多线程小知识
多线程
- 多线程环境使用哈希表
-
- HashMap
- Hashtable
- ConcurrentHashMap
- 死锁
-
- 死锁是什么
-
- 两者之间的死锁
- 多人之间的死锁
- 死锁产生的四个必要条件:
-
- 互斥使用
- 不可抢占
- 请求和保持
- 循环等待
- 不同的锁
-
- ReentrantLock
- Synchronized和ReentrantLock之间的区别:
- 具体选择
- Synchronized
- 加锁工作过程
-
- 偏向锁
- 轻量级锁
- 重量级锁
- 锁消除
- 锁粗化
- 线程池
-
- ThreadPoolExecutor构造方法
- 执行流程
- CAS && ABA
-
-
- CAS
- ABA
-
前几次给小小的给多线程做了一些小铺垫,现在我们就来稍微唠唠多线程中一些比较有意思的知识!
多线程环境使用哈希表
HashMap
原来我们学习的集合类,大部分都不是线程安全的,HashMap也不是线程安全的类,为此我们搞出了Hashtable以及ConcurrentHashMap
Hashtable
HashTable知识简单粗暴地给一些重要方法加上了锁,换言之,只要在多线程环境下使用了Hashtable,就会有阻塞的情况发生.

我们之间说过了只要是使用了synchronized,那么你写出来的代码大概率就和高效无缘了,之前我们写懒汉模式的时候,还要处处计较,我们当然可以无脑加锁,但是那样子就不专业了.
这边给put和get方法加锁,从效果上来看其实就是给Hashtable对象加锁了,我们使用的较多的方法就是这几个,所以一个Hashtable对象只有一把锁,锁冲突就会比较激烈,于是乎ConcurrentHashMap应运而生.
ConcurrentHashMap
我们要知道一个普通的哈希表的结构是,每个节点下面会挂着一串链表,每当我们想要插入或者是查询的时候,都要对数据进行哈希,找到对应链表的起始位置,然后慢慢遍历.
我们的ConcurrentHashMap并不是针对整个对象进行加锁,而是细化到了针对到了每个链表,只有当对同一个链表进行和写有关的操作的时候,才会发生锁竞争,这也就一定程度上提高了效率.
死锁
我们之前遇到到死循环和死递归,死锁就是把自己给锁死了.
死锁是什么
两者之间的死锁
我把车钥匙放在家里了,又把家里的钥匙放在了车里.
这样子是不是两者就僵住了啊.
多人之间的死锁
这里比较经典的问题就是哲学家就餐问题:
链接: 哲学家就餐
简单说一下,一座子的人都比较死板,吃饭都要先拿左手边的筷子,然后再拿右手边的筷子,同时这一桌子的人都比较绅士,如果右手边的筷子被占用,那么就要等到筷子不被占用为止,只有吃好了,他们才会放下筷子.
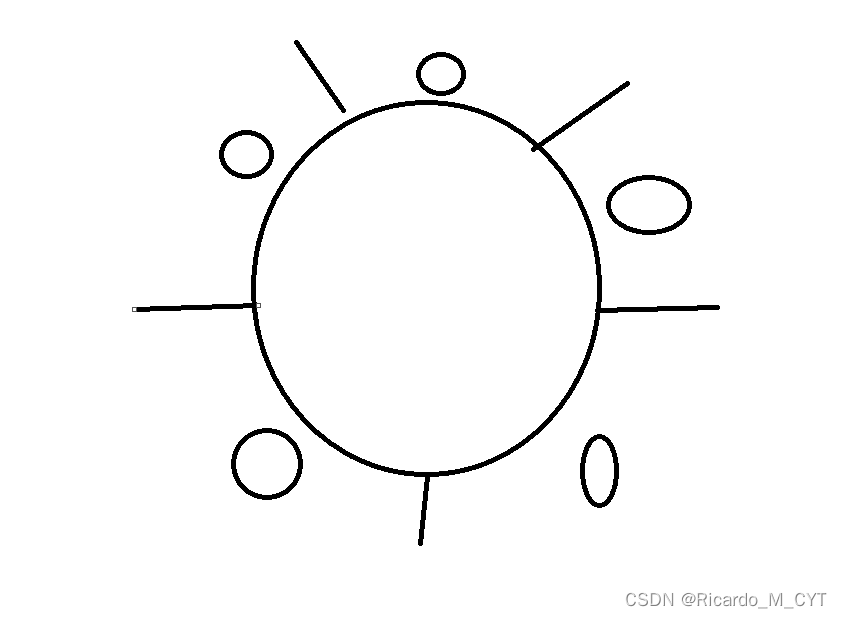
这样子如果极端情况下,这一桌子老哥同时拿起左手边的筷子,那么这一桌子的人这辈子都没办法吃完这一顿饭了.
死锁产生的四个必要条件:
互斥使用
即当资源被一个线程使用(占有)时,别的线程不能使用
不可抢占
资源请求者不能强制从资源占有者手中夺取资源,资源只能由资源占有者主动释放。
请求和保持
当资源请求者在请求其他的资源的同时保持对原有资源的占有。
循环等待
即存在一个等待队列:P1占有P2的资源,P2占有P3的资源,P3占有P1的资源。这样就形成了一个等待环路.
我们想要破局只要把上面任意一点突破了就行.
就比如哲学家就餐问题,我们只要稍加变通,给每根筷子编号,把拿起走左手边的改成拿起号码小的,这样子就可以了.
不同的锁
ReentrantLock
这把锁代表着可重入锁,比我们之前的synchronized多了几个方法:
lock(): 加锁, 如果获取不到锁就死等.
trylock(超时时间): 加锁, 如果获取不到锁, 等待一定的时间之后就放弃加锁.
unlock(): 解锁
Synchronized和ReentrantLock之间的区别:
synchronized 是一个关键字, 是 JVM 内部实现的(大概率是基于 C++ 实现). ReentrantLock 是标准库的一个类, 在 JVM 外实现的(基于 Java 实现).
synchronized 使用时不需要手动释放锁. ReentrantLock 使用时需要手动释放. 使用起来更灵活, 但是也容易遗漏 unlock.
synchronized 在申请锁失败时, 会死等. ReentrantLock 可以通过 trylock 的方式等待一段时间就放弃.
synchronized 是非公平锁, ReentrantLock 默认是非公平锁. 可以通过构造方法传入一个 true 开启公平锁模式
更强大的唤醒机制. synchronized 是通过 Object 的 wait / notify 实现等待-唤醒. 每次唤醒的是一个随机等待的线程. ReentrantLock 搭配 Condition 类实现等待-唤醒, 可以更精确控制唤醒某个指定的线程.
具体选择
锁竞争不激烈的时候, 使用 synchronized, 效率更高, 自动释放更方便.
锁竞争激烈的时候, 使用 ReentrantLock, 搭配 trylock 更灵活控制加锁的行为, 而不是死等.
如果需要使用公平锁, 使用 ReentrantLock.
Synchronized
- 开始时是乐观锁, 如果锁冲突频繁, 就转换为悲观锁.
- 开始是轻量级锁实现, 如果锁被持有的时间较长, 就转换成重量级锁.
- 实现轻量级锁的时候大概率用到的自旋锁策略
- 是一种不公平锁
- 是一种可重入锁
- 不是读写锁
加锁工作过程
JVM 将 synchronized 锁分为 无锁、偏向锁、轻量级锁、重量级锁 状态。会根据情况,进行依次升级。
偏向锁
并不是真正加锁,只是在内部给了一个标志位,避免了部分开销
轻量级锁
轻量级锁大概率是通过自旋来实现的,竞争并不是很激烈,自选一会也就拿到了
重量级锁
竞争比较激烈了,自旋也不好使了,开销还大,那就老老实实挂起等待吧
锁消除
就比如在单线程环境下使用StringBuffer,本身单线程就没有多线程安全那一套,那么这里的synchronized那一套只会平白徒增消耗,我们就把它给优化掉了
锁粗化
这里的粗和细指的是锁的粒度,也就是加锁时间的长度,如果加锁粗,那么同一段代码下我们进行加锁的次数也就少了,这样子开销也就少了,我个人感觉就是如果一段代码需要加锁的地方比较多,那么我们可以使用锁粗化,避免频繁加锁销毁锁带来的开销.
线程池
线程是轻量级进程,轻量就体现在除了第一次调用线程,线程的创建调度销毁所需要的开销都远远小于进程,但是凡事都是相对的,我们的线程池所需要的开销又要小于线程,池这个概念我们并不陌生,之前我们讲的字符串常量池也是一种池.
所谓池就是一盘大杂烩,就线程池来讲,你创建好的线程都会放在线程池里面,即使后面你想要销毁线程也不会真正销毁,想要调度创建线程了,首先先去线程池里面看看,看看之前有没有创建过线程,这样子又减少了一部分开销,但是这样的存储方式必然会占用内存
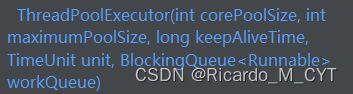
ThreadPoolExecutor构造方法
把创建一个线程池想象成开个公司. 每个员工相当于一个线程.
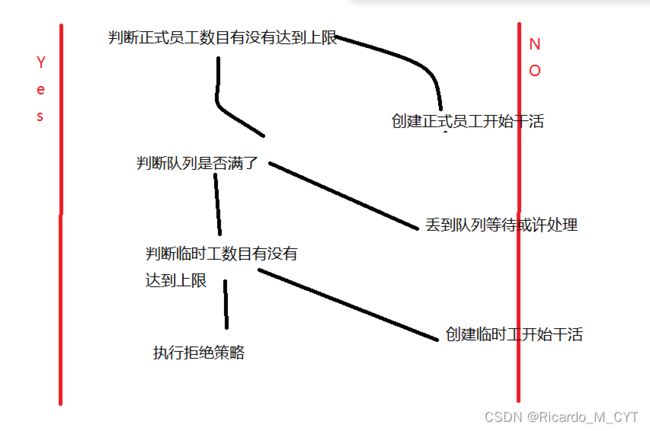
- corePoolSize: 正式员工的数量. (正式员工, 一旦录用, 永不辞退)
- maximumPoolSize: 正式员工 + 临时工的数目. (临时工: 一段时间不干活, 就被辞退).
- keepAliveTime: 临时工允许的摸鱼时间.
- unit: keepaliveTime 的时间单位, 是秒, 分钟, 还是其他值.
- workQueue: 传递任务的阻塞队列
- threadFactory: 创建线程的工厂, 参与具体的创建线程工作.
- RejectedExecutionHandler: 拒绝策略, 如果任务量超出公司的负荷了接下来怎么处理.
AbortPolicy(): 超过负荷, 直接抛出异常. 把球丢给程序猿,您自己来
CallerRunsPolicy(): 调用者负责处理
DiscardOldestPolicy(): 丢弃队列中最老的任务.
DiscardPolicy(): 丢弃新来的任务.
执行流程
CAS && ABA
CAS
CAS:compare and swap
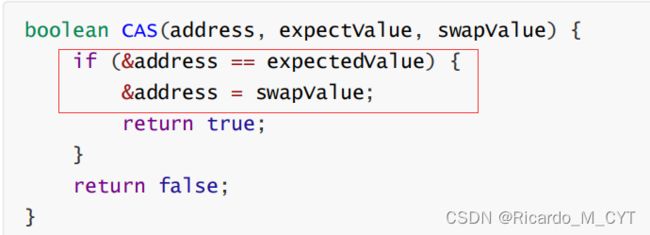
CAS也可以从某种程度上保证原子性的问题,因为CAS整个工作流程是一条指令:如果我们取到的内存的值和我们所期望的值一样,那么首先第二个参数和第三个参数就会交换,然后再把第二个参数写回到第一个参数里面.
实际上我们要保证CAS的原子性还要基于一部分的代码

只有当CAS返回为true的时候才会交换,但实际上由于多线程,不可能每一次我们我们拿到的值都和期待的一样,这样子我们就会持续进入循环,每次都会要再去获取一遍内存中的值,这样子不论如何最终我们都会执行到一次CAS
ABA
ABA问题其实也是走了一个极端,加入就在我们刚刚执行完一次CAS的同时,我们又有一个操作把本该结束循环的条件又给修改了,这样子这次CAS我们又会多执行一次,是不是听上去并没有什么的,那如果是转账呢?我们先转了10万给别人,然后同时我们又收到了十万块钱,循环的条件是money!=10万,显然我们还会执行第二次,这不就是天大的问题了吗?
如何解决ABA问题也不难,每次我们针对内存进行操作完成之后,再给版本号进行自增如果寄存器中的版本号小于内存中的版本号,那么这次操作就作废
好了今天的内容差不多就到这里了,我希望我能通过最简单的语言教会给你们基本内容.
百年大道,你我共勉!