常(一般来说,继承RuntimeException)
4.异常处理规则
成功的异常应该实现下面4个目标:
- 是程序代码混乱最小化
- 捕获并保留诊断信息
- 通知合适的人员
- 采用合适的方式结束异常活动
1.不要过度使用异常
异常机制确实方便,但滥用异常机制也会带来一些负面影响。
过度使用异常主要有两个方面:
- 把异常和普通错误混淆在一起,不再编写任何错误处理代码,而是以简单地抛出异常来代替所有的错误处理
- 使用异常处理来代替流程控制
- 异常只应该用于处理非正常的情况,不要使用异常处理来代替正常的流程控制。对于一些完全可预知,而且处理方式清楚的错误,程序应该提供相应的错误处理代码,而不是将其笼统地称为异常。
2. 不要使用过于庞大的 try 块
3.避免使用 Catch All语句
4.不要忽略捕捉到的异常
二、Git

1,版本控制
版本控制:版本迭代
版本控制( Revision control )是一种在开发的过程中用于管理我们对文件、目录或工程等内容的修改历史,方便查看更改历史记录,备份以便恢复以前的版本的软件工程技术。
作用:
- 实现跨区域多人协同开发
- 追踪和记载一个或者多个文件的历史记录
- 组织和保护你的源代码和文档
- 统计工作量
- 并行开发、提高开发效率
- 跟踪记录整个软件的开发过程
- 减轻开发人员的负担,节省时间,同时降低人为错误
简单说就是用于管理多人协同开发项目的技术!
常见的版本控制器:

目前影响力最大且使用最广泛的是Git与SVN
2.版本控制的分类
1.本地版本控制
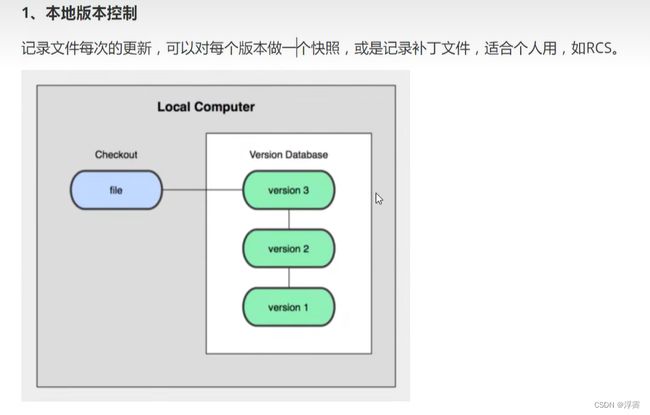
本地版本控制:就是一个人完成某个项目的增删查改并且把每一次的资料都保存了下来,一个人就完整的拥有所有的资料。
2.集中版本控制
代表产品:SVN

所有的版本数据都存在服务器上,用户的本地只有自己以前所同步的版本,如果不连网的话,用户就看不到历史版本,也无法切换版本验证问题,或在不同分支工作。而且,所有数据都保存在单一的服务器上,有很大的风险这个服务器会损坏,这样就会丢失所有的数据,当然可以定期备份。代表产品:SVN、CVS、VSS
可以理解为:就
3.分布式版本控制
代表:Git
- 缺点:相当于每个人都拥有所有的代码,可能会导致代码泄露问题。
- 优点:不会因为服务器损坏或者网络问题,造成不能工作的情况!
所有版本信息仓库全部同步到本地的每个用户,这样就可以在本地查看所有版本历史,可以离线在本地提交,只需在连网时push到相应的服务器或其他用户那里。由于每个用户那里保存的都是所有的版本数据,只要有一个用户的设备没有问题就可以恢复所有的数据,但这增加了本地存储空间的占用。


Git配置:所有的配置文件,全部都保存在本地。
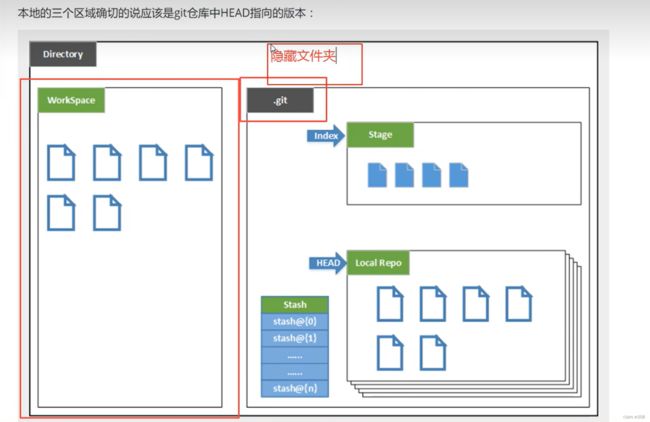
2.Git基本理论
- Workspace:工作区,就是平时存放项目代码的地方
- Index/Stage:暂存区,用于临时存放你的改动,事实上它只是一个文件,保存即将提交到文件列表信息
- Repository:仓库区(或本地仓库),就是安全存放数据的位置,这里面有你提交到所有版本的数据。其中HEAD指向最新放入仓库的版本
- Remote:远程仓库,托管代码的服务器,可以简单的认为是项目组中的一台电脑用于远程数据交换
3.Git工作流程


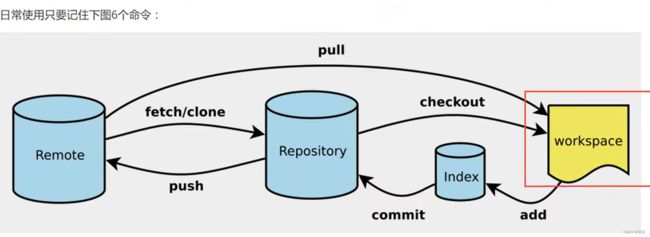 4.Git创建本地仓库
4.Git创建本地仓库
1.创建全新的仓库:创建全新的仓库,需要用Git管理的项目的根目录执行:
#在当前目录新建一个Git代码库
$ git init使用操作命令之前:
 使用操作命令之后 :
使用操作命令之后 :
克隆远程仓库:是将远程服务器上的仓库完全镜像一份至本地
#克隆一个项目和它的真个代码历史(版本信息)
$ git clone [url]
//[url] 也就是地址
5.Git文件操作
#查看指定文件状态
git status [filename]
#查看所有文件状态
git status
#添加所有文件到暂存区
git add
#提交暂存中的内容到本地仓库
# -m 表示提交信息
git commit -m “消息内容”
使用 git add . 操作之后: 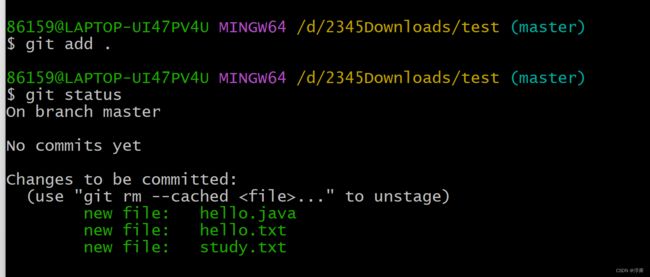
Git的分支


多个分支如果并行执行,就会导致我们代码不冲突,也就是同时存在多个版本!
如果同一个文件在合并分支时都被修改了则会引起冲突:解决的办法是我们可以修改冲突文件后重新提交!选择要保留他的代码还是你的代码!
如果了冲突了就需要协商即可!
master主分支应该非常稳定,用来发布新版本,一般情况下不允许在上面工作,工作一般情况下在新建的dev分支上工作,工作完后,比如上要发布,或者说dev分支代码稳定后可以合并到主分支master上来。
三、数据库
JDBC:即Java 数据库连接,它是一种可以执行 SQL 语句的 Java API。
JDBC为数据库开发提供了标准的API,所以使用JDBC开发的数据库可以跨平台运行,而且可以跨数据库运行。

1.数据库的概念
- 所谓安装Mysql数据库,就是在主机安装一个数据库管理系统(DBMS),这个管理程序可以管理多个数据库。DBMS(database)
- 一个数据库中可以创建多个表,以保存数据(信息)。
- 数据库管理系统(DBMS)、数据库和表的关系如图所示:示意图
数据库的三层结构;
Mysql数据表-普通表的本质仍然是文件

表的一行称之为一条记录--> 在Java程序中,一条记录往往使用对象表示