[chapter 25][PyTorch][激活函数与GPU加速]
前言:
这里面主要介绍一下常用的激活函数与GPU 加速
目录
- tanH 函数
- sigmoid函数
- relu 函数
- leaky Relu 函数
- tf.nn.selu 扩展型指数线性单元
- GPU 加速
- softplus 激活函数
- numpy 傅里叶变换
一: tanH 函数
![[chapter 25][PyTorch][激活函数与GPU加速]_第1张图片](http://img.e-com-net.com/image/info8/36e4d69c28c6499bb697c3e61cc187f4.jpg)
定义:
![]()
应用:
该激活函数在RNN 模型中应用比较广泛
导数:
![[chapter 25][PyTorch][激活函数与GPU加速]_第2张图片](http://img.e-com-net.com/image/info8/5ec5d6f2f2044c719c6be93be31cf7a4.jpg)
导数区间:
[0,1]
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 4 16:45:50 2023
@author: chengxf2
"""
import numpy as np
import torch as t
import matplotlib.pyplot as plt
def activate():
x = t.linspace(-5.0, 5.0, 20)
y = t.tanh(x)
plt.xlabel('x')
plt.ylabel('tanH')
plt.plot(x, y, 'r--',label="tanH")
plt.grid(True)
plt.legend()
print(x)
activate()二 sigmoid函数
![[chapter 25][PyTorch][激活函数与GPU加速]_第3张图片](http://img.e-com-net.com/image/info8/94fad8bf05ce489ebccaaf0f04bca746.jpg)
定义:
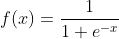
应用:
机器学习classifcation ,多层神经网络应用较少,存在梯度弥散问题
导数
![]()
导数区间
[0,0.25]
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 4 16:45:50 2023
@author: chengxf2
"""
import numpy as np
import torch as t
import matplotlib.pyplot as plt
def activate():
x = t.linspace(-5.0, 5.0, 20)
y = t.sigmoid(x)
plt.xlabel('x')
plt.ylabel('sigmoid')
plt.plot(x, y, 'r--',label="sigmoid")
plt.grid(True)
plt.legend()
print(x)
activate()三 relu 函数
relu(x) =max(0,x)
定义:
应用:
比较广泛,参考知乎
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度 时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现 梯度消失 的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
第三,ReLu会使一部分神经元的输出为0,这样就造成了 网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
第四,relu函数的导数计算更快,程序实现就是一个if-else语句,而sigmoid函数要进行浮点四则运算。
导数:
![]()
导数区间:
0 or 1
x = t.linspace(-5.0, 5.0, 20)
y = t.relu(x)四 leaky Relu 函数
修正线性单元(Rectified linear unit,ReLU)是神经网络中最常用的激活函数
Leaky ReLU 激活函数首次在该论文关于声学模型应用中被提出,
![[chapter 25][PyTorch][激活函数与GPU加速]_第4张图片](http://img.e-com-net.com/image/info8/af2c2fb09dd341358dbcb27f650939d0.jpg)
梯度:
ReLu 在x<0时候,梯度为0,存在梯度弥散现象。
leaky ReLu x<0, 梯度为
代码
torch.nn.LeakyReLU(negative_slope=0.01, inplace=False)
- negative_slope:x为负数时的需要的一个系数,控制负斜率的角度。默认值:1e-2
- inplace:可以选择就地执行操作。默认值:False
五: tf.nn.selu 扩展型指数线性单元
在权重用tf.keras.initializers.lecun_normal初始化前提下能够对神经网络进行自归一化.
不可能出现梯度爆炸或者梯度消失问题。需要和Dropout的变种AlphaDropout一起使用
![[chapter 25][PyTorch][激活函数与GPU加速]_第5张图片](http://img.e-com-net.com/image/info8/62d36201e4ba4a779c262251e10e3740.jpg)
六 softplus 激活函数
![[chapter 25][PyTorch][激活函数与GPU加速]_第6张图片](http://img.e-com-net.com/image/info8/586fd30e1bba486a8d8a2e66bc4c62bd.jpg)
七 GPU 加速
首先通过任务管理器查看一下当前的GPU,CPU情况
我的Lenovo T14 有两个GPU0, GPU1(独立显卡)
![[chapter 25][PyTorch][激活函数与GPU加速]_第7张图片](http://img.e-com-net.com/image/info8/efcd707ae567439494e1c383a7cdc159.jpg)
![[chapter 25][PyTorch][激活函数与GPU加速]_第8张图片](http://img.e-com-net.com/image/info8/2ab89f7dec9c48c2a88c6b18df5de2bb.jpg)
我们开始初始花了一个GPU device,使用了GPU 0
后面把 model, loss, data 陆续放到对应的GPU上进行训练
八 numpy 傅里叶变换
def fft_data(input_data):
ffts = []
for block in range(input_data.shape[0]):
for channel in range(input_data.shape[-1]):
input_data[block, :, channel] -= input_data[block,:, channel].mean()
# print data.shape
ffts.append(np.abs(np.fft.rfft(input_data[block,:,channel])))
mean_fft = np.stack(ffts).mean(axis=0)
return mean_fft
def plot_fft(x_axis, data_fft):
plt.plot(x_axis, data_fft, 'tab:red')
plt.xlabel('Frequency', fontsize=17)
plt.ylabel('Amplitude', fontsize=17)
plt.axis(xmin = 5, xmax = 70)
plt.axis(ymin = 0, ymax = 20)
plt.tight_layout()
filename = "fft_plot_class%i.pdf"
plt.savefig(filename % (nf), format='PDF', bbox_inches='tight')
参考:
六、【TF2】Activation 激活函数_tf activation_feifeiyechuan的博客-CSDN博客