linux内核之select/poll/epoll
一些主流应用IO多路复用技术,突破高并发问题,如nginx、redis、netty,分布式服务框架dubbo,大数据组件hadoop、spark、flink、hbase纷纷使用netty作为网络通信组件。
一、背景:C10K问题
The C10K problem
最早被Dan Kegel提出的,
c10k问题,指的是:服务器如何支持10k个并发连接,也就是concurrent 10000 connection(这也是c10k这个名字的由来)。由于硬件成本的大幅度降低和硬件技术的进步,如果一台服务器能够同时服务更多的客户端,那么也就意味着服务每一个客户端的成本大幅度降低。从这个角度来看,c10k问题显得非常有意义。
但是最初的服务器都是基于进程/线程模型的,新到来一个TCP连接,就需要分配1个进程(或者线程)。进程又是操作系统最昂贵的资源,一台机器无法创建很多进程。如果是C10K,就要创建1万个进程,那么就单机而言,操作系统是无法承受的(往往出现效率低下、甚至完全瘫痪)。如果是采用分布式系统,维持1亿用户在线需要10万台服务器,成本巨大,也只有Facebook、Google、Apple等巨头,才有财力购买如此多的服务器。
基于上述考虑,如何突破单机性能局限,是高性能网络编程所必须要直面的问题。这些局限和问题,最早被Dan Kegel 进行了归纳和总结,并首次系统地分析和提出了解决方案。后来,这种普遍的网络现象和技术局限,都被大家称为 C10K 问题。
1.1 C10K问题的本质:
C10K问题,本质上是操作系统的问题。对于Web1.0/2.0时代的操作系统而言, 传统的同步阻塞I/O模型都是一样的,处理的方式都是requests per second,并发10K和100的区别关键在于CPU。
创建的进程、线程多了,数据拷贝频繁(缓存I/O、内核将数据拷贝到用户进程空间、阻塞), 进程/线程上下文切换消耗大, 导致操作系统崩溃,这就是C10K问题的本质!
可见,解决C10K问题的关键就是:尽可能减少CPU等核心资源消耗,从而榨干单台服务器的性能,突破C10K问题所描述的瓶颈。
1.2 C10K问题的解决方案探讨
从网络编程技术的角度来说,主要思路为:
- 为每个连接分配一个独立的线程/进程。
- 同一个线程/进程同时处理多个连接(IO多路复用)。
1.2.1 为每个连接分配一个独立的线程/进程
这一思路最为直接。但是,由于申请进程/线程会占用相当可观的系统资源,同时对于多进程/线程的管理会对系统造成压力,因此,这种方案不具备良好的可扩展性。
这一思路在服务器资源还没有富裕到足够程度的时候,是不可行的。即便资源足够富裕,效率也不够高。
总之,此思路技术实现会使得资源占用过多,可扩展性差,在实际应用中已被抛弃。
1.2.2 同一个线程/进程同时处理多个连接(IO多路复用)
IO多路复用,从技术实现上,又分很多种。下面会逐一来看看下述各种实现方式的优劣。
1.3 引申讨论C10M问题
C10M :指单机同时处理一千万的并发请求。
二、linux内核中的select/poll/epoll
linux内核中的select/poll/epoll是属于五种linux IO模型中的IO多路复用,IO多路复用(也叫事件驱动模型):指的是可以在同一进(线)程中处理多个网络连接。
I/O 多路复用技术在 I/O 编程过程中,当需要同时处理多个客户端接入请求时,可以利用多线程或者 I/O 多路复用技术进行处理。I/O 多路复用技术通过把多个 I/O 的阻塞复用到同一个 select 的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。
与传统的多线程/多进程模型比,I/O 多路复用的最大优势是系统开销小,系统不需要创建新的额外进程或者线程,也不需要维护这些进程和线程的运行,降低了系统的维护工作量,节省了系统资源。
I/O多路复用的主要应用场景如下:
- 服务器需要同时处理多个处于监听状态或者多个连接状态的套接字
- 服务器需要同时处理多种网络协议的套接字。
和多线程与多进程(单个线程,单个进程都是处理一个请求)相比。可以避免大量线程的切换。
进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的。
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
1. 保存处理机上下文,包括程序计数器和其他寄存器。
2. 更新PCB信息。
3. 把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列。
4. 选择另一个进程执行,并更新其PCB。
5. 更新内存管理的数据结构。
6. 恢复处理机上下文。
注:总而言之就是很耗资源
线程切换:
系统内核调度的对象是线程,因为线程是调度的基本单元(进程是资源拥有的基本单元,进程的切换需要做的事情更多),而线程的调度只有拥有最高权限的内核空间才可以完成,所以线程的切换涉及到用户空间和内核空间的切换,也就是特权模式切换,然后需要操作系统调度模块完成线程调度(taskstruct),而且除了和协程相同基本的 CPU 上下文,还有线程私有的栈和寄存器等。
2.1 网络的发展过程
阻塞IO(BIO)
非阻塞IO(NIO)
IO多路复用第一版(select/poll)
IO多路复用第二版(epoll)
信号驱动IO
异步IO (AIO)
- Linux环境下的network IO?
- 用户空间与内核空间
-
- 操作系统采用虚拟存储器,并将虚拟存储器分为内核空间与用户空间,虚拟存储对于研发人员来说,可以不关注内存问题。
- 内核空间(Kernel Space):独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。可以执行任意命令,调用系统的一切资源。
- 用户空间(User Space):用户程序的运行空间。为了安全,它们是隔离的,即使用户的程序崩溃,内核也不会受到影响。只能执行简单的运算,不能直接调用系统资源,必须通过系统接口(system call),才能向内核发出指令。

网络IO的本质是socket的读取,socket在linux系统被抽象为流,IO可以理解为对流的操作。
2.1.1阻塞IO(BIO)
2.1.1.1基本的socket模型(编写一个server的步骤是怎么样的?)
| 代码(c) |
释义 |
|
|
1、serverfd=Socket(opt) 调用Socket()方法创建一个对应的serverfd(文件描述符) 2、Bind(serverfd,address) 调用Bind()方法将fd和指定的地址(ip+port)进行绑定 3、Listen(serverfd) 调用Listen()方法监听前面绑定时指定的地址 4、clientfd=Accept(serverfd) 进入无线循环循环等待接手客户端连接请求
accept方法为阻塞方法,当客户端与服务端建立连接之后,开始返回。 以TCP为例,发生在三次握手之后,返回值是clientfd(一个标识客户端连接的网络描述符) 后续整个网络通信过程,数据的读写都是基于客户端clientfd操作。 |
| 代码(java) |
释义 |
| //创建ServerSocket 对象。用来响应客户端的连接请求的。请求一旦过来。生成一个Socket 对象。 //使用生成的Socket对象和客户端的Socket 对象交互 ServerSocket server = new ServerSocket(SERVER_PORT); System.out.println("等待连接请求。。"); //该方法是一个阻塞式方法,没有连接请求过来,就一直等待,有连接过来,立即返回,并生成一个socket 对象。 Socket socket = server.accept(); System.out.println("连接成功:" + socket); |
ServerSocket封装了bind()、listen()等方法 |
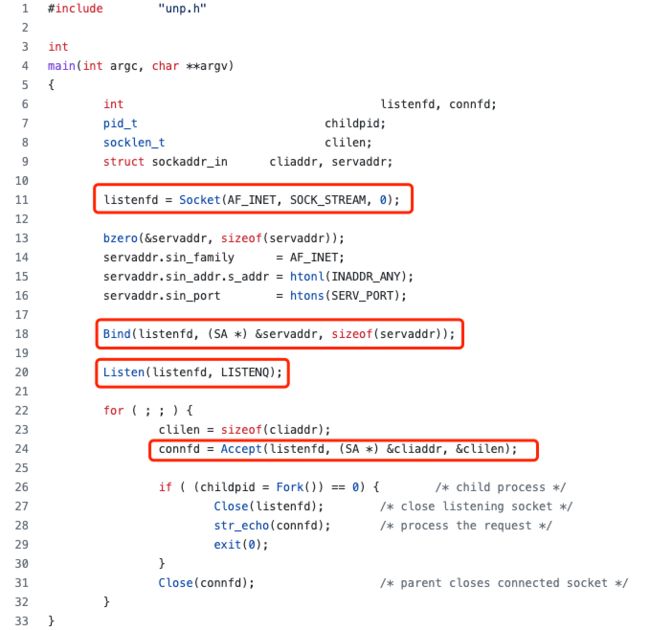
2.1.1.2 server是怎么处理建立连接后的client请求的?
| 代码(c) |
释义 |
|
|
两个核心方法。 1、n=read(clientfd,buf,size) 从客户端clientfd里读取传输进来的数据,并将数据存放到buf中(可存入数据大小为0~size),n表示写的过程中有多少字节成功 2、write(clientfd,buf,n) 往客户端clientfd写入数据n个字节的数据,写入的数据存放在buf中 |
| 代码(java) |
|
| Socket socket = new Socket(ip,LoginServer.SERVER_PORT); String str = "xxx"; //使用字节输出流将内容写出去 OutputStream os = socket.getOutputStream(); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(os)); bw.write(str); bw.newLine(); //为了立即将数据写出去,需要刷新缓冲区。 bw.flush(); ServerSocket server = new ServerSocket(SERVER_PORT); Socket socket = server.accept(); //接收客户端的发送的内容 InputStream is = socket.getInputStream(); BufferedReader br = new BufferedReader(new InputStreamReader(is)); String s = br.readLine(); |
|

2.1.1.3 server和client完整交互过程

2.1.1.4 网络连接的本质
为了解决网络连接数量。
select(1984)
poll(1997)
epoll(2002)
13 、5

2.1.1.5 阻塞IO
阻塞IO(BIO,Blocking IO)
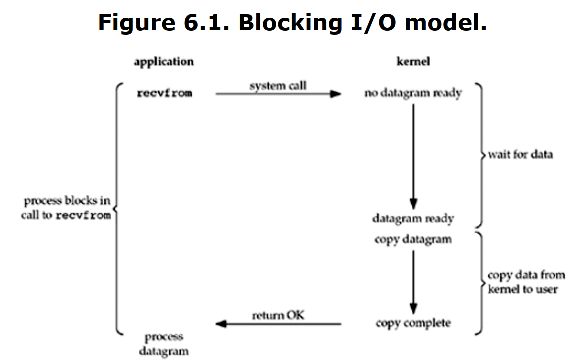
应用进程通过调用recvform()来接收客户端的数据,使用system call访问kernel,
- 内核中没有数据(需要等待数据准备好)
- 准备好之后的数据需要将数据从内核复制到用户空间
- 复制完成,返回成功标志
前两步都会被阻塞。
2.1.1.6 阻塞IO的优缺点:
优点:
- 功能层面上:可以实现client与server的通信
- 实现模式上:实现简单,通常一个client连接分配一个线程进行处理
缺点:
能支持的并发client的连接数较少,原因如下:
- 一台srever能分配的线程是有限的
- 大量的线程会造成上下文切换过多而影响性能
2.1.1.7 思考:怎么改进?(引出非阻塞IO(NIO))
核心矛盾:之所以一个client连接分配一个线程是因为处理客户端的读写是阻塞式的,为避免该阻塞影响后续接收新的client连接,所以将阻塞逻辑交由单独线程处理。
2.1.2 非阻塞IO(NIO)
直观改进思路:
阻塞IO(BIO)------内核改进支持---->非阻塞IO(NIO)

百万级一个连接目标。为避免该阻塞影响后续接收新client的连接,需要将阻塞逻辑并发线程执行,异步处理,这就是核心矛盾。
这个阶段的的实现需要内核支持,是内核支持之后暴露给上层应用实现。
程序反复轮询调用,看是否内核数据准备好。
2.1.2.1 阻塞IO与非阻塞IO的区别?

阻塞IO和非阻塞IO的主要区别在于内核中数据尚未就绪时,如何处理。
对于非阻塞IO,则直接返回给用户EWOULDBLOCK错误;
而阻塞IO则一直处于阻塞状态,直到数据就绪并从内核态拷贝到用户态后才返回。
2.1.2.2 如何设置非阻塞呢?
| 方法1:通过socket()方法中的type参数来指定为SOCK_NONBLOCK即可设置该socket为 非阻塞方式。
linux手册:socket(2) - Linux manual page |
int socket(int domain, int type, int protoco); |
| 方法2:通过fcntl()方法中args参数设置为O_NONBLOCK即可设置该socket为非阻塞方式
linux手册:fcntl(2) - Linux manual page |
int fcntl(int fd, int cmd, .../* arg*/); fcntl(socket_fd, F_SETFL, flags |O_NONBLOCK) |


2.1.2.3 思考:非阻塞IO优缺点
优点:
将socket设置成非阻塞后,在读取时如果数据未就绪就直接返回。 得益于非阻塞的特性可以通过一个线程管理多个client连接
缺点:
需要不断的轮询询问内核,数据是否已就绪,涉及很多无效的、太频繁的系统调用(system call),浪费CPU时间。
2.1.2.4 思考:怎么改进?(引出IO多路复用第一版)
核心矛盾:
涉及很多次无用的、频繁的系统调用的原因是:非阻塞socket在read时并不知道什么时候数据会准备好了,所以需要不断主动询问。如何改进呢?
2.1.3 IO多路复用(IO Mutilplexing)
优化点如下:
- 当数据有的时候,直接通知你,不需要你不断询问。
- 优化点:系统调用次数(O(N))单个请求,将原先的单个请求改为批量请求。
2.1.3.1 select
一个select可以传多个客户端,传多个网络描述符。请求内核,当内核有数据时,来通知客户端。
Figure 6.3. I/O multiplexing model
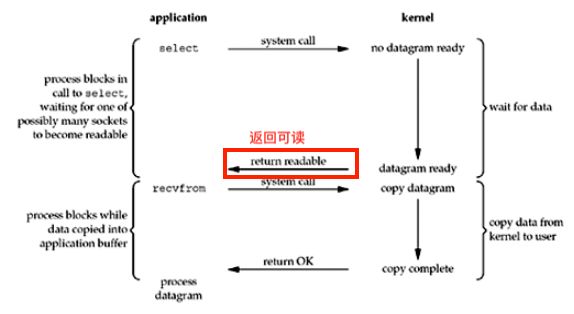
当有了I/O复用,我们就可以调用select或poll,阻塞在这两个系统调用的某一个之上,而不是阻塞在真正的I/O系统调用上。
进程受阻于select调用,等待可能多个套接字中的任一个变为可读。
IO多路复用主要复用的是系统调用。从原先非阻塞情况下的多个client需要各自多次发送recvfrom系统调用
去不断询问内核数据是否已就绪;转变成了现在通过一次系统调用select/poll由内核主动通知用户哪些client 数据已就绪(read、write、accept等事件)。大大减少了无效的系统调用次数。
复用:可以通过单个线程,管理多个client的连接。通过提供select/poll这些batch接口来批量处理client请求。主要复用的是系统调用。
单个client--->batch调用。
2.1.3.1.1 NIO 与 IO多路复用的区别
IO多路复用主要复用的是系统调用。从原先非阻塞情况下的多个client需要各自多次发送recvfrom系统调用
去不断询问内核数据是否已就绪;转变成了现在通过一次系统调用select/poll由内核主动通知用户哪些client 数据已就绪(read、write、accept等事件)。大大减少了无效的系统调用次数。
2.1.3.1.2 select核心接口
| select()定义 |
实际举例 |
||
| #include |
As an example, we can call select and tell the kernel to return only when:
|
||
| select函数 各参数含义 |
maxfdp1 |
表示被select管理的描述符个数。值为最大描述符+1.不是描述符最大值。 |
|
| fd_set |
表示一组描述符集合, select中是用一个位数组来实现的,一个描述符占一位 |
||
| readset、 writeset、 exeptset |
select将客户端事件分开管理。可读事件集合、可写事件集合、异常事件集合。这三者都可以填null |
||
| timeout |
IO多路复用这里:立即返回=0;>0:表示指定的正常超时时间;<0:永远等待 超时时间有三种语义:永远等待(null)、正常超时、立即返回(0),指的是struct结构的两个参数 |
||
| 其他接口定义 |
void FD_ZERO(fd_set *fdset) ; /* 清空 */ void FD_SET(int fd, fd_set *fdset); /* 向集合中增加客户端*/ void FD CLR(int fd, fd_set *fdset) ; /* 从集合中删除客户端 */ int FD_ISSET(int fd, fd_set *fdset) ; /* 判断客户端在不在集合中 */ |
For example, to define a variable of type fd_set and then turn on the bits for descriptors 1,4, and 5, we write fd_set rset; FD ZERO(&rset); /* initialize the set: all bits off */ FD SET(1, &rset); /* turn on bit for fd 1*/ FD SET(4, &rset); /* turn on bit for fd 4*/ FD SET(5, &rset); /* turn on bit for fd 5*/ |
|
| fd_set实现 |
What we are describing, an array of integers using one bit per descriptor is just one possible way to implement select Nevertheless, it is common to refer to the individual descriptors within a descriptor set as bits, as in turn on the bit for the listening descriptor in the read set.' We will see in Section 6.10 that the poll function uses a completely different representation: a variable-length array of structures with one structure per descriptor. |
||
| select超时参数含义: 告知内核等待时间。 |
We start our description of this function with its final argument, which tells the ker- nel how long to wait for one of the specified descriptors to become ready. A timeval structure specifies the number of seconds and microseconds. struct timeval { long tv_ sec; /* seconds */ long tv_usec; /* microseconds */ }; There are three possibilities: 1、 Wait forever——Return only when one of the specified descriptors is ready for I/O. For this, we specify the timeout argument as a null pointer. 2、 Wait up to a fixed amount of time—Return when one of the specified descriptors is ready for I/O, but do not wait beyond the number of seconds and microseconds specified in the timeval structure pointed to by the timeout argument. 3、 Do not wait at all—Return immediately after checking the descriptors. This is called polling. To specify this, the timeout argument must point to a timeval structure and the timer value (the number of seconds and microseconds speci- fied by the structure) must be 0. |
||
| select maxfdp1参数含义: plus 1 |
Any of the middle three arguments to select, readset, writeset, or exceptset, can be specified as a null pointer if we are not interested in that condition(对哪个事件不感兴趣,可以设置为null). Indeed, if all three pointers are null, then we have a higher precision timer than the normal Unix sleep function (which sleeps for multiples of a second).(都为null,是一个高精度的sleep函数) The poll function provides similar functionality. Figures C.9 and C.10 of APUE show a sleep_us function implemented using both select and poll that sleeps for multiples of a microsecond. The maxfdp1 argument specifies the number of descriptors to be tested. Its value is the maximum descriptor to be tested plus one (hence our name of maxyfdp1). The descriptors 0,1,2, up through and including maxfdp1-1 are tested. The constant FD_SETSIZE, defined by including |
||
| 为什么需要maxfdp1? |
The reason this argument exists, along with the burden of calculating its value, is purely for efficiency. Although each fd_set has room for many descriptors, typically 1,024, this is much more than the number used by a typical procesp. The kernel gains efficiency by not copying unneeded portions of the descriptor set between the process and the kernel, and by not testing bits that are always 0 (Section 16.13 ofTCPv2).(内核通过不在进程和内核之间复制描述符集不需要的部分,以及不计算始终为0的位来提高效率) |
||
| 使用示例 |
|
||


2.1.3.2 poll
poll和select要解决的问题是一致的,但是实现方式不一样
2.1.3.2 poll核心接口
| poll()定义 |
pollfd定义 |
||
| #include 前两个参数构成一个动态数组 |
struct pollfd { int fd; /* descriptor to check */ short events; /*events of interest on fd */ short revents; /*events that occurred on fd */ }; |
||
| poll事件定义 |
Constant:
poll识别三类事件: 普通(normal)、优先级带(priority band)、高优先级(priority) |
||
| poll函数 各参数含义 |
fdarray |
fdarray参数为传入的pollfd数组的首地址,该数组中的每一个元素为 一个pollfd结构体对象,关联一个管理的描述符fd |
|
| nfds |
nfds传入的值为fdarray数组的长度,表示管理的描述符个数。主要原因在于前面的fdarray是一个可变长度的数组。因此需要指定数组长度。 |
||
| timeout |
timeout有三种取值无限等待(INFTIM)、立即返回不阻塞(0)、等待指 定的超时时间(timeout)。 备注:INFTIM是一个负值。 |
||
| 使用示例 |
|
||


2.1.3.3 select和poll区别?
| 维度 |
select |
poll |
| 实现 |
select底层实现是采用位数组来实现的。 一个描述符对应一位 |
poll底层是通过pollfd结构体来实现的,管理的描述符通过pollfd链表来组织,一个描述符对应一个pllfd对象 |
| 用法不同 |
select默认大小是FD_SETSIZE(1024) 修改的话,需要修改配置参数同时重 新编译内核来实现。 |
polI是采用变长数组管理的,因此理论上可 以支持管理海量连接 |
| 相同点 |
1.二者都属于IO多路复用第一版的经典实现 2.二者在调用时,都需要从用户态拷贝管理的全量描述符到内核态; 返回时都从内核态拷贝全量的描述符到用户态; 再由用户态遍历全量的描述符判断哪些描述符有就绪事件 |
|
2.1.3.3.1 思考:IO多路复用第一版有什么问题?(优缺点)
优点:充分利用了一次系统调用select(/poll0就可以实现管理多个client的事件(read、 write、 accept等)。大大降低了之前非阻塞IO时频繁无效的系统调用。 核心思路是:将主动询问内核转变为等待内核通知,提升了性能
缺点:每次select()、poll() 都需要将注册管理的多个client从用户态拷贝到内核态。在管理百万连接时,由拷贝带来的资源开销较大,影响性能
2.1.3.3.2 思考:怎么改进(引出IO多路复用第二版)
核心矛盾: 从主动轮询转变为被动通知,确实提升了性能。但select()、poll() 每次调用都需要拷贝管理的全量 的fd到内核态,导致影响性能,有没有办法改进呢?
2.1.3.4 epoll
改进思路:第一版:拷贝、模糊通知-------内核改进支持----->第二版:不拷贝、明确通知
2.1.3.4.1 epoll核心接口
epoll三大核心接口:epoll_create()、epoll ctl()、epoll_wait()
| epoll_create()定义:创建一个epoll |
描述 |
||
| #include #include |
备注: 1.从linux2.6.8以后,size参数已经被忽略,但必须大于0 2.epoll_create()创建返回的epollfd指向内核中的一个epol实例,同时该epollfd用来调 用所有和epolI相关的接口(epoll_ctl()、 epoll-wait()) 3.当epollfd不再使用时,需要调用close()关闭。当所有指向epoll的文件描述符关闭后, 内核会摧毁该epoll实例并释放和其关联的资源 4.成功返回时,返回大于0的epollfd。失败时返回-1,根据errno查看错误 |
||
| epoll_ctl()定义: epoll的事件注册函数,epoll_ctl向 epoll对象中添加、修改或者删除感兴趣的事件 |
描述 |
||
| #includecsys/epoll.h> int epol1_ctl(int epfd, int op, int fd, struct epol1_event *event) |
各参数含义:
将哪个客户端(fd)的哪些事件(event)交给哪个epoll(epfd)来管理(op:增删改) |
||
| epoll _wait()定义: 检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。 |
描述 |
||
| #include event检测: if(event& EPOLLHUP){/*事件类型*/ ... } if(event &(EPOLLPRII| EPOLLERRI| EPOLLHUP)) { ... } |
各参数含义:
|
||
| 使用示例 |
|


2.1.3.4.2 epoll的触发模式
epoll的ET模式和LT模式(触发模式)
| 维度 |
ET (edge-trigger)模式 |
LT (level-trigger )模式 |
| 触发时机 |
仅当监控的描述符有事件就绪时触发 |
当监控的描述符有事件就绪或就绪事件未完全处理完时都会触发 |
| 性能消耗 |
相同场景下ET模式所涉及的系统调用次数较少 |
相同场景下LT模式所涉及的系统调用次数相对较多 |
| 编程难度 |
难度较高、数据完整性交由上层用户态保证 |
难度较低、数据完整性交由内核来保证;epol默认模式就是LT模式 |
| 相同点 |
都属于epol内置的触发模式 都可以实现网络传输功能 |
|
2.1.3.4.3 epoll的实现
|
|
epoll_create() |
在内核中分配一段空间,并初始化管理监听描述符的数据结构: 红黑树、就绪事件链表 |
| epoll_ctl() |
暴露给上层用户的对底层红黑树的增删改接口:
|
|
| epoll_wait() |
可从就绪事件链表中获取就绪事件关联的描述符, 然后填充到 events中并返回上层用户。 |
|
| 就绪事件迁移 |
当内核监听到有就绪事件中断时就会将就绪事件 从红黑树迁移 一份到就绪事件链表中 |
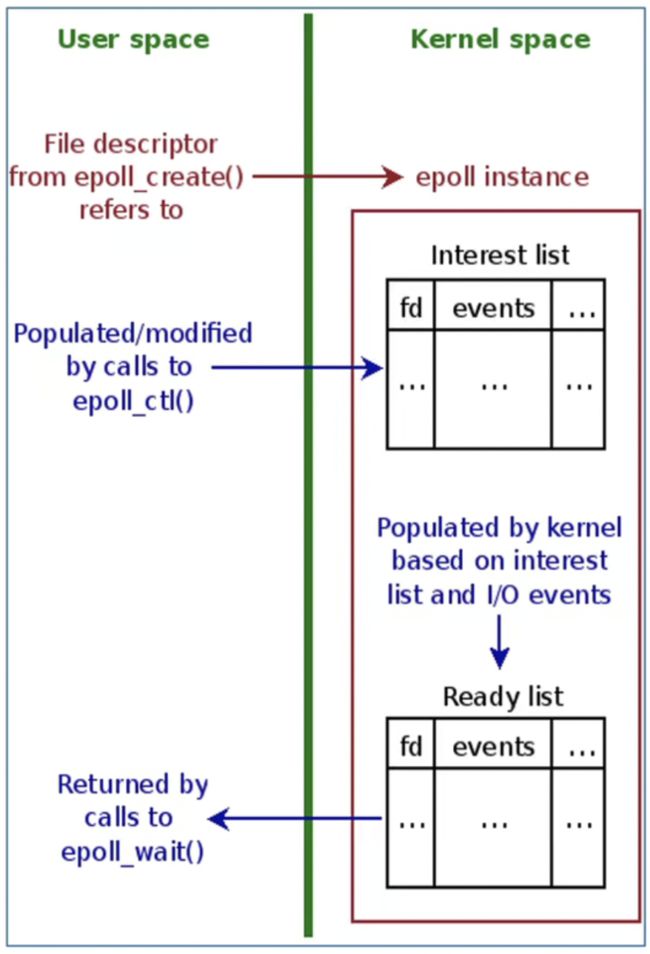
2.1.3.4.4 epoll的数据结构:

2.1.3.4.5 epoll源码分析
《深入理解nginx》 下期
2.1.4 信号驱动IO(SIGIO)

2.1.5 异步IO

在数据准备阶段&拷贝阶段都不会阻塞。
2.1.5.1 同步IO&异步IO的区别?
第二阶段由用户线程完成属于同步IO,由内核线程完成属于异步IO。
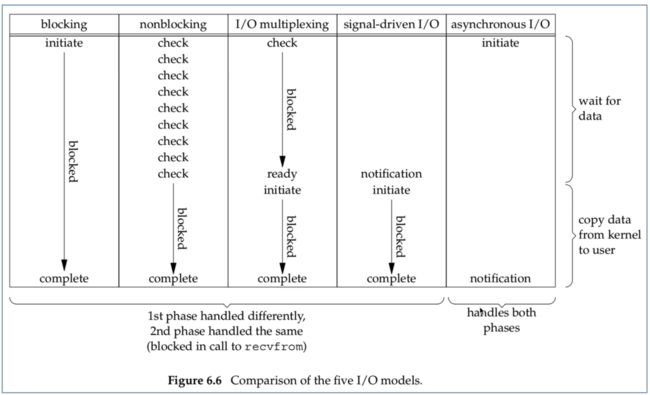
2.2 主流网络架构
Thread-Based 的架构模型
Single-Reactor单线程模型
Single-Reactor线程池模型
Multi-Reactor多线程模型
Multi-Reactor多进程模型
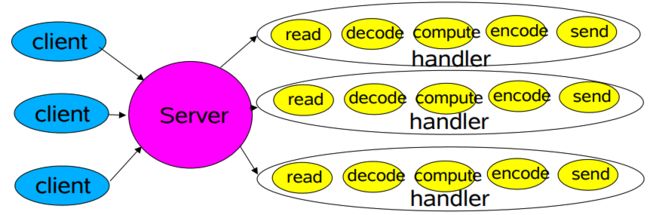
2.2.1 Thread-Based 的架构模型
| 基于线程架构的模型:thread-based |
适用场景 |
原因 |
| 并发量不大的场景 |
|
|
| 架构模型 对应于BIO (阻塞式IO) |
|
|
2.2.2 Single-Reactor单线程模型
| 基于单-reactor线程的模型:Single-Reactor单线程 |
适用场景 |
存在问题&典型实现 |
| 此处单线程主要针对IO操作而言,简而言之,I/O中的accept()、 read()、 write()都是在一个线程完成的 |
存在问题: 目前该模型中,除了I/O操作 在Reactor线程外,业务逻辑 处理操作也在Reactor线程上, 当业务逻辑处理比较耗时时, 会大大降低了I/O请求的处理 效率 典型实现: redis(4.0之前) 典型实现:redis4.0之前 |
|
| 架构模型 对应于 I/O多路复用 |
|
|

2.2.3 Single-Reactor线程池模型
| 基于单-reactor线程池的模型:Single-Reactor线程池 |
改进思路 |
存在问题 |
| 引入了线程池,用来专门处理业 务逻辑操作,提升I/O响应速度 |
虽然在引入线程池后,I/O的响 应速度提升了不少,但在管理百 万级连接、高并发大数据量时, 单个Reactor线程仍然会效率比 较底下。 |
|
| 架构模型 对应于 I/O多路复用 |
|
|
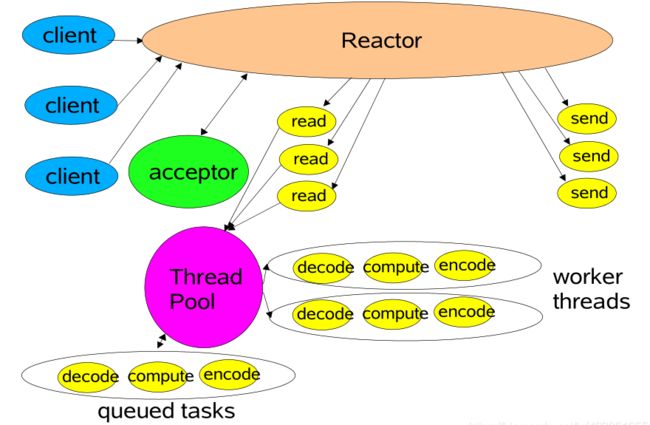
2.2.4 Multi-Reactor多线程模型 与 Multi-Reactor多进程模型
| Reactor模式-多线程模型:multi-reactor多线程 |
改进思路 |
存在问题 |
| 保留原先Single-Reactor引入的 线程池外,新扩展了Reactor线 程。引入多个Reactor线程。也 称为主从结构 |
在此处有两种扩展Reactor思路: 1.单进程(多线程)模式 2.多进程模式
典型实现: netty memcached |
|
| multi-reactor多进程 |
mainReactor进程主要负责接收客户端 连接,并将建立的客户端连接进行分发 给subReactor进程中 subReactor进程主要负责处理客户端的 数据读写和业务逻辑的处理 |
nginx |
| 架构模型 对应于 I/O多路复用 |
|
|
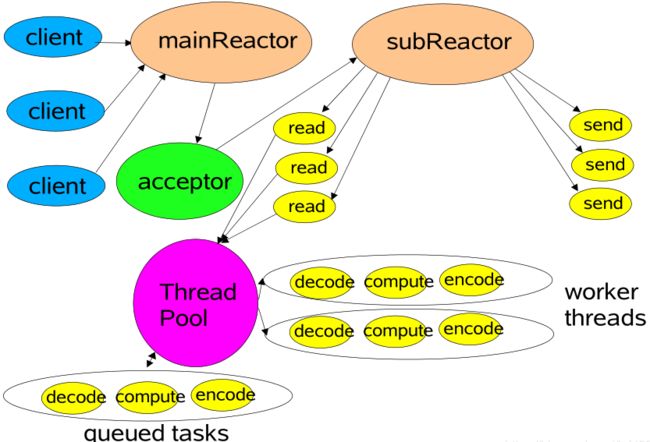
2.2.4.1 Multi-Reactor多线(进)程模型 异同点
| 维度 |
Multi-Reactor多线程模型 |
Multi-Reactor多进程模型 |
| 资源分配 |
一个server端进程中开启多个线程(1个 mainReactor线程、n个subReactor 线程)。上述线程之间如果涉及资源竞 争的话,需要通过锁来保证同步 |
有多个server进程。其中mainReactor进程 负责监听客户端连接。多个subReactor进 程负责自己管理的客户端的数据的读写和 逻辑处理。由于是多个进程在处理。所以 需要进程间通信。 |
| 资源利用 |
单进程多线程模式,对于资源的利用率稍低 |
多进程模式下,对于机器的资源利用率更 加充分 |
| 编程难度 |
难度较低。所有的逻辑都在一个进程内,通过不同模块进行解耦实现 |
难度较高,需要控制进程间通信 |
| 相同点 |
都属于经典的Multi-Reactor模型 |
|
2.2.5 网络架构总结
| 开源组件 |
epoll触发模式 |
网络模型 |
| redis |
水平触发(LT) |
Single-Reactor模型 |
| skynet |
水平触发(LT) |
Single-Reactor模型 |
| memcache |
水平触发(LT) |
Multi-Reactor(多线程)模型 |
| nginx |
边缘触发(ET) |
Multi-Reactor(多进程)模型 |
| netty |
边缘触发(ET) |
Multi-Reactor(多线程)模型 |
2.3 小结
I/O多路复用(multiplexing)的本质是通过一种机制(系统内核缓冲I/O数据),让单个进程可以监视多个文件描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作。
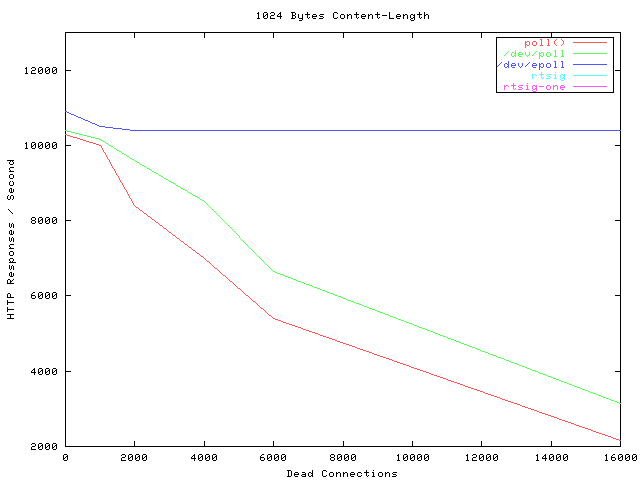
横轴Dead connections 就是链接数的意思,叫这个名字只是它的测试工具叫deadcon. 纵轴是每秒处理请求的数量。
可以看到,epoll每秒处理请求的数量基本不会随着链接变多而下降的。poll 和/dev/poll 就很惨了。
| 实现过程 |
存在问题 |
操作方式 |
底层实现 |
IO效率 |
理论最大连接数 |
fd拷贝 |
|
| 基本socket |
直接循环逐个处理各个连接(每个连接对应一个socket) |
任一文件句柄的不成功会阻塞住整个应用。 |
|||||
| select |
读文件前,单独线程,先查状态,如果ready就处理,反之不处理 |
句柄上限FD_SETSIZE+重复初始化+逐个排查所有文件句柄状态,效率不高。 |
遍历 |
数组 |
对线性表进行遍历O(N) |
1024(x86)或2048(x64) |
每次调用select,都需要把fd集合从用户态拷贝到内核态 |
| poll |
1、链表,消除上限 2、对事件进行分类,避免重复初始化调用 |
逐个排查所有文件句柄状态,效率不高。 |
遍历 |
链表 |
对线性表进行遍历O(N) |
无上限 |
每次调用poll,都需要把fd集合从用户态拷贝到内核态 |
| epoll |
只关心活跃的链接 |
无需遍历所有事件 |
回调 |
红黑树 |
事件通知,每当fd就绪,系统注册的回调函数会被调用,将就绪fd放到readyList。 O(1) |
无上限 |
调用epoll_ctl时拷贝进内核并保存,之后每次epoll_wait不拷贝 |
2.4 参考文献:
Unix-Network-Programming/tcpserv01.c at master · hailinzeng/Unix-Network-Programming · GitHub
Unix-Network-Programming/tcpservselect01.c at master · hailinzeng/Unix-Network-Programming · GitHub
https://github.com/witallwang/epoll-demo/blob/master/server.c
https://mathcs.clarku.edu/~jbreecher/cs280/UNIX%20Network%20Programming(Volume1,3rd).pdf
socket(2) - Linux manual page
《深入理解nginx》
Apache Dubbo