# 联邦学习-安全树模型 SecureBoost之集成学习
文章目录
- 1 联邦学习背景
- 2 联邦学习树模型方案
- 3 Ensemble Learning
-
- 3.1 集成学习
- 3.2 Bagging & Boosting
-
- 3.2.1 Bagging (bootstrap aggregating)
- 3.2.2 Boosting
- 3.2.3 Bagging,Boosting二者之间的区别
- 4 GBDT
-
- 4.1 GDBT定义
- 4.2 GBDT推导过程
- 5 番外篇
1 联邦学习背景
鉴于数据隐私的重要性,国内外对于数据的保护意识逐步加强。2018年欧盟发布了《通用数据保护条例》(GDPR),我国国家互联网信息办公室起草的《数据安全管理办法(征求意见稿)》因此数据在安全合规的前提下自由流动,成了大势所趋。这些法律法规的出台,不同程度的对人工智能传统处理数据的方式提出更多的挑战。
AI高度发展的今天,多维度高质量的数据是制约其进一步发展的瓶颈。随着各个组织对于数据的重视程度的不断提升,跨组织以及组织内部不同部门之间的数据合作将变得越来越谨慎,造成了数据大量的以孤岛的形式存在

联邦学习的本质是基于数据隐私保护一种分布式机器学习技术或机器学习框架。它的目标是在保证数据隐私安全及合法合规的基础上,在模型无损的前提实现共同建模,提升AI模型的效果,进行业务的赋能。
那么既然是建模,在工业界最近若干年比较出名的大致可以分为GBDT和神经网络了,但是由于联邦学习的特性,需要对用户的特征与Label进行隐私安全保护,所以需要采用同态加密、秘钥分享、差分隐私等隐私计算手段保障安全。但是基于此带来了比较大的挑战,神经网络的复杂运算,指数、对数等会给建模提出非常大的难题,以目前的硬件与软件加密技术还是非常困难的,但是对于SecureBoost来说,只需要进行简单的同态运算就解决,达到和Xgboost同样的建模效果,所以本篇文章会和大家分享下联邦学习的安全树模型-Secure Boost。
BTW,目前神经网络虽然比较难做安全屏障,无法很好的做到计算性能与模型性能的Balance,但是经过笔者长期的思考,已经有了一个自己认为靠谱的方案,后续会逐步验证,如果最终验证靠谱,会和大家Share出来一起分享。
由于树模型相对来说知识较多,所以无法一步到位解决清晰SecureBoost,故本文章分成以下主题来进行,主要的脉络就是:决策树 -> 集成方法Bagging & Boosting -> GBDT -> XGBoost -> Secure Boost Tree。希望读者可以通过这一系列文章,对联邦学习的SecureBoost方法有一个整体的全方位的掌握。
其实,对于树模型系列来说,笔者以前做算法的时候,也在大量的使用,并且觉得自己是理解到位的,但是在我写联邦学习安全树模型的时候,发现很多的地方并没有理解透彻,有很多细节是没有考虑到的,写着写着就会发现自己的理论厚度不够,细节没有吃透。后来也花了大量的精力和时间去充电,这个事情也让我明白了,很多东西你看起来懂了,其实并没有懂,只有去真正的用心的去做过一遍,你才有些懂了,无论做什么事情脚踏实地才是最重要的。
2 联邦学习树模型方案
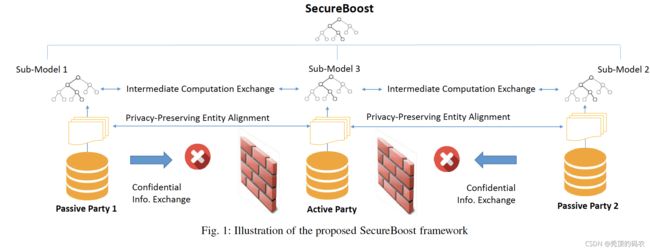
众所周知,在机器学习的前期,当深度学习没有大方异彩的时候,基本是LR、Xgboost的天下,在搜广推的场景中,基本上都可以看到Xboost的身影,基本可以说一个Xgb能用的明白,就可以在工业界占据一个位置。同时在Kaggle竞赛中,Xgb也是经常作为黑马出现。
万事万物都不是作为孤立的存在,所以针对联邦学习而言,联邦学习本质是基于隐私安全的分布式的建模,所以既要做安全的Xgb与LR等传统机器学习模型,也要做安全的深度模型。本系列文章主要介绍安全的树模型系列,计划出三章,基于上一章介绍了《联邦学习-安全树模型 SecureBoost之Desicion Tree》基础内容后,本章会继续介绍集成学习以及GBDT,关于Xgboost与联邦安全树模型会在下个章节进行描述。
SecureBoost属于Ensemble Learning集成学习的范畴,属于Boosting方法,基于残差去训练模型来拟合真实数据场景,非隐私计算的实现方式还有Xgboost、LightGBM、HistGradientBoostingClassifier等,不过过渡到这些集成学习算法之前,需要先介绍下GBDT。
3 Ensemble Learning
3.1 集成学习
集成学习(Ensemble Learning)是一种非常行之有效,并且在工业界大放异彩的机器学习方法。它本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务。也就是我们常说的“博采众长”、“三个臭皮匠顶个诸葛亮”,综合多家之长,集体的智慧,一起来解决复杂的问题,有点类似于社会中的参谋部与智囊团、智库。
集成学习可以用于分类问题,回归问题,特征选取,异常点检测等等,可以说所有的机器学习领域都可以看到集成学习的身影,在整个机器学习的演进史上承担的重要的作用,留下了浓厚的一笔,在工业界更是充当救火队员的角色,在Kaggle等国际比赛中,更是充当黑马的存在。在这里插入代码片
集成学习主要分为两种模式,Bagging与Boosting模式,这两种模式的区别主要是,弱学习器的组合方式,由于树模型是比较有效的机器学习模型,所以集成学习里面与树模型的结合非常紧密,将Bagging和Boosting分别和树模型结合分别生成:
- Bagging + 决策树=随机森林
- Boosting + 决策树=GBDT
- Boosting + 二阶可导Loss函数 = Xgboost
3.2 Bagging & Boosting
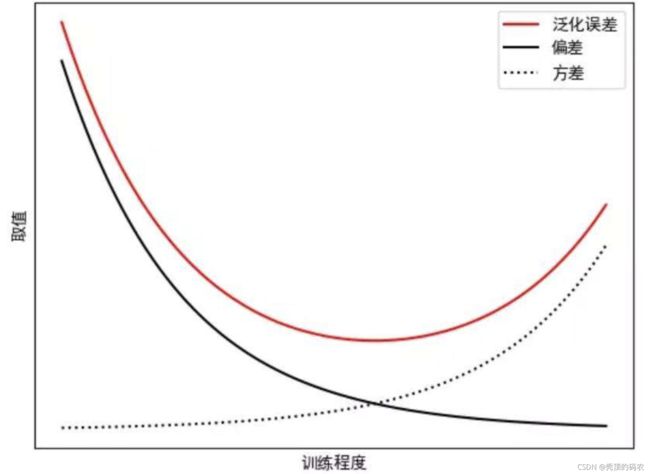
机器学习里面有两个非常重要的基础概念:Variance与Bias,就是方差与偏差,用来衡量模型,但是他们两个本身其实是矛盾的,Bagging与Boosting分布针对Variance与Bias进行探索。
bagging 的重点在于获得一个方差更小的集成模型,而 boosting则将主要生成偏差更小的集成模型(即使方差也可以被减小)。
3.2.1 Bagging (bootstrap aggregating)
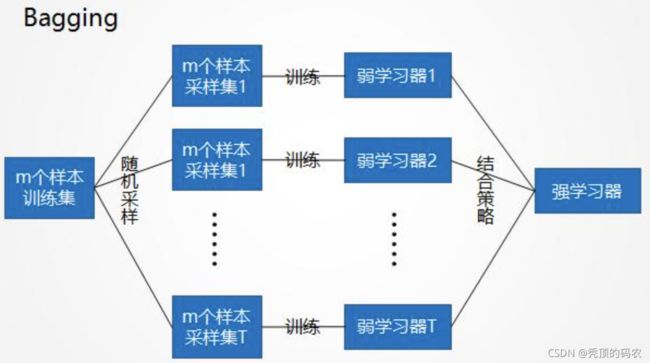
Bagging即套袋法,通过并行的计算多个弱学习器,然后将多个弱学习器的结果进行投票或者均值等粗略,进行融合凝练,表征模型的判断。
- 从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
- 每次使用一个训练集得到一个模型,k个训练集共得到k个模型。K个模型相互独立,没有依赖关系。
- 集体智慧生成最终模型:
- 对分类问题:针对K个模型的结果,采用投票的方式得到分类结果;
- 对回归问题,针对K个模型的结果,计算数学期望作为最后的结果。
3.2.2 Boosting
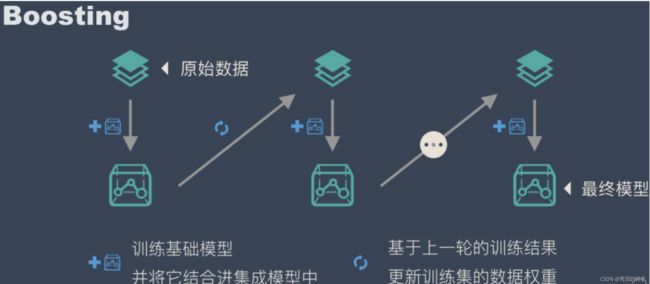
其主要思想是将弱学习器组装成一个强学习器,并且通过一些列的顺序迭代过程,通过弱学习器的迭代组合,调整关键样本权重,训练出一组弱分类器,进行模型的迭代。
关于Boosting的两个核心问题:
- 如何改变训练数据的概率分布与样本权重?
通过提高那些在前一轮被弱学习器判断错误的样例的权值,减小前一轮判断准确的样本权值,达到对错误信息的纠正的目标,亦或者通过学习残差的方式进行拟合。
- 如何组合弱分类器?
通过加法模型将弱分类器进行线性组合,比如AdaBoost通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值吗,亦或GBDT的基于残差的加法模型组合,通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型。
3.2.3 Bagging,Boosting二者之间的区别
Bagging和Boosting的区别主要有以下三点:
-
样本选择上:
- Bagging:采取Bootstraping的是随机有放回的取样,从原始集中选出的各轮训练集之间是独立的。
- Boosting:Boosting的每一轮训练的样本是固定的,改变的是每个样本的权重。而权值是根据上一轮的计算结果进行调整。
-
样例权重:
- Bagging:采取的是均匀取样,每个样本的权重相同。
- Boosting:根据错误率调整样本权重,错误率越大的样本权重越大。
-
训练推理:
- Bagging:各个弱学习器权值相同,并且各个弱学习器可以并行计算。
- Boosting:各个弱学习器都有相应的权重,对于拟合的更好的分类器有较大的权重,并且各个弱学习器需要顺序迭代计算。
4 GBDT
其实很多人对于GBDT和Xgboost是分不清的,笔者最爱做的事情就是问很多面试者一个问题就是GDBT和Xgboost的区别。实际上这不是一个多么难的问题,上网一搜一个大把,从性能角度啊,一阶导数与二阶导数的区别啊。但是对于最本质的缺没有说清楚,所以说我们可以去网上查些资料,但是对于这些从网上获取的资料,要自己去甄别下,去提炼下,做到自己的融会贯通。
4.1 GDBT定义
下面给出定义:GBDT (Gradient Boosting Decision Tree) 梯度提升迭代决策树,是Boosting算法的一种。约束条件:
- GBDT使用的弱学习器必须是CART,且必须是回归树。
- GBDT用来做回归预测,当然也可以通过阈值的方式进行分类,不过主要是进行回归预测。
所以大家一定要记住,GBDT的弱学习器一定只能是CART树,一般是基于MSE的Loss利用最小二乘法计算一阶梯度。而Xgb的弱学习器非常灵活,一般只要求具备二阶导数就可以了。所以很多把GBDT和Xgb的概念混淆,或者只说一阶导与二阶导的区别,都是太片面的。
4.2 GBDT推导过程
GBDT的每次计算都是为了减少上次计算的残差,那么一个比较朴素的想法就是我们在残差的方向上减少梯度,进而建立新的学习器是不是就可以了呢?不错,GBDT就是这么来的。
- 首先,假设数据集是 ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) (x_1, y_1), (x_2, y_2), ..., (x_n, y_n) (x1,y1),(x2,y2),...,(xn,yn),模型是 F ( x ) F(x) F(x),去拟合这些数据。那么残差的定义是 y i − F ( x i ) y_i - F(x_i) yi−F(xi),定义本模型未拟合的部分。
- 接着,假设损失函数定义MSE(回归问题的Loss Function),那么损失函数的定义是 1 2 ∑ 0 n ( y i − F ( x i ) ) 2 \frac 1 2\sum_0^n(y_i - F(x_i))^2 21∑0n(yi−F(xi))2。
- 然后,针对损失函数进行推导 L ( y , F ( x ) ) = 1 2 ∑ 0 n ( y i − F ( x i ) ) 2 L(y,F(x)) = \frac 1 2\sum_0^n(y_i - F(x_i))^2 L(y,F(x))=210∑n(yi−F(xi))2,然后对损失函数进行一阶求导, ∂ L ∂ F ( x ) = ∂ L ( y , F ( x i ) ) ∂ F ( x i ) = F ( x i ) − y i \frac{\partial L}{\partial F(x)} = \frac{\partial {L(y,F(x_i))}}{\partial F(x_i)} = F(x_i) - y_i ∂F(x)∂L=∂F(xi)∂L(y,F(xi))=F(xi)−yi
- 然后,通过如上公式可以推导,残差与负的梯度方向相同。验证完毕。
- 所以,GBDT的分裂节点可以根据各个特征的梯度大小来进行选取。
5 番外篇
个人介绍:杜宝坤,隐私计算行业从业者,从0到1带领团队构建了京东的联邦学习解决方案9N-FL,同时主导了联邦学习框架与联邦开门红业务。
框架层面:实现了电商营销领域支持超大规模的工业化联邦学习解决方案,支持超大规模样本PSI隐私对齐、安全的树模型与神经网络模型等众多模型支持。
业务层面:实现了业务侧的开门红业务落地,开创了新的业务增长点,产生了显著的业务经济效益。
个人比较喜欢学习新东西,乐于钻研技术。基于从全链路思考与决策技术规划的考量,研究的领域比较多,从工程架构、大数据到机器学习算法与算法框架均有涉及。欢迎喜欢技术的同学和我交流,邮箱:[email protected]