JVM学习 GC垃圾回收机制 (堆内存结构、GC分类、四大垃圾回收算法)

作者简介:努力的clz ,一个努力编程的菜鸟
文章专栏:《JVM 学习笔记》 ,本专栏会专门记录博主在学习JVM中学习的知识点,以及遇到的问题。
文章详情: 本篇博客是学习 【狂神说Java】JVM快速入门篇 的学习笔记,关于GC垃圾回收机制 (堆内存结构、GC分类、四大垃圾回收算法)知识点的学习总结,由于这三个知识点的相互联系,所以放在一起进行描述介绍。
ʜᴀ͟ᴘ͟ᴘ͟ʏᴇᴠᴇʀʏᴅᴀʏ̆̈
一、堆
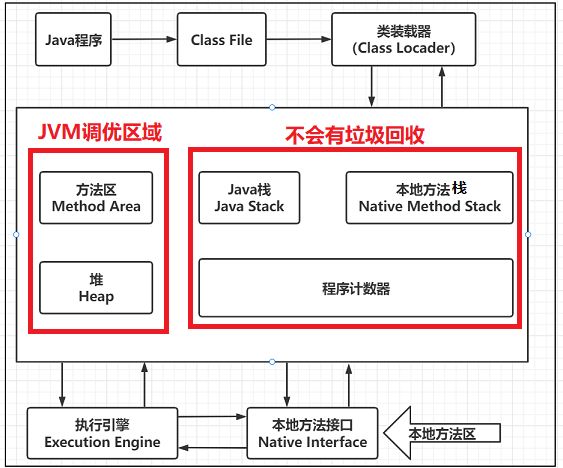
1. JVM体系结构图
简单回顾下
JVM体系结构图,后续将针对堆进行展开学习。
2. 堆
Heap 堆,一个JVM实例只存在一个堆内存,堆内存的大小是可以调节的;
类加载器读取了类文件后,需要 把类,方法,常变量放到堆内存中,保存所有引用类型的真实信息,以方便执行器执行;
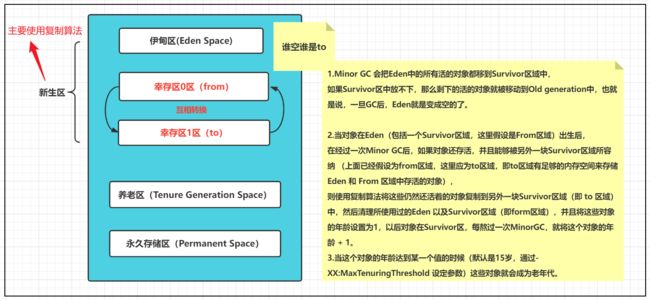
堆内存逻辑上分为三部分:新生,养老,永久 (元空间 : JDK8 以后名称)
GC垃圾回收主要是在 新生区和养老区,又分为 轻GC 和 重GC。
如果内存满了,OOM 堆内存不够,就会导致java.lang.OutOfMemoryError: Java heap space
| 堆内存结构 | |
|---|---|
| 新生区 Young Generation Space | Young/New |
| 养老区 Tenure generation space | Old/Tenure |
| 永久区 Permanent Space | Perm |
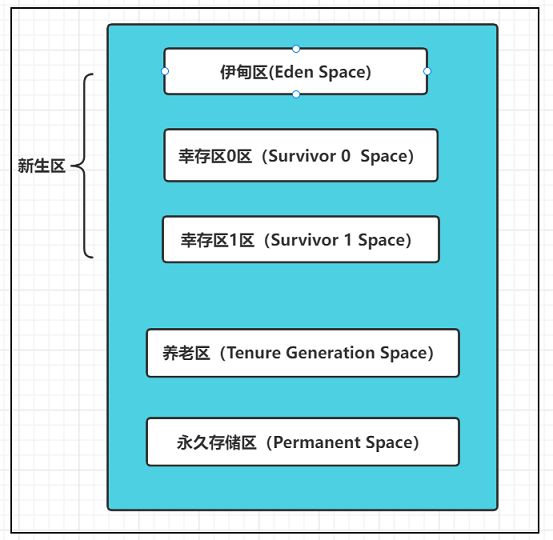
新生区:
新生区是类诞生,成长,消亡的区域,一个类在这里产生,应用,最后被垃圾回收器收集,结束生命。
新生区又分为两部分:伊甸区(Eden Space)和幸存者区(Survivor Space),所有的类都是在伊甸区被new出来的;
幸存区有两个:0区 和 1区;
当伊甸园的空间用完时,程序又需要创建对象,JVM的垃圾回收器将对伊甸园区进行垃圾回收 (Minor GC)。
养老区
将伊甸园中的剩余对象移动到幸存0区,若幸存0区也满了,再对该区进行垃圾回收,然后移动到1区,那如果1区也满了呢?
(这里幸存0区和1区是一个互相交替的过程)
就再移动到养老区,若养老区也满了,那么这个时候将产生 MajorGC(Full GC),进行养老区的内存清理,若养老区执行了Full GC 后发现依然无法进行对象的保存,就会 产生OOM异常“OutOfMemoryError ”。
如果出现 java.lang.OutOfMemoryError:java heap space异常,说明Java虚拟机的堆内存不够,原因如下:
1、Java虚拟机的堆内存设置不够,可以通过参数 -Xms(初始值大小),-Xmx(最大大小)来调整。
2、代码中创建了 大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)或者死循环了。
永久区(Perm):
永久存储区是一个常驻内存区域,用于存放JDK自身所携带的Class,Interface的元数据,也就是说它存储的是运行环境必须的类
信息,被装载进此区域的数据是不会被垃圾回收器回收掉的,关闭JVM才会释放此区域所占用的内存。
如果出现 java.lang.OutOfMemoryError:PermGen space ,说明是 Java虚拟机对永久代Perm内存设置不够。一般出现这种情况,
都是程序启动需要加载大量的第三方jar包。
例如:在一个Tomcat下部署了太多的应用。或者大量动态反射生成的类不断被加载,最终导致Perm区被占满。
Jdk1.6之前: 有永久代,常量池1.6在方法区
Jdk1.7: 有永久代,但是已经逐步 “去永久代”,常量池1.7在堆
Jdk1.8及之后:无永久代,常量池1.8在元空间

二、GC分类
熟悉堆的三区结构后,方可学习JVM垃圾回收机制。
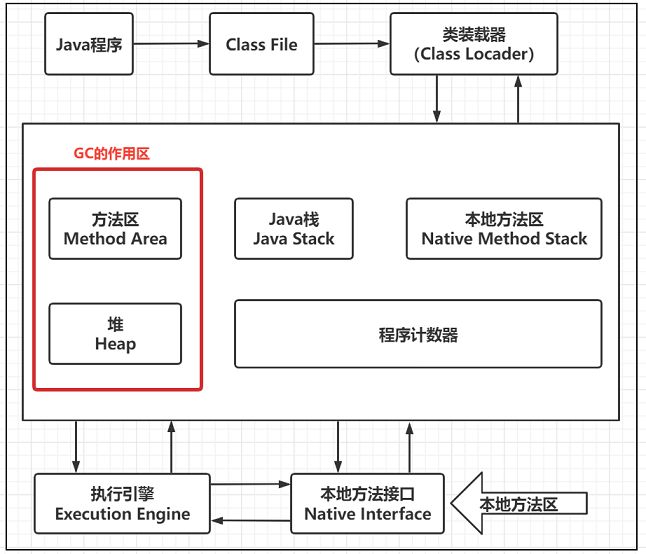
记住GC口诀: 分代收集算法
次数频繁Young区,次数较少Old区,基本不动Perm(永久区)区
JVM在GC时,并非每次都对上面三个内存区域一起回收的,大部分时候回收的都是新生代
GC安装回收的区域分成两种:普通GC(minor GC),全局GC(major GC or Full GC)
普通GC:只针对新生代的GC
全局GC:针对老年代的GC,偶尔伴随对新生代的GC以及对永久代的GC
三、GC四大算法
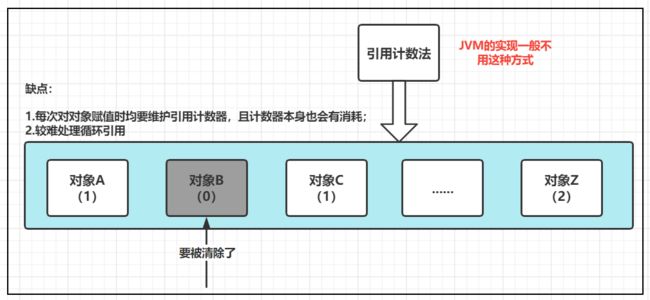
1. 引用计数法
每个对象有一个引用计数器,当对象被引用一次则计数器加1,当对象引用失效一次,则计数器减1;
对于计数器为0的对象意味着是垃圾对象,可以被GC回收。
目前虚拟机基本都是采用 可达性算法 ,从 GC Roots 作为起点开始搜索,那么整个连通图中的对象里边都是活对象,对于GC Roots 无法到达的对象变成了垃圾回收对象,随时可被GC回收。
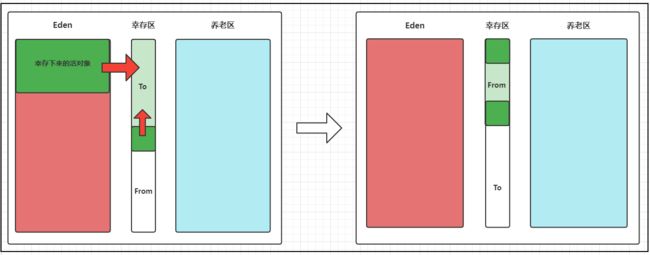
2. 复制算法
年轻代中使用的是
Minor GC,采用的就是复制算法 (Copying)
好处:没有内存碎片,坏处:浪费内存空间
劣势:
1、他浪费了一半的内存,这太要命了.
2、如果对象的存活率很高,我们可以极端一点,假设是100%存活,那么我们需要将所有对象都复制一遍,并将所有引用地址重置一遍。
复制这一工作所花费的时间,在对象存活率达到一定程度时,将会变的不可忽视,所以从以上描述不难看出。
复制算法要想使用,最起码对象的存活率要非常低才行,而且最重要的是,我们必须要克服50%的内存浪费。
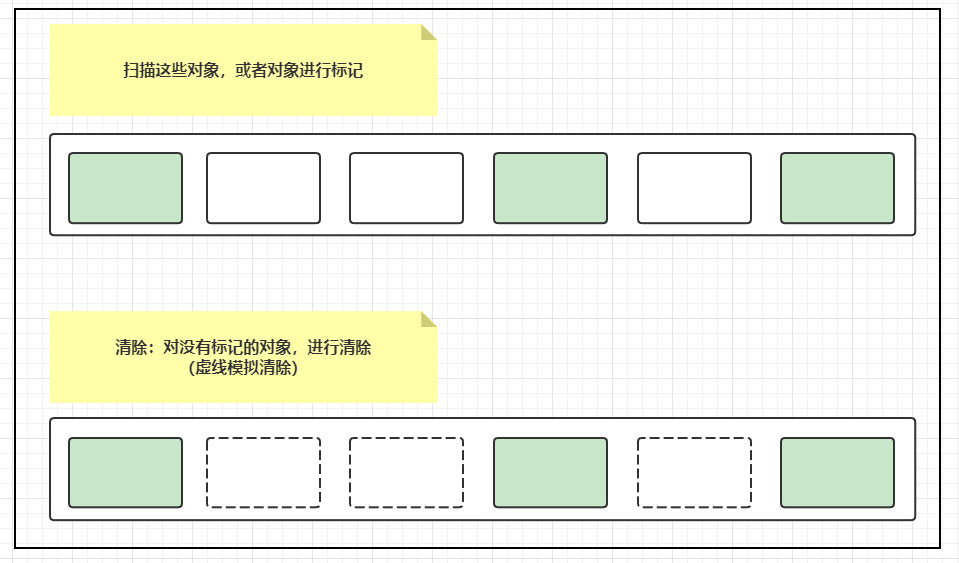
3. 标记清除(Mark-Sweep)
扫描(Mark):从根集合开始扫描,对存活的对象进行标记
清除(Sweep):扫描整个内存空间,回收未标记的对象,使用free-list记录可用区域
优点:不需要额外的空间;
缺点:两次扫描,验证浪费时间,会产生内存碎片;
4. 标记清除压缩算法(Mark-Sweep-Compact)
进一步优化——标记压缩(Mark-Compact)
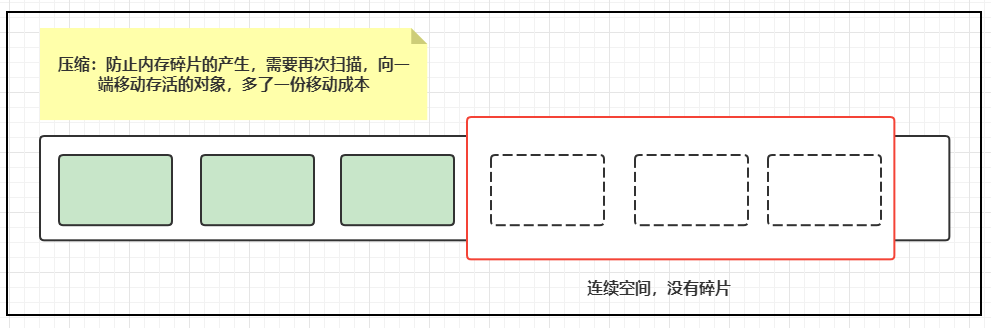
最终版本算法 —— 先标记清除几次,再进行压缩

总结
内存效率:
复制算法 > 标记清除算法 > 标记整理算法 (时间复杂度)
内存整齐度:复制算法 = 标记整理算法 > 标记清除算法
内存利用率:标记整理算法 = 标记清除算法 > 复制算法
可以看出,效率上来说,复制算法是当之无愧的老大,但是却浪费了太多内存,而为了尽量兼顾上面所提到的三个指标,标记整理算法相对来说更平滑一些 , 但是效率上依然不尽如人意,它比复制算法多了一个标记的阶段,又比标记清除多了一个整理内存的过程。
【问】难道就没有一种最优算法吗?
答案 : 无,没有最好的算法,只有最合适的算法 —— GC: 分代收集算法
年轻代:
- 存活率低
- 使用复制算法
老年代:
- 区域大,存活率高
- 标记清除(内存碎片不是太多的时候) + 标记压缩混合
点击可快速回到文章开头:文章顶部