面临的问题
在我设计一个分析系统中,我们公司的目标是能够处理来自数百万个端点的大量POST请求。web 网络处理程序将收到一个JSON文档,其中可能包含许多有效载荷的集合,需要写入Amazon S3,以便我们的地图还原系统随后对这些数据进行操作。
传统上,我们会研究创建一个工人层架构,利用诸如以下东西:
- Sidekiq
- Resque
- DelayedJob
- Elasticbeanstalk Worker Tier
- RabbitMQ
- 还有等等其他的技术手段...
并设置 2 个不同的集群,一个用于 Web 前端,另一个用于 worker 处理进程,这样我们就可以扩大我们可以处理的后台工作量。
但从一开始,我们的团队就知道我们应该在 Go 中这样做,因为在讨论阶段我们看到这可能是一个非常大的流量系统。 我使用 Go 已有大约 2 年左右的时间,我们公司在处理业务时开发了一些系统,但没有一个能承受如此大的负载。以下是优化的过程。
我们首先创建一些结构体来定义我们将通过 POST 调用接收的 Web 请求负载,以及一种将其上传到我们的 S3 存储桶的方法。代码如下:
type PayloadCollection struct {
WindowsVersion string `json:"version"`
Token string `json:"token"`
Payloads []Payload `json:"data"`
}
type Payload struct {
// ...负载字段
}
func (p *Payload) UploadToS3() error {
// storageFolder 方法确保在我们在键名中获得相同时间戳时不会发生名称冲突
storage_path := fmt.Sprintf("%v/%v", p.storageFolder, time.Now().UnixNano())
bucket := S3Bucket
b := new(bytes.Buffer)
encodeErr := json.NewEncoder(b).Encode(payload)
if encodeErr != nil {
return encodeErr
}
// 我们发布到 S3 存储桶的所有内容都应标记为“私有”
var acl = s3.Private
var contentType = "application/octet-stream"
return bucket.PutReader(storage_path, b, int64(b.Len()), contentType, acl, s3.Options{})
}
使用 Go 协程
最初我们采用了一个非常简单的 POST 处理程序实现,只是试图将job 处理程序并行化到一个简单的 goroutine 中:
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// 将body读入字符串进行json解码
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// 分别检查每个有效负载和队列项目以发布到 S3
for _, payload := range content.Payloads {
go payload.UploadToS3() // <----- 这是不建议的做法。这里是最开始的做法。
}
w.WriteHeader(http.StatusOK)
}
对于中等负载,这可能适用于大多数公司的流量,但很快证明这在大规模情况下效果不佳。 我们期望有很多请求,但没有达到我们将第一个版本部署到生产环境时开始看到的数量级。 我们完全低估了流量。
上面的方法在几个不同的方面是不好的。 无法控制我们生成了多少个 go routines。 由于我们每分钟收到 100 万个 POST 请求,因此这段代码很快崩溃了。
进一步优化
我们需要找到一种不同的方式。 从一开始我们就开始讨论我们需要如何保持请求处理程序的生命周期非常短,并在后台进行生成处理。 当然,这是你在使用 Ruby on Rails 时必须做的,否则你将阻止所有可用的 worker web 处理器,无论你使用的是 puma、unicorn 还是 passenger(请不要进入 JRuby 讨论)。 然后我们需要利用常见的解决方案来做到这一点,例如 Resque、Sidekiq、SQS 等等,有很多方法可以实现这一点。
所以第二次迭代是创建一个缓冲通道,我们可以创建一些队列,然后把 job push到队列并将它们上传到 S3,并且由于我们可以控制job 队列中的最大数数量并且我们有足够的内存来处理队列中的 job。在这个方案中,我们认为只需要在通道队列中缓冲需要处理的 job 就可以了。
代码如下:
var Queue chan Payload
func init() {
Queue = make(chan Payload, MAX_QUEUE)
}
func payloadHandler(w http.ResponseWriter, r *http.Request) {
...
// 分别检查每个有效负载和队列项目以发布到 S3
for _, payload := range content.Payloads {
Queue <- payload // <----- 这是建议的做法。
}
...
}
然后为了实际出列作业并处理它们,我们使用了类似的东西:
func StartProcessor() {
for {
select {
case job := <-Queue:
job.payload.UploadToS3() // <-- 这里虽然优化了,但还不是最好的。
}
}
}
在上面的代码中,我们用一个缓冲队列来交换有缺陷的并发性,而缓冲队列只是推迟了问题。 我们的同步处理器一次只将一个有效负载上传到 S3,并且由于传入请求的速率远远大于单个处理器上传到 S3 的能力,我们的 job 缓冲通道很快达到了极限并阻止了请求处理程序的能力,队列很快就阻塞满了。
我们只是在避免这个问题,并开始倒计时,直到我们的系统最终死亡。 在我们部署这个有缺陷的版本后,我们的延迟率在几分钟内以恒定的速度持续增加。以下是延迟率增长图:

更好的解决方案
我们决定在使用 Go 通道时使用一种通用模式,以创建一个 2 层通道系统,一个用于 Job 队列,另一个用于控制同时在 Job 队列上操作的 Worker 的数量。
这个想法是将上传到 S3 的数据并行化到某种程度上可持续的速度,这种速度既不会削弱机器也不会开始从 S3 生成连接错误。 所以我们选择创建 Job/Worker 模式。 对于那些熟悉 Java、C# 等的人来说,可以将其视为 Golang 使用通道实现 Worker 线程池的方式。
代码如下:
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)
// Job 表示要运行的作业
type Job struct {
Payload Payload
}
// 我们可以在 Job 队列上发送工作请求的缓冲通道。
var JobQueue chan Job
// Worker 代表执行作业的 Worker。
type Worker struct {
WorkerPool chan chan Job
JobChannel chan Job
quit chan bool
}
func NewWorker(workerPool chan chan Job) Worker {
return Worker{
WorkerPool: workerPool,
JobChannel: make(chan Job),
quit: make(chan bool)}
}
// Start 方法为 Worker 启动循环监听。监听退出信号以防我们需要停止它。
func (w Worker) Start() {
go func() {
for {
// 将当前 woker 注册到工作队列中。
w.WorkerPool <- w.JobChannel
select {
case job := <-w.JobChannel:
// 接收 work 请求。
if err := job.Payload.UploadToS3(); err != nil {
log.Errorf("Error uploading to S3: %s", err.Error())
}
case <-w.quit:
// 接收一个退出的信号。
return
}
}
}()
}
// 将退出信号传递给 Worker 进程以停止处理清理。
func (w Worker) Stop() {
go func() {
w.quit <- true
}()
}
我们已经修改了我们的 Web 请求处理程序,以创建一个带有有效负载的 Job 结构实例,并将其发送到 JobQueue 通道以供 Worker 提取。
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// 将body读入字符串进行json解码
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// 分别检查每个有效负载和队列项目以发布到 S3
for _, payload := range content.Payloads {
// 创建一个有效负载的job
work := Job{Payload: payload}
// 将 work push 到队列。
JobQueue <- work
}
w.WriteHeader(http.StatusOK)
}
在我们的 Web 服务器初始化期间,我们创建一个 Dispatcher 调度器并调用 Run() 来创建 Woker 工作池并开始侦听将出现在 Job 队列中的 Job。
dispatcher := NewDispatcher(MaxWorker) dispatcher.Run()
下面是我们的调度程序实现的代码:
type Dispatcher struct {
// 通过调度器注册一个 Worker 通道池
WorkerPool chan chan Job
}
func NewDispatcher(maxWorkers int) *Dispatcher {
pool := make(chan chan Job, maxWorkers)
return &Dispatcher{WorkerPool: pool}
}
func (d *Dispatcher) Run() {
// 启动指定数量的 Worker
for i := 0; i < d.maxWorkers; i++ {
worker := NewWorker(d.pool)
worker.Start()
}
go d.dispatch()
}
func (d *Dispatcher) dispatch() {
for {
select {
case job := <-JobQueue:
// 接收一个 job 请求
go func(job Job) {
// 尝试获取可用的 worker job 通道
// 这将阻塞 worker 直到空闲
jobChannel := <-d.WorkerPool
// 调度一个 job 到 worker job 通道
jobChannel <- job
}(job)
}
}
}
请注意,我们提供了要实例化并添加到我们的 Worker 池中的最大worker 数量。 由于我们在这个项目中使用了 Amazon Elasticbeanstalk 和 dockerized Go 环境,因此我们从环境变量中读取这些值。 这样我们就可以控制 Job 队列的数量和最大大小,因此我们可以快速调整这些值而无需重新部署集群。
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)
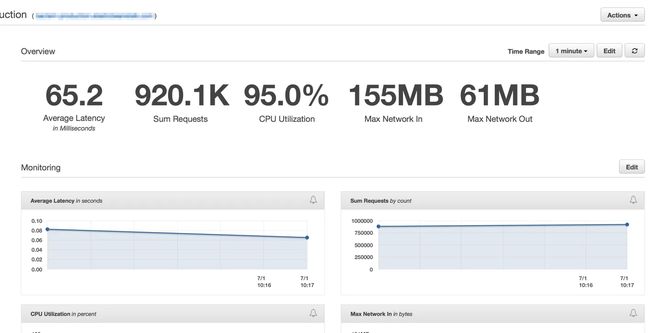
在我们部署它之后,我们立即看到我们所有的延迟率都下降到极低的延迟,并且我们处理请求的能力急剧上升。以下是流量截图:

在我们的弹性负载均衡器完全预热几分钟后,我们看到我们的 ElasticBeanstalk 应用程序每分钟处理近 100 万个请求。 我们通常在早上有几个小时的流量会飙升至每分钟超过一百万。
一旦我们部署了新代码,服务器数量就从 100 台服务器大幅下降到大约 20 台服务器。以下是服务器数量变化截图:
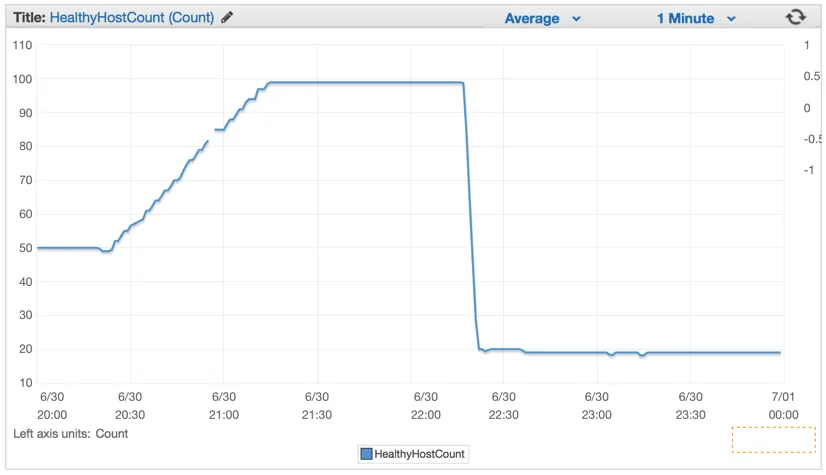
在正确配置集群和自动缩放设置后,我们能够将其进一步降低到仅 4x EC2 c4.Large 实例,并且如果 CPU 使用率超过 90% 持续 5 天,Elastic Auto-Scaling 将生成一个新实例 分钟值。以下是截图:
总结
可以看出利用 Elasticbeanstalk 自动缩放的强大功能以及 Golang 提供的开箱即用的高效和简单的并发方法,就可以构建出一个高性能的处理程序。
以上就是详解如何用Golang处理每分钟100万个请求的详细内容,更多关于Golang处理请求的资料请关注脚本之家其它相关文章!