Python数据分析师|Pandas之数据结构
版权声明:原创不易,本文禁止抄袭、转载,侵权必究!
目录
-
- 一、数据创建
- 二、Series数据结构
- 三、DataFrame数据结构
- 四、更改数据
- 五、知识总结
- 六、作者Info
一、数据创建
创建Series数据
我们在上一篇介绍到Pandas中的Series类似于numpy.ndarray和Python中的List容器,所以我们可以用List容器创建Series数据:
import pandas as pd
from string import ascii_uppercase
series_data = pd.Series(list(ascii_uppercase))
print(series_data)
控制台输出:

也可以用numpy.ndarray数组创建Series数据:
import pandas as pd
import numpy as np
import random
series_data = pd.Series(np.random.randn(5))
print(series_data)
series_data = pd.Series(np.array(list(random.random() for _ in range(5))))
print(series_data)
series_data = pd.Series(np.arange(5))
print(series_data)
控制台输出:
0 0.748095
1 -1.129178
2 2.546962
3 -0.150222
4 -1.333712
dtype: float64
0 0.615831
1 0.261528
2 0.273036
3 0.345906
4 0.053881
dtype: float64
0 0
1 1
2 2
3 3
4 4
dtype: int32
我们使用了numpy中的random()、array()、arange()方法(其返回类型都是numpy.ndarray)并结合Python自带的标准库random创建了三个Series,成功创建并输出数据
#np.random.randn()方法能够随机返回指定数字的实数,与Python自带的标准库random类似,Python内置的random模块还有以下常用操作:
import random
#随机返回0-1之间的一个小数:
ramdom.random()
#随机返回指定区间内的一个整数:
ramdom.randint(3, 5)
这种操作在进行数据实验或者爬虫时会经常被用到,比如我们在爬取数据时为了避免爬取速度过快或防止对方的服务器监测到我们的爬虫程序,可用延时操作:
import random
import time
time.sleep(random.random())
time.sleep(random.randint(3, 5))
#array()方法可直接返回numpy.ndarray数组(强制性转换),类似于Python中的List容器
#arange()方法可返回指定范围内的numpy.ndarray数组,类似于Python中的全局函数range(),可进行skip(跳跃)操作:
#input:
ndarray_data = np.arange(1, 6, 2)
#output
[1 3 5]
arange()方法还可创建多维ndarray数组,比如我们现在创建一个2*3的二维ndarray数组,并直接将该数组转换为矩阵:
#input:
ndarray_data = np.arange(6).reshape(2, 3)
#output
[[0 1 2]
[3 4 5]]
#type(ndarray_data )
<class 'numpy.ndarray'>
#input:
matrix_data = np.bmat(np.arange(6).reshape(2, 3))
#matrix_data = np.matrix(np.arange(6).reshape(2, 3))
#output
[[0 1 2]
[3 4 5]]
#type(matrix_data )
<class 'numpy.matrix'>
从上面的代码中我们可看出,同样是2*3结构,输出数据也一样,但数据类型却不同,分别是ndarray和matrix,根据业务逻辑,有时候我们可能需要将数组转换为矩阵并执行相关的计算(矩阵链乘法等)
使用List容器或ndarray数组是可以成功创建Series数据的,那么如果使用tuple(元组)、dict(字典)、set(集合)可以创建成功吗?我们实验一下
#使用元组创建Series:
#input:
series_data = pd.Series(('a','b', 'c'))
#output
0 a
1 b
2 c
dtype: object
从输出可以看出,元组被转换为了一整列数据,并且索引默认也是数字
#使用字典创建Series:
#input:
series_data = pd.Series({'a': '1', 'b': 2, 'c' : 3})
#output
a 1
b 2
c 3
dtype: object
从输出可以看出,字典中所有的value也被转换为了一整列数据,但是默认索引数字被字典中的key取代了
#使用集合创建Series:
#input:
import random
series_data = pd.Series(set(random.random() for _ in range(5)))
#output
TypeError: 'set' type is unordered
从输出可以看出,当使用集合创建Series时抛出了TypeError(类型错误),报错的意思就是说集合是无序的,那这就奇怪了,我们在上面使用字典创建Series时使用的字典也是无序的,为什么无序字典能够成功创建Series,而无序集合却创建失败呢?
小伙伴们可以去各种渠道搜一下(Google/StackOverFlow/ChatGPT/官方文档等)
注意:使用dict()全局函数或{}创建的字典默认是无序的,若有特殊业务需求也用使用有序字典,可从标准库collections直接导入即可:
from collections import OrderedDict
创建DataFrame数据
上篇教程说过,我们可以把DataFrame看作Series组成的字典或二维数组,而字典是创建DataFrame是最常用的方式,,其中key(键)表示列名,value(值)表示一整列数据,而value可以由series、list、tuple、dict、ndarray创建,现在我们使用列表创建value,代码如下:
import pandas as pd
from string import ascii_lowercase,ascii_uppercase
dataframe_data = pd.DataFrame(data={'lower_case': list(ascii_lowercase), 'upper_case': list(ascii_uppercase)})
我们只看前5数据:
#intput
print(dataframe.head(n=5))
#output
lower_case upper_case
0 a A
1 b B
2 c C
3 d D
4 e E
我们也可以下面的格式查看前5行数据:
datafram_data{ : 5}
从上面输出可看出,小写字母在第一列,大写字母在第二列,但这样的顺序并非不变,因为字典默认是无序的,也就是说在下一次输出时大写字母有可能出现在第一列,为了固定每列数据的顺序,我们可使用参数columns,需要传递一个列表:
dataframe_data = pd.DataFrame(data={'lower_case': list(ascii_lowercase), 'upper_case': list(ascii_uppercase)}, columns=['lower_case', 'upper_case'])
当然我们也可使用有序字典OrderedDict
输出数据相同的,但请注意,这里是先由元组对(key, value)组成列表,再由OrderedDict强制转换为有序字典
嵌套结构创建DataFrame
#元组列表创建DataFrame
既然由元组组成的列表可以通过OrderedDict转换为字典进而创建DataFrame,那么如果我们不通过OrderedDict进行转换,直接把由元组构成的列表传递给参数data能不能创建成功呢?试验一下:
#input
dataframe_data = pd.DataFrame(data=[(1, 2, 3), (4, 5, 6), (7, 8, 9)])
#output
0 1 2
0 1 2 3
1 4 5 6
2 7 8 9
#input
dataframe_data = pd.DataFrame(data=[('a', 'b', 'c'), ('d', 'e', 'f'), ('g', 'h', 'i')], columns=['A', 'B', 'C'])
#output
A B C
0 a b c
1 d e f
2 g h i
从上面的输出数据可以看出,当我们以数字组成的元组对构建列表并传递给参数data创建DataFrame时,一个元组对变成了一行数据,就是说有n个元组对就有n行数据;
而且我们没有指定列名,列名默认是以0开头的单位递增数字,当我们给columns参数传递大写字母列名时,数字列名被替换成了我们所定义的大写字母
#字典列表创建DataFrame
由元组构成的列表能够成功创建DataFrame,那么由字典构成的列表能够创建DataFrame吗?再次进行实验:
#input
dataframe_data = pd.DataFrame(data=[{"a": 1, "b": 2, "c": 3}, {"a": 4, "b": 5, "c": 6}])
#output
a b c
0 1 2 3
1 4 5 6
从输出结构可以看出,由字典构成的列表能够创建成功DataFrame,并且列名就是
字典的key,每个字典的所有value构成了每一行数据
但是这里的每个字典长度都是相同的(都是3),如果字典长度不一样会怎样呢?比如
在列表中我们定义第一个字典的长度为3,第二个字典长度为2,输出格式会有什么
不同呢?实验一下:
#input
dataframe_data = pd.DataFrame(data=[{"a": 1, "b": 2, "c": 3}, {"a": 4, "b": 5}])
#output
a b c
0 1 2 3.0
1 4 5 NaN
我们所定义的第二个字典没有key为字符c的数据,而输出的数据中有一个特殊值
NaN,很明显,如果我们在第二个字典中定义key“c”为6,那么NaN的位置应该是
6,而NaN是Pandas用于标记缺失数据的特殊值,来源于numpy,还有np.nan也
表示缺失值,我们可以直接把NaN或nan定义为value:
#input
dataframe_data = pd.DataFrame(data=[{"a": 1, "b": np.NaN, "c": 3}, {"a": np.nan, "b": 5}])
#output
a b c
0 1.0 NaN 3.0
1 NaN 5.0 NaN
字典列表创建DataFrame也是比较常用的方式,特别是在爬虫方面,因为在爬取数
据时,我们常常会采用字典+列表的格式来存储数据,字典其实是哈希表在Python
中的一种表现形式,哈希表由哈希函数(或称散列函数)+数组实现的,而Python中
的列表是使用数组来实现的,在平均情况下这两种数据结构读取的时间复杂度都为
O(1),能够极大提高我们的代码性能
想象一下,在爬完数据之后,如果我们采用字典+列表的格式创建DataFrame,可以
直接对数据进行分析或存储,不需要再进一步转化为series、list、ndraary、tuple
类型以此来创建DataFrame,是不是非常方面呢?办公效率也会极大提升,但这不
局限于爬虫,比如我们直接从数据库抽取数据等
二、Series数据结构
Series索引
这里我们使用上一篇教程所用的实习僧数据集,先看看数据:
import pandas as pd
filename = '2021_Python_shixi_data.xlsx'
df = pd.read_excel(filename)
print(df)
控制台输出:
position salary location degree time duration
0 三维人体/三维视觉算法实习生 250-300/天 全国 硕士 5天/周 实习3个月
1 python开发工程师 100-150/天 成都 不限 5天/周 实习5个月
2 Python工程师 0-50/天 北京 不限 2天/周 实习2个月
3 python实习生 200-400/天 全国 本科 4天/周 实习3个月
4 Python开发工程师 120-200/天 成都 大专 5天/周 实习3个月
.. ... ... ... ... ... ...
234 清华大学机器学习课题组实习生 薪资面议 深圳 本科 5天/周 实习12个月
235 爬虫实习生 120-150/天 南京 不限 5天/周 实习3个月
236 数据采集实习生 100-150/天 北京 不限 4天/周 实习6个月
237 少儿编程讲师 400-500/天 北京 本科 6天/周 实习12个月
238 信息安全工程师 150-300/天 广州 大专 5天/周 实习8个月
[239 rows x 6 columns]
之前我们说过,熟悉了pandas的数据结构之后,不需要打印类型,我们就能根据获取数据的范围和字段大致判断出是Series还是DataFrame,比如我们只获取单行或单列那么返回类型就是Series,如果获取多行或多列就是DataFrame,现在我们单独获取position这个字段的整列数据:
#input
df['postition']
#output
0 三维人体/三维视觉算法实习生
1 python开发工程师
2 Python工程师
3 python实习生
4 Python开发工程师
...
234 清华大学机器学习课题组实习生
235 爬虫实习生
236 数据采集实习生
237 少儿编程讲师
238 信息安全工程师
Name: position, Length: 239, dtype: object
其实每个字段(列名)也是DataFrame的属性,所以我们可以这样获取数据:
df.postition
通过观察可以发现,无论是DataFrame还是Series数据,在不指定新的索引之前,索引默认是以0开头单位递增的整数,可以通过.index属性单独查看索引:
#input
df.postition.index
#output
RangeIndex(start=0, stop=239, step=1)
假想一下,无论是工作中或是个人项目中,此时由于某种逻辑,你需要把默认的索引更改并插入到数据库中,以便以后的数据查询,即便某些数据库有着特殊的索引(比如MySQL能够设置索引自增,MongoDB能够为每条数据创建默认的索引ID等)
现在我们希望为每条数据创建类似2023-03-18 00:03:58这样的索引,我们需要使用DataFrame中的date_range()方法:
#input
position_series = df['position']
position_series.index = pd.date_range('2023-03-18', periods=len(df), freq='S')
print(position_series )
#output
2023-03-18 00:00:00 三维人体/三维视觉算法实习生
2023-03-18 00:00:01 python开发工程师
2023-03-18 00:00:02 Python工程师
2023-03-18 00:00:03 python实习生
2023-03-18 00:00:04 Python开发工程师
...
2023-03-18 00:03:54 清华大学机器学习课题组实习生
2023-03-18 00:03:55 爬虫实习生
2023-03-18 00:03:56 数据采集实习生
2023-03-18 00:03:57 少儿编程讲师
2023-03-18 00:03:58 信息安全工程师
Freq: S, Name: position, Length: 239, dtype: object
date_range()方法有四个参数,分别是start(开始时间)、end(结束时间)、periods(数据个数/长度)、freq(递增频率),freq参数可以选择秒数递增、月数递增、年数递增等,现在我们来建一个长度为5的时间索引并查看类型:
#input
time_index = pd.date_range('2023-03-18', periods=5)
print(time_index)
#output
DatetimeIndex(['2023-03-18', '2023-03-19', '2023-03-20', '2023-03-21',
'2023-03-22'],
dtype='datetime64[ns]', freq='D')
#input
type(time_index)
#output
<class 'pandas.core.indexes.datetimes.DatetimeIndex'>
从输出可看出,其返回类型是DatetimeIndex,每个元素的类型是datetime64,而且如果我们不指定递增频率的话默认是以天数来递增的;这里还需注意一点,date_range()的start和end时间参数无论是形如[xxxx/xx/xx]还是[xx/xx/xxxx]这样的格式最终都将转换为[xxxx-xx-xx]这样的格式,代码如下所示:
#格式1
time_index = pd.date_range('2023/3/18', periods=5)
#格式2
time_index = pd.date_range('3/18/2023', periods=5)
返回内容和上面一致
说到这种格式,我就想到了Python中的datetime模块和time模块,如果我们想要获取当前时间作为索引并且以秒数递增的话可以这样做:
import time
now_time = time.strftime('%Y%m%d %H:%M:%S', time.localtime(int(time.time())))
time_index = pd.date_range(now_time, periods=5, freq='S')
print(time_index)
#output
DatetimeIndex(['2023-03-20 22:11:16', '2023-03-20 22:11:17',
'2023-03-20 22:11:18', '2023-03-20 22:11:19',
'2023-03-20 22:11:20'],
dtype='datetime64[ns]', freq='S')
也可以使用datetime模块这样做:
import datetime
now_time = datetime.now().strftime('%Y%m%d %H:%M:%S')
time_index = pd.date_range(now_time, periods=5, freq='S')
print(time_index)
#output
DatetimeIndex(['2023-03-20 22:16:35', '2023-03-20 22:16:36',
'2023-03-20 22:16:37', '2023-03-20 22:16:38',
'2023-03-20 22:16:39'],
dtype='datetime64[ns]', freq='S')
Series常用属性
#使用loc属性获取Series子集
#input
position_series = df['position']
print(position_series.loc[5:10])
#output
5 Python开发实习生
6 Python实习生
7 python开发工程师
8 Python实习生
9 Python实习生
10 Python研发工程师
Name: position, dtype: object
从输出结果可看出,使用loc属性获取数据时,数据是包含最后一个切片索引位置数据的
#使用iloc属性获取Series子集
#input
position_series = df['position']
print(position_series.iloc[:5])
#output
0 三维人体/三维视觉算法实习生
1 python开发工程师
2 Python工程师
3 python实习生
4 Python开发工程师
Name: position, dtype: object
从输出结果可看出,使用loc属性获取数据时,数据是不包含最后一个切片索引位置数据的
#使用dtype或dtypes属性获取Series类型
#input
position_series.dtype
#output
object
#使用shape属性获取Series的维数
#input
position_series.shape
#output
(239,)
#使用size属性获取Series的元素数量
#input
position_series.size
#output
239
直接使用Python全局函数len()也可:len(position_series)
#使用values属性获取numpy.ndarray数组:
position_series.values
控制台输出:

从输出数据可看出这是一个类似Python中List容器的类型,元素之间是没有逗号的,该类型就是
Series常用方法
#使用append()方法连接两个或多个Series
#input
series_one = pd.Series(np.zeros(5))
series_two = pd.Series(np.ones(5))
series_three = series_one.append(series_two)
print(series_three)
#output
0 0.0
1 0.0
2 0.0
3 0.0
4 0.0
0 1.0
1 1.0
2 1.0
3 1.0
4 1.0
dtype: float64
注意:两个series连接之后,默认的索引不是单位递增的,而是它们之前的series索引,而且使用append方法连接两个series会有一个警告:
FutureWarning: The series.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
这个警告就是说append方法会在pandas未来的版本中移除,提示我们使用pd.concat()方法来替换:
series_three = pd.concat([series_one, series_two])
输出数据是一样的,警告没有了
#使用describe()方法计算概况统计量
#input
series_three.describe()
#output
count 10.000000
mean 0.500000
std 0.527046
min 0.000000
25% 0.000000
50% 0.500000
75% 1.000000
max 1.000000
dtype: float64
#使用drop_duplicates()方法对series进行去重返回series
#input
series_three.drop_duplicates()
#output
0 0.0
0 1.0
dtype: float64
因为series_three的元素只含0和1,所有去重后只剩0和1
#使用get_values()方法获取ndarray向量
此方法和series.values属性效果相同
#使用unique()方法对series进行去重返回ndarray数组(向量)
此方法目的也是去重,但返回的是ndarray向量,不是series向量
#使用sample()方法对series进行随机采样
由于series也是向量,numpy的ndarray向量和series中的一些方法有重叠,比如max()、min()、mean()、median()、众数mode()、协方差cov()、std()等,我们可把series看作是ndarray向量的扩展
三、DataFrame数据结构
前面我们介绍了series的索引、属性和方法,这些操作同样适用于DataFrame
#更改DataFrame的默认索引
#input
filename = '2021_Python_shixi_data.xlsx'
df = pd.read_excel(filename)
now_time = datetime.now().strftime('%Y%m%d %H:%M:%S')
df.index = pd.date_range(now_time, periods=df.shape[0], freq='S')
print(df.tail(n=5))
#output
position salary location degree time duration
2023-03-22 20:22:31 清华大学机器学习课题组实习生 薪资面议 深圳 本科 5天/周 实习12个月
2023-03-22 20:22:32 爬虫实习生 120-150/天 南京 不限 5天/周 实习3个月
2023-03-22 20:22:33 数据采集实习生 100-150/天 北京 不限 4天/周 实习6个月
2023-03-22 20:22:34 少儿编程讲师 400-500/天 北京 本科 6天/周 实习12个月
2023-03-22 20:22:35 信息安全工程师 150-300/天 广州 大专 5天/周 实习8个月
DataFrame常用属性
shape属性:
#input
df.shape
#output
(239, 6)
index属性:
#input
df.index
#output
DatetimeIndex(['2023-03-22 20:25:10', '2023-03-22 20:25:11',
'2023-03-22 20:25:12', '2023-03-22 20:25:13',
'2023-03-22 20:25:14', '2023-03-22 20:25:15',
'2023-03-22 20:25:16', '2023-03-22 20:25:17',
'2023-03-22 20:25:18', '2023-03-22 20:25:19',
...
'2023-03-22 20:28:59', '2023-03-22 20:29:00',
'2023-03-22 20:29:01', '2023-03-22 20:29:02',
'2023-03-22 20:29:03', '2023-03-22 20:29:04',
'2023-03-22 20:29:05', '2023-03-22 20:29:06',
'2023-03-22 20:29:07', '2023-03-22 20:29:08'],
dtype='datetime64[ns]', length=239, freq='S')
values属性:
#input
df.values
#output
[['三维人体/三维视觉算法实习生' '250-300/天' '全国' '硕士' '5天/周' '实习3个月']
['python开发工程师' '100-150/天' '成都' '不限' '5天/周' '实习5个月']
['Python工程师' '0-50/天' '北京' '不限' '2天/周' '实习2个月']
...
['数据采集实习生' '100-150/天' '北京' '不限' '4天/周' '实习6个月']
['少儿编程讲师' '400-500/天' '北京' '本科' '6天/周' '实习12个月']
['信息安全工程师' '150-300/天' '广州' '大专' '5天/周' '实习8个月']]
注意看,DataFrame的values属性返回的是一个二维numpy.ndarray数组,中间使用三个点代表中间未打印的数据,即数据不会全部打印,使用tolsit()方法或全局函数list()将其转换为列表:
df.values.tolist()
打印列表数据,此时会全部打印出来:
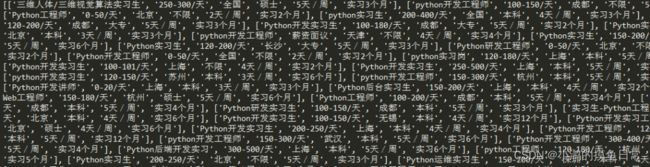
转换为列表之后数据全部打印,元素之间有逗号相隔
loc属性(包含最后一个索引数据):
#input
df.loc[:5, ['position']]
#output
position
0 三维人体/三维视觉算法实习生
1 python开发工程师
2 Python工程师
3 python实习生
4 Python开发工程师
5 Python开发实习生
从输出数据看出,使用loc属性获取数据,当最后一个索引位置为5时,可打印6行数据,此时我们仅获取position这个字段的数据
iloc属性(不包含最后一个索引数据):
#input
df.iloc[:5, [0]]
#output
position
0 三维人体/三维视觉算法实习生
1 python开发工程师
2 Python工程师
3 python实习生
4 Python开发工程师
dtypes属性:
#input
df.dtypes
#output
<class 'pandas.core.frame.DataFrame'>
columns属性:
#input
df.columns
#output
Index(['position', 'salary', 'location', 'degree', 'time', 'duration'], dtype='object')
DataFrame获取多列数据:
#input
df[['position', 'salary']]
#output
0 三维人体/三维视觉算法实习生 250-300/天
1 python开发工程师 100-150/天
2 Python工程师 0-50/天
3 python实习生 200-400/天
4 Python开发工程师 120-200/天
.. ... ...
234 清华大学机器学习课题组实习生 薪资面议
235 爬虫实习生 120-150/天
236 数据采集实习生 100-150/天
237 少儿编程讲师 400-500/天
238 信息安全工程师 150-300/天
DataFrame常用方法
#info()方法获取概要信息
#input
df.info()
#output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 239 entries, 0 to 238
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 position 239 non-null object
1 salary 239 non-null object
2 location 239 non-null object
3 degree 239 non-null object
4 time 239 non-null object
5 duration 239 non-null object
dtypes: object(6)
memory usage: 11.3+ KB
None
从输出结果可看出,info()方法包含一些概要信息,包括数据类型
#count()方法统计每列非NaN的的数量
#input
df.count()
#output
position 239
salary 239
location 239
degree 239
time 239
duration 239
dtype: int64
#concat()方法连接两个或多个DataFrame
#input
dataframe_one = pd.DataFrame(data=[list(np.zeros(5))])
dataframe_two = pd.DataFrame(data=[list(np.ones(5))])
dataframe_three = pd.concat([dataframe_one, dataframe_two])
print(dataframe_three)
#output
0 1 2 3 4
0 0.0 0.0 0.0 0.0 0.0
0 1.0 1.0 1.0 1.0 1.0
#也可使用append()方法进行连接
#input
dataframe_three = dataframe_one.append(dataframe_two)
#output
FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
dataframe_three = dataframe_one.append(dataframe_two)
0 1 2 3 4
0 0.0 0.0 0.0 0.0 0.0
0 1.0 1.0 1.0 1.0 1.0
与连接series一样,仍然会有一个未来警告,所以以后无论是连接series还是连接DataFrame我们都使用concat()方法
这里分享一个Python库glob,它可以按我们指定的规则把所有符合规则的文件名以列表的形式返回,比如我们想要匹配当前目录下所有以下划线(_)开头的文件名,首先看看目录文件:
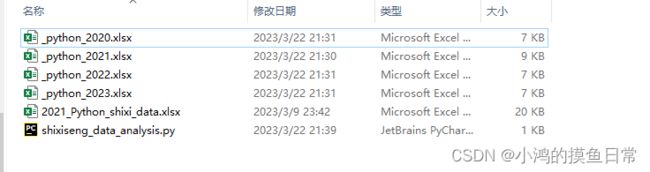
注意,当前文件中以下划线开头的共有4个文件,接下来看看我们匹配的对不对:
import glob
print(glob.glob('_*'))
匹配看来是正确的:
['_python_2020.xlsx', '_python_2021.xlsx', '_python_2022.xlsx', '_python_2023.xlsx']
设想一下,现在你有一个任务,需要把Excel文件中以下划线开头的文件批量合并,为了下一步的数据分析做准备,此时你可以把代码写成这样:
all_df = pd.concat([pd.read_excel(file) for file in glob.glob('_*')])
这样一来,我们在遇到类似的问题时,不必再一个一个读取Excel文件以及合并DataFrame了,编写自动化代码,可以让我们的工作效率得以提高,代码复现性也提高了
这种方式有点类似于os库中的listdir()方法:
#input
import os
dir_list = os.listdir('./')
print(dir_list)
#output
['2021_Python_shixi_data.xlsx', 'shixiseng_data_analysis.py', '_python_2020.xlsx', '_python_2021.xlsx', '_python_2022.xlsx', '_python_2023.xlsx']
但是该方法会返回所有的文件名,如果我们只想要以下划线开头的文件名,可能就需要使用正则表达式进行字符匹配了,比如我们可以这样写:
re.findall('^_.*', filename)
这样就可以匹配出以下划线开头的文件名,.*表示贪婪匹配
#使用drop_duplicates()方法对DataFrame去重
注意,pandas的这种去重方法必须所有字段的数据相同时才会进行去重,也就是说对于每一行数据,就算其他字段都相同,只要有一个字段的数据不相同pandas是不去重的,比如下面这两行数据:

你没猜错,当你调用drop_duplicates()方法进行去重时,这两条数据是不去重的,因为它们的description这个字段是不同的,只因为前者多了三个点“…”
当pandas中的内置方法不能满足我们的需求时,我们就需要自己去写一个去重方法,比如上面这两条数据,如果我们只想保留其中一条数据使得id唯一,一个简单的做法是使用动态规划算法+哈希表(可以理解为Python中的字典),每迭代一条数据,我们都将该数据的id存入哈希表中,如果后面的数据能在哈希表中找到,说明该条数据是重复的,直接continue,不用再迭代后面的数据了
很明显,上面的去重思路是可行的,但是当遇到数百万,甚至上亿条数据时,这种方法无疑会存在相当大的时间复杂度,虽然我们可使用异步(Asynchronous)的方式,但前提是要符合我们的业务逻辑;这时候我们可采用他人写好的大规模去重算法,比如Boom Filter(布隆过滤器),这个算法的空间利用率极高,常用来处理大规模的数据去重;当然,如果你对这方面感兴趣并且肯花时间专研,可以尝试去编写一个大规模去重算法,使得比已经开源的去重算法的时间复杂度还要低,那就非常厉害了!
pandas中的drop_duplicates()去重方法其实还有很多限制(一些坑),比如当你存入的字段中嵌套着其他结构,比如列表:

上面这个type字段中是一个列表,有时候我们确实需要这样的格式存储数据,这是合理的,但是此时如果你用drop_duplicates()去重,不仅去不了重,反而会报错,代码如下:
df = pd.DataFrame(data=[
['1653452436', ['Hacker', 'Scam'], 'I see this hacker...'],
['1653452436', ['Hacker', 'Scam'], 'I see this hakcer']
])
print(df.drop_duplicates())
报错如下:
TypeError: unhashable type: 'list'
字段元素类型如果是List,是能够在不去重的情况下存储在Excel、csv或其他格式的文件中,如果一旦使用drop_duplicates()去重方法就会报错,但是,如果你把列表变为元组,确实能够运行,即使达不到我们想要的去重效果:
df = pd.DataFrame(data=[
['1653452436', ('Hacker', 'Scam'), 'I see this hacker...'],
['1653452436', ('Hacker', 'Scam'), 'I see this hakcer']
])
print(df.drop_duplicates())
数据输出如下:
0 1 2
0 1653452436 (Hacker, Scam) I see this hacker...
1 1653452436 (Hacker, Scam) I see this hakcer
其实还有很多适用于小中型数据规模的去重算法思路,DataFrame也有很多其他常用方法,我们会结合后面的内容给大家一起介绍
四、更改数据
#为DataFrame添加新列
from datetime import datetime
import pandas as pd
filename = '2021_Python_shixi_data.xlsx'
df = pd.read_excel(filename)
df['start_time'] = pd.date_range(datetime.now(), periods=df.shape[0], freq='S')
print(df)
我们为实习僧数据添加了每个岗位开始工作的时间,频率为秒,这数据显然不正常,但这仅仅是一个示例而已,输出如下:
position salary ... duration start_time
0 三维人体/三维视觉算法实习生 250-300/天 ... 实习3个月 2023-03-23 22:13:19.849278
1 python开发工程师 100-150/天 ... 实习5个月 2023-03-23 22:13:20.849278
2 Python工程师 0-50/天 ... 实习2个月 2023-03-23 22:13:21.849278
3 python实习生 200-400/天 ... 实习3个月 2023-03-23 22:13:22.849278
4 Python开发工程师 120-200/天 ... 实习3个月 2023-03-23 22:13:23.849278
.. ... ... ... ... ...
234 清华大学机器学习课题组实习生 薪资面议 ... 实习12个月 2023-03-23 22:17:13.849278
235 爬虫实习生 120-150/天 ... 实习3个月 2023-03-23 22:17:14.849278
236 数据采集实习生 100-150/天 ... 实习6个月 2023-03-23 22:17:15.849278
237 少儿编程讲师 400-500/天 ... 实习12个月 2023-03-23 22:17:16.849278
238 信息安全工程师 150-300/天 ... 实习8个月 2023-03-23 22:17:17.849278
#直接更改DataFrame整列
比如我们把实习总长全部改为3个月:
#input
df['duration'] = [3 for _ in range(len(df))]
#output
position salary location degree time duration
0 三维人体/三维视觉算法实习生 250-300/天 全国 硕士 5天/周 3
1 python开发工程师 100-150/天 成都 不限 5天/周 3
2 Python工程师 0-50/天 北京 不限 2天/周 3
3 python实习生 200-400/天 全国 本科 4天/周 3
4 Python开发工程师 120-200/天 成都 大专 5天/周 3
.. ... ... ... ... ... ...
234 清华大学机器学习课题组实习生 薪资面议 深圳 本科 5天/周 3
235 爬虫实习生 120-150/天 南京 不限 5天/周 3
236 数据采集实习生 100-150/天 北京 不限 4天/周 3
237 少儿编程讲师 400-500/天 北京 本科 6天/周 3
238 信息安全工程师 150-300/天 广州 大专 5天/周 3
#删除DataFrame整列
比如我们想把degree这一列数据整个删掉,可以调用drop()方法,并把axis参数赋值为1,表示删除整列:
#input
no_degree_df = df.drop(['degree'], axis=1)
#output
position salary location time duration
0 三维人体/三维视觉算法实习生 250-300/天 全国 5天/周 实习3个月
1 python开发工程师 100-150/天 成都 5天/周 实习5个月
2 Python工程师 0-50/天 北京 2天/周 实习2个月
3 python实习生 200-400/天 全国 4天/周 实习3个月
4 Python开发工程师 120-200/天 成都 5天/周 实习3个月
.. ... ... ... ... ...
234 清华大学机器学习课题组实习生 薪资面议 深圳 5天/周 实习12个月
235 爬虫实习生 120-150/天 南京 5天/周 实习3个月
236 数据采集实习生 100-150/天 北京 4天/周 实习6个月
237 少儿编程讲师 400-500/天 北京 6天/周 实习12个月
238 信息安全工程师 150-300/天 广州 5天/周 实习8个月
五、知识总结
本篇教程向大家介绍了Series和DataFrame创建数据的多种方式,它们的的常用属性和方法,索引的构建,怎样更改和删除DataFrame数据等,详细介绍了一些方法的使用限制(比如去重方法),注意到了其中的一些坑,还结合了其他的库进行对比学习以此增强记忆,扩展技能链。我们最终的目的是为了实现代码的自动化和复现性,达到一题多解,多题一解的效果,从而提高办公效率
六、作者Info
Author:小鸿的摸鱼日常,Goal:让编程更有趣!
专注于算法、爬虫,网站,游戏开发,数据分析、自然语言处理,AI等,期待你的关注,让我们一起成长、一起Coding!
版权说明:本文禁止抄袭、转载 ,侵权必究!