Python编程快速入门
1、Python简介
1. python的起源
Python 的创始人为吉多·范罗苏姆(Guido van Rossum)。
1991 年,第一个 Python 解释器诞生,它是用C语言实现的,并能够调用C 语言的库文件。
2. 解释器
计算机不能直接理解任何除机器语言以外的语言,所以必须要把程序员所写的程序语言翻译成机器语言,计算机才能执行程序。将其他语言翻译成机器语言的工具,被称为编译器。
编译器翻译的方式有两种:一个是编译,另外一个是解释。两种方式之间的区别在于翻译时间点的不同。当编译器以解释方式运行的时候,也称之为解释器。
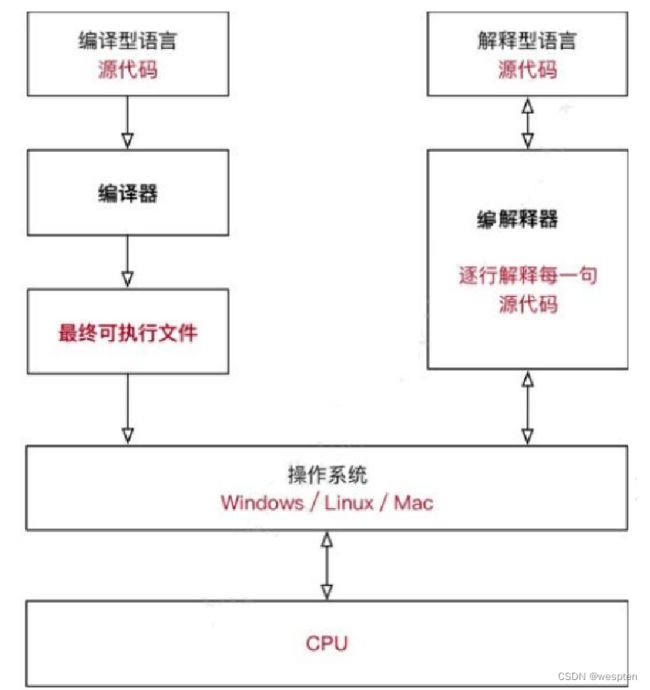
编译型语言:程序在执行之前需要一个专门的编译过程,把程序编译成为机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。如C、C++。
解释型语言:解释型语言编写的程序不进行预先编译,以文本方式存储程序代码,会将代码一句一句直接运行。在发布程序时,看起来省了道编译工序,但是在运行程序的时候,必须先解释再运行。
3. 编译型语言和解释型语言对比
执行速度:编译型语言比解释型语言执行速度快;
跨平台性:解释性语言更容易跨平台,如java,python;
2、Python运行原理
1. python程序的生命周期
(1)源码阶段(.py文件)
(2)编译阶段(PyCodeObject字节码对象)
(3)运行阶段(Python虚拟机运行字节码指令)
python程序的运行依赖python解释器,执行一个.py文件,首先是将.py文件编译成PyCodeObject字节码对象,并存入内存中。接下来,python虚拟机逐条运行字节码指令。当运行完毕后,会生成.pyc文件, .pyc文件是PyCodeObject字节码对象 在硬盘中的表现形式。
当下次再运行相同的.py文件时,假如源码没有任何改动,则不会再次将文件编译成PyCodeObject字节码对象,而是优先将,pyc文件载入到内存中去执行相应的字节码指令。
2. .pyc文件包含哪些信息
一个 pyc 文件包含了三部分信息:Python 的 magic number、pyc 文件创建的时间信息,以及 PyCodeObject 对象。
注意:一个.py文件,只有被当作module时,才会生成 .pyc 文件,也就是假如文件中有 if __name__ == '__main__' : ,将不会为这个 .py 文件生成 .pyc 文件,除非这个文件同时被其他运行的文件所引用( import )
3. 如何查看python的字节码指令
import dis
with open('xxx.py','r') as f:
# print(f.read())
co = compile(f.read(),'xxx.py','exec')
print(dis.dis(co))
3、第一个Python程序
1. HelloPython 程序
Python 源程序就是一个特殊格式的文本文件,可以使用任意文本编辑软件做 Python 的开发。
Python 程序的文件扩展名通常都是 .py。
在桌面下,新建python目录,在Python目录下新建hello.py文件,使用文本编辑器 hello.py 编辑如下内容:
print("hello world")
print("hello python")在命令终端中输入以下命令执行 hello.py:
python hello.pyprint 是 python 中我们学习的第一个函数。
print 函数的作用,可以把引号包裹的的内容,输出到屏幕上。
2. Python程序构成
1)注释
使用用自己熟悉的语言,在程序中对某些代码进行标注说明,增强程序的可读性。
- 单行注释
以 # 开头, # 右边的所有东西都被当做说明文字,而不是真正要执行的程序,只起到辅助说明作用。
示例代码如下:
# 这是单行注释
print("hello python")为了保证代码的可读性,# 后面建议先添加一个空格,然后再编写相应的说明文字。
- 多行注释
如果希望编写的注释信息很多,一行无法显示,就可以使用多行注释。
要在 Python 程序中使用多行注释,可以用一对连续的三个引号(单引号和双引号都可以)。
示例代码如下:
''' 这是多行注释
多行用三个引号来注释
'''
print("hello python")什么时候需要使用注释?
1. 注释不是越多越好,对于一目了然的代码,不需要添加注释;
2. 对于复杂的操作,应该在操作开始前写上若干行注释
3. 对于不是一目了然的代码,应在其行尾添加注释(为了提高可读性,注释应该至少离开代码 2个空格);
4. 绝不要描述代码,假设阅读代码的人比你更懂Python,他只是不知道你的代码要做什么。
在一些正规的开发团队,通常会有代码审核的惯例,就是一个团队中彼此阅读对方的代码。
2)算数运算符
(1)算数运算符定义
算数运算符是运算符的一种。
是完成基本的算术运算使用的符号,用来处理四则运算。
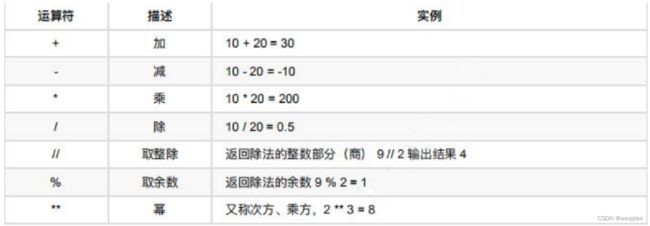
在 Python 中 * 运算符还可以用于字符串,计算结果就是字符串重复指定次数的结果。
(2)算数运算符的优先级
中进行数学计算时,同样也是和数学中的运算符的优先级一致,在Python 先乘除后加减,同级运算符是从左至右计算。
可以使用()调整计算的优先级。
以下表格的算数优先级由高到最低顺序排列:
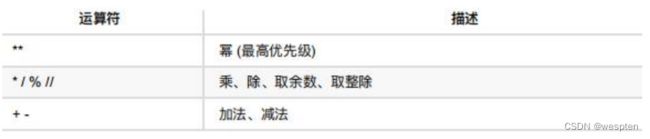
例如:
2 + 3 * 5 = 17
(2 + 3) * 5 = 25
2 * 3 + 5 = 11
2 * (3 + 5) = 163)变量
在 Python 中,每个变量在使用前都必须赋值,变量赋值以后 该变量才会被创建。
- 等号(=)用来给变量赋值;
- = 左边是一个变量名;
- =右边是存储在变量中的值;
- 变量名=值;
变量定义之后,后续就可以直接使用了。
python中字符串用单引号或者双引号引起来,数字不需要引号。
在程序中,如果要输出变量的内容,需要使用 print 函数。
name = "妲己"
age = 25
print(name)
print(age)变量结合运算符演练 —— 超市买苹果
苹果的价格是 8.5 元/斤。
买了 7.5 斤 苹果。
计算付款金额。
# 定义苹果单价变量
price = 8.5
# 定义购买重量变量
weight = 7.5
# 计算金额
money = price * weight
# 显示结果
print(money)如果买10斤苹果,就返5块钱,请重新计算购买金额。
# 定义苹果单价变量
price = 8.5
# 定义购买重量变量
weight = 10
# 计算金额
money = price * weight
# 减 5 块钱
money = money - 5;
# 显示结果
print(money)变量的命名规则
命名规则可以被视为一种惯例,并无绝对与强制目的是为了增加代码的识别和可读性。
注意Python中的标识符是区分大小写的。
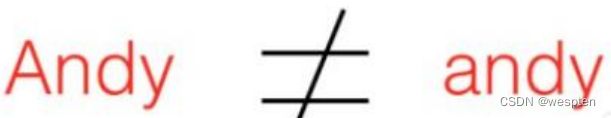
1. 在定义变量时,为了保证代码格式,=的左右应该各保留一个空格;
2. 在 Python 中,如果变量名需要由两个或多个单词组成时,可以按照以下方式命名:
i. 每个单词都使用小写字母
ii. 单词与单词之间使用_下划线连接
iii. 例如: first_name 、 last_name 、 qq_number 、 qq_password
- 驼峰命名法
当变量是由两个或多个单词组成时,还可以利用驼峰命名法来命名
- 小驼峰式命名法
第一个单词以小写字母开始,后续单词的首字母大写。
例如: firstName 、lastName
- 大驼峰式命名法
每一个单词的首字母都采用大写字母。
例如:
FirstName 、LastName 、camelCase

4)标识符
标示符就是程序员定义的 变量名、函数名 ;
名字需要有见名知意的效果,见下图:

- 标示符可以由字母、下划线和数字组成;
- 不能以数字开头;
- 不能是括号以及各种特殊符号;
- 不能与关键字重名;
5)关键字
- 关键字就是在 Python 内部已经使用的标识符。
- 关键字具有特殊的功能和含义。
- 开发者不允许定义和关键字相同的名字的标示符。
通过以下代码可以查看 Python 中的关键字:
import keyword
print(keyword.kwlist)3. 执行 Python 程序的两种方式
1. 命令行运行python程序
python 文件.py
2. PyCharm 运行 python程序
通过集成开发环境 pycharm 编写并运行 python 代码。
4、Python数据类型
Python基本数据类型(8种):1.整型(int)2.浮点型(float)3.字符串(str)4.列表(list)5.元祖(tuple)6.字典(dict)7.集合(set)8.布尔(bool)
Python的内置数据类型既包括数值型和布尔型之类的标量,也包括更为复杂的列表、字典和文件等结构。
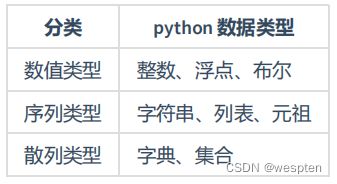
字节类型表示:
a=bytes('123') or a=b'123'字节数组:
bytearray('123')可变序列:列表 [],集合{},字典{"key":'value'}
不可变序列:字符串 ,元祖()
有序序列:列表[],字符串 ,元祖()
无序散列:集合{},字典{"key":'value'}
None 代表具体类型待定,或者说不确定具体类型。
# 变量 a 为空类型
a = NonePython 可以根据 = 等号右侧的值, 自动推导出变量存储数据的类型,不需要指定类型。
定义变量保存小明的个人信息姓名:小明 ;年龄:18岁;性别:男;身高:1.75米;是否为学生:是(True)。
name = "小明"
age = 18
sex = "男"
height = 1.75
is_student = True1. 数值
Python有4种数值类型,即整数型、浮点数型、复数型和布尔型。
整数型——1、-3、42、355、888888888888888、-7777777777,整数没有大小限制,仅受限于可用内存的大小。
浮点数型——3.0、31e12、–6e-4。
复数型——3 + 2j、–4- 2j、4.2 + 6.3j。
布尔型——True、False。
数值类型用算术操作符进行运算操作,包括+(加法)、-(减法)、*(乘法)、/(除法)、**(求幂)和%(求模)。
下面是整数型的使用示例:
>>> x = 5 + 2 - 3 * 2
>>> x
1
>>> 5 / 2
2.5 ⇽--- ❶
>>> 5 // 2
2 ⇽--- ❷
>>> 5 % 2
1
>>> 2 ** 8
256
>>> 1000000001 ** 3
1000000003000000003000000001 ⇽--- ❸用“/”❶对整数做除法,结果将会是浮点数(这是Python 3.x的新规则)。用“//”❷对整数做除法,则结果会被截断为整数。注意,整数的大小是没有限制的❸,会根据需要自动增长,仅受限于可用内存的大小。
下面是浮点数型的操作示例,浮点数型是基于C语言的双精度数据类型实现的:
>>> x = 4.3 ** 2.4
>>> x
33.13784737771648
>>> 3.5e30 * 2.77e45
9.695e+75
>>> 1000000001.0 ** 3
1.000000003e+27下面是复数型的示例:
>>> (3+2j) ** (2+3j)
(0.6817665190890336-2.1207457766159625j)
>>> x = (3+2j) * (4+9j)
>>> x ⇽--- ❶
(-6+35j)
>>> x.real
-6.0
>>> x.imag
35.0复数由实部和虚部组合而成,并带有后缀j。在上述代码中,变量x被赋了一个复数❶。这里用属性x.real可以获得实部,用x.imag则可获得虚部。
有很多内置函数都可以操作数值类型,Python还提供了库模块cmath(包含了处理复数的函数)和math(包含了处理其他3种数值类型的函数)。
>>> round(3.49) ⇽--- ❶
3
>>> import math
>>> math.ceil(3.49) ⇽--- ❷
4内置函数总是可用的,并使用标准的函数调用语法进行调用。在上述代码中,调用round函数时要用浮点数作为输入参数❶。
库模块里的函数需要经过import语句导入后才能使用。在❷处,导入库模块math之后,其中的ceil函数需要用属性的语法进行调用:module.function(arguments)。
下面是布尔型的操作示例:
>>> x = False
>>> x
False
>>> not x
True
>>> y = True * 2 ⇽--- ❶
>>> y
2布尔型的表现和数值1(True)和0(False)类似,只是用了True和False表示而已❶。
2. 列表
List (列表) 是 Python 中使用最频繁的数据类型,在其他语言中通常叫做数组,专门用于存储一串信息。
- 列表用[]定义,列表中的数据之间使用,分隔;
- 列表的索引从 0 开始;
- 索引就是数据在列表中的位置编号,索引又可以被称为下标;
Python内置了强大的列表(list)类型:
[]
[1]
[1, 2, 3, 4, 5, 6, 7, 8, 12]
[1, "two", 3, 4.0, ["a", "b"], (5,6)] ⇽--- ❶列表中的元素可以是其他多种类型的混搭,如字符串、元组、列表、字典、函数、文件对象和任意类型的数字❶。
注意:从列表中取值时,如果超出索引范围程序会报错。
# 定义一个空列表变量,名字叫 a
a = []
# 定义一个列表变量,名字叫 list1,有三个元素
list1 = ["刘备","关羽","张飞"]
# 显示列表第一个元素的值
print(list1[0])
# IndexError: list index out of range
# 错误,列表没有[3]这个值
print(list1[3])列表可以通过索引访问,从头开始或从末尾开始均可。还可以通过切片(slice)记法来表示列表的某个片段或切片。
>>> x = ["first", "second", "third", "fourth"]
>>> x[0] ❶
'first'
>>> x[2]
'third' ❷
>>> x[-1]
'fourth'
>>> x[-2]
'third'
>>> x[1:-1]
['second', 'third'] ❸
>>> x[0:3]
['first', 'second', 'third']
>>> x[-2:-1]
['third']
>>> x[:3]
['first', 'second', 'third'] ❹
>>> x[-2:]
['third', 'fourth']从头开始的索引用正数表示,从0开始,索引0表示第一个元素。从末尾开始的索引用负数表示,从-1开始,索引-1表示最后一个元素。用[m:n]可以获得一个切片,其中m是包含在内的起始索引,n是不包含在内的终止索引。
[:n]表示切片从列表头开始,而[m:]则表示切片直至列表末尾才结束。
可以用以下记法添加、移除、替换列表中的元素,或者是由切片获取某个元素或新的列表。
>>> x = [1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> x[1] = "two"
>>> x[8:9] = []
>>> x
[1, 'two', 3, 4, 5, 6, 7, 8]
>>> x[5:7] = [6.0, 6.5, 7.0] ⇽--- ❶
>>> x
[1, 'two', 3, 4, 5, 6.0, 6.5, 7.0, 8]
>>> x[5:]
[6.0, 6.5, 7.0, 8]如果替换之后的新切片大小与原来的不一样,列表的大小会自动调整❶。
下面是其他一些列表操作,包括内置函数(len、max和min)、操作符(in、+、*)、del语句和列表本身的方法(append、count、extend、index、insert、pop、remove、reverse和sort)。
>>> x = [1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> len(x)
9
>>> [-1, 0] + x ⇽--- ❶
[-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> x.reverse() ⇽--- ❷
>>> x
[9, 8, 7, 6, 5, 4, 3, 2, 1]操作符+和*会创建新的列表,原来的列表保持不变❶。列表方法的调用语法就是使用列表自身的属性记法:x.method(arguments) ❷。
通过 dir()函数查看某类型中定义的方法:
# 定义一个列表变量,名字叫 list1,有三个元素
list1 = ["刘备","关羽","张飞"]
# 通过 dir 函数显示列表所有的方法
print(dir(list1))上述操作有些是重复了切片记法完成的功能,但代码的可读性得到了提升。
列表常用方法:
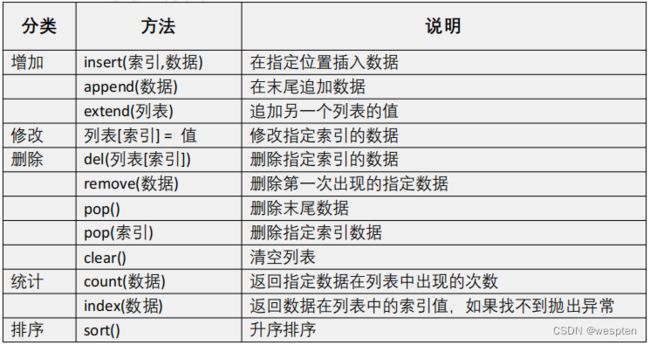

insert 作用是在列表指定位置插入指定的值:
list1 = ['刘备', '关羽', '张飞']
list1.insert(1, '吕布')
print(list1)append 作用是列表最后位置添加成员:
append(要添加成员的值)extend 把一个列表的成员追加到指定列表的后面:
list1 = ['刘备', '关羽', '张飞']
list1.insert(1, '吕布')
list1.append("曹操")
print(list1)
list2 = ['周瑜', '孙权']
list1.extend(list2) # 把list2的所有成员,追加到list1的后面
print(list1)修改列表成员的值:
list1[1] = '许褚' # 修改第二个成员的值删除成员值:
语法:
del(列表变量[索引])
del(list1[4]) 语法:
remove(要删除的值)
list1.remove('张飞')语法:
pop() # 删除列表中最后一个成员
list1.pop()
pop(索引) # 删除指定索引的值,功能与del类似
list1.pop(0) # 删除索引为0的成员语法:
clear() # 清空列表
list1.clear() 统计相同成员数量:
count(值) # 如果有多个值,返回值的数量,如果没有值,返回0
list1.count('刘备')返回指定值在列表中的索引编号:
index(指定的值, 起始位置) # 如果不写起始位置,默认为0, 指定的值一定要存在,不然报错
list1.index('刘备') 排序:
sort() # 对列表成员从小到大排序
list1.sort()
sort(reverse=True) # 对列表成员从大到小排序
list1.sort(reverse=True)逆置:
reverse() # 把列表所有成员顺序颠倒
list1.reverse()拆包:
- 拆包就是把一个列表中每个值拆出来;
- 拆包操作同样适用于元组,集合和字典;
# 定义一个列表
list1 = ["张三", 30, 4.5]
# a = list1[0]
# b = list1[1]
# c = list1[2]
# 通过对列表进行拆包方式获取列表中每个元素的值
a, b, c = list1
print(a, b, c)列表推导式:所谓的列表推导式,就是指轻量级的循环创建列表的方法。
基本的方式:
# a 的内容为[0, 1, 2, 3]
a = [x for x in range(4)]
# a 的内容为[2, 3]
a = [x for x in range(2, 4)]
# a 的内容为[3, 5, 7, 9]
a = [x for x in range(3, 10, 2)]在推导过程中使用 if:
# a 的内容为[4, 6, 8]
a = [x for x in range(3, 10) if x % 2 == 0]
# a 的内容为[3, 5, 7, 9]
a = [x for x in range(3, 10) if x % 2 != 0]公共方法:
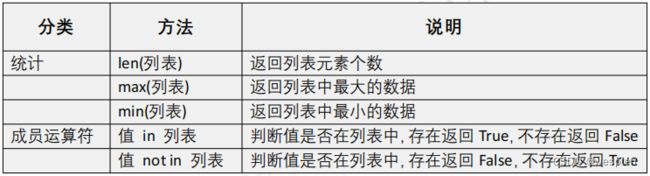
公共方法同样适用于元组,集合,字典,字符串等类型。
list1 = [4, 2, 5, 3]
print(len(list1))
str1 = "hello"
print(len(str1))
list1 = ['刘备','关羽','张飞']
print(len(list1))
# 如果len里面放的是列表,返回列表成员的个数
# 如果len里面放的是字符串,返回字符串中字符的个数返回列表中的最大值:
max(列表) -- 列表中最大的值
max(字符串) -- 返回字符串中ASCII最大的那个字符
list1 = [54, 12, 78, 123, 77]
print(max(list1))
str2 = "hellaz"
print(max(str2))返回列表中的最小值:
min(列表) -- 列表中最小的值
min(字符串) -- 返回字符串中ASCII最小的那个字符
list1 = [54, 12, 78, 123, 77]
print(min(list1))
str2 = "hellaz"
print(min(str2))in 判断指定的值是否在列表中存在,not in 判断指定的值是否不在列表中:
指定的值 not in 列表
# 这个操作对字符串同样有效
list3 = [4, 6, 1, 23]
if 4 in list3:
print("有4")
if 5 not in list3:
print("没有5")
str3 = "hello"
if "a" in str3:
print("有a")
if "b" not in str3:
print("没有b")公共方法:
list1 = ['张飞', '刘备', '关羽', '刘邦', '刘老二', '曹操']
if "刘备" in list1:
list1.remove("刘备")
print(list1)
list2 = [3, 5, 67, 2, 34, 12, 5, 11]
# 求列表的平均值
# 求平均值就是先求和,然后除以成员数量
sum = 0
for n in list2:
sum += n
print(sum / len(list2))list API:
list1 = ['刘备', '关羽', '张飞']
list1.insert(1, '吕布')
list1.append("曹操")
print(list1)
list2 = ['周瑜', '孙权']
list1.extend(list2) # 把list2的所有成员,追加到list1的后面
print(list1)
list1[1] = '许褚' # 修改第二个成员的值
print(list1)
del(list1[4])
print(list1)
list1.remove('张飞')
print(list1)
list1.pop()
print(list1)
list1.pop(0) # 删除索引为0的成员
print(list1)
list1.clear()
print(list1)
list1 = ['刘备', '关羽', '张飞', '刘备', '关羽']
print(list1.count('刘备'))
print(list1.count('张飞'))
print(list1.count('吕布'))
print(list1.index('刘备'))
list1 = [4, 3, 1, 56, 12, 67]
# list1.sort()
# list1.sort(reverse=True)
list1.reverse()
print(list1)写代码判断列表中名字为三个字的人有几个:
list1 = ['张三', '李四', '刘老二', '王麻子', '王达成', '隔壁老王']
# 写代码判断列表中名字为三个字的人有几个
# 思路,首先得把每个名字遍历一遍
num1 = 0 # 存放名字为3个字的出现次数
for n in list1: # n是列表中的每个成员,list1中有几个成员循环几次
sum = 0
for a in n: # a是字符串n中的每个字符,n中有几个字符for循环几次
sum += 1
if sum == 3:
num1 += 1
print(num1)
# 只要知道sum出现3有几次,就是这个答案
# 第一次循环n是张三
# 第二次循环n是李四
# 第三次循环n是刘老二
# 第四次循环n是王麻子
# 第五次循环n是隔壁老王
# n = "刘二"
# sum = 0
# for a in n:
# sum += 1
# print(sum)3. 元组
元组元组(tuple)与列表类似,但是元组是不可修改的(immutable),元组可以理解为一个只读的列表。也就是说,元组一旦被创建就不可被修改了。
操作符(in、+、*)和内置函数(len、max、min)对于元组的使用效果和列表是一样的,因为这几个操作都不会修改元组的元素。索引和切片的用法在获取部分元素或切片时和列表是一样的效果,但是不能用来添加、移除、替换元素。元组的方法也只有两个,即count和index。
元组的重要用途之一就是用作字典的键。如果不需要修改元素,那么使用元组的效率会比列表更高。
元组用 () 定义 ;
()
(1,) ⇽--- ❶
(1, 2, 3, 4, 5, 6, 7, 8, 12)
(1, "two", 3L, 4.0, ["a", "b"], (5, 6)) ⇽--- ❷只包含1个元素的元组需要加上逗号❶。和列表一样,元组的元素也可以是各种类型的混搭,包括字符串、元组、列表、字典、函数、文件对象和任意类型的数字❷。
定义元组时, () 可以省略:
tuple4 = "张飞", 30
tuple5 = "吕布",利用内置函数tuple,可以将列表转换为元组:
>>> x = [1, 2, 3, 4]
>>> tuple(x)
(1, 2, 3, 4)反之,元组也可以通过内置函数list转换为列表:
>>> x = (1, 2, 3, 4)
>>> list(x)
[1, 2, 3, 4]元组的常用方法与列表类似, 元组的内容不可修改,所以没有增加、修改和删除相关方法。
只要不涉及到修改成员的值,所有列表适用的方法,元组都通用。
tuple1 = ('刘备', '关羽', '张飞')
a = tuple1[1]
print(a)
# tuple1[1] = '曹操' # 元组的值不能修改
print(tuple1.count('刘备'))
print(tuple1.index('刘备'))
tuple2 = (4, 6, 1, 67, 100)
print(len(tuple2))
print(max(tuple2))
print(min(tuple2))
if 3 in tuple2:
print("3在元组tuple2中")元组和列表之间的转换:
- 把列表转化为元组目的是让列表不可以被修改,以保护数据安全 ;
- 使用 list 函数可以把元组转换成列表;
- 使用 tuple 函数可以把列表转换成元组;
list1 = ["刘备","关羽","张飞"]
# 通过 tuple 函数把 list1 转换为元组
tuple1 = tuple(list1)
tuple2 = ("孙权","周瑜","鲁肃")
# 通过 list 函数把 tuple2 转换为列表
list2 = list(list1)把元组放到列表前面:
list1 = ['刘备', '关羽', '张飞']
tuple1 = ('曹操', '周瑜')
# list1.insert(0, tuple1)
# print(list1)
# for n in tuple1:
# list1.insert(0, n)
# print(list1)
# for第一次循环的时候,n的值是曹操
# insert的时候,曹操是第一个成员
# for第二次循环的时候,n的值是周瑜
# insert的时候,周瑜是第一个成员
# 第一次循环的时候,把n放到0这个位置
# 第二次循环的时候,把n放到1这个位置
a = 0
for n in tuple1:
list1.insert(a, n)
a += 1
# 第一次循环a的值为0insert(0, 曹操)
# 第二次循环a的值为1insert(1, 周瑜)
print(list1)4. 字符串
字符串就是一串字符,是编程语言中表示文本的数据类型。
在Python中可以使用一对双引号"或者一对单引号'定义一个字符串。
虽然可以使用\"或者\'做字符串的转义,但是在实际开发中:如果字符串内部需要使用",可以使用'定义字符串。
如果字符串内部需要使用',可以使用"定义字符串。
可以使用[索引]获取一个字符串中指定位置的字符,索引计数从0开始。
字符串处理是Python的一大强项。标识字符串的方式有很多种:
"A string in double quotes can contain 'single quote' characters."
'A string in single quotes can contain "double quote" characters.'
'''\tA string which starts with a tab; ends with a newline character.\n'''
"""This is a triple double quoted string, the only kind that can contain real newlines."""字符串可以用单引号(' ')、双引号(" ")、3个单引号(''' ''')或3个双引号(""" """)进行标识,可以包含制表符(\t)和换行符(\n)。
字符串类型也是不可修改的。在原字符串上执行的操作符和函数调用,都会返回从原字符串提取的新的字符串。操作符(in、+、*)和内置函数(len、max、min)对于字符串的使用效果,和列表、元组是一样的。索引和切片的用法在获取部分元素或切片时,效果也是一样的,但是不能用于添加、移除或替换元素。
字符串类型包含了很多处理字符串的方法,在库模块re中还额外提供了一些字符串处理函数:
>>> x = "live and let \t \tlive"
>>> x.split()
['live', 'and', 'let', 'live']
>>> x.replace(" let \t \tlive", "enjoy life")
'live and enjoy life'
>>> import re ⇽--- ❶
>>> regexpr = re.compile(r"[\t ]+")
>>> regexpr.sub(" ", x)
'live and let live're模块❶提供了正则表达式的处理功能。与string模块相比,它能够以更为复杂的模式实现字符串提取或替换功能。
print函数用于输出字符串,可将其他Python数据类型简单地转换为字符串并进行格式化输出:
>>> e = 2.718
>>> x = [1, "two", 3, 4.0, ["a", "b"], (5, 6)]
>>> print("The constant e is:", e, "and the list x is:", x) ⇽--- ❶
The constant e is: 2.718 and the list x is: [1, 'two', 3, 4.0, ['a', 'b'], (5, 6)]
>>> print("the value of %s is: %.2f" % ("e", e)) ⇽--- ❷
the value of e is: 2.72在用print输出的时候,对象会被自动转换为字符串形式❶。操作符%提供的格式化能力❷,与C语言的sprintf函数类似。
可以使用 for 循环遍历 字符串中每一个字符:
# 定义一个字符串 str1
str1 = "我爱 python"
for n in str1:
print(n)字符串的常用方法:
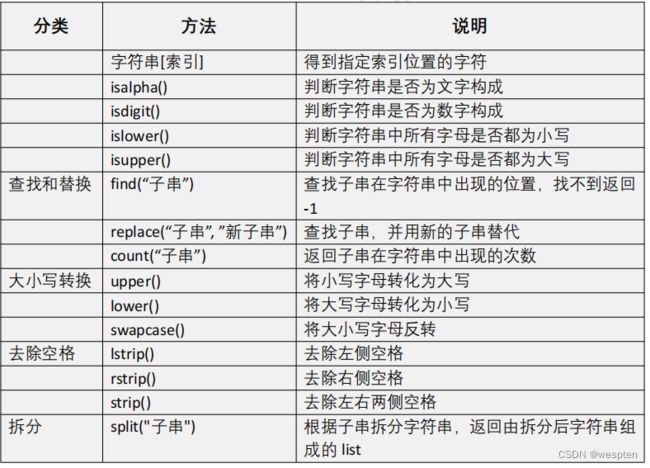
得到字符串指定位置的字符,字符串[索引]:
- 第一个字符的索引为0;
- 最后一个字符的索引为-1;
str1 = "abcdefg"
print(str1[3])
print(str1[-1])
print(str1[-3])判断字符串是否由纯字母组成:
- isalpha()
如果条件成立,返回True,否则返回False。
str1 = "abcde123fg"
print(str1[3])
print(str1[-1])
print(str1[-3])
if str1.isalpha():
print("字符串都是由字母构成的")判断字符串是否由纯数字组成:
- isdigit()
如果字符串是纯数字组成,返回True,否则返回False。
str2 = "1234ab5"
if str2.isdigit():
print("str2是由纯数字组成的")
# a = int(input("请输入一个整数"))
# b = int(input("请输入一个整数"))
str1 = input("请输入一个整数") # 不要着急转int,转int前先判断能不能转
str2 = input("请输入一个整数") # 不要着急转int,转int前先判断能不能转
if str1.isdigit() and str2.isdigit():
a = int(str1)
b = int(str2)
print(a + b)
else:
print("老实点,小心挨打")
# 如果用户老老实实,输入的是整数,就计算两个整数的相加结果
# 如果用户不老实,输入的是不是整数,就显示"老实点,小心挨打"- isupper
判断字符串是否全部由大写字母构成。
str1 = "aaaaAbbbcc"
if str1.islower():
print("str1全部使用小写字母构成")
str2 = "ABaCDE"
if str2.isupper():
print("str2全部都是大写字母构成")- find
查找子串在字符串中的位置,找不到返回-1,找到返回子串的位置。
str1 = "hello python"
a = str1.find("python")
print(a)
a = str1.find("asffsf")
print(a)- replace
替换子串:
str1 = "hello python"
a = str1.find("python")
print(a)
a = str1.find("asffsf")
print(a)
str2 = str1.replace("python", "world")
# 并不是str1改变了,是把str1中的python变为world给str2了
# str1的值并没有改变
print(str2)count:
- 查找子串出现次数;
- 找到返回次数;
- 找不到返回0;
str3 = "hello world hello python"
a = str3.count("hello")
print(a)
a = str3.count("a")
print(a)- swapcase
把字符串中大小写字母反转:
str1 = "AbCdEf"
str2 = str1.upper() # str1的值并没有改变,str2是改变后的结果
print(str2)
str2 = str1.lower()
print(str2)
str2 = str1.swapcase()
print(str2)- strip
去除左右两侧空格:
str1 = " aaaaaaaaa "
str2 = str1.lstrip()
print(str2)
str2 = str1.rstrip()
print("'%s'" % str1)
print("'%s'" % str2)
str2 = str1.strip()
print("'%s'" % str2)split:
- 根据子串拆分字符串;
- 拆分后的结果,放到一个列表中;
str1 = "aaaa_bbbb_eeee_hello"
list1 = str1.split("_") # 拆分之后,list1有四个成员,每个成员类型是字符串
print(list1)
str2 = "123@4567@000"
list2 = str2.split("@")
print(list2)格式化字符串:
% 被称为格式化操作符,专门用于处理字符串中的格式。
包含 % 的字符串,被称为格式化字符串。
% 和不同的字符连用,不同类型的数据需要使用不同的格式化字符。
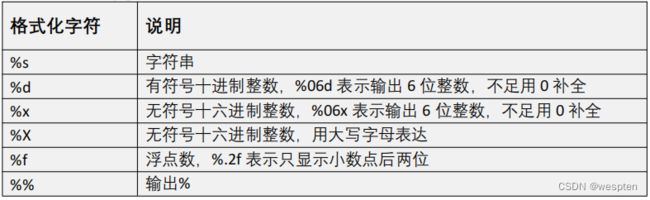
语法格式:
str1 = "姓名:%s, 年龄%d" % ("鲁肃", 31)- %x意思是把一个十进制数按照十六进制方式显示,abcdef用小写表示;
- %X意思是把一个十进制数按照十六进制方式显示ABCDEF用大写表示;
print("%x" % 9)
print("%x" % 10) # 十进制的10就是十六进制的a
print("%x" % 16) # 十进制的16就是十六进制的???
print("%x" % 15) # 十进制的15就是十六进制的???
# 0 1 2 3 4 5 6 7 8 9 a b c d e f 10 11 12 13 ...
print("%X" % 10)
str1 = "我是%s, 年龄是%d" % ("小明", 20) # 把格式化字符串的结果,放到str1这个变量里面去
print(str1) 
d = 1
name = '刘备'
weight = 80.2
tel = '13912345678'
print("*" * 20)
print("编号%06d" % id)
print("姓名:%s" % name)
print("体重:%.3f" % weight)
print("电话:%s" % tel)
print("*" * 20)字符串的切片:
- 切片方法适用于字符串、列表、元组;
- 切片使用索引值来限定范围,从一个大的字符串中切出小的字符串 ;
- 字符串、列表和元组都是有序的集合,都能够通过[索引]获取到对应的数据;
字符串【开始索引:结束索引:步长】
注意:
- 指定的区间属于左闭右开型 [开始索引,结束索引)=> 开始索引 >= 范围 < 结束索引从起始位开始,到结束位的前一位结束(不包含结束位本身);
- 从头开始,开始索引数字可以省略,冒号不能省略;
- 到末尾结束,结束索引数字可以省略,冒号不能省略;
- 步长默认为1,如果连续切片,数字和冒号都可以省略;
索引的顺序和倒序:
在 Python 中不仅支持顺序索引,同时还支持倒序索引;
所谓倒序索引就是从右向左计算索引;
最右边的索引值是-1,依次递减:
# 定义一个字符串 str1
str1 = "我爱 python"
s = str1[-1]
print(s)截取从 2 ~ 5 位置的字符串:
# 定义一个字符串 str1
str1 = "我爱 python"
s = str1[2:6]
print(s)截取从 2 ~ 末尾的字符串:
# 定义一个字符串 str1
str1 = "我爱 python"
s = str1[2:]
print(s)截取从开始 ~ 5 位置的字符串:
# 定义一个字符串 str1
str1 = "我爱 python"
s = str1[:6]
print(s)截取完整的字符串:
# 定义一个字符串 str1
str1 = "我爱 python"
s = str1[:]
print(s)从开始位置,每隔一个字符截取字符串:
# 定义一个字符串 str1
str1 = "我爱 python"
s = str1[::2]
print(s)从索引 1 开始,每隔一个取一个:
# 定义一个字符串 str1
str1 = "我爱 python"
s = str1[1::2]
print(s)截取从 2 到末尾 - 1 的字符串:
# 定义一个字符串 str1
str1 = "我爱 python"
s = str1[2:-1]
print(s)截取字符串末尾两个字符:
# 定义一个字符串 str1
str1 = "我爱 python"
s = str1[-2:]
print(s)字符串的逆序:
# 定义一个字符串 str1
str1 = "我爱 python"
s = str1[::-1]
print(s)字符串中的引号:
- 在字符串中如果包含单引号,那么字符串用双引号引起来;
- 在字符串中如果包含双引号,那么字符串用单引号引起来;
- 如果字符串不包含引号,那么双引号单引号引字符串无所谓;
- 如果字符串同时包含单引号和双引号,必须用转义字符的方式实现;
str1 = "我\"你"
print(str1)
str1 = '我"你'
print(str1)
str2 = '我\'你'
print(str2)
str2 = "我'你"
print(str2)
str3 = "我你"
str4 = '我你'
str5 = "我\'你\"他"
print(str5)通过[索引]访问字符串中的指定位置字符
字符串[索引]:
- 第一个字符的索引编号为0;
只能得到指定位置的字符,不能修改指定位置的字符。
str1 = "hello python"
a = str1[0] # a就是字符串str1的第一个字符
print(a)
a = str1[3] # a是字符串str1的第四个字符
print(a)
# str1[0] = "b" 不能通过[索引]的方式修改字符串中具体字符的值
# 字符串更像一个由字符构成的元组字符串中所有数字求和:
str1 = "123 98 234 23 345"
# 思路,先把str1中每个数字分隔出来
list1 = str1.split(" ")
# 遍历列表,计算和
sum = 0
for n in list1:
sum += int(n) # n的类型为字符串,所以需要转化为int
print(sum)去除字符串中间空格:
str1 = "aaa bbbbb eeee aaaaaa bbbb"
str2 = str1.replace(" ", "")
print(str2)列表以及成员都逆置:
# ['刘备', '诸葛亮', '曹操', '周瑜', '关羽']
# 作业,把列表中个成员名字逆序
# 把列表中也逆序
list1 = ['刘备', '诸葛亮', '曹操', '周瑜', '关羽']
list1 = list1[::-1] # 把列表中的成员逆置
# print(list1)
# 列表中每个字符串也要逆置
# 思路,遍历列表,在遍历出来每个字符串后,把每个字符串逆置
index = 0 # 定义了一个变量叫index,值为0
for n in list1:
str1 = n[::-1] # str1就是n颠倒后的结果
list1[index] = str1
# 第一次循环的时候index的值为0,所以相当于list1[0] = str1
# 第二次循环的时候index的值为1,所以相当于list1[1] = str1
index += 1
print(list1)索引为一个变量的用例:
- 列表或者元组,或者字符串都经常用[索引]的方式访问成员;
- 索引可以是一个具体的数字,也可以是一个变量;
a = 1
列表[a] = '张三' # 相当于列表[1] = '张三'
list1 = ['刘备', '关羽', '张飞']
list1[0] = '曹操'
print(list1)
list1[1] = '周瑜'
print(list1)
index = 2
list1[index] = '马超'
print(list1)
# 列表[索引] = 值 修改列表指定成员的值
# 索引可以是一个具体的数字,也可以是一个变量
index = 0
list1[index] = '张三'
print(list1)多维列表:
- 一个列表的成员,又是一个列表,这种列表就是多维列表;
list1 = ['张飞', '刘备', '关羽']
# list1是一个一维的列表,有三个成员,分别为'张飞', '刘备', '关羽'三个字符串
list2 = [['张飞', '刘备', '关羽'], ['曹操', '周瑜', '孙权']]
# list2是一个二维列表,有两个成员
# 第一个成员也是一个列表['张飞', '刘备', '关羽']
# 第二个成员也是一个列表['曹操', '周瑜', '孙权']
a = list2[1] # a是什么, a是一个列表['曹操', '周瑜', '孙权']
print(a)
print(a[1]) # 显示列表a的第二个成员5. 字典
dictionary (字典)通常用于存储“键值对”数据,键与值之间用冒号分隔。
- 键key是索引,同一个字典内,键名不能重复;
- value是数据;
字典用{}定义:
- 通过变量名={}创建一个空字典
# 定义一个空字典
dict1 = {}字典与集合的区别:
- 集合中只有值;
- 字典是包含键与值的键值对;
# 定义一个字典,包含三个键值对
dict1 = {"name":"刘备", "age":32, "height":1.75}Python内置的字典(dictionary)数据类型提供了关联数组的功能,实现机制是利用了散列表(hash table)。内置的len函数将返回字典中键/值对的数量。del语句可以用来删除键/值对。像列表类型一样,字典类型也提供了一些可用的方法(clear、copy、get、items、keys、update和values)。
>>> x = {1: "one", 2: "two"}
>>> x["first"] = "one" ⇽--- 新建一个字典成员,键为"first",值为"one"
>>> x[("Delorme", "Ryan", 1995)] = (1, 2, 3) ⇽--- ❶
>>> list(x.keys())
['first', 2, 1, ('Delorme', 'Ryan', 1995)]
>>> x[1]
'one'
>>> x.get(1, "not available")
'one'
>>> x.get(4, "not available") ⇽--- ❷
'not available'字典键必须是不可变类型❶,如数值、字符串、元组。字典值可以是任何对象,包括列表和字典这种可变类型。当要访问的键的值在字典中不存在时,将会引发KeyError。如果想要避免这种异常,字典方法get❷选择可以当键在字典中不存在时返回自定义值。
字典常用操作:
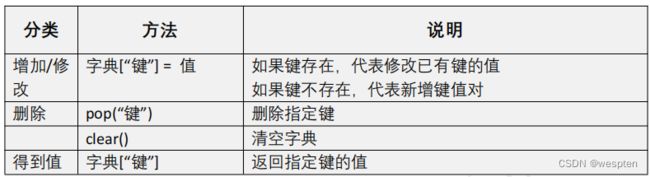
新增或者修改键值对,字典[键]=值:
- 如果键存在,就是修改值;
- 如果键不存在,就是新增键值对;
dict1 = {"name":"刘备", "age":20, "sex":"男"}
dict1["name"] = "关羽" # 修改键name对应的值
print(dict1)
dict1["class"] = '1班' # 新增一个键值对,键为class,值为1班
print(dict1)删除键值对:
- pop(键);
dict1.pop('name') # 删除name键,一旦键被删除,对应的值也同时被删除清空:
- clear();
dict1.clear()得到键对应的值,变量名=字典[键]:
- 把键对应的值赋值给指定的变量
a = dict1["age"] # 得到键对应的值
dict1 = {"name":"刘备", "age":20, "sex":"男"}
dict1["name"] = "关羽" # 修改键name对应的值
print(dict1)
dict1["class"] = '1班' # 新增一个键值对,键为class,值为1班
print(dict1)
dict1.pop('name') # 删除name键,一旦键被删除,对应的值也同时被删除
print(dict1)
# dict1.clear()
print(dict1)
a = dict1["age"] # 得到键对应的值
print(a)
b = dict1["sex"] # 得到键sex对应的值
print(b)循环遍历字典:
遍历就是依次从字典中获取所有键值对。
# 定义一个字典 dict1,包含三个键值对
dict1 = {"name":"刘备", "age":32, "height":1.75}
# n 为键,通过 dict1[n]可以得到键对应的值
for n in dict1:
print("键=%s,值=%s" % (n, str(dict1[n])))字典.items()返回一个包含键和值的元组:
dict1 = {"name":"刘备", "age":20, "sex":"男"}
# for n in dict1.items():
# print(n)
# 一旦使用了字典的items方法,n就是一个包含了键和值的元组
# n就是一个包含了两个成员的元组,第一个成员是键,第二个成员是值
# for循环了3次
# 第一次n = ('name', '刘备')
# 第二次n = ('age', 20)
# 第三次n = ('sex', '男')
# for n in dict1.items():
# a, b = n # 对一个元组进行拆包
# print(a, b)
for a, b in dict1.items(): # a就是键,b就是键对应的值
print(a, b)dict1 = {"a":23, "b":4, "c":9, "d":3, "e":12}
for n in dict1:
print(n, dict1[n])
print("------------------")
for a, b in dict1.items():
print(a, b)拆包方式:
- 字典的 items 方法获取字典中的键值对。
- items 方法返回包含字典键值对的元组。
# 定义一个字典 dict1,包含三个键值对
dict1 = {"name":"刘备", "age":32, "height":1.75}
# n 获取 dict12 中的每个键值对
for n in dict1.items():
print(n)通过对元组拆包的方式获取键和值:
# 定义一个字典 dict1,包含三个键值对
dict1 = {"name":"刘备", "age":32, "height":1.75}
# a 为键,b 为值
for a, b in dict1.items():
print("键=%s,值=%s" % (a, str(b)))显示值9对应的键名:
dict1 = {"a":23, "b":4, "c":9, "d":3, "e":12}
# 思路
# 遍历字典,在遍历的时候,检查值是否为9,如果是9,显示9对应的键
for n in dict1:
if dict1[n] == 9:
print(n) # 如果条件成立,那么就显示n,就是是值9对应的键6. 集合
Python中的集合(set)类型是由对象组成的无序集。如果主要关心的是对象在集合中的存在性和唯一性,可以考虑使用集合类型。集合的行为,就像是没有关联值的字典键集。
创建空集合 变量名 = set():
# 定义一个空集合 set1
set1 = set()注意:不能通过 变量名={}来创建空集合。
集合和列表的区别:
- 列表是有序的对象集合;
- 集合是无序的对象集合;
- 同一个集合内值不允许重复;
>>> x = set([1, 2, 3, 1, 3, 5]) ⇽--- ❶
>>> x
{1, 2, 3, 5} ⇽--- ❷
>>> 1 in x ⇽--- ❸
True
>>> 4 in x ⇽--- ❸
False
>>>对序列型对象(如列表)调用set函数,可以创建一个集合❶。在创建时,重复的序列成员将会被移除❷。关键字in可用于检查对象是否为集合的成员❸。
集合常用操作:
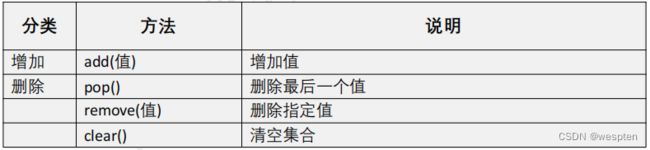
add添加值:
- 集合变量.add(值);
pop删除一个值:
- 集合变量.pop();
remove删除指定的值:
- 集合变量.remove(值);
clear删除所有值:
- 集合变量.clear();
set1 = {'刘备', '关羽', '张飞'} # 定义了一个集合变量set1
set2 = set() # 定义一个空集合set2
set3 = {'刘备', '关羽', '刘备'}
print(set1)
print(set2)
print(set3)
set1.add('曹操')
print(set1)
# set1.pop()
print(set1)
set1.remove('刘备')
print(set1)
set1.clear()
print(set1)7. 文件对象
Python通过文件对象来访问文件:
>>> f = open("myfile", "w") ⇽--- ❶
>>> f.write("First line with necessary newline character\n")
44
>>> f.write("Second line to write to the file\n")
33
>>> f.close()
>>> f = open("myfile", "r") ⇽--- ❷
>>> line1 = f.readline()
>>> line2 = f.readline()
>>> f.close()
>>> print(line1, line2)
First line with necessary newline character
Second line to write to the file
>>> import os ⇽--- ❸
>>> print(os.getcwd())
c:\My Documents\test
>>> os.chdir(os.path.join("c:\\", "My Documents", "images")) ⇽--- ❹
>>> filename = os.path.join("c:\\", "My Documents", "test", "myfile") ⇽--- ❺
>>> print(filename)
c:\My Documents\test\myfile
>>> f = open(filename, "r")
>>> print(f.readline())
First line with necessary newline character
>>> f.close()open语句会创建一个文件对象❶,这里以写入("w")模式打开当前工作目录中的文件myfile。然后写入两行数据并关闭文件❷,再以只读("r")模式打开该文件。os模块❸中提供了一些与文件系统相关的函数,参数是文件和目录的路径名。接着将当前目录移到另一个目录❹。但通过引用绝对路径下的文件❺,仍然可以访问到该文件。
Python还提供了其他几种输入/输出功能。内置的input函数可用来提示并读取用户录入的字符串。通过sys库模块,能访问到stdin、stdout和stderr。如果文件是由C程序生成的,或者是要供C程序访问的,那么可以通过struct库模块获得文件读取和写入的支持。用Pickle库模块则能够轻松地读写保存在文件中的Python数据类型,以实现对象数据的持久化。
8. 数据类型方法总结
1)字符串方法
字符串拼接:
stri+ str2
"".join([str1,str2])数组转字符串的常用方法
"str1:%s,str2:%s"%(str1, str2)
"{}{}{}".format(str1, str2, str3)2. str1.replace(m,n,x)
- 字符串替换;
- m:新字符串,n:旧字符串,x:替换个数;
3. str1.index(m)
- 查找m在str1中位置(索引),找不到会抛出异常;
4. str1.find(m)
- 查找m在str1中位置(索引),找不到返回-1;
5. str1.count(m)
- 统计m在str1中出现的次数,一个都没有返回0;
6. str1.isdigit()
- 判断str1是否是数字,返回bool;
7. str1.isalpha()
- 判断str1是否是字母,返回bool;
8. str1.isupper()
- 判断str1是否是大写,返回bool;
9. str1.islower()
- 判断str1是否是小写,返回bool;
10. str1.startswith(m)
- 判断str1是不是以m开头,返回bool;
11. str1.endswith(m)
- 判断str1是不是m结尾,返回bool;
12. str1.upper()
- str1转化为大写;
13. str1.lower()
- str1转化为小写;
14. str1.strip()
- 去掉str1左右空白字符串;
- lstrip()去掉左侧空白;
- rstrip()去掉右侧空白;
15. str1.title()
- str1标题化;
16. str1.capitalize()
- str1第一个字母变成大写;
17. str1.split(m,x)
- 以m为界分割,分割x次;
2)列表方法
1. li.append(m)
- m添加到列表末尾;
2. li.insert(x,m)
- 将m插入到列表,x是列表元素下标;
3. li.extend(list1)
- 列表拼接,li尾部增加list1的元素,作用在li上;
- 这个方法也是充分体现了鸭子类型,传入的参数不仅是列表,元组、集合等可迭代对象都可以当作参数传入;
- 和 li+list1 区别: li + list1 是表达式,要用一个变量来接收,如 list2=li + list1;
4. li.pop(x)
- x:被删除元素的索引,返回值:被删除的元素;
- 若不传参数,则从最后开始删除;
5. li.remove(m)
- 删除一个元素m,没有返回值;
6. li.clear()
- 清空列表li;
7. li.index(m)
- 查询m的下标;
8. li.count(m)
- 统计m在li中出现的次数,一个都没有返回0;
9. li[x] = m
- 把li中下标为x的元素的值,设置成m;
10.深拷贝和浅拷贝
- copy.copy(li)浅拷贝,只拷贝第一层元素的引用,产生的新的列表与被拷贝的列表互不影响
- copy.deepcopy(li)深拷贝,递归拷贝所有元素,产生新的列表与被拷贝的列表互不影响;
- li= old_li 赋值,两个变量都指向同一个内存块,修改li会对old_li产生影响,同理,修改old_li也会对li产生影响;
11. 永久排序
li.sort(reverse=True/False)
- True倒序;
- False 正序;
li.reverse()
- 永久倒序;
12.临时排序
sorted(li, reverse=True/False)
- True倒序;
- False 正序;
reversed(li)
- 临时倒序;
13. 数组遍历
lists=[1,2,3,4,5]
print("------# 只遍历值-----------")
# 只遍历值
for i in lists:
print(i)
print("-…-# 逆序遍历--1----")
# 逆序遍历
for i in lists[:-1]:
print(i)
print("-------# 逆序遍历--2--------")
# 逆序遍历
for i in range(len(lists),0,-1):
print(i)
print("-------# 遍历键和值--2---------")
# 遍历键和值
for idx, val in enumerate(lists):
print(idx,':',val)
print("---# 遍历键----------")
# 只遍历键
for idx in range(0, len(lists):
print(idx)
3)元组方法
tup.index(m):
- 查找m在tup中下标;
tup.count(m):
- 统计m在tup中出现的次数,一个都没有返回0;
4)集合方法
1. st1 & st2
- 求st1和st2的交集
2. st1 | st2
- 求st1和st2的并集
3. st1 - st2
- 求st1和st2的差集
4. st.add(m)
- 向集合st里面添加一个元素m
5. st.pop()
- 随机删除集合里的元素
6. st.remove(m)
- 指定删除集合里的元素m,若集合没有元素m,也不会报错
7. st1.isdisjoint(st2)
- 判断st1与st2是否存在交集
8. st1.issubset(st2)
- 判断st1是否是st2的子集
9. st1.issuperset(st2)
- 判断st1是否是st2的父集
10. st1.update(m)
- 向集合里面添加元素m,m可以为字符串、列表、元组、集合、字典(字典只存key)
5)字典方法
1. d = dict.fromkeys(m, v)
- 生成一个字典d,键是可迭代对象m中的元素,值是默认值v;
2. d.setdefault(k, v)
- 查询字典d中有没有k这个键,有则返回k对应的值;无则添加,d[k]=v;
3. d.clear()
- 清空字典;
4. d.pop(k)
- 删除以k为键的键值对;
5. d.popitem()
- 删除最后一个键值对;
6. d.update(new_d)
- 把new_d的键值对合并到d中;
7. d[k]=v
- 添加或修改键值对;
8. d.get(k, v)
- 查询d中是否k这个键值对,若有,返回k的值;若没有,返回默认值v;
6)判断类型的方法
1.type(变量)
2. isinstance(变量,类型)
9. 运算符
优先级从上至下,由高到低。
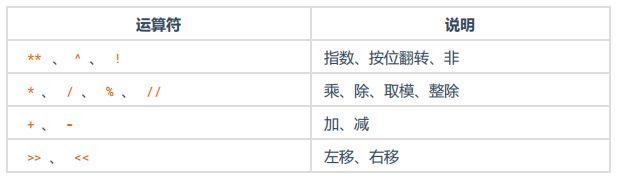
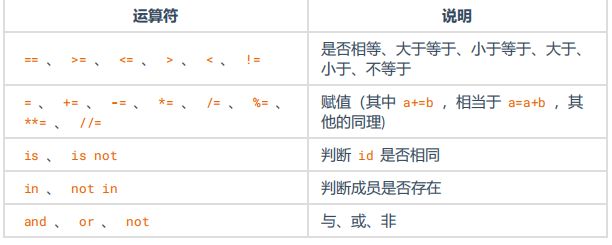
10. 不同类型变量之间的计算
1)数字型变量之间可以直接计算
在 Python 中,两个数字型变量是可以直接进行算数运算的。
如果变量是 bool 型,在计算时:
- True 对应的数字是 1;
- False 对应的数字是 0;
i = 10
f = 10.5
b = True
print(i + f)
print(i + b)
print(i - b)2)字符串变量之间使用 + 拼接字符串
在 Python 中,字符串之间可以使用 + 拼接生成新的字符串。
first_name = "张"
last_name = "三"
name = first_name + last_name
print(name)3)字符串变量可以和整数使用 * 重复拼接相同的字符串
str1 = "张"
str2 = str1 * 5
print(str2)4)数字型变量和字符串之间不能进行其他计算
first_name = "张"
age = 20
abc = first_name + age
# TypeError: can only concatenate str (not "int") to str一个数字如果用引号引起来,这就不是数字了,而是一个字符串。
a = 10 # 数字10
b = "10" # 这个地方不是整数10, 是一个字符串 有一个字符是1 还有一个字符是0
c = 1
d = "1"
print(a + c)
print(b + d)11. 不同类型变量的转化
1)数字类型转化为字符串类型
str(数字):
a = 20
#把 a 转化为字符串
str(a)2)字符串类型转化为整型
int(字符串):
a = "123"
# 转化为 int 型
int(a)3)字符串类型转化为浮点型
float(字符串):
a = "3.5"
# 转化为 float 型
float(a)a = "123"
b = 456
print(a + str(b))
print(int(a) + b)四舍五入:
# 如何把一个float类型的小数点去掉只保留整数
# f = 3.5
# a = int(f) # 只要把一个浮点数用int()转化为一个整数,那么小数点就没了
# print(a)
a = 5
b = 2
# 2.5 + 0.5 = 3
print(int(a / b + 0.5))
a = 10
b = 3
# 3.333333 + 0.5 = 3.83333333333
print(int(a / b + 0.5))
a = 11
b = 2
# 5.5 + 0.5 = 6
print(int(a / b + 0.5))
# 任意两个数字除,结果加0.5,最后只保留整数位,就是对一个小数四舍五入取整的结果12. 变量的输入
所谓输入,就是用代码获取用户通过键盘输入的信息;
例如:去银行取钱,在ATM上输入密码。
在 Python 中,如果要获取用户在键盘上的输入信息,需要使用到 input 函数。
1)input 函数实现键盘输入变量的值
在 Python 中可以使用 input 函数从键盘等待用户的输入。
语法如下:
变量 = input("提示信息:")之前演练的变量值都是程序中写死的,通过input函数就可以在程序运行过程中动态的给变量赋值了。
# 通过 input 函数输入变量 name 的值,
# 通过 print 函数把 name 的值通过屏幕打印出来
name = input("请输入姓名")
print(name)超市买苹果:
# 输入苹果的价格
price = input("请输入苹果单价")
# 输入要买的斤数
weight = input("请输入要买的斤数")
# 把输入结果转化为小数并计算和显示总价
money = float(price) * float(weight)
print(money)13. 变量的格式化输出
1)格式化字符
在 Python 中可以使用 print 函数将信息输出到控制台 。
如果希望输出文字信息的同时,一起输出数字,就需要使用到格式化操作符。
%被称为格式化操作符,专门用于处理字符串中的格式。
包含 % 的字符串,被称为格式化字符串。
% 和不同的字符连用,不同类型的数据需要使用不同的格式化字符。

2)语法格式
print("格式化字符串"%变量1)
print("格式化字符串"%(变量1,变量2...)
name = "张三"
age = 20
print("姓名" + name + ", 年龄" + str(age) + "岁")
# 这两个print输入的结果是一样的
print("姓名%s, 年龄%d岁" % (name, age))
print("姓名%s, 年龄%d岁, %%, %%s" % (name, age))f = 3.14
str1 = "圆周率是"
print(str1 + str(f))
print("%s%.2f" % (str1, f))
a = 10
print("变量a的值是%05d" % a)14. 字符串中的转义字符
print函数的输出默认是回车结尾:
# 两个 print 函数会输出两行内容
print("hello world")
print("hello python")多个 print 函数的输出结果打印到一行:
# 多个 print 函数会输出结果打印到一行
print("hello world", end="")
print("hello python")格式化字符串名片:
company = input("请输入公司名称")
name = input("请输入姓名")
tel = input("请输入电话号码")
mailbox = input("请输入邮箱地址")
print("*" * 20)
print("公司名称:%s" % company)
print("姓名:%s" % name)
print("电话:%s" % tel)
print("邮箱:%s" % mailbox)
print("*" * 20)格式化字符:
# 定义字符串变量 name = “小明”,输出: 我的名字叫小明,请多多关照!
name = "小明"
print("我的名字叫%s,请多多关照!" % name)
# 2. 定义整数变量 num = 1,输出: 我的学号是 000001
num = 1
print("我的学号是 %06d" % num)
# 3. 定义⼩数 price = 8.5、 weight = 5 ,输出:苹果单价 8.5 元/⽄,购买了 5.00
⽄,需要支付 42.50 元
price = 8.5
weight = 5
print("苹果单价 %.1f元/⽄,购买了 %.2f ⽄,需要支付 %.2f 元" % (price, weight,
price * weight))
# 4. 定义⼀个⼩数 scale = 10.01 ,输出: 数据是 10.01%
scale = 10.01
print("数据是 %.2f%%" % scale)转义字符
\t 在控制台输出一个制表符(tab),制表符的功能是在不使用表格的情况下在垂直方向对齐,这样通过 print 函数输出文本时可以保持垂直方向对齐。
\n 在控制台输出一个换行符。
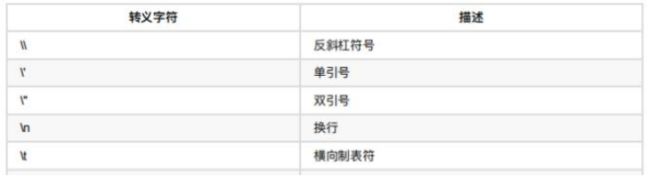
如果需要字符串输出"\n"或者"\t",而不是转义,那么就需要在字符串前面加r。
print("我\t你")
print("我\n你")
print("我\\你")
print("我\"你")
print("我\'你")
print(r"我\n你")5、流程控制
Python拥有控制代码执行和程序流程的多种语句结构,包括常见的分支结构和循环结构。
1. 布尔值和表达式
Python有很多表达布尔值的方式,布尔常量False、0、Python零值None、空值(如空的列表[]和空字符串""),都被视为False。布尔常量True和其他一切值都被视为True。
通过比较操作符(<、<=、==、>、>=、!=、is、is not、in、not in)和逻辑操作符(and、not、or),可以创建返回True和False的比较表达式。
2. if-elif-else语句
如果第一个if或elif后的代码块首个条件为True的代码块将会得以执行。如果都不为True,则else后的代码块会被执行。
x = 5
if x < 5:
y = -1
z = 5
elif x > 5: ❶
y = 1
z = 11
else: ❷
y = 0
z = 10
print(x, y, z)elif和else从句是可选的❶,elif从句的数量是任意的。Python用缩进作为代码块的分界线❷。代码块不必用什么显式的方括号或大括号之类的分隔符来标识。每个代码块由一条或多条换行符分隔的语句组成,同一个代码块中的语句必须处于同一缩进级别。上述示例中的输出将会是5 0 10。
只有姓名为”小明”并且年龄大于 20,才能通过:
name = "小明"
age = 25
if name == "小明" and age >= 20:
print("通过了")
else:
print("不能通过")只要姓名为”小明”或者年龄大于 20,都能通过:
name = "小明"
age = 25
if name == "小明" or age >= 20:
print("通过了")
else:
print("不能通过")只有姓名不叫”小明”才能通过:
name = "小明"
if not name == "小明":
print("通过了")
else:
print("不能通过")判断除数是否为0:
# num1通过input输入的数字
# num2通过input输入的数字
num1 = int(input("请输入num1的值"))
num2 = int(input("请输入num2的值"))
# 如果num2不等于0,计算num1 除以num2的结果
if num2 != 0:
print(num1 / num2)计算器:
num1 = int(input("请输入num1的值"))
num2 = int(input("请输入num2的值"))
a = input("请输入a的值")
if a == "+":
print(num1 + num2)
elif a == "-":
print(num1 - num2)
elif a == "*":
print(num1 * num2)
elif a == "/":
if num2 != 0:
print(num1 / num2)
else:
print("除数不能为0")
else:
print("a的值必须为+-*/")判断偶数:
num1 = int(input("请输入num1的值"))
# 如何判断一个整数是否为偶数,可以和2取余数,如果余数为0就是偶数,否则为奇数
if num1 % 2 == 0:
print("偶数")
else:
print("奇数")猜拳游戏:
# 1:石头
# 2:剪刀
# 3:布
# 石头赢剪刀
# 剪刀赢布
# 布赢石头
# 人通过键盘输入石头,剪刀,和布
# 电脑随机产生数字1或者2或者3
# 如果电脑产生数字1,那么就要转化为石头
# 如果电脑产生数字2,那么就要转化为剪刀
# 如果电脑产生数字3,那么就要转化为布
# 比较胜负
import random
# pc代表电脑要出的拳,可能是1,可能2或者3
pc = random.randint(1, 3)
# 需要把数字1,2,3转化为对应的字符串
# 变量a存放数字转化为字符串的结果
a = None
if pc == 1:
a = "石头"
elif pc == 2:
a = "剪刀"
else:
a = "布"
# player代表人要出的拳,可能是石头或者剪刀或者布
player = input("请输入石头或者剪刀或者布")
if (a == "石头" and player == "剪刀") or (a == "剪刀" and player == "布") or (a == "布" and player == "石头"):
print("电脑出了%s, 我出了%s, 电脑赢了" % (a, player))
elif (a == player):
print("电脑出了%s, 我出了%s, 平局" % (a, player))
else:
print("电脑出了%s, 我出了%s, 我赢了" % (a, player))3. while循环
只要循环条件为True(以下例子为x > y),while循环就会一直执行下去:
u, v, x, y = 0, 0, 100, 30 ⇽--- ❶
while x > y: ❷
u = u + y
x = x - y
if x < y + 2:
v = v + x
x = 0
else:
v = v + y + 2
x = x - y - 2
print(u, v)上面用到了一个简写记法,u和v被赋值为0,x被设置为100,y的值则成为30❶。接下来是循环代码块❷,循环可能包含break(退出循环)和continue语句(中止循环的本次迭代)。输出结果将会是60 40。
死循环:
由于程序员的原因,忘记在循环内部修改循环的判断条件,导致循环持续执行,程序无法终止!
a = 0
# 注意,这是一个死循环,因为 a 的值永远为 0,所以循环不会结束
while a < 5:
print("hello python")常见的计数方法有两种,可以分别称为:
- 自然计数法(从 1 开始)———更符合人类的习惯;
- 程序计数法(从0开始)--几乎所有的程序语言都选择从0开始计数;
因此,大家在编写程序时,应该尽量养成习惯:除非需求的特殊要求,否则循环 的计数都从 0 开始。
从 0 开始,截止到 5 的 6 个数字。
i = 0
while i <= 5:
print(i)
i += 1计算 0 ~ 100 之间所有数字的累计求和结果:
# 定义一个变量 num, 存放从 0 到 100 累加的结果
num = 0
# 定义一个变量 a, 决定 while 循环的次数
a = 0
# 只要 a<=100,循环就一直会进行,直到 a > 100 循环结束
while a <= 100:
num += a
a += 1
# 循环结束后,打印 num 的值
print(num)输出以下结果:
*
**
***
****
*****a = 0
# 外循环决定输出行数
while a < 5:
# 内循环决定每行输出的*号个数
b = 0
while b <= a:
print("*", end="")
b += 1
print("")
a += 14. for循环
for循环可以遍历所有可迭代类型,例如列表和元组,因此既简单又强大。与许多其他语言不同,Python的for循环遍历的是序列(如列表或元组)中的每一个数据项,使其更像是一个foreach循环。
下面的循环,将会找到第一个可以被7整除的整数:
item_list = [3, "string1", 23, 14.0, "string2", 49, 64, 70]
for x in item_list: ⇽--- ❶
if not isinstance(x, int):
continue ⇽--- ❷
if not x % 7:
print("found an integer divisible by seven: %d" % x)
break ⇽--- ❸x依次被赋予列表中的每个值❶。如果x不是整数,则用continue语句跳过本次迭代的其余语句。
程序继续流转,x被设为列表的下一项❷。当找到第一个符合条件的整数后,循环由break语句结束❸。
输出结果将会是:
found an integer divisible by seven: 49范围函数 range:
- range 生成一个指定范围的数据;
- range(start, stop,int);
- start,范围开始值;
- stop 范围终止值(不包括 stop);
- int,步长,如果小于 0,代表生成降序范围,如果省略 int,默认值为 1;
# 生成从 0 到 9 的范围,不包括 10
range(0, 10)
# 生成从 2 到 11 的偶数,不包括 11
range(2, 11, 2)
# 生成从 20 到 11 的降序范围,不包括 10
range(20, 10, -1)for 结合 range 实现指定次数的循环:
# a = 0
# while a < 10:
# print(a)
# a += 1
for n in range(0, 10):
print(n)结合range实现输出5行*号:
# 外循环循环了5次
# 内循环循环了5次
# 内循环的print("*", end="")
# 每次内循环完成外循环都有个print()
for a in range(0, 5):
for b in range(0, 5):
print("*", end="")
print()计算从50到124之间所有偶数的累加和:
# 在循环外,先定义一个变量存放累加和
# 在循环内,计算
# 循环完成后,输出这个变量的计算结果
sum = 0
for n in range(50, 125, 2):
sum += n
print(sum)5. break 和 continue
break 和 continue 是专门在循环中使用的关键字;
break 某一条件满足时,退出单层循环;
continue 某一条件满足时,结束本次循环(不执行continue后的循环体语句),执行下次循环;
break 和 continue 只针对当前所在循环有效;
1)break
在循环过程中,如果某一个条件满足后,不再希望循环继续执行,可以使用break 退出循环。
a = 0
while a < 10:
a += 1
# 如果 a 等于 5,while 循环退出
if a == 5:
break
print(a)2)continue
在循环过程中,如果 某一个条件满足后,不希望执行循环代码,但是又不希望退出循环,可以使用continue。
也就是:在整个循环中,只有某些条件,不需要执行循环代码,而其他条件都需要执行。
需要注意:使用 continue 时,条件处理部分的代码,需要特别注意,不小心会出现死循环。
a = 0
while a < 10:
a += 1
# 如果 a 等于 5,跳过下面的 print,直接回到 while 的开始继续循环
if a == 5:
continue
print(a)6、函数
1. 函数的作用
函数的作用,在开发程序时,使用函数可以提高编写的效率以及代码的重用。
函数的使用包含两个步骤:
- 定义函数 一一 封装独立的功能;
- 调用函数 一一 执行函数的代码;
2. 函数的定义
把代码封装到函数内部。
定义函数的格式如下:
def 函数名():
函数封装的代码
......1. def 是英文 define 的缩写;
2. 函数名称应该能够表达函数封装代码的功能,方便后续的调用;
3. 函数名称的命名应该符合标识符的命名规则;
3. 函数调用
通过 函数名() 即可完成函数的调用。
编写一个hello的函数,封装三行代码,在函数下方调用hello函数。
# 这里只是定义了一个函数,名叫hello
# 定义函数的时候,函数内部的代码并不会执行
def hello():
print("hello world")
print("hello world")
print("hello world")
# 调用函数
# 只有调用函数的时候,函数内部的代码才回真正执行
hello()定义函数和调用函数的说明:

注意:因为函数体相对比较独立,函数定义的上方,应该和其他代码(包括注释)保留两个空行。
定义好函数之后,函数内的代码并不会执行,只表示这个函数封装了一段代码而已。
调用函数后,函数的代码才会执行。如果不主动调用函数,函数是不会主动执行的。
能否将函数调⽤放在函数定义的上方?
不能!
因为在调⽤函数之前,必须要提前定义函数。
4. 函数的参数
- 函数的主要功能是封装代码;
- 一个已经定义完成函数,不应该在去修改函数内部的定义代码;
- 可以通过函数的参数,实现函数代码的灵活功能;
语法:
def 函数名(参数1, 参数2, .....):
函数内部封装代码
函数名(参数1对应的值, 参数2对应的值, .......)
# 调用的时候和定义函数的时候,参数的数量要一一对应开发一个 my_sum的函数,函数能够实现两个数字的求和功能。
# def my_sum():
# a = 5
# b = 6
# print(a + b)
# 函数一旦定义完成,就不会再次修改函数内部代码
# my_sum()
def my_sum(a, b):
print(a + b)
# 函数在定义的时候,有几个参数,调用的时候就要对应几个值
my_sum(5, 6) # 把5赋值给my_sum函数的a参数,把6赋值给my_sum函数的b参数函数只能处理固定数值的相加,如果能够把需要计算的数字,在调用函数时,传递到函数内部就好了。
- 在函数名的后面的小括号内部填写参数;
- 多个参数之间使用,分隔;
- 带参数的求和函数;
def my_sum1(num1, num2):
result = num1 + num2
print(result)
my_sum1(5, 9)5. 参数的作用
函数:把具有独立功能的代码块组织为一个小模块,在需要的时候调用。
函数的参数:增加函数的通用性,针对相同的数据处理逻辑,能够适应更多的数据。
1. 在函数内部,把参数当做变量使用,进行需要的数据处理。
2. 函数调用时,按照函数定义的参数顺序,把希望在函数内部处理的数据,通过参数传递。
6. 形参和实参
形参:
- 定义函数的时候,括号里面的参数;
- 形参必须是变量;
实参:
- 调用函数的时候,括号里面的参数;
- 实参可以是常量;
- 实参可以是变量;
- 实参可以是表达式;
定义函数的时候,形参有值吗?
- 定义函数的时候,形参没有值,只是一个变量名;
- 只要调用函数的时候,通过实参把值实时赋值给形参;

Python为函数提供了灵活的参数传递机制:
>>> def funct1(x, y, z): ⇽--- ❶
... value = x + 2*y + z**2
... if value > 0:
... return x + 2*y + z**2 ⇽--- ❷
... else:
... return 0
...
>>> u, v = 3, 4
>>> funct1(u, v, 2)
15
>>> funct1(u, z=v, y=2) ⇽--- ❸
23
>>> def funct2(x, y=1, z=1): ⇽--- ❹
... return x + 2 * y + z ** 2
...
>>> funct2(3, z=4)
21
>>> def funct3(x, y=1, z=1, *tup): ⇽--- ❺
... print((x, y, z) + tup)
...
>>> funct3(2)
(2, 1, 1)
>>> funct3(1, 2, 3, 4, 5, 6, 7, 8, 9)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
>>> def funct4(x, y=1, z=1, **kwargs): ⇽--- ❻
... print(x, y, z, kwargs)
>>> funct4(1, 2, m=5, n=9, z=3)
1 2 3 {'n': 9, 'm': 5}函数通过def语句❶来定义,并用return语句❷来返回值,返回值可以是任意类型。
如果没有遇到return语句,则函数将返回Python的None值。函数的参数可以由位置或名称(关键字)来给出。
在上述例子中,z和y就是按名称给出的❸。可以为函数参数定义默认值,只要在调用时不为该参数赋值即可生效❹。还可以为函数定义一个特殊的元组参数,将调用时剩余的位置参数都放入元组中❺。同样,也可以定义一个特殊的字典参数,将调用函数时剩余的关键字参数全都放入字典中❻。
7. Python参数高级特性
1)必选参数
- def foo(x,y,z):pass
2)默认参数
- def foo(x=1):pass
- 假如不传x参数的话,x默认是等于1
3)可变参数(*)
不定长传参:
- 定义: def foo(*args):pass
- 调用:foo(1,2,3,4,5)
元组和列表的压包:
- 定义:def foo(*args):pass
- 调用:foo(*(1,2,3,4,5)) or foo(*[1,2,3,4,5])
4)关键字参数(**)
- 定义: def foo(**kwargs):pass,其中kwargs是一个字典;
调用:
- foo(k1=v1,k2mv2)参数传入键值对;
- foo(**d)参数传入字典d;
5)命名关键字参数(*)
定义:
- def foo(a,b,*,k1,k2,k3):pass a,b是普通参数,k1,k2,k3是命名关键字参数;
- 命名关键字参数需要一个特殊分隔符*,后面的参数被视为命名关键字参数;
- 如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了;
调用:
- foo(a,b,k1mv1,k2mv2,k3mv3)
6)参数组合
定义:
def fun(parameter,*args,keyparameter,**kwargs):pass参数定义顺序:必选参数,默认参数,可变参数,命名关键字参数,关键字参数。
8. 函数返回值
在程序开发中,有时候会希望一个函数执行结束后,告诉调用者一个结果,以便调用者针对具体的结果做后续的处理。
返回值是函数完成工作后,最后给调用者的一个结果。
在函数中使用 return 关键字可以返回结果。
调用函数一方,可以使用变量来接收函数的返回结果。
注意:return 表示返回,后续的代码都不会被执行。
带返回值的my_sum2函数:
def my_sum2(num1, num2):
result = num1 + num2
return result
# return 后面的代码,将不会被执行
print("test")
a = my_sum2(5, 9)
print(a)返回参数中的最大值:
def my_max(num1, num2):
if num1 > num2:
return num1
else:
return num2
a = my_max(5, 9)
print(a)定义一个函数,有两个参数,start 和 stop,start 代表开始范围,stop 代表终止范围,求这个范围中所有整数相加的和。
def my_sum1(start, stop):
sum = 0
a = start
while a <= stop:
sum += a
a += 1
return sum
print(my_sum1(3, 9))定义一个函数能够根据半径计算圆的面积:
def circular(r):
pai = 3.14
s = pai * r **2
return s
print(circular(1))return的意义:
- 需求不停的变化,但函数一旦定义函数内部的代码不应该因为需求改变而改变;
- 所以要把因为需求而改变的代码放到函数之外,函数之内代码函数定义完不改变;
定义一个函数,名字叫 my_func,有两个参数 num1与 num2,当 num1能被 num2 整除时,返回值为True,否则返回值为False。
def my_func(num1, num2):
if num1 % num2 == 0:
return True
else:
return False
print(my_func(8, 4))
print(my_func(9, 4))多个返回值:
return多个值,其实是返回一个元组。
def foo():
×,y,z=1,2,3
return x,y,z
# 返回一个元组
tup = foo()
# 元组拆包
x1,y1,z1 = foo()9. 函数-嵌套调用
一个函数里面又调用了另外一个函数,这就是函数嵌套调用。
如果函数 test2 中,调用了另外一个函数 test1,那么执行到调用 test1 函数时,会先把函数 test1 中的任务都执行完才会回到 test2中调用函数 test1 的位置,继续执行后续代码。
def test1():
print("我是 test1")
def test2():
# 先执行函数 test1 的代码
test1()
# test1 函数执行完毕后,再执行下面代码
print("我是 test2")
test2()7、函数高级特性
1. 函数的递归
# 典型案例:斐波那契数列
def fib_recursion(idx):
if idx <= 2:
return 1
else:
return fib_recursion(idx-1) + fib_recursion(idx-2)
注意:
- 必须设置函数终止条件;
- 实用递归优点是逻辑简单清晰,缺点是过深调用导致栈溢出;
2. 函数作用域
1)局部变量和全局变量
局部变量是在函数内部定义的变量,只能在函数内部使用。
全局变量是在函数外部定义的变量(没有定义在某一个函数内),所有函数内部都可以使用这个变量。
提示:在其他的开发语言中,大多不推荐使用全局变量——可变范围太大,导致程序不好维护。
2)局部变量
局部变量是在函数内部 定义的变量,只能在函数内部使用。
函数执行结束后,函数内部的局部变量,会被系统回收。
不同的函数,可以定义相同的名字的局部变量,彼此之间不会产生影响。
3)局部变量的作用
在函数内部使用,临时保存函数内部需要使用的数据:
def my_func1():
a = 10
def my_func2():
a = 20
my_func1() # 调用 my_func2 函数,不会影响 a 的值
print("a = %d" % a)
my_func2()局部变量从调用函数的时候开始在内存出现,函数调用完毕,局部变量从内存消失。
如果一个函数内部定义了局部变量,但这个函数没有被调用,那么局部变量也不在内存中存在。
def my_func1():
a = 1 # a是一个局部变量,只属于my_func1函数
print(a)
def my_func2():
a = 2 # a是一个局部变量,只属于my_func2函数
print(a)
my_func1() # 调用函数的时候,局部变量a出现了
# my_func1函数调用完毕,a消失了
# 定义函数的时候局部变量并不存在,只有调用函数的时候局部变量出现了
print("end")4)局部变量的生命周期
所谓生命周期就是变量从被创建到被系统回收的过程;
局部变量在函数执行时才会被创建;
函数执行结束后局部变量被系统回收;
局部变量在生命周期内,可以用来存储 函数内部临时使用到的数据;
5)全局变量
全局变量是在函数外部定义的变量,所有函数内部都可以使用这个变量。
为了保证所有的函数都能够正确使用到全局变量,应该将全局变量定义放在其他函数上方。
# 定义一个全局变量 num
num = 100
def my_func1():
print(num)
def my_func2():
print(num)
my_func1()
my_func2()全局变量一般定义在函数定义的上方。
全局变量从定义变量开始在内存中出现,一直到程序运行完成,和程序一起从内存中消失 。
num1 = 2
def my_func1():
print(num1)
def my_func2():
print(num1)
my_func1()
num1 = 10
my_func2()
print("end")6)全局变量与局部变量重名
如果在函数内部定义一个变量,名字和全局变量重名,那么在这个函数内部只能使用局部变量。
# 定义一个全局变量 num
num = 100
def my_func1():
# 函数内部定义一个变量和全局变量重名
num = 1
# 全局变量 num 的值并没有改变
my_func1()
print(num)注意:只是在函数内部定义了一个局部变量而已,只是变量名相同--在函数内部不能直接修改全局变量的值。
num1 = 1
def my_func1():
num1 = 10 # 这里不是为全局变量赋值, 这里是定义了一个局部变量, 名字和全局变量重名
print(num1) # 打印的是局部变量num1的值
num1 += 1 # 这里改的是局部变量num1的值
def my_func2():
print(num1) # 全局变量num1
my_func1()
my_func2()
print(num1) # 打印的是全局变量num1的值7)global关键字
如果在函数中需要修改全局变量,需要使用 global 进行声明:
# 定义一个全局变量 num
num = 100
def my_func1():
# 函数内部使用 global 关键字声明全局变量 num
global num
num = 1
# 全局变量 num 的值被 my_func1 函数改变
my_func1()
print(num)8)函数作用域案例
1. 外部不能访问函数内部变量;
2. 函数内部能够访问外部变量;
3. 函数内部不能修改外部变量,强行修改需要加 global外部变量=新值;
4. 函数内部和函数外部变量名可以相同,但需要注意访问优先级;
# 例子一,内部访问同名变量,不要在内部变量定义之前去访问
g = 1
def foo():
print(g) # 报错 UnboundLocalError: local variable 'g' referenced be
g = 2
print(g) # 2
foo()
print(g) # 1
# -------------------- #
# 例子二,采用global关键字,会把内部变量g声明成全局变量,从而在函数内部可以改变
g = 1
def foo():
global g
print(g) # 1
g = 2
print(g) # 2
foo()
print(g) # 23. 参数进阶
1)形参和实参的值传递
如果函数的参数为数字,字符串,在函数内部,针对形参使用赋值语句,不会影响调用函数时传递的实参的值。
def my_func1(a): # 这里的a是形参, 这里的a只是一个属于函数my_func1的形参,而不是全局变量a
a += 1 # 在函数内部,修改了形参a的值,不是修改了全局变量a的值
print(a) # 输出了形参a的值
a = 10 # 程序的入口 定义一个全局变量a,值是10
my_func1(a) # 把全局变量a做为实参,去调用函数my_func1
print(a) # 全局变量a的值没有改变
# 当参数类型为数字或者字符串, 形参的值改变了,实参的值不会改变函数的形参,本质就是一个属于函数内部的局部变量。
a = 10
def my_test1(a):
a += 1 # 重名后,这里操作的是局部变量a
print(a)
my_test1(a) # 把全局变量做为形参来调用my_test1函数了
print(a)
# 代码中一共出现两个变量
# 全局变量a和一个形参a(形参其实就是一个属于函数内部的局部变量)
# 以上代码的结果是全局变量与局部变量重名如果函数参数为列表,集合,字典等类型。函数内部修改了参数的内容,会影响到外部的数据。
a = [1, 2, 3]
def my_test1(a): # 这里的a是一个形参,也是一个属于my_test1的局部变量
a[0] = 10 # 修改的是形参a的值
# 如果形参的类型为列表,集合和字典,修改形参的值会直接影响实参的值
print(a) # 显示的是全局变量a的值
my_test1(a) # 把全局变量做为实参,来调用my_test1
print(a)定义一个函数,参数为列表类型,调用函数过后,删除列表所有值。
a = [1, 2, 3]
def my_test1(a):
a.clear()
my_test1(a)
print(a)2)缺省参数
定义函数时,可以给 某个参数指定一个默认值,具有默认值的参数就叫做缺省参数。
调用函数时,如果没有传入缺省参数的值,则在函数内部使用定义函数时指定的参数默认值。
函数的缺省参数,将常见的值设置为参数的缺省值,从而简化函数的调用。
单个缺省参数:
# 第二个参数的缺省值为 100
def my_func1(a, b = 100):
print("a = %d, b = %d" % (a, b))
my_func1(1, 2)
# 没有写第二个参数,第二个参数采用缺省值 100
my_func1(1)多个缺省参数:
当函数有多个缺省参数,调用函数的时候,对于不使用默认值的缺省参数可以通过:参数 = 值 的方式,明确具体参数的值。
def my_func2(a = 100, b = 200, c = 300):
print("a = %d, b = %d, c = %d" % (a, b, c))
my_func2(1, 2, 3)
# 没有写前两个参数,前二个参数采用默认值,第三个参数值为 3
my_func2(c = 3)缺省参数的注意事项:
缺省参数的定义位置,必须保证带有默认值的缺省参数在参数列表末尾。
所以,以下定义是错误的!
def print_info(name,gender=True,title):不能把有缺省值的形参写在没有缺省值形参的前面:
# def my_test3(a = 10, b): 不能把有缺省值的形参写到没缺省值形参的前面
# print(a, b)4. 匿名函数
用lambda 关键词能创建小型匿名函数。
这种函数得名于省略了用def声明函数的标准步骤,也不用写return 。
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,....argn]]:expression如下实例:
sum = lambda arg1,arg2: arg1+ arg2lambda 案例 1:
# 简化版的 sum 求和函数
my_sum = lambda a, b: a + b
num = my_sum(3, 6)
print(num)
num1 = my_sum(23, 4)
print(num1)lambda 案例 2:
# def my_max(a, b):
# if a > b:
# return a
# else:
# return b
# 简化版的 lambda 函数,求最大值
num = (lambda a, b: a if a > b else b)(3, 6)
print(num)lambda注意事项:
- 匿名函数内部只能有一条语句,而且这条语句要有个具体的值返回;
- Lambda 函数只能返回一个表达式的值 ;
- 匿名函数不能直接调用print,因为 lambda 需要一个表达式;
5. 高阶函数
1)map
用法: map(函数名,列表/元组/集合/字符串)。
说明:把传入的函数依次作用于每个元素,处理完后返回的是生成器类型,需要用list生成数据。
li = [1, 2, 3, 4, 5]
def add1(x):
return x + 1
add_li = list(map(add1, li)) # [2, 3, 4, 5, 6]2)filter
用法:filter(函数名, 列表/元组/集合/字符串)。
说明:filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素,处理完后返回的是生成器类型,需要用list生成数据。
li = [1, 2, 3, 4, 5, 6]
def even_num(n):
if n%2 == 0:
return n
even_li = list(filter(even_num, li)) # [2,4,6]3)reduce()
用法:reduce(函数名,列表/元组/集合/字符串)。
说明:reduce()用于对参数序列中元素进行累积。python3 中,reduce已经被从全局名字空间里移除了,它被放置在functools模块里。
from functools import reduce
li = [1, 2, 3, 4, 5]
m = reduce(lambda x, y : x+y, li) # m=156. 返回函数
def outer_foo(*args):
def inner_foo():
for i in args:
print(i)
return inner_foo
f = outer_foo(1, 2, 3, 4, 5)
f() # 1 2 3 4 5函数可以被当作返回值返回。
7. 函数的闭包
闭包就是引用了自有变量的函数,这个函数保存了执行的上下文,可以脱离原本的作用域独立存在。实际上,装饰器就是一个闭包,把一个函数当做参数然后返回一个替代版函数。
# print_msg是外围函数
def print_msg():
msg = “Hello World!“
# printer是嵌套函数
def printer():
print(msg)
return printer
# 这里获得的就是一个闭包
closure = print_msg()
closure()典型案例1:
# 外部函数只是返回了函数名的列表,但并没有调用。等到内部函数被调用的时候,外部函
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
print(f1()) # 9
print(f2()) # 9
print(f3()) # 9
典型案例2:
# 外部函数返回的是内部函数名的调用,所以结果和案例1不相同
def count():
def f(j):
def g():
return j*j
return g
fs = []
for i in range(1, 4):
fs.append(f(i)) # f(i)立刻被执行,因此i的当前值被传入f()
return fs
f1,f2,f3=count()
print(f1()) # 1
print(f2()) # 4
print(f3()) # 98. 匿名函数
语法: lambda 形参:含形参的表达式。
f = lambda x:x+1
print(f(1)) # 2lambda 返回的是函数名(函数地址)。
lambda 常常与map、filter、reduce、sorted等联合使用。
9. 装饰器
装饰器,顾名思义,就是增强函数或类的功能的一个函数,也可以装饰类。装饰器本质上是一个python函数,它可以让其他函数在不需要做任何代码改动的前提下增加额外的功能,装饰器的返回值也是一个函数对象。
装饰器经常用于有切面需求的场景,比如:插入日志/性能测试/事务处理/缓存/权限校验等,有了装饰器就可以抽离出大量与函数功能本身无关的雷同代码并继续重用,概括地讲,装饰器的作用就是为已经存在的对象添加额外的功能。
装饰器使用方便的因为:python中允许将函数赋给变量,允许在函数中定义另外的函数,允许从函数中返回函数,也允许将函数作为参数传给另一个函数。
定义装饰器:
def decorator(func):
def wrapper(*args,**kargs): # 可以自定义传入的参数
print(func.__name__)
return func(*args,**kargs) # 返回传入的方法名参数的调用
return wrapper # 返回内层函数函数名实用装饰器:
# 使用方法1
f = decorator(函数名) # 装饰器不传入参数时
f = (decorator(参数))(函数名) # 装饰器传入参数时
f() # 执行被装饰过的函数
# 使用方法2
@decorator # 已定义的装饰器
def f(): # 自定义函数
pass
f() # 执行被装饰过的函数自身不传入参数的装饰器:
def login(func):
def wrapper(*args,**kargs):
print('函数名:%s'% func.__name__)
return func(*args,**kargs)
return wrapper
@login
def f():
print('inside decorator!')
f()
# 输出:
# 函数名:f
# 函数本身:inside decorator!自身传入参数的装饰器:
def login(text):
def decorator(func):
def wrapper(*args,**kargs):
print('%s----%s'%(text, func.__name__))
return func(*args,**kargs)
return wrapper
return decorator
@login('this is a parameter of decorator')
def f():
print('2022-06-13')
f() # 等价于 ==> (login(text))(f)() ==> 调用 wrapper() 并返回 f()
# 输出:
# this is a parameter of decorator----f
# 2022-06-13装饰器的使用:
不用语法糖。
# 装饰器不传入参数时
f = decorator(函数名)
# 装饰器传入参数时
f = (decorator(参数))(函数名)使用语法糖。
# 已定义的装饰器
@decorator
def f():
pass
# 执行被装饰过的函数
f()简单装饰器举例:
如何为foo()函数增加需求“记录函数的执行日志”。
def foo():
print('i am foo’)方法1:
在函数内增加代码,当多个函数都需要增加这个功能需要在每个函数都增添相同的代码。
def foo():
print('i am foo’)
logging.info(“foo is running”)方法2:
额外定义一个专门处理日子的函数,日志处理后在执行真正的业务代码,问题是需要修改函数的调用方式。
def foo():
print('i am foo’)
def using_logging(func):
logging.info(“%s is running”% func.__name__)
func()
using_logging(foo)方法3:
利用简单装饰器,函数use_logging就是装饰器,它把真正的业务方法函数包裹在函数里。
def foo():
print('i am foo’)
def use_logging(func):
def wrapper(*args, **kwargs):
logging.info(“%s is running”% func.__name__)
return func(*args, **kwargs)
return wrapper
foo = use_logging(foo)
foo()方法4:
利用装饰器的语法糖@(语法糖:便捷写法),在定义函数的使用,避免再一次赋值操作,直接调用函数就可以得到想要的结果。
def use_logging(func):
def wrapper(*args, **kwargs):
logging.info(“%s is running”% func.__name__)
return func(*args, **kwargs)
return wrapper
@use_logging
def foo():
print('i am foo’)
@use_logging
def zoo():
print('i am zoo’)
foo()
zoo()10. 内置装饰器
@property :把类内方法当成属性来使用,必须要有返回值,相当于getter;假如没有定义@func.setter修饰的方法的话,就是只读属性。
# property 例子
class Car:
def __init__(self,name,price):
self._name = name
self._price = price
@property
def car_name(self):
return self._name
# car_name可以读写的属性
@car_name.setter
def car_name(self,value):
self._name = value
# car_price是只读属性
@property
def car_price(self):
return str(self._price)+'万'
benz = Car('benz',30)
print(benz.car_name) # benz
benz.car_name = "baojun"
print(benz.car_name) # baojun
print(benz.car_price) #30万@staticmethod:静态方法,不需要表示自身对象的self和自身类的cls参数,就跟使用函数一样。
@classmethod:类方法,不需要self参数,但第一个参数需要是表示自身类的cls参数。
class Demo(object):
text = "三种方法的比较"
# 【1】
def instance_method(self):
print("调用实例方法")
# 【2】
@classmethod
def class_method(cls):
print("调用类方法")
print("在类方法中 访问类属性 text: {}".format(cls.text))
print("在类方法中 调用实例方法 instance_method: {}".format(cls().instance_method()))
# 【3】
@staticmethod
def static_method():
print("调用静态方法")
print("在静态方法中 访问类属性 text: {}".format(Demo.text))
print("在静态方法中 调用实例方法 instance_method: {}".format(Demo().instance_method()))
if __name__ == "__main__":
# 实例化对象
d = Demo()
# 对象可以访问 实例方法、类方法、静态方法
# 通过对象访问text属性
print(d.text)
# 通过对象调用实例方法
d.instance_method()
# 通过对象调用类方法
d.class_method()
# 通过对象调用静态方法
d.static_method()
# 类可以访问类方法、静态方法
# 通过类访问text属性
print(Demo.text)
# 通过类调用类方法
Demo.class_method()
# 通过类调用静态方法
Demo.static_method()@staticmethod和@classmethod的区别和使用场景:
在上述例子中,我们可以看出,在定义静态类方法和类方法时, Qstaticmethod 装饰的静态方法里面,想要访问类属性或调用实例方法,必须需要把类名写上;而@classmethod装饰的类方法里面,会传一个cls参数,代表本类,这样就能够避免手写类名的硬编码。
在调用静态方法和类方法时,实际上写法都差不多,一般都是通过类名.静态方法()或类名.类方法()。也可以用实例化对象去调用静态方法和类方法,但为了和实例方法区分,最好还是用类去调用静态方法和类方法。
所以,在定义类的时候,假如不需要用到与类相关的属性或方法时,就用静态方法
@staticmethod ;假如需要用到与类相关的属性或方法,然后又想表明这个方法是整个类通用的,而不是对象特异的,就可以使用类方法 @classmethod 。
11. 装饰器进阶
1)带参数的装饰器
不能接收参数的装饰器只能适用于一些简单的场景,只能对被装饰函数执行固定逻辑,这无疑是非常不合理的。装饰器实现传参需要两层嵌套。
def now(time):
def sayName(func):
def inner(name):
print('现在是: %s' % time)
print("I'm Yu")
return func(name)
return inner
return sayName
@now('2016/10/30')
def sayHi(name):
print('Hello,' + name)
sayHi('siri')
输出信息:
现在是: 2016/10/30
I'm Yu
Hello,siri2)类装饰器
类装饰器本质上和函数装饰器原理、作用相同,都是为其它函数增加额外的功能。但是相比于函数装饰器,类装饰器具有灵活度大、高内聚、封装性等优点。使用类装饰器可以直接依靠类内部的__call__方法来实现,当使用语法糖形式将类装饰器附加到函数上时,就会调用类装饰器的__call__方法,而不需要向函数装饰器那样,在装饰器函数中定义嵌套函数,来实现装饰功能。
下面代码中的的@Foo相当于bar = Foo(bar),等号左边的bar是类Foo的实例对象,等号右边的bar是类装饰器所装饰的函数名bar作为参数传递给类Foo。下面执行bar()即为调用类Foo的对象bar,此时会自动调用类中定义的__call__方法。
# 功能:使用类装饰器为一个函数的执行增加计时功能
import time
class Foo():
# 初始化函数中传入函数对象的参数
def __init__(self, func):
self._func = func
# 定义__call__方法,直接实现装饰功能
def __call__(self):
start_time = time.time()
self._func()
end_time = time.time()
print('花费了 %.2f' % (end_time - start_time))
# bar=Foo(bar)
@Foo
def bar():
print('bar函数的执行时间为:')
time.sleep(2.5)
foo = Foo()
# bar=Foo(bar)(),没有嵌套关系,直接执行Foo的 __call__方法,实现装饰功能
foo.bar()
输出信息:
bar函数的执行时间为:
花费了 2.513)functools.wraps
Python装饰器在实现的时候,被装饰后的函数其实已经是另外一个函数了(函数名等函数属性会发生改变),为了消除这样的副作用,Python的functools包中提供了一个叫wraps的装饰器来消除这样的副作用。
使用functools的wraps来创建装饰器的目的是为了被封装的函数能保留原来的内置属性。如以下代码:可以看到未使用wraps的sayhello函数的__name__输出的是封装函数wraptest的属性,而不是被封装函数自身的属性,而使用wraps的输出的是被封装函数自身的属性。
# 【1】
def protest(func):
def wraptest(*args, **kwargs):
print('Before func')
func(*args, **kwargs)
return wrap
@protest
def sayhello(word):
print(word)
if __name__ == '__main__':
sayhello('hello, boy')
print(sayhello.__name__)
输出信息:
Before func
hello, boy
wraptest
# 【2】
from functools import wraps
def protest(func):
@wraps(func)
def wraptest(*args, **kwargs):
print('Before func')
func(*args, **kwargs)
return wrap
@protest
def sayhello(word):
print(word)
if __name__ == '__main__':
sayhello('hello, boy')
print(sayhello.__name__)
输出信息:
Before func
hello, boy
sayhello12. 内置函数
1)常用函数
- len() 求长度;
- min() 求最小值;
- max() 求最大值;
- sorted() 排序;
- sum() 求和;
- dir() 查看对象所有属性和方法;
- type() 查看对象属于哪个类;
2)进制转换函数
- bin() 转换为二进制;
- oct() 转换为八进制;
- hex() 转换为十六进制;
- ord() 字符转ASCII码;
- chr() ASCII码转字符;
3)高级内置函数
enumerate() 转化为元组标号,通常用于遍历输出列表元素下标:
# enumerate 的例子
li = [1, 2, 3, 4, 5]
for idx, ele in enumerate(li):
print(idx, ':', ele)eval(str) 只能运行一行字符串代码,也可以用于字符串转字典:
# eval 的例子
d = eval("{'a':1,'b':2}")
print(type(d))
print(d)exec(str) 执行字符串编译过的字符串,可以运行多行字符串代码。
filter(函数名,可迭代对象) 过滤器。
map(函数名,可迭代对象) 对每个可迭代对象的每个元素处理。
zip(可迭代对象,可迭代对象) 将对象逐一配对。
# zip 的例子
# 压缩
l1 = ['a', 'b', 'c', 'd', 'e']
l2 = [1, 2, 3, 4, 5]
l = list(zip(l1,l2)) # [('a', 1), ('b', 2), ('c', 3), ('d', 4), ('e', 5)
d = dict(zip(l1,l2)) # {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
# 解压
tup = (('a',1),('b',2),('c',3),('d',4))
l1,l2 = zip(*tup)
# l1 ('a', 'b', 'c', 'd')
# l2 (1, 2, 3, 4)13. 高级特性
1)切片
切片适用于字符串 '' 、列表 [] 和元组 ():
li = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(li[0]) # 取下标为0的元素,1
print(li[::]) # 取全部元素,[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(li[::2]) # 步长为2取值,[1, 3, 5, 7, 9]
print(li[1:3]) # 左开右闭,[2, 3]
print(li[1:]) # 下标大于等于1的元素,[2, 3, 4, 5, 6, 7, 8, 9, 10]
print(li[:5]) # 下标小于5的元素,[1, 2, 3, 4, 5]
print(li[::-1]) # 列表逆序,[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]2)迭代
可迭代对象:可以直接作用于for循环的对象统称为可迭代对象( Iterable ) 。
判断对象是否可迭代:
from collections import Iterable
print(isinstanc(对象,Iterable))
# True为可迭代
# False为不可迭代可迭代对象:字符串,列表,元组,字典,集合。
遍历可迭代对象(字典除外):
for i in 可迭代对象:
语句对字典遍历:
# d 是一个字典
# 遍历 keys
for i in d:
语句
# 或者
for i in d.keys():
语句
# 遍历 values
for i in d.values():
语句
# 同时遍历 key 和 value
for k,v in d.items():
语句3)生成式
列表生成式 [返回的参数 for循环 条件判断]:
li = [i for i in range(11) if i%2==0]
print(li) # [0, 2, 4, 6, 8, 10]集合生成式 {返回的参数 for循环 条件判断}:
s = {i for i in range(1,10) if i%2==0}
print(s) # {8, 2, 4, 6}字典生成式 {key:value for循环 条件判断}:
li=['a','b','c','d','e','f','g','h']
d={i:j for i,j in enumerate(li) if i%2==0}
print(d) # {0: 'a', 2: 'c', 4: 'e', 6: 'g'}生成器 (返回的参数 for循环 条件判断):
gen = [i for i in range(11) if i%2==0]
print(gen) # [0, 2, 4, 6, 8, 10]14. 生成器
生成器:为了节省内存空间,提高程序速度,这种一边循环一边计算的机制,称为生成器
( Generator )。
next() 取值:
li=[1, 2, 3, 4, 5]
g=(x for x in li)
print(g)
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
# [输出]:
# at 0x0000018F628397C8>
# 1
# 2
# 3
# 4
# 5 for循环遍历取值:
li=[1, 2, 3, 4, 5]
g=(x for x in li)
print(g)
for i in g:
print(i)
# [输出]:
# at 0x0000018F628397C8>
# 1
# 2
# 3
# 4
# 5 生成器函数:
用yield返回的函数,都可以看作是生成器。
def fun():
yield 1
yield 2
yield 3
print(next(f)) # 1
print(next(f)) # 2
print(next(f)) # 3
print(next(f)) # 抛出异常:StopIteration用for循环遍历生成器:
f = fun()
for i in f:
print(i)
# [输出]:
# 1
# 2
# 315. 迭代器
迭代器:可以被 next() 函数调用并不断返回下一个值的对象称为迭代器( Iterator ) 。
实用 iter(可迭代对象) 可以把可迭代对象转化为迭代器。
it = iter([1, 2, 3, 4, 5])
next(it) # 1
next(it) # 2
next(it) # 3注意:
- 凡是可作用于for循环的对象都是Iterable类型;
- 凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
- 集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象;
- Python的for循环本质上就是通过不断调用next()函数实现的;
8、类与面向对象编程
1. 面向函数的编程方式
- 把完成某一个需求的所有步骤从头到尾逐步实现;
- 根据开发需求,将某些功能独立的代码封装成一个又一个函数;
- 最后完成的代码,就是顺序地调用不同的函数;
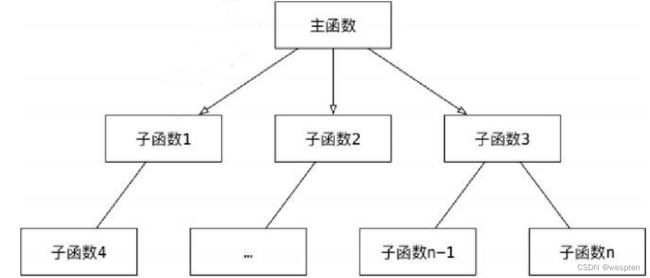
2. 面向对象的编程方式
相比较函数,面向对象是更大的封装,根据职责在一个对象中封装多个方法。
- 在完成某一个需求前,首先确定职责 -- 要做的事情(方法);
- 根据职责确定不同的对象,在对象内部封装不同的方法;
- 最后完成的代码,就是顺序地让不同的对象调用不同的方法;
3. 类和对象的概念
类和对象是面向对象编程的两个核心概念。
1)类
类是对一群具有相同特征或者行为的事物的一个统称,是抽象的,不能直接使用。
- 特征被称为属性;
- 行为被称为方法;
类就相当于制造飞机时的图纸,是一个模板。
2)对象
对象是由类创建出来的一个具体存在,可以直接使用。
由哪一个类创建出来的对象,就拥有在哪一个类中定义的:
- 属性 ;
- 方法;
对象就相当于用图纸制造的飞机。
3)类和对象的关系
类是模板,对象是根据类这个模板创建出来的,应该先有类,再有对象 ;
类只有一个,而对象可以有很多个;
不同的对象之间属性可能会各不相同;
类中定义了什么属性和方法,对象中就有什么属性和方法,不可能多,也不可能少 ;
4. 类的设计
在程序开发中,要设计一个类,通常需要满足一下三个要素:
- 类名:这类事物的名字;
- 属性:这类事物具有什么样的特征;
- 方法:这类事物具有什么样的行为;
1)属性和方法的确定
对于对象的特征描述,通常可以定义成属性,属性的具体实现可以是一个变量。
对象具有的行为(动词),通常可以定义成方法,方法的具体实现可以是一个类里面的函数。
提示:需求中没有涉及的属性或者方法在设计类时,不需要考虑。
2)一个小猫类 cat 的描述
属性:
- name(姓名);
-
color(颜色);
-
height(身高);
-
weight(体重);
-
sex(性别);
方法:
- eat (吃);
- drink(喝);
-
sleep( 睡 ) ;
5. 面向对象编程
1)class关键字
class 关键字用于创建一个类,语法如下:
class 类名:
def 方法1(self, 参数列表):
pass
def 方法2(self, 参数列表):
pass方法的定义格式和之前学习过的函数几乎一样。
区别在于第一个参数必须是 self,大家暂时先记住,稍后介绍 self。
2)类的代码实现
class cat:
def eat(self):
print("汤姆爱吃鱼")
def drink(self):
print("汤姆爱喝水")3)创建一个对象
名词解释:
- 实例-----通过类创建出来的对象叫做类的实例;
- 实例化-----创建对象的动作叫做实例化;
创建对象语法:
对象名 = 类名(参数列表)
# 对象创建后通过对象名.方法名(参数),调用方法
对象名.方法1()类是静态的,只有创建为对象后,才能成为动态运行的程序。
class cat: # 定义了一个类cat,这个类不能直接使用
def eat(self): # 第一个参数必须是self
print("猫吃饭")
def drink(self):
print("猫喝水")
c1 = cat() # 根据类cat, 创建了一个对象c1, 对象名类似于变量名
c1.eat() # 调用的时候,不需要提供self对应的实参
c1.drink() # 调用对象的方法
# 方法只能通过对象调用,不能通过类直接调用
# c1就是类cat的实例
# c1 = cat() 这个动作就叫实例化
c2 = cat() # 实例化, 实例化的结果是cat类有一个对象叫c2
# c2是类cat的实例4)方法中的 self 参数
- 在类封装的方法内部, self 就表示调用方法的对象自己;
- 调用方法时,不需要传递 self 参数;
- 在方法内部可以通过 self.访问对象的属性,通过在方法内部使用 self.属性名=值,为类添加属性;
- 在方法内部可以通过 self.调用对象的方法;
- 在类的外部,通过 对象名.访问对象的属性和方法 ;
- self 可以在方法内部定义和使用属性;
-
self 可以在方法内部嵌套调用其他方法;
-
在类的外部,是不能使用self;
-
在类的外部调用方法:对象名.方法名;
-
在类的外部使用属性:对象名.属性名;
class cat: # 定义了一个类cat,这个类不能直接使用
def set_name(self):
self.name = "tom" # 定义了一个属性,名叫name,值是tom
def eat(self): # 第一个参数必须是self
print("%s吃饭" % self.name) # 这里在使用name属性
def drink(self):
print("%s喝水" % self.name) # 这里在使用name属性
def demo(self): # 这个方法只是为了举例,在类的内部,方法嵌套调用
self.eat()
self.drink()
c = cat()
c.set_name()
c.drink()
c.eat()
c.name = "张三"
c.drink()
c.eat()
c.demo()5)cat类添加name属性,同时创建两个对象
# 定义 cat 类
class cat:
def set_name(self, name):
# 给 cat 类添加一个属性 name
self.name = name
def eat(self):
print("%s 爱吃鱼" % self.name)
def drink(self):
print("%s 爱喝水" % self.name)
# 创建 lazy_cat 对象
lazy_cat = cat()
lazy_cat.set_name("懒猫")
lazy_cat.eat()
lazy_cat.drink()
# 创建 tom_cat 对象
tom_cat = cat()
tom_cat.set_name("tom 猫")
tom_cat.eat()
tom_cat.drink()6)定义小狗类
创建小狗类的对象,设置对象的name为"旺财";
调用show_name显示对象的name;
class dog:
def set_name(self, name):
self.name = name
def show_name(self):
print(self.name)
d = dog()
d.set_name("旺财")
d.show_name()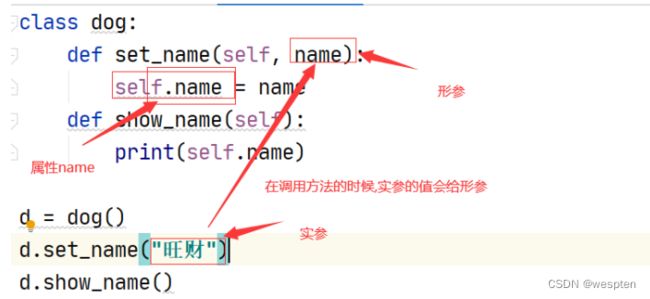
6. __init__方法
1)__init__初始化方法
__init__就是对象的初始化方法,__init__是对象的内置方法,用来完善对象的,在对象生成之后调用。
当使用 类名() 创建对象时,会自动执行以下操作:
- 为对象在内存中分配空间 —— 创建对象;
- 当创建对象的时候,也就是实例化对象的时候,init自动调用;
2)cat类增加__init__方法
# 定义 cat 类
class cat:
# 初始化方法
def __init__(self):
print("初始化方法")
def eat(self):
print("小猫爱吃鱼")
def drink(self):
print("小猫爱喝水")
# 创建对象的同时,初始化方法被自动调用
lazy_cat = cat()3)在初始化方法内部为类添加属性
# 定义 cat 类
class cat:
# 初始化方法
def __init__(self):
self.name = "猫"
print("%s 的初始化方法" % self.name)
def eat(self):
print("%s 爱吃鱼" % self.name)
def drink(self):
print("%s 爱喝水" % self.name)
# 创建对象的同时,初始化方法被自动调用
lazy_cat = cat()4)带有参数的初始化方法
init方法一旦有形参,对象实例化的时候就必须提供实参 。
# 定义 cat 类
class cat:
# 带有参数初始化方法
def __init__(self, name):
self.name = name
print("%s 的带有参数的初始化方法" % self.name)
def eat(self):
print("%s 爱吃鱼" % self.name)
def drink(self):
print("%s 爱喝水" % self.name)
lazy_cat = cat("tom")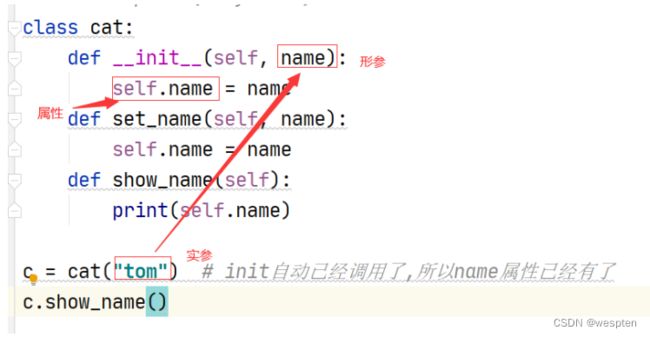
5)初始化方法的缺省参数
为了避免实例化的时候必须提供实参,init的形参总是有缺省值。
# 定义 cat 类
class cat:
# 带有缺省参数初始化方法
def __init__(self, name = "猫"):
self.name = name
print("%s 的带有参数的初始化方法" % self.name)
def eat(self):
print("%s 爱吃鱼" % self.name)
def drink(self):
print("%s 爱喝水" % self.name)
# 没有指定 name 的值,此时 name 等于缺省值
lazy_cat = cat()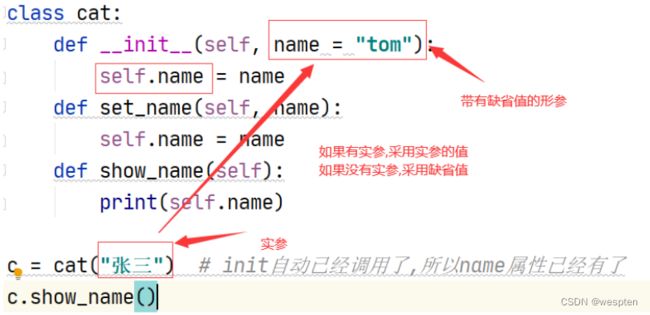
car类 的设计:
# 汽车car 要区分属性和方法,在init方法中为每个属性定义默认值
# 属性
# luntai(轮胎)
# yanse(颜色)
# chuanghu(窗户)
# xinghao(型号)
# 方法
# guadang(挂挡)
# qianjin(前进)
# houtui(后退)
# wurenjiashi(无人驾驶)
# shache(刹车)
# jiayou(加油)
class car:
def __init__(self, luntai="轮胎", yanse="白色", chuanghu="黑窗户",xinghao="大众"):
self.luntai = luntai
self.yanse = yanse
self.chuanghu = chuanghu
self.xinghao = xinghao
def guadang(self, a = "前进"):
self.jiayou()
if a == "前进":
self.qianjin()
elif a == "后退":
self.houtui()
else:
print("档不对")
def qianjin(self):
print("%s在前进" % self.xinghao)
def houtui(self):
print("%s在后退" % self.xinghao)
def wurenjiashi(self):
print("无人驾驶")
def shache(self):
print("刹车")
def jiayou(self):
print("加油")
c = car()
# c.qianjin()
c.guadang("前进")
c1 = car(xinghao="奔驰")
c1.guadang("后退")7. __new__方法
__new__是用来控制对象的生成过程的,在对象生成之间调用,如果__new__方法不返回对象,则不会调用 __init__。
class User:
def __new__(cls, *args, **kwargs):
print("in new")
return super().__new__(cls)
def __init__(self, name):
print("in init")
self.name = name
8. __del__方法
__del_方式只能有一个参数self;
当对象在内存中被销毁的时候,__del_方法被系统自动调用;
当使用 类名()创建对象时,为对象分配完空间后,自动调用__init__方法;
当一个对象被从内存中销毁前,会自动调用__del_方法 ;
一个对象的__del__方法一旦被调用,对象的生命周期结束;
# 定义 cat 类
class cat:
def __init__(self, name = "猫"):
self.name = name
print("%s 的带有参数的初始化方法" % self.name)
def __del__(self):
print("%s 被销毁了" % self.name)
def eat(self):
print("%s 爱吃鱼" % self.name)
def drink(self):
print("%s 爱喝水" % self.name)
lazy_cat = cat()在函数内定义的局部变量,函数执行完毕,自动调用对象的del方法,变量就被销毁了。
在函数外部定义的全局变量,程序执行完毕,自动调用对象的del方法,变量就被销毁了。
class cat:
def __init__(self, name = "tom"):
self.name = name
def show_name(self):
print(self.name)
def __del__(self):
print("%s销毁了" % self.name)
def my_test1():
c1 = cat("小猫")
c1.show_name()
my_test1() # 程序的第一条执行语句
c = cat() # c是个对象,同时也是一个变量
c.show_name() # 这里显示了tom__init__不要写成__int__。
__del__对象在内存中销毁的时候自动调用del:
- 不要理解成调用del是把对象从内存中删除了;
- 对象即使没有del,同样会被销毁;
- 当对象从内存中销毁的时候,有机会能执行一些代码;
设计方法的惯例:
class cat:
def __init__(self, name = "tom"):
self.name = name
# 不想写show_name方法, 只是想把name返回给调用者
def get_name(self): # 设计方法管理,得到属性值get_属性名
return self.name
def set_name(self, name): # set_属性名(self, 形参)
self.name = name
def show_name(self): # 在方法中显示属性的值一般show_属性名
print(self.name)
c = cat()
print(c.get_name())
print(c.show_name()) # 没有return语句的方法或者函数,不要放到print
c1 = cat("小猫")
c1.set_name("加菲猫")
print(c1.get_name())可以通过del关键字,显式的销毁一个变量。
案例一:调用 del 函数在程序完成前把对象销毁。
# 定义 cat 类
class cat:
def __init__(self, name = "猫"):
self.name = name
print("%s 的带有参数的初始化方法" % self.name)
def __del__(self):
print("%s 被销毁了" % self.name)
def eat(self):
print("%s 爱吃鱼" % self.name)
def drink(self):
print("%s 爱喝水" % self.name)
lazy_cat = cat()
del lazy_cat
print("程序终止")案例二:函数执行完成,对象销毁。
# 定义 cat 类
class cat:
def __init__(self, name = "猫"):
self.name = name
print("%s 的带有参数的初始化方法" % self.name)
def __del__(self):
print("%s 被销毁了" % self.name)
def eat(self):
print("%s 爱吃鱼" % self.name)
def drink(self):
print("%s 爱喝水" % self.name)
def test_cat():
lazy_cat = cat()
test_cat()
print("程序终止")案例三:设计小狗类。
# 有一个dog类,有属性name和age
# 提供设置,得到,显示name和age属性的方法
class dog:
def __init__(self, name = '二哈', age = 2):
self.name = name
self.age = age
def set_name(self, name):
self.name = name
def get_name(self):
return self.name
def show_name(self):
print(self.name)
def set_age(self, age):
self.age = age
def get_age(self):
return self.age
def show_age(self):
print(self.age)
d = dog("比熊", 3) # 实例化的时候设置属性的值
print(d.get_name())
d.set_name("黑背") # 实例化以后再设置属性值
print(d.get_name())
d.show_name()9. __str__ 方法
在 Python 中,使用 print 输出 对象变量,默认情况下,会输出这个变量。
引用的对象是由哪一个类创建的对象,以及在内存中的地址(十六进制表示)。
# 定义 cat 类
class cat:
def __init__(self, name = "猫"):
self.name = name
print("%s 的带有参数的初始化方法" % self.name)
def __del__(self):
print("%s 被销毁了" % self.name)
def eat(self):
print("%s 爱吃鱼" % self.name)
def drink(self):
print("%s 爱喝水" % self.name)
lazy_cat = cat()
print(lazy_cat)如果在开发中,希望使用 print 输出对象变量时,能够打印自定义的内容,就可以利用__str__这个内置方法了。
注意:
__str__方法必须返回一个字符串。
# 定义 cat 类
class cat:
def __init__(self, name = "猫"):
self.name = name
print("%s 的带有参数的初始化方法" % self.name)
def __del__(self):
print("%s 被销毁了" % self.name)
def __str__(self):
return "我是一只%s" % self.name
def eat(self):
print("%s 爱吃鱼" % self.name)
def drink(self):
print("%s 爱喝水" % self.name)
lazy_cat = cat('aaaa')
# 这个时候 print 将显示__str__函数返回的字符串
print(lazy_cat)__str__只有self,没有其他参数,必须有return return必须返回一个字符串。
str方法的作用:
当把一个带有str方法的对象放到print里面,print函数会显示str方法return返回的字符串。
如果类没有str方法,那么类实例化的对象放到print里面显示的是对象的内存地址。
创建小狗类的对象,调用 print(小狗类对象),显示如下字符:"这是一个小狗类对象”。
class dog:
def __str__(self):
return "这是一个小狗类对象"
d = dog()
print(d)10. 面向对象编程案例
Python为OOP提供了完整的支持,下面给出了一个示例,也许可以成为一个初级的简单图形绘制模块,为某个绘图程序服务。
如果对OOP比较熟悉,此例程仅供参考。
对于OOP的标准特性,Python的语法和语义,与其他编程语言是类似的。
"""sh module. Contains classes Shape, Square and Circle"""
class Shape: ⇽--- ❶
"""Shape class: has method move"""
def __init__(self, x, y): ⇽--- ❷
self.x = x ❸
self.y = y
def move(self, deltaX, deltaY): ⇽--- ❹
self.x = self.x + deltaX
self.y = self.y + deltaY
class Square(Shape):
"""Square Class:inherits from Shape"""
def __init__(self, side=1, x=0, y=0):
Shape.__init__(self, x, y)
self.side = side
class Circle(Shape): ⇽--- ❺
"""Circle Class: inherits from Shape and has method area"""
pi = 3.14159 ⇽--- ❻
def __init__(self, r=1, x=0, y=0):
Shape.__init__(self, x, y) ⇽--- ❼
self.radius = r
def area(self):
"""Circle area method: returns the area of the circle."""
return self.radius * self.radius * self.pi
def __str__(self): ⇽--- ❽
return "Circle of radius %s at coordinates (%d, %d)"\
% (self.radius, self.x, self.y)类的实例初始化方法(构造函数)叫作__init__❷,实例变量x和y就是在这里创建和初始化的❸。方法和函数一样,由def关键字定义❹。所有方法的第一个参数习惯上叫作self。当方法被调用(invoke)时,self会被置为调用该方法的实例。
类Circle是从类Shape继承而来的❺,类似于一个标准的类变量❻,但又不完全相同。类必须显式调用其基类的初始化函数(initializer),这是在其初始化函数中完成的❼。__str__方法将会由print函数调用❽。类还有一些其他的特殊方法属性,用于支持操作符重载,或供len()函数之类的内置方法调用。
导入以下文件,以便启用上述类:
>>> import sh
>>> c1 = sh.Circle() ⇽--- ❶
>>> c2 = sh.Circle(5, 15, 20)
>>> print(c1)
Circle of radius 1 at coordinates (0, 0)
>>> print(c2) ⇽--- ❷
Circle of radius 5 at coordinates (15, 20)
>>> c2.area()
78.539749999999998
>>> c2.move(5, 6) ⇽--- ❸
>>> print(c2)
Circle of radius 5 at coordinates (20, 26)这里创建了一个Circle类的实例❶,初始化函数是会被隐式调用的。print函数会隐式调用特殊方法__str__❷。在这里Circle可以直接调用父类Shape的move方法❸。方法调用的语法,就是在对象实例上使用属性语法object.method()。第一个参数(self)会自动隐式赋值。
计算器:
class calc:
def __init__(self, oper = "+"):
self.oper = oper
def calc(self, a, b):
if self.oper == "+":
return a + b
elif self.oper == "-":
return a - b
elif self.oper == "*":
return a * b
elif self.oper == "/":
if b != 0:
return a / b
else:
return None
else:
return None
c = calc()
print(c.calc(3, 4))
d = calc("*")
print(d.calc(3, 4))
e = calc("/")
print(e.calc(3, 0))
f = calc("sdfsd")
print(f.calc(4, 5))9、面向对象进阶
1. 实例属性和类属性
class Teacher:
age = 20
def __init__(self,name,age,subject):
self.name = name
self.age = age
self.subject = subject
t = Teacher('Dzreal', 25, 'PE')
print(t.age) #25
del t.age # 删除实例属性后,自动调用类属性
print(t.age) #20
注意:
- 实例属性的优先级高于类属性;
- 类没有实例属性时会调用类属性;
2. 访问限定
伪私有属性 _attrname : 可以访问,但不要随意访问。
私有属性 __attrname:一般不可访问,强行访问的话,可以通过实例._类名__attrname 来访问。
class Teacher:
def __init__(self, name, age, subject):
self.__name = name
self.age = age
self._subject = subject
def get_fake_private(self):
print(self._subject)
def get_private(self):
print(self.__name)
t = Teacher('Dzreal',25,'PE')
# 通过实例方法访问私有属性
t.get_fake_private() # PE
t.get_private() # Dzreal
# 直接访问私有属性
print(t._subject) # PE
print(t._Teacher__name) # Dzreal
print(t.__name) # 报错 AttributeError: 'Teacher' object has no attrib3. 定制属性访问
hasattr(m,'n') m:实例 n:类里面的属性确定属性是否存在。
getattr(m,'n') m:实例 n:类里面的属性得到指定类属性的值。
setattr(m,'n',x) m:实例 n:类里面的属性x:设置属性的值有则改无则添加。
delattr(m,'n') m:实例 n:类里面的属性删除一个类属性。
4. 面向对象程序设计三大特性
- 封装------根据职责将属性和⽅法封装到⼀个抽象的类中 ;
- 继承------实现代码的重⽤,相同的代码不需要重复的编写 ;
- 多态------不同的对象调⽤相同的⽅法,产⽣不同的执⾏结果,增加代码的灵活度;
5. 封装
就是把类的属性和方法封装到类的内部,只能在内部使用,不能在类的外部使用。
把属性和方法名前面加两个下划线__,这个属性和方法就成为了类的私有属性和方法。
类的私有属性和私有方法:
- 私有属性就是对象不希望公开的属性;
- 私有方法就是对象不希望公开的方法;
在定义属性或方法时,在属性名或者方法名前 增加两个下划线,定义的就是私有属性或方法。
对于私有属性和私有方法,只能在类的内部访问,类的外部无法访问。
class woman:
def __init__(self, weight = 0, age = 0, name = ""):
# __weight 为私有属性
self.__weight = weight
# __age 为私有属性
self.__age = age
self.name = name
# __secret 为私有方法
def __secret(self):
print("我的体重是%d, 年龄是%d" % (self.__weight,self.__age))
def show_secret(self):
self.__secret()
w = woman()
print(w.name)
# print(w.__weight) 不能在类的外部访问类的私有属性
# w.__secret() 不能在类的外部调用私有方法设计一个类user,属性和方法如下:
- 属性:name:姓名;
- 方法:show_name(self);
- 私有属性:_passwd:密码;
- 私有方法:def_show_passwd(self);
class user:
def __init__(self):
self.name = "tom"
self.__passwd = "123456"
def show_name(self):
print(self.name)
def __show_passwd(self):
print(self.__passwd)
u = user()
u.show_name()
# u.__show_passwd() 类的外部不能访问类的私有属性和方法6. 继承
继承的概念:子类拥有父类的所有方法和属性。
继承的语法:
class 类名(父类名):
pass子类继承自父类,可以直接享受父类中已经封装好的方法,不需要再次开发。
子类中应该根据职责,封装子类特有的属性和方法。
class animal:
def sleep(self):
print("睡")
def eat(self):
print("吃")
class dog(animal):
def run(self):
print("跑")dog 类是 animal 类的子类, animal类是 dog 类的父类, dog 类从 animal 类继承。
dog 类是 animal 类的派生类, animal 类是 dog 类的基类, dog 类从animal 类派生。
类A继承自类B,类A会拥有类B的所有属性和方法:
class animal:
def sleep(self):
print("睡")
def eat(self):
print("吃")
class dog(animal): # 类dog继承自animal类
def run(self):
print("跑")
d = dog() # dog会拥有animal所有属性和方法
d.sleep()
d.eat()
d.run()子类--派生类:
- dog是animal的子类;
- dog是animal的派生类;
父类--基类:
- animal是dog的父类;
- animal是dog基类;
继承--派生:
- dog类继承自animal;
- dog类派生自animal;
一个父类可以有多个子类继承,每个子类可以有自己特有的方法和属性。
class animal:
def sleep(self):
print("睡")
def eat(self):
print("吃")
class dog(animal):
def run(self):
print("跑")
class fish(animal):
def swimming(self):
print("游泳")
class bird(animal):
def fly(self):
print("飞")针对animal类,dog、fish和bird类是说明。
C 类从 B 类继承,B类又从 A 类继承,那么 C 类就具有 B 类和 A 类的所有属性和方法。
子类拥有父类以及父类的父类 中封装的所有属性和方法。
class animal:
def sleep(self):
print("睡")
def eat(self):
print("吃")
class dog(animal):
def run(self):
print("跑")
class erha(dog):
def kawayi(self):
print("萌")
e = erha()
e.sleep()
e.eat()
e.run()
e.kawayi()
多级继承案例:
class animal:
def sleep(self):
print("睡")
def eat(self):
print("吃")
class dog(animal):
def run(self):
print("跑")
class fish(animal):
def swimming(self):
print("游泳")
class erha(dog):
def kawayi(self):
print("萌")
class cangao(dog):
def yaoren(self):
print("咬人")
class shark(fish):
def chiren(self):
print("吃人")
s = shark()
s.sleep()
s.eat()
s.swimming()
s.chiren()
c = cangao()
c.sleep()
c.eat()
c.run()
c.yaoren()
继承顺序:
# 案例一、普通多继承
class A:
def foo(self):
print(A)
class B:
def foo(self):
print(B)
class C(A):
pass
class D(B):
pass
# 继承顺序似乎和C、D的顺序有关,要是改成 class E(D,C),继承顺序又会不一样
class E(C, D):
pass
e = E()
e.foo()
#A
# mro()或 __mro__可以查看继承顺序print(E.mro())
# 即继承顺序是:E->C->A->D->B
# 案例二、菱形结构继承
class A:
pass
class B(A):
pass
class C(A):
pass
class D(C,B):
pass
print(D.mro())
# 即继承顺序是:D->C->B->A
# 说明python的继承不完全是深度优先算法实现,而是采用 C3算法+DFS算法(深度优先)
7. 方法的重写
当父类的方法实现不能满足子类需求时,可以对方法进行重写(override)。
重写父类方法有两种情况:
- 覆盖父类的方法;
- 对父类方法进行扩展。
1)覆盖父类的方法
如果在开发中,父类的方法实现和子类的方法实现,完全不同,就可以使用覆盖的方式,在子类中重新编写父类的方法实现。
具体的实现方式,就相当于在子类中定义了一个 和父类同名的方法并且实现。
重写之后,在运行时,只会调用子类中重写的方法,而不再会调用父类封装的方法。
class animal:
def sleep(self):
print("睡")
def eat(self):
print("吃")
class dog(animal):
def eat(self): # 出现和父类同名方法,在子类dog中,就没有父类的eat方法了
print("吃肉")
d = dog()
d.sleep()
d.eat() # 由于覆盖了父类的eat方法,,所以这里调用的是dog类的eat方法2)扩展父类方法
如果父类的方法不能完全满足子类需求,子类可以在父类方法基础上增加功能。
语法:
- 在子类中实现和父类同名方法;
- 在子类的同名方法中用super().父类同名方法,来调用父类的方法;
class animal:
def sleep(self):
print("睡")
def eat(self):
print("吃")
class dog(animal):
def sleep(self):
super().sleep() # 在子类方法中调用父类的sleep方法
print("睡得更多")
d = dog()
d.sleep() # 扩展了父类的sleep,所以既执行了父类的sleep,又增加了功能3)父类的私有属性和私有方法
1.子类对象不能在自己的方法内部,直接访问父类的私有属性或私有方法;
2.子类对象 可以通过父类的公有方法间接访问到私有属性或私有方法;
私有属性、方法是对象的隐私,不对外公开,外界以及子类都不能直接访问。
私有属性、方法通常用于做一些内部的事情。
class animal:
def sleep(self):
print("睡")
def __eat(self): # 私有成员不会被子类继承
print("吃")
class dog(animal): # 在dog类里面,没有__eat方法
pass
d = dog()
d.sleep()
# d.__eat() # 这里的代码会出错father类和继承:
class father:
def __init__(self):
self.__name = "张三"
self.house = "别墅"
def eat(self):
print("吃")
def sleep(self):
print("睡")
def __edu_back(self):
print("本科")
class son(father): # son拥有father所有的方法和属性
def show_eat(self):
self.eat() # eat是继承自father的,但也是son自己的
def show_sleep(self):
self.sleep()
def show_house(self):
print(self.house) # house是一个属性,不能调用,要用print
s = son()
s.show_eat()
s.show_sleep()
s.show_house()
# father有两个属性,三个方法
# son继承了father一个属性,两个方法8. object类
在 Python 3中定义类时,如果没有指定父类,会默认使用 object 作为该类的基类 ——Python 3中定义的类都是新式类。
在 Python 2中定义类时,如果没有指定父类,则不会以 object 作为基类。
新式类和经典类在多继承时 ——会影响到方法的搜索顺序。
为了保证编写的代码能够同时在 Python 2和 Python3运行!今后在定义类时,如果没有父类,建议统一继承自object。
class 类名(object):
passclass animal(object):
def sleep(self):
print("睡")
def eat(self):
print("吃")
class dog(animal):
def run(self):
print("跑")class animal: # 如果定义了一个类,没明确的写父类,那么父类就是object
def sleep(self):
print("睡")
# class animal(object):
# def sleep(self):
# print("睡")
a = animal()9. 多态
不同的子类对象调用相同的父类方法,产生不同的执行结果。
多态的前提,不同的子类来自相同的一个父类,子类会覆盖父类的方法。
class animal:
def food(self):
pass
def eat(self):
self.food()
class dog(animal):
def food(self):
print("吃肉")
class cattle(animal):
def food(self):
print("吃草")
d = dog()
d.eat()
c = cattle()
c.eat()
注意:
- super().__init__()不是调用父类的构造函数,而是调用mro下一个类的构造函数;
- 假如父类方法foo被子类重写,super().foo()可以调用父类方法;
- 假如父类方法foo没有被子类重写,self.foo()可以调用父类方法;
10. 类属性和类方法
不需要创建类的对象,通过 类名. 的方式就可以访问类的属性或者调用类的方法。
1)类属性
class dog:
name = "二哈" # 如果在这个位置定义的变量,就是类属性
def __init__(self):
pass
print(dog.name) # 显示类属性的值
dog.name = "狼狗" # 修改类属性的值
print(dog.name)2)类方法
- 类方法不需要把类实例化为对象,通过类名.类方法名调用;
- 用@classmethod来修饰的方法,就是类方法;
- 类方法的一个参数是cls(不是self);
- 在类方法内部如果使用类属性,cls.类属性名, cls.类方法 来访问同一个类中其他类方法;
- 类方法内部不能使用普通属性,也不能调用普通方法,因为类方法不需要对象的,但普通方法和普通属性一定需要通过对象调用;
- 类方法不需要实例化就可以调用,类方法只能访问同一个类中的类属性和类方法;
class dog:
name = "二哈" # 如果在这个位置定义的变量,就是类属性
@classmethod
def set_name(cls, name):
cls.name = name # 通过类方法的形参修改类属性name值
def __init__(self):
self.age = 20 # 在类方法里面无法访问age
def demo(self): # 在类方法中无法调用demo
print("普通方法")
print(dog.name) # 显示类属性的值
dog.name = "狼狗" # 修改类属性的值
print(dog.name)
dog.set_name("比熊")
print(dog.name)类属性和类方法案例:
class dog:
name = "小白"
@classmethod
def get_name(cls):
return cls.name
def __init__(self):
self.age = 0
def get_age(self):
return self.age
# 要把类属性name的值修改为"小小白"
dog.name = "小小白"
# 调用类方法get_name,显示name的值
print(dog.get_name())
# 要把普通属性age的值修改为10
d = dog()
d.age = 10
# 调用普通方法get_age显示age的值
print(d.get_age())3)普通方法访问类属性或者类方法
在普通方法中通过 类名.类属性 或者 类名.类方法 来访问类属性和类方法。
class dog:
name = "小白"
@classmethod
def get_name(cls):
return cls.name
def demo(self): # 演示如何在普通方法中使用类属性和类方法
dog.name = "小小白"
print(dog.get_name())
d = dog()
d.demo()class dog:
index = 0 # 定义了一个类属性
@classmethod
def count(cls): # 返回值为类属性index
return cls.index
def __init__(self): # 实例化的时候自动调用init
dog.index += 1 # 每次实例化的时候类属性index + 1
d1 = dog()
d2 = dog()
d3 = dog()
d4 = dog()
print(dog.count())11. 静态方法
如果需要在类中封装一个方法,这个方法既不需要访问实例属性 或者调用实例方法也不需要访问类属性或者调用类方法,这个时候,可以把这个方法封装成一个静态方法。
- 用@staticmethod修饰的方法为静态方法;
- 静态方法是独立存在的,不能访问类或者实例的任何属性和方法;
- 静态方法不需要实例化为对象,通过类名.静态方法名 调用;
- 静态方法不能访问类中的其他成员,静态方法就是一个独立与类存在的函数;
通过 类名.静态方法 调用静态方法。
语法如下:
@staticmethod
def 静态方法名():
passclass dog:
@staticmethod
def help():
print("这是一个静态方法")
dog.help()静态方式使用场景:
- 当代码量特别大的时候函数也会特别多,为了避免函数的重名,可以把同名函数放到不同的类里面,做为静态方法;
- 避免由于函数重名带来错误;
class dog:
@staticmethod
def help():
print("这是一个静态方法")
class A:
@staticmethod
def help():
print("这是第二个静态方法help")
dog.help()
A.help()12. 鸭子类型
python的内置协议(魔法函数)就是一个很典型的鸭子类型的例子:
如果一个对象实现了__getitem__方法,那python的解释器就会把它当做一个collection,就可以在这个对象上使用切片,获取子项等方法。
如果一个对象实现了__iter__和 next 方法,python就会认为它是一个iterator,就可以在这个对象上通过循环来获取各个子项。
# 鸭子类型案例:
# 下面的例子,之所以能实现鸭子类型,是因为python的变量可以指向任意类型。
class Pig:
def say(self):
print("i am a pig")
class Dog:
def say(self):
print("i am a dog")
class Duck:
def say(self):
print("i am a duck")
animal_list = [Pig, Dog, Duck]
for animal in animal_list:
animal().say()
#【输出】:
# i am a pig
# i am a dog
# i am a duck
13. 魔法函数
python的魔法函数定义之后,不要去调用它,python解释器自己会去调用,定义魔法函数的作用是在于利用python的鸭子类型的特性,给类添加一些特性。
1)字符串表示
__repr__:在命令行交互模式下会用到,某个类中重写了__repr__方法,就不用调用 print 函数,只需要输入类名,在控制台下就会调用__repr__,输出__repr__定义的内容。
__str__:调用print(类名),实际上会调用类的__str_方法。
2)集合、序列相关
__len__:获取元素个数
--getitem__
--setitem__
__delitem__
--contains__
3)迭代相关
__iter__
__next__
4)可调用
__call__
5)with上下文管理器
__enter__:开始的时候调用
__exit__:结束的时候调用
6)数值转换
__abs__
__bool__
__int__
__float__
__hash__
__index__
7)元类相关
__Mau__
__init__
8)属性相关
__getattr__、__setattr__
__getattribute__
__setattribute__
__dir__
9)属性描述符
__get__
__set__
__delete__
10)协程
__await__
__aiter__
__anext__
__aenter__
__aexit__
10、模块与包
1. 模块的概念
当项目代码越来越多,不可能把所有代码都放到一个py文件中。
一个项目往往由多个py文件组成,所以说一个项目是多个模块组成。
模块是 Python 程序架构的一个核心概念,每一个以扩展名 py 结尾的 Python 源代码文件都是一个模块。
模块名同样也是一个标识符,需要符合标识符的命名规则,一般习惯模块名用小写字母,如果有多个单词,单词之间用下划线分隔。
在模块中定义的全局变量、函数、类 都是提供给外界直接使用的工具。
模块就好比是工具包,要想使用这个工具包中的工具,就需要先导入这个模块。
2. 创建模块
创建自己的模块十分容易,导入和使用与Python的内置库模块没有区别。
下面代码给出了包含了一个函数的简单模块,函数的用途是提示用户输入文件名并统计该文件中单词出现的次数。
"""wo module. Contains function: words_occur()""" ⇽--- ❶
# 接口函数 ⇽--- ❷
def words_occur():
"""words_occur() - count the occurrences of words in a file."""
# 提示用户输入文件名称
file_name = input("Enter the name of the file: ")
# 打开文件,读取单词并保存在列表中
f = open(file_name, 'r')
word_list = f.read().split() ⇽--- ❸
f.close()
# 对文件中的每个单词出现的次数进行计数
occurs_dict = {}
for word in word_list:
# 对该单词次数加1
occurs_dict[word] = occurs_dict.get(word, 0) + 1
# 打印结果
print("File %s has %d words (%d are unique)" \ ⇽--- ❹
% (file_name, len(word_list), len(occurs_dict)))
print(occurs_dict)
if __name__ == '__main__': ⇽--- ❺
words_occur()文档字符串(即docstring)是对模块、函数、方法和类给出文档说明的标准方式❶。而注释则以#字符开头❷。read函数将返回一个字符串,其中包含了文件中的所有字符❸。字符串类的split方法将返回一个字符串列表,列表的成员是将该字符串内容按空白符分隔开的各个单词。“\”符用于将长语句拆分为多行❹。这里的if语句❺使得本段程序可以以脚本的方式运行,只要在命令行中输入python wo.py即可。
如果代码文件存放的目录被包含在模块搜索路径中(由sys.path给出),就可以像内置库模块一样用import语句导入该文件:
>>> import wo
>>> wo.words_occur() ⇽--- 以上函数的用法和库模块函数完全相同,只是采用对象属性的调用语法❶。
注意,在同一个交互式会话当中,如果磁盘文件wo.py中途做过改动,import是不会自动加载改动内容的。这时可以利用imp库中的reload函数来重新加载:
>>> import imp
>>> imp.reload(wo)
为了适应较大型的项目,Python支持一种叫包(package)的概念,也就是多个模块的汇总。利用“包”很容易就能把模块以目录或目录子树的形式分组存放,然后通过package.subpackage.module的语法导入并按层次引用。
只要为每个包或子包创建一个初始化文件即可,这个初始化文件的内容可以为空。
3. 模块的导入方式
1)import 导入
语法:
import 模块名
模块名.函数新建一个文件 module1.py,文件内容如下:
# module1.py
# my_max 函数,计算参数最大值
def my_max(*a):
return max(a)
# my_sum 函数,参数求和
def my_sum(*a):
sum = 0
for n in a:
sum += n
return sum新建一个文件 module2.py,文件内容如下:
# module2.py
# 导入 module1 模块
import module1
# 调用 module1 中的 my_max 函数
print(module1.my_max(4,6,2))2)as 指定模块别名
语法:
import 模块名 as 别名
别名.函数名注意:
- 如果两个模块,存在同名的函数,那么后导入模块的函数,会覆盖掉先导入的函数;
- 开发时 import 代码应该统一写在代码的顶部,更容易及时发现冲突;
- 一旦发现冲突,可以使用 as 关键字 给其中一个工具起一个别名;
module2.py,文件内容更改如下:
# module2.py
# 导入 module1 模块
import module1 as m
# 通过别名 m 调用 module1 中的 my_max 函数
print(m.my_max(4,6,2))3)from...import导入
import 模块名 是一次性把模块中所有内容全部导入。
如果希望从某一个模块中导入部分内容,就可以使用 from...import 的方式。
语法一:
from 模块名 import 函数名
调用函数的时候,不需要前面在接模块名.,直接写函数名调用即可语法二:
from 模块名 import *
导入所有内容,使用内容的时候,不需要写模块名导入之后不需要通过 模块名.可以直接使用模块提供的工具 —— 全局变量、函数、类。
module2.py,文件内容更改如下:
# module2.py
# 导入 module1 模块
from module1 import my_max, my_sum
# 调用 module1 中的 my_max 函数
print(my_max(4,6,2))
# 调用 module1 中的 my_sum 函数
print(my_sum(4,6,2))或者使用 import *:
# module2.py
# 导入 module1 模块
from module1 import *
# 调用 module1 中的 my_max 函数
print(my_max(4,6,2))
# 调用 module1 中的 my_sum 函数
print(my_sum(4,6,2))4. __name__ 属性
每一个py文件都有一个属性_name_。
如果这个py文件是正在执行的模块,那么name属性的值为__main__。
如果这个py文件是被其他py文件import导入调用的,那么name属性的值就是这个py文件的模块名
def my_test():
print(__name__)
# my_test() 当前如果执行的就是module4这个模块,那么属性__name__的值为"__main__"import module4
module4.my_test() # 调用module4中的my_test函数
# 这里的my_test会输出module45. 包
包就是一个包含多个模块的特殊目录。
一个目录下需要有__init__.py文件,使用包的目的是一次性可以把一个目录下所有的模块通过一条import语句导入。
第一步:在项目里建立一个目录 my_pack。
第二步:在my_pack目录里创建两个py文件,a1.py和a2.py,内容如下。
a1.py:
def my_max(a, b):
if a > b:
return a
else:
return ba2.py:
def my_sum(a, b):
return a + b第三步,在my_pack目录下创建__init__.py文件。
__init__.py:
from . import a1
from . import a2第四步:在my_pack的上级目录建立一个module6.py文件,建立这个文件的目的是要使用、my_pack 包。
module6.py:
# module6要使用包my_back
import my_pack
print(my_pack.a1.my_max(3, 5))
print(my_pack.a2.my_sum(3, 5))使用包中的函数:
import 包名
包名.模块名.函数名使用包注意的点:
- 不管目录下有多少模块;
- 只有在_init_.py文件中通过import导入模块才能使用;
- __init__.py里面的from后面是个相对路径;
6. 导入包中指定函数
语法:
from 包.模块 import 函数
直接写函数名调用函数即可from my_pack.a1 import my_max
from my_pack.a2 import my_sum
print(my_max(4, 6))
print(my_sum(4, 6))7. 包与模块导入案例
新建一个 py 文件, 通过 import my_pack1 导入m1.py 和 m2.py,并且调用m1_func、m1_test和m2_func函数。
my_pack1/m1.py:
def m1_func():
print("我是m1的func函数")
def m1_test():
print("我是m1的test函数")my_pack1/m2.py:
def m2_func():
print("我是m2的func函数")
my_pack1/__init__.py:
from . import m1
from . import m2module8.py:
# import my_pack1
# my_pack1.m1.m1_func()
# my_pack1.m1.m1_test()
# my_pack1.m2.m2_func()
from my_pack1.m1 import m1_test
from my_pack1.m1 import m1_func
from my_pack1.m2 import m2_func
m1_test()
m1_func()
m2_func()11、异常
1. 认识错误(BUG)
编写的程序不能正常执行,或者执行的结果不是我们期望的俗称 BUG,是程序员在开发时非常常见的,初学者常见错误的原因包括:
- 手误;
- 对已经学习过的知识理解还存在不足;
- 对语言还有需要学习和提升的内容;
在学习语言时,不仅要学会语言的语法,而且还要学会如何认识错误和解决错误的方法。
每一个程序员都是在不断地修改错误中成长的。
常见错误:
1> 手误,例如使用 pirnt("Hello world")
NameError: name 'pirnt' is not defined
名称错误:'pirnt' 名字没有定义2> 将多条 print 写在一行。
SyntaxError: invalid syntax
语法错误:语法无效每行代码负责完成一个动作。3> 缩进错误
IndentationError: unexpected indent
缩进错误:不期望出现的缩进Python 是一个格式非常严格的程序设计语言。
目前而言,大家记住每行代码前面都不要增加空格。
2. 捕获异常
程序在运行时,如果遇到到一个错误,会停止程序的执行,并且提示一些错误信息,这就是异常。
程序停止执行并且提示错误信息这个动作,称之为:抛出(raise)异常。
程序开发时,很难将所有的特殊情况都处理的面面俱到,通过异常捕获可以针对突发事件做集中的处理,从而保证程序的稳定性和健壮性。
1)简单的捕获异常语法
在程序开发中,如果对某些代码的执行不能确定是否正确,可以增加 try(尝试) 来捕获异常。
语法格式:
try:
可能出现异常的代码
except:
出现异常的处理代码如果try下面的代码没出现异常,那么except下面的代码不会执行,只有try下面的代码出现异常,except下面的代码才会执行。
一旦异常被try捕捉,那么程序就不会报错终止了。
要求用户输入整数:
try:
a = int(input("请输入一个整数"))
except:
print("输入不正确")
2)捕捉不同类型异常
语法:
try:
可能出异常的代码
except 异常类型1:
出现异常类型执行的代码
except 异常类型2:
出现异常类型执行的代码
except (错误类型 1,错误类型 2):
出现异常的处理代码
except:
出现未知异常执行的代码异常案例:
try:
a = int(input("请输入一个整数"))
b = int(input("请输入一个整数"))
print(a / b)
except ValueError:
print("请输入一个可以转化整数")
except ZeroDivisionError:
print("除数不能为0")
except:
print("未知错误")
# ValueError: 输入的值不能转化为整数
# ZeroDivisionError: 除数为0的时候报的错误计算器案例:
try:
num1 = int(input("请输入num1的值"))
num2 = int(input("请输入num2的值"))
op1 = input("请输入op1的值")
if op1 == "+":
print(num1 + num2)
elif op1 == "-":
print(num1 - num2)
elif op1 == "*":
print(num1 * num2)
elif op1 == "/":
print(num1 / num2)
else:
print("op1值不对")
except ValueError:
print("请输入一个可以转化整数")
except ZeroDivisionError:
print("除数不能为0")
except:
print("未知错误")3. 没有异常发生执行的代码
try:
可能出现异常的代码
except:
发生异常要处理的代码
else:
没有异常发生要执行的代码案例:
try:
a = int(input("请输入a的值"))
b = int(input("请输入b的值"))
print(a / b)
except:
print("异常发生")
else:
print("没有异常发生")4. 捕获未知异常
try:
a = int(input("请输入a的值"))
b = int(input("请输入b的值"))
print(a / b)
except Exception as result: # 捕捉未知异常,把未知异常系统的错误提示显示出来
print(result)5. 无论是否异常都要执行的代码
try:
可能出现异常的代码
except:
出现异常要处理的代码
finally:
无论是否异常都要执行的代码try:
a = int(input("请输入a的值"))
b = int(input("请输入b的值"))
print(a / b)
except:
print("异常发生")
finally:
print("不论是否有异常都要执行的代码")6. 异常完整语法
try:
可能出现异常的代码
except 指定异常类型1:
异常执行代码
except 指定异常类型2:
异常执行代码
except Exception as result:
异常执行代码
else:
没有异常执行代码
finally:
无论是否有异常执行代码try:
a = int(input("请输入a的值"))
b = int(input("请输入b的值"))
print(a / b)
except ValueError:
print("请输入正确的整数")
except ZeroDivisionError:
print("除数不能为0")
except Exception as result:
print("未知异常", result)
else:
print("代码没有异常发生")
finally:
print("代码执行完成")7. 主动抛出异常
可以通过代码人为的抛出异常。
语法:
raise Exception("异常描述")主动抛出的异常同样会导致程序报错终止。
print("开始")
raise Exception("主动抛出的异常") # 这个异常是自己人为抛出
# 不论什么样的异常,只有不捕捉,代码就会报错终止
print("结束") # 这里的print执行不了,因为上面一句代码已经抛出异常了,程序终止了8. 捕捉主动抛出的异常
不管是什么异常,都需要代码捕捉,不然程序会报错。
# 计算器,当用户输入的不是+-*/会抛出异常,并捕捉这个异常
try:
num1 = int(input("请输入整数"))
num2 = int(input("请输入整数"))
op1 = input("请输入+-*/")
if op1 != "+" and op1 != "-" and op1 != "*" and op1 != "/":
raise Exception("请输入正确的+-*/")
if op1 == "+":
print(num1 + num2)
elif op1 == "-":
print(num1 - num2)
elif op1 == "*":
print(num1 * num2)
else:
print(num1 / num2)
except Exception as result:
print(result)
设计一个函数,如果参数str1中有数字返回true,否则返回false。
def digital(str1):
for n in str1:
if n >= "0" and n <= "9":
return True
return False
try:
name = input("请输入姓名")
if digital(name): # 条件成立,抛出异常
raise Exception("名字不允许有数字")
age = int(input("请输入年龄"))
if age < 0:
raise Exception("年龄不能小于0")
except Exception as result:
print(result)当一个函数返回一个布尔值,做为条件放到if或者while后面的时候,if 函数名 == True 等价 if 函数名 如果函数返回True,等于条件成立。
如果返回返回False等于条件不成立,如果一个函数返回False,那么就执行if语句 if not 函数名 :。
9. 异常案例
异常(错误)可以由try-except-else-finally组合语句捕获并进行处理,自定义的异常和主动引发(raise)的“异常”也可以由该语句捕获并处理。只要存在未被捕获处理的异常,就会导致程序退出。
class EmptyFileError(Exception): ⇽--- ❶
pass
filenames = ["myfile1", "nonExistent", "emptyFile", "myfile2"]
for file in filenames:
try: ⇽--- ❷
f = open(file, 'r')
line = f.readline() ⇽--- ❸
if line == "":
f.close()
raise EmptyFileError("%s: is empty" % file) ⇽--- ❹
except IOError as error:
print("%s: could not be opened: %s" % (file, error.strerror)
except EmptyFileError as error:
print(error)
else: ⇽--- ❺
print("%s: %s" % (file, f.readline()))
finally:
print("Done processing", file) ⇽---
上述代码自定义了一个异常,是从基类Exception中继承而来的❶。只要在try语句块的执行过程中发生了IOError或EmptyFileError,对应的except语句块就会被执行❷。此处的代码❸可能会引发IOError。而下面的代码主动引发了EmptyFileError ❹。
else从句不是必须有的❺,它会在try语句块没有发生异常时得以执行。注意,在上述例子中,在except语句块中加入continue语句也可以达到else语句的同样效果。finally语句也是可选项❻,无论是否引发了异常都会在try语句块结束时得以执行。
10. 用关键字with控制上下文
有一种更简单的try-except-finally封装模式,就是利用with关键字和上下文管理器(context manager)。Python会为文件访问之类的操作定义上下文管理器,开发人员也可以定义自己的上下文管理器。使用上下文管理器有一个好处,可以(通常)为其定义默认的善后清理操作,无论是否发生异常,一定能得以执行。
下面给出的是用with和上下文管理器打开并读取文件的例子。
with.py文件:
filename = "myfile.txt"
with open(filename, "r") as f:
for line in f:
print(line)这里的with建立了一个上下文管理器,将open函数和后续的语句块封装在一起。这时即便发生了异常,上下文管理器的预定义清理操作也会自动关闭该文件,只要第一行中的表达式执行时不会引发异常,就能确保关闭文件。
上述代码等价于:
filename = "myfile.txt"
try:
f = open(filename, "r")
for line in f:
print(line)
except Exception as e:
raise e
finally:
f.close()12、IO编程
1. 文件操作
1)文件的概念
计算机的文件,就是存储在某种长期储存设备上的一段数据。
长期存储设备包括:硬盘、U盘、移动硬盘、光盘…。
文件的作用是可以将数据长期保存下来,在需要的时候再使用。
2)文件的种类
(1)文本文件
可以使用文本编辑软件查看。
例如:python 的源程序,txt文本文件等。
(2)二进制文件
保存的内容不是给人直接阅读的,而是提供给其他软件使用的。
例如:图片文件、音频文件、视频文件等等。
二进制文件不能使用文本编辑软件查看。
2. 操作文件的“套路”
在计算机中要操作文件的套路非常固定,一共包含三个步骤:
1.打开文件;
2.读、写文件;
读: 将文件内容读入内存;
写: 将内容写入文件。
3. 关闭文件。
操作文件的函数/方法:
open 函数,打开文件。
open 函数负责打开文件,并且返回文件对象。
read/write/close三个方法都需要通过文件对象来调用。
read 方法 ——读取文件。
open 函数的第一个参数是要打开的文件名(文件名区分大小写),如果文件存在-----返回文件操作对象,如果文件不存在-----出错。
read 方法可以一次性读取文件的所有内容。
close 方法负责关闭文件。
如果忘记关闭文件,会造成系统资源消耗,而且会影响到后续对文件的访问。
3. 读取第一个文件内容
打开文件:
- file=open(要打开文件的路径和文件名,"r");
- file是一个变量名,代表文件操作对象;
- open的第一个参数一定要文件存在,如果文件不存在,会报错;
- "r"意思是用只读方式打开文件;
读取文件内容:
- txt=file.read();
- txt是定义一个变量,代表存放读取到的文件内容;
- file是上一个open返回的文件操作对象o read是file对象的一个方法,用来读取文件内容;
关闭文件:
- file.close();
- 文件打开后,一定要记得关闭;
# 第一步: 打开文件
file = open(r"C:\file\temp\a.txt", "r")
# 第二步:读取文件内容
txt = file.read()
print(txt) # 为了显示文件内容
# 第三步:关闭文件
file.close()4. 写第一个文件内容
打开文件:
- file=open("要打开的文件路径和文件名","w");
- 第二个参数w代表用写的方式打开文件;
- 如果用w方法打开文件,文件名不存在,会创建一个新文件,存在的话会覆盖已有文件;
写文件:
- file.write(要写入的内容);
- fp.writelines(list) 文件中写入列表类型内容;
- fp.truncate() 文件内容清空;
关闭文件:
- file.close();
# 第一步:打开文件
file = open(r"c:\file\temp\b.txt", "w")
# 第二步:写内容
file.write("hello python")
# 第三步:关闭文件
file.close()
# 验证程序是否执行成功?看c盘file目录的temp目录下是否生成了文件b.txt
# b.txt文件内容是否为hello python注意项:如果open第二个参数是"r",打开文件后只能用read读,不能用write写。
如果open第二个参数是"w",打开文件后只能用write写,不能用read读。
5. 追加写文件内容
打开文件:
- file=open("文件路径和文件名","a");
- "a"当文件不存在的时候创建新文件o当文件存在的时候,在文件后面追加内容;
写文件
- file.write("要写入文件的内容");
关闭文件
- file.close();
file = open(r"c:\file\temp\c.txt", "a")
file.write("hello\n")
file.close()open函数第二个参数的意思是打开文件的方式:
- r只读;
- w只写;
- a追加写;
- rb用二进制方法打开,只读;
- wb用二进制方法打开,只写;
- ab用二进制方法打开,追加;
6. 打开文件的时候,指定字符集
以 utf8 编码格式打开文件,如果指定文件字符集编码不是 utf8,打开会报错。
# 打开文件
file = open(r"C:\file\temp\a.txt", "r", encoding="utf8")
# 读取文件
text = file.read()
# 显示读取内容
print(text)
# 关闭文件
file.close()如果指定文件字符集编码不是 gbk,打开会报错。
# 打开文件
file = open(r"C:\file\temp\a.txt", "r", encoding="gbk")
# 读取文件
text = file.read()
# 显示读取内容
print(text)
# 关闭文件
file.close()如果文件格式是utf8的,open打开文件的时候需要指定字符集。
- file=open("文件名","r",encoding="utf8")
如果出现以下错误提示,基本就是由于字符集导致的错误。
UnicodeDecodeError:
file = open(r"C:\file\teach\05python\day09\3-code\01-open函数.py", "r",
encoding="utf8")
txt = file.read()
print(txt)
file.close()7. 修改文件内容案例
# 有文件a.txt
# 内容如下:
# 我爱你python, 我爱你
#
# 写代码,把a.txt内容中的python替换为world
#
# 思路,先把a.txt文件内用r方式读出来
# 用字符串的replace方法把python替换为world
# 在用w方式把替换后的内容写回到a.txt里面
file = open(r"c:\file\temp\a.txt", "r")
txt = file.read()
a = txt.replace("python", "world")
file.close() # 这一步必须关闭
file = open(r"c:\file\temp\a.txt", "w")
file.write(a)
file.close()8. 复制文件
# 把文件a.txt复制为b.txt
# 思路:把a.txt打开,读取全部内容
# 把b.txt用w方法打开,把内容写入
file = open(r"c:\file\temp\a.txt", "r")
txt = file.read()
file.close()
file = open(r"c:\file\temp\b.txt", "w")
file.write(txt)
file.close()9. 合并文件
# 有文件a.txt
# 内容如下:
#
# 我爱你python, 我爱你
#
# 有文件b.txt
# 内容如下:
#
# hello
#
# 把文件a.txt和b.txt合并为c.txt
# 思路:把文件a.txt内如读出来放到变量a
# 把文件b.txt内如读出来放到变量b
# 把a + b 结果写入的c.txt中
file = open(r"c:\file\temp\a.txt", "r")
a = file.read()
file.close()
file = open(r"c:\file\temp\b.txt", "r")
b = file.read()
file.close()
file = open(r"c:\file\temp\c.txt", "w")
file.write(a + b)
file.close()10. 按行读取文件内容
readline()按行读取文件内容,由于read一次把文件所有内容都读取到内存中,如果文件特别大,会消耗内存。每调用一次readline,内部的文件指针就会向下一行移动,这样的结果是下次再次调用readline会自动读取下一行。readline读取到文件最后,返回""。
如果要通过readline来读取文件所有内容:
- 写一些死循环;
- 在循环内部调用readline,读取文件每一行;
- 如果readline返回为"",终止这个死循环;
file = open(r"c:\file\temp\a.txt", "r")
# 在循环开始的时候,不知道文件有多少行,所以也不能决定循环多少次
while True:
txt = file.readline()
# 如果readline读取到文件最后末尾,返回""
if txt == "":
break
print(txt, end="")
file.close()11. 读取文件偶数行
# 有文件a.txt,有很多行,只显示偶数行
# 思路:只读方式打开a.txt,读取所有行,但只显示偶数行
# 做一个循环读取所有行,在循环的时候做一个计数器,每次循环计数器+1
# 可以判断计数器是偶数还是奇数,如果是偶数那么就print
file = open(r"c:\file\temp\a.txt", "r")
index = 1
while True:
txt = file.readline()
if txt == "":
break
if index % 2 == 0: # 如果条件成立,代表index为偶数
print(txt, end="")
index += 1
file.close()12. readlines
一下读取文件所有行,返回一个列表列表中的一个成员就是文件中的一行,文件有多少行,列表就有多少成员。
file = open(r"c:\file\temp\a.txt", "r")
list1 = file.readlines()
for n in list1:
print(n, end="")
file.close()计算文件中最大数字与最小数字的差:
# 有个文件a.txt,内容每一行是一个整数,最大值和最小值的差
# 思路:
# 把文件每一行 做为list的每个成员(文件的每一行是字符串)
# 只有max(list) - min (list)
#
# 先做一个空的list
# 循环读每行,把每行用int转化为整数,append到空的list里面
# 循环读完后,就可以max(list) - min(list)
file = open(r"c:\file\temp\a.txt", "r")
list1 = []
while True:
txt = file.readline()
if txt == "":
break
list1.append(int(txt))
file.close()
print(max(list1) - min(list1))字符串比较大小的原理:
list1 = [2, 12, 5]
list2 = ['2', '12', '5']
print(max(list1), min(list1))
print(max(list2), min(list2))
# 如果长得像数字的字符串比较大小,比较原理是先比较字符串的一个字符13. with open语法
这个语法传统的file=open的一种简化语法,不需要明确的调用close关闭文件。
# file = open(r"c:\file\temp\a.txt", "r")
# txt = file.read()
# print(txt)
# file.close()
# 对等代码
with open(r"c:\file\temp\a.txt", "r") as file:
txt = file.read()
print(txt)# 上下文管理器打开文件(会自动close文件)
with open(文件路径,模式,encoding='utf-8')as fp:
fp.read()
fp.seek(m):移动文件指针,当前位置向后移动m个字节;
fp.tell(m):查看文件指针;
fp.flush(m):刷新缓冲区和 fp.close()类似;
14. JSON 操作
1)JSON 简介
JSON的全称是"JavaScriptObject Notation",是JavaScript 对象表示法,它是一种基于文本,独立 于语言的轻量级数据交换格式。
JSON特点:
- JSON是纯文本;
- JSON具有良好的自我描述性,便于阅读和编写;
- JSON具有清晰的层级结构;
- 有效地提升网络传输效率;
JSON 语法规则:
- 大括号保存对象;
- 中括号保存数组;
- 对象数组可以相互嵌套;
- 数据采用键值对表示;
- 多个数据由逗号分隔;
JSON 值可以是:
- 数字(整数或浮点数);
- 字符串(在双引号中);
- 逻辑值(true 或 false);
- 数组(在中括号中);
- 对象(在大括号中);
- null;
在互联网传递数据的时候, JSON是很常见的一种文件格式,所有数据用一对大括号括起来。
大括号内部是键值对,键和值用冒号分隔,多个键值对用逗号分隔,字符串用双引号,数字不需要引号,列表用中括号,对象用大括号。
{
"name": "tom",
"age": 18,
"isMan": true,
"school": null,
"address": {
"country": "中国",
"city": "北京",
"street": "新街里东路"
},
"numbers": [2, 6, 8, 9],
"links": [
{
"name": "baidu",
"url": "http://www.百度.com"
},
{
"name": "百度",
"url": "http://www.百度.com"
}
]
}2)Json操作
需要用到json库(import json):
- json.loads():把json格式的字符串转换成python对象;
- json.dumps():把python对象转换成json格式的字符串;
- json.load(open(文件路径)):读取文件中json形式的字符串元素,转换成python对象;
- json.dump(open(文件路径)):把python对象转换成json格式的字符串并存入文件中;
jsonpath:
import json import jsonpath
json_str = '【{"id":1,"category":{"id":1,"category":"常用改图工具","sn":"c
# json 字符串转成 python 对象
py_obj = json.loads(json_str)
name = jsonpath.jsonpath(py_obj,'$..name')
url = jsonpath.jsonpath(py_obj,'$..url')
3)读取json文件的方法
第一步要导入json模块:
- import json
第二步打开json文件:
- json中有中文,一般字符集都是utf8,打开文件的时候要指定字符集为utf8;
- open(json文件名,"r",encoding="utf8");
第三步:调用json模块的load方法,读取文件内容:
- data=json.load(file);
第四步:关闭open打开的文件:
- file.close();
import json
file = open("a.json", "r", encoding="utf8")
data = json.load(file) # 把json文件的内容转化为python的字典
file.close()
# print(data)
for n in data:
print(n, data[n])4)操作json文件常见错误
错误1:json格式错误。
json.decoder.JSONDecodeError错误2:扩展名不是json,是其他的。
json文件的扩展名必须是.json错误3:自己创建了一个文件名叫json.py。
AttributeError: module 'json' has no attribute 'load'5)写json文件
导入json模块:
- import json;
用只写方式打开json文件:
- open(json文件,"w",encoding="utf8");
用dump方法把字典内容写入到json文件中:
- ensure_ascii=False代表中文不转义;
关闭文件;
import json
dict1 = {"name":"刘备", "age":20, "sex":"男"}
file = open("data.json", "w", encoding="utf8")
json.dump(dict1, file, ensure_ascii=False)
file.close()6)修改json文件内容

# 思路:
# 先把内容从test.json文件中读出来
# 读出来的结果是一个字典
# 把字典中键age对应 的值修改为30
# 再把字典写回到test.json文件中
import json
file = open("test.json", "r", encoding="utf8")
dict1 = json.load(file)
file.close()
dict1["age"] = 30
file = open("test.json", "w", encoding="utf8")
json.dump(dict1, file, ensure_ascii=False)
file.close()