【数据分析】从零开始带你了解商业数据分析模型——线性回归模型
【数据分析】从零开始带你了解商业数据分析模型——线性回归模型
1 摘要
随着数据导向型决策、数据科学、大数据分析等话题日益火热,各行各业都开始关注数据分析这个课题。
**数字化转型成了很多企业在未来十年的重大举措。**企业如何利用现有庞大的数据辅助决策,以及通过数据分析帮助企业盈利或削减开支成了越来越多部门关注的难题。
除了上述提到的行业内部的业务理解,从业人士对数据科学技术细节的理解,对数据建模的落地实施也成了当下的难点。
Altair的数据分析师将持续推出一系列文章,旨在帮助非科班从业人士了解常见的商业数据分析模型。
内容涵盖模型的基本介绍、优劣势分析、常见使用案例,以及如何在具体平台中实施相应的模型。
此文为系列文章的第一篇,从大家最耳熟能详的线性回归模型开始说起,并以Altair Knowledge Studio™为平台,介绍线性回归在实际中如何应用,给大家在实战中贡献一点参考。
2 线性回归模型
2.1 什么是回归
在讨论线性回归之前,我们先用一些篇幅来讨论什么是回归模型。
作为最基础的机器学习算法,回归模型最早发表于1805年,用以研究行星轨道距离太阳的距离。
随着后续两百多年的发展,回归模型的族群逐渐壮大。现在常见的族员有线性回归,逻辑回归,多项式回归,岭回归,套索回归等等。
简而言之,当想要研究自变量与因变量之间的关系时,回归模型往往是我们的首选。
那么,什么又叫做自变量,什么又是因变量呢?
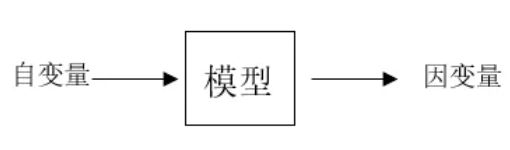
2.2 自变量与因变量
通常来说,自变量是指可以通过研究者主动操作而改变的因素或者条件,它可以视为使得因变量变化的原因。因变量是指会随着自变量变化,而变化的因素。
而模型则是通过自变量和因变量的历史数据,运用适当的统计算法所寻求出来的一套规律。通常在回归模型中,我们可以拥有多个自变量,但是因变量只能有一个。
这样的描述可能也不是特别清晰。不过没关系,我们可以通过下面的一个简单例子来辅助理解。
比如我们现在想要研究子女的身高和父母的身高是否存在一定的关系。我们想要寻找的关系,就是模型。父母的身高就是自变量,而子女的身高就是因变量。
2.3 一元线性回归
有了上述的基本介绍,我们接下来看看最简单的一种线性回归模型 – 一元线性回归模型,这里的一元指的是模型中只含有一个自变量。它的表达式可以写作:
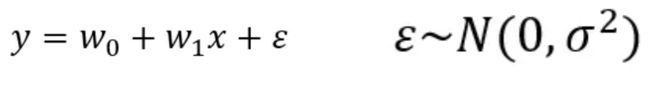
为方便理解,大家可以将 y 视为子女的身高(单位是cm),x 视为父亲的身高(单位是cm)。其中的 w0 与 w1 叫做模型的参数,也是我们需要通过统计算法寻找的值。
大家可以将参数理解为权重。比如当 w1 = 0.05 时,我们可以认为,如果父亲的身高每增加一厘米,子女的身高就可能增加 0. 05 厘米。相应的,w0 则类似于子女的保底身高。
因为孩子的身高还会取决于现今的生活环境和营养水平等因素,该参数则涵盖了非遗传角度考量的绝大多数因素。
最后的 ε 则是代表了统计学中的不确定性。它代表的含义是:即便拥有同样遗传因素,在相同条件下生长的两个孩子的身高大概率也会是不同的。
接下来我们借助一个简单的案例来了解这个过程。假如我们已知了6对父亲与子女身高的数据如下(父亲的身高, 子女的身高):
(160,162),(165,167),(170,168.5),(175,179),(180,182),(185,184).
将这些数据画作散点图,并对其进行任意拟合。我们可以发现这些点可以拟合出无数条可能的模型结果,分别由每条线所对应的不同的 w0 和 w1 组成。
不同的线所对应的样本模型为:
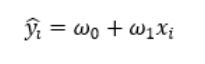
也各有不同。
如果从这些拟合结果中选出最优的那个结果,成了我们接下来的讨论话题。
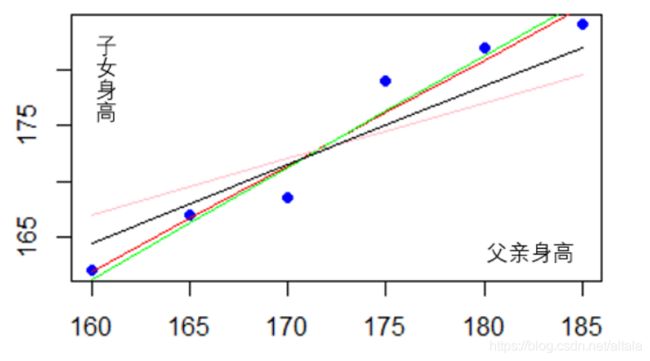
要知道哪一条结果模型拟合的最好,其中一个方法就是最小化预测出来的身高值和真实的身高值之差的平方和,数学表达式为:
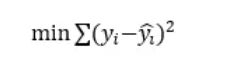
比如说,我们得出了其中一条拟合模型为:y = 10.6 + 0.95 * x。我们用(160,162)这组数据举例。其中的真实值yi 就是162,我们的预测值
则是 10.6 + 0.95*160 = 162.6。这组数据的差值平方就是0.36。全部的六组数据计算完成后,我们就可以得出这个拟合模型的差值平方和为23.75。
类似的,我们可以计算出别的拟合模型的差值平方和。最后该数值最小的拟合模型既是我们所寻找的最佳方案。
2.4 多元线性回归
我们上面所展示的案例,在实际生活之中基本不可能出现。因为它过于简单也过于理想化。不过它足够帮助大家了解清楚线性回归的基本概念了。
多元线性回归可以视为简单的一元线性回归的补充。同样拿上述的例子说明,子女的身高很可能也取决于母亲的身高,当地的平均身高,子女青春期的锻炼程度等因素。如果数据允许的话,我们可以用一个多元线性回归表达式来概述这个模型:
多元线性回归表达式的意义和寻找最佳拟合的方法和一元线性回归类似,我在此也就不过多赘述了。
2.5 线性回归的优劣分析和模型假设
虽然线性回归是最常见的一种回归模型,也是绝大多数科班生接触到的第一个统计模型,但是这并不代表了所有问题都适合用线性回归来解决,也不代表了任何数据都可以直接输入到线性回归之中。
线性回归的优点非常直接:
i.模型建立速度快。因为它并不包含复杂的算法过程,所以就算我们有庞大的数据量,线性回归也能够很快的拟合出最佳参数;
ii. 可解释性高。我们可以明确的指出线性回归里面包含的自变量,以及通过参数的大小解释不同自变量和因变量之间的线性关系。这是很多复杂模型所无法做到的。
然而线性回归的缺点更加直接:它只适用于分析自变量和因变量之间的线性关系。所以它不是适用于非线性关系之间的解析,且它仅适合处理因变量是连续型/数值型变量的数据。
与此同时,为了运用线性回归模型,我们还应确保我们的历史数据符合以下的假设条件:
i. 随机扰动项 εi 与自变量 xi 之间不相关,即
ii. 随机扰动项服从平均值为0的正态分布且互不相关
iii. 自变量之间不存在完全共线性,也就是说没有精确的线性关系。
2.6 线性回归的商业实用案例
作为最常见的模型之一,各行各业之中都可以找到线性回归的身影。
比如在快消行业,我们想要去研究特定的市场活动,价格变化,促销活动,季节气候等因素对某一商品的销量影响;
比如在体育竞技行业,我们想去研究球队,地区,身体因素,教练因素,赞助商状况对一位运动员比赛得分的影响;
再比如在银行信用卡行业,我们想去研究学历,收入情况,家庭情况,年龄等因素对信用卡持有人是否能够准时还款的影响。
随着算法模型的发展,线性回归在日常商业中的应用案例逐渐减少,取而代之的是逻辑回归,支持向量机,深度学习,决策树,随机森林等模型。我们也会在后续的文章中对这些模型进行一一讲解。
希望大家能够借住线性回归模型打开对数据分析建模的兴趣。随着讲解的深入,最好还能够帮助大家在自己的行业里面解决现有的问题,完成数字化转型的重要一步。
3 如何在Altair Knowledge Studio平台应用线性回归
3.1 为什么选择Altair Knowledge Studio
绝大多数的数据分析项目都是遵照着CRISP-DM的行业标准流程 (详情可见:《数据挖掘简介》)。
市面上常见的开源或商业数据分析软件大多需要从业人员掌握一定编程知识,且需要大量时间来编写代码并调试。
这里需要强调的就是Altair Knowledge Studio的强大之一在于无需编码,一切的操作都可以通过拖拽完成。
下面我会用一个例子来展示如果使用 Altair Knowledge Studio 来完成线性回归的建模操作。
这个例子从导入数据到最终模型预测大概需要10-15分钟的时间,操作简便,节约时间成本。
我们会用到的数据是一个有关鱼生长长度的数据集,其中包含了每条鱼的编号(index),年龄(age),生长水温(temp)和最终它的生长长度(length)。
我们的目的是去研究鱼的长度与年龄和水温是否存在线性关系,以及存在怎样的的线性关系。
3.2 Altair Knowledge Studio线性回归
3.2.1 数据导入
数据在本地以 Excel 的格式存在,我们在 Connect 栏 选择 Excel Import 节点,并双击点开。
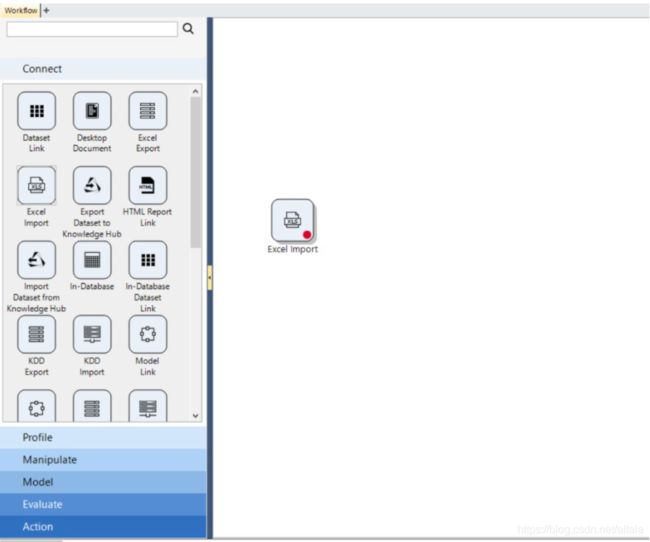
选择本地数据的所在路径,并为引入目标数据集命名。选择软件自动识别数据是否包含字节名称。设置好之后请点击 next。
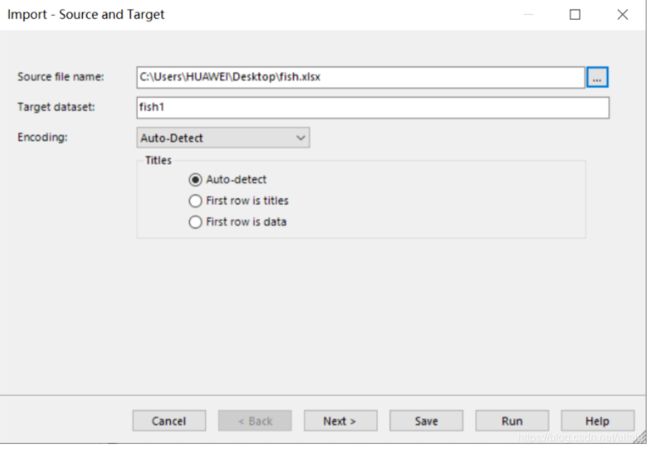
选择需要导入的字节。在这里,我们知道鱼的编码与鱼的长度是无关的,因此我们可以将这一列数据排除。
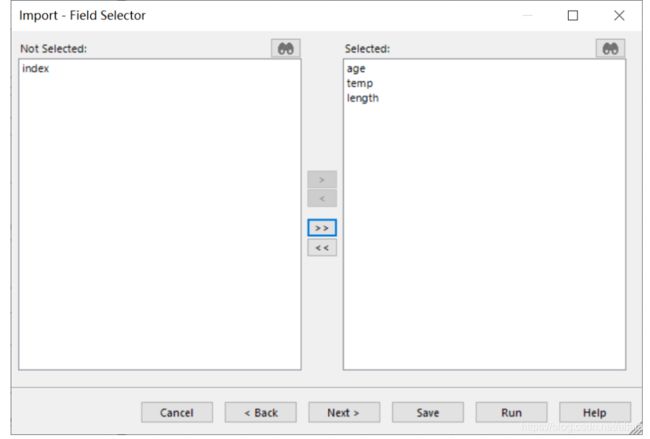
点击 Next,我们可以进一步确认每一个字节的数据类型,并且这里我们提供了预览该数据集的功能。
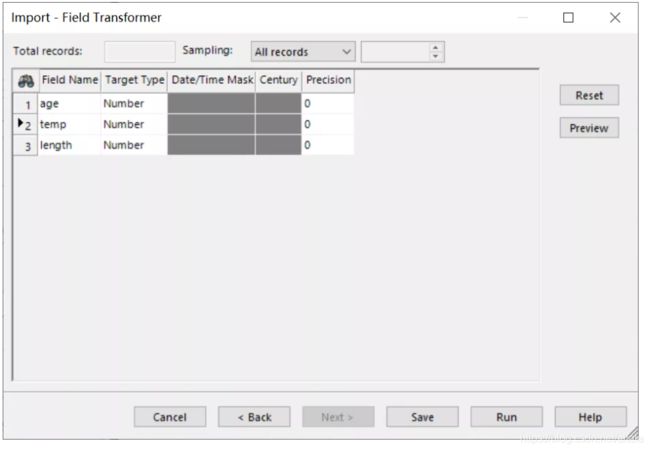
点击运行,我们就会看见一个绿色的,名为 fish的数据集自动生成了。
3.2.2 查看数据
双击 fish 数据集,我们可以看见在页面的最下方有很多不同的选项卡。它们涵盖了Altair Knowledge Studio数据画像功能的重要部分。
比如说,在 overview report 选项卡中,点击 calculate all,可计算出常见的统计指标。% of Missing Values 可以选择每个字节的缺失值比例。如下图所示,三个字节均没有缺失值:

又比如,correlations 选项卡中,可计算三个变量之间的相关系数,可以看一下 age、temp 与 length 的相关程度,便于后续选择模型。
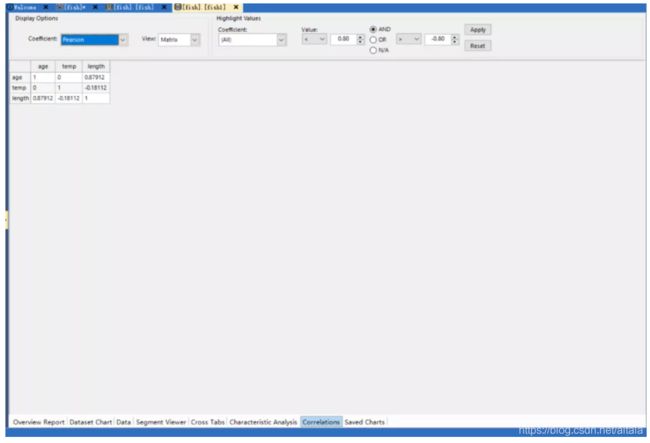
如果您想了解更多选项卡的功能展示,请直接联系[email protected] 获取更多资料。
3.2.3 异常值检验
因为线性回归模型对异常值极度敏感,极大异常值或极小异常值均会对模型造成不可预知的影响。检测数据是否存在异常值是建立每个线性回归模型的必须操作。
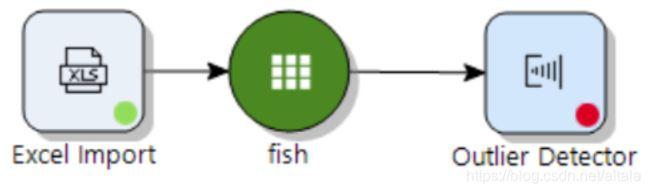
在 Altair Knowledge Studio 中,我们可以通过 Outlier Detector 节点完成此操作。在 Profile 栏中拖出 Outlier Detector, 并单机选中 fish 连线到 Outlier Detector。
双击该功能节点,我们可以看见目标数据和设定结果数据名。这里大家可以看见,我们提供了多种计算距离的方法。
根据不同的数据类型,和大家都这些检验方法的熟悉程度,大家可以自行选择不同算法。这里为了演示,我们接受默认算法。
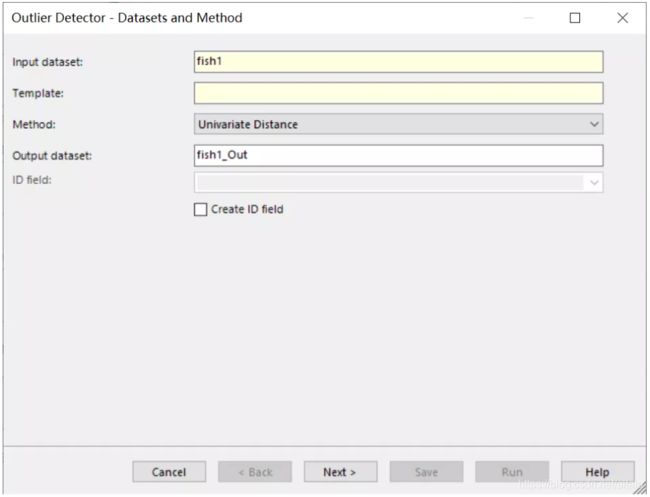
点击下一步,选择我们需要检测的字节。
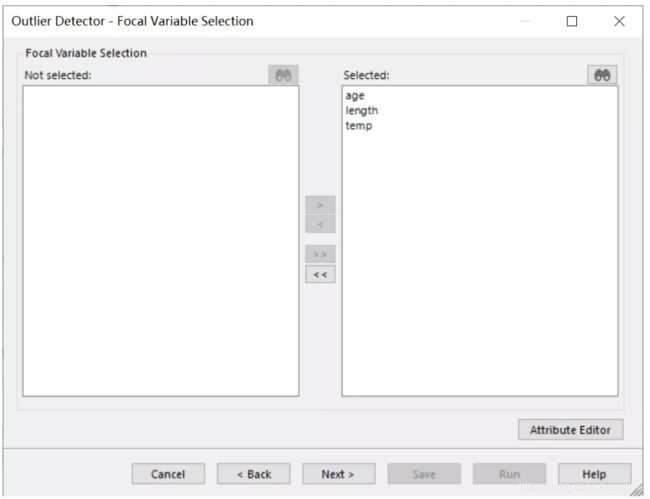
选好变量后,如果点击Next 再点击Run。同样的,这里会自动生成一个结果数据集。点开它,我们会发现,该数据中不存在异常值。
3.2.4 数据分箱
做预测分析时,我们通常会将数据集分成训练集和测试集。我们会用训练集来生成我们的模型结果,随后再用测试集来检测我们模型结果的好坏。
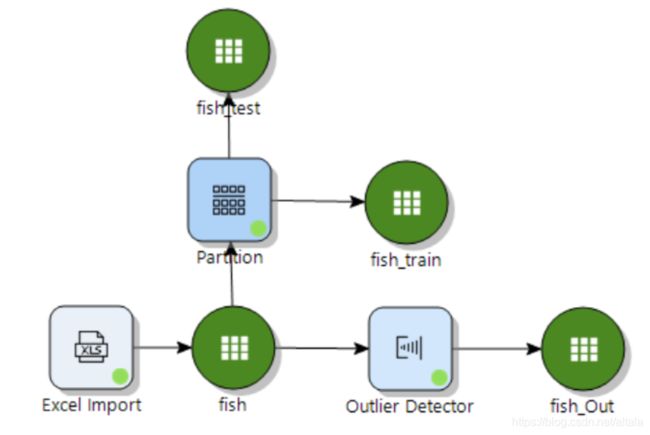
这里,我们可以通过 Manipulate 栏中的 Partition 节点 将原数据集随机抽取70%的样本作为训练集,30%的样本作为测试集。
将 fish 数据集与 partition 相连,双击点开,点击 add。可先添加训练集,完成后再次点击 add,添加测试集。完成后点击 run。会出现两个数据集。
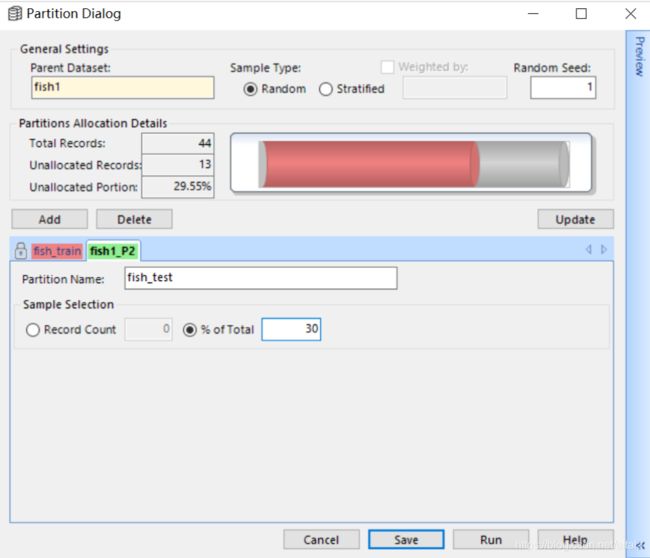
分箱结果会如下图所示:
3.2.5 拟合线性回归模型
我们基于训练集拟合线性回归模型。在models栏中选择linear regression。将fish_train数据集与该模型相连。
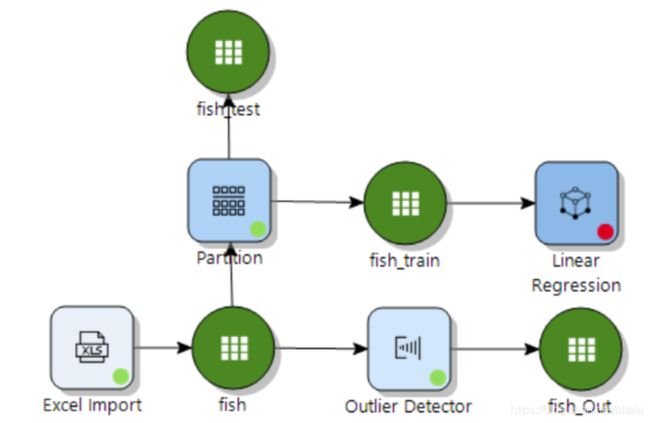
并双击Linear Regression模型节点:
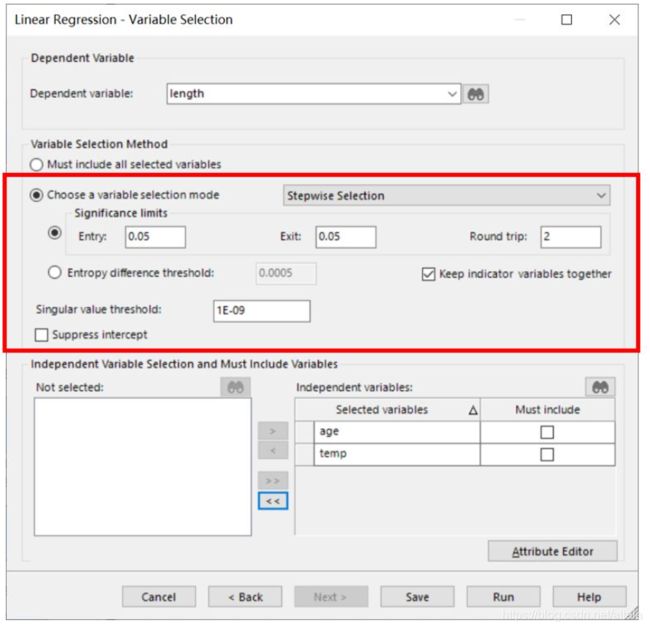
在 dependent variable 中选择我们的被解释变量。红框的部分可以进行重要变量的选择,按照解释变量对被解释变量的影响程度进行选择,可以将对被解释变量影响不显著的变量剔除。而且用逐步选择也可一定程度上缓解多重共线。
在 independent variable 中将解释变量选入,这里可以选择是否一定包含该变量。若没有,则会根据变量重要性选择。点击 run。双击点开linear regression,可查看回归报告。
在 output to view 中选择 currently selected sequence,可看模型最终拟合情况。读者也可在该栏中选择其他选项来看一下单变量的结果。
最终结果如下图:

该表可以看出模型的拟合情况,其中Generalized R^2=0.855,F值为82.845,认为模型拟合程度较好,被解释变量的85.5%都可由这两个解释变量来解释

这一张表是方差分析的表,同样可以看出结果还是不错的。

Independent Variable Statistics 中表示的是解释变量的情况,其中 Model Parameter 表示的是其回归系数,后面是对变量是否显著进行的检验。其中P值均小于0.05,我们认为年龄和温度对鱼的长度是有显著影响的。
多重共线性检验

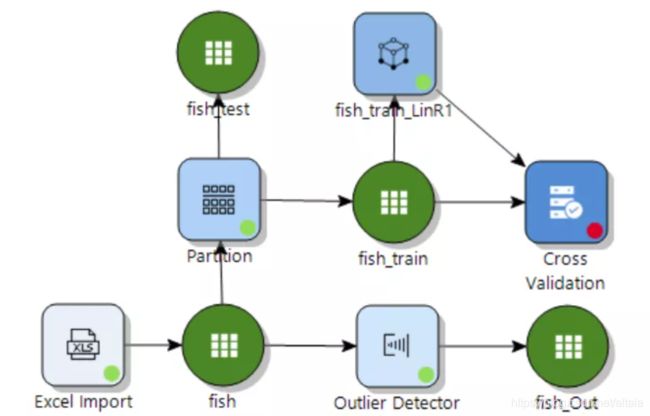
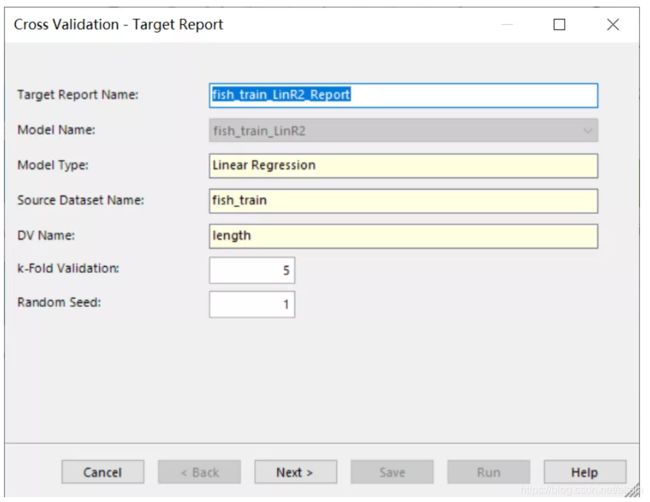
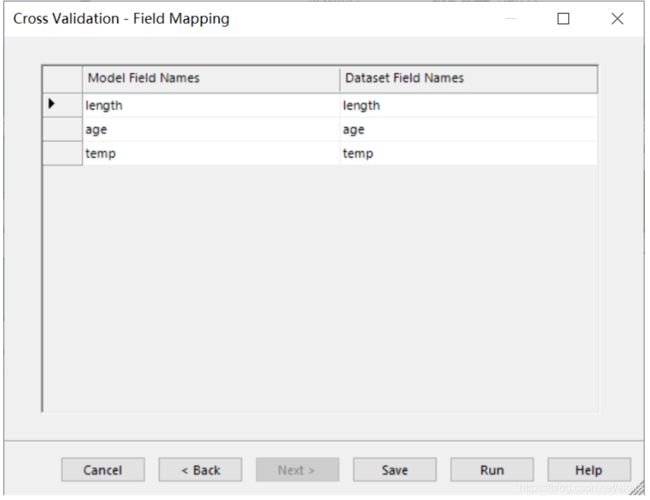
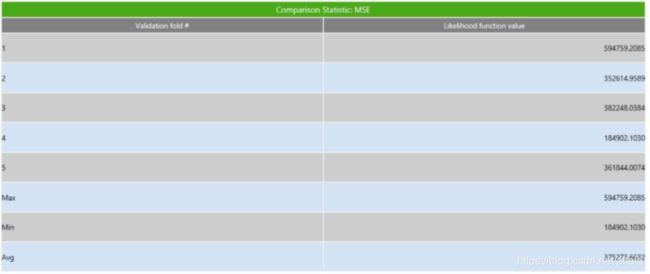
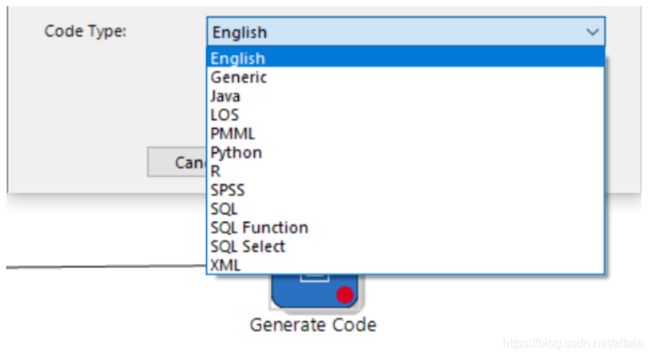
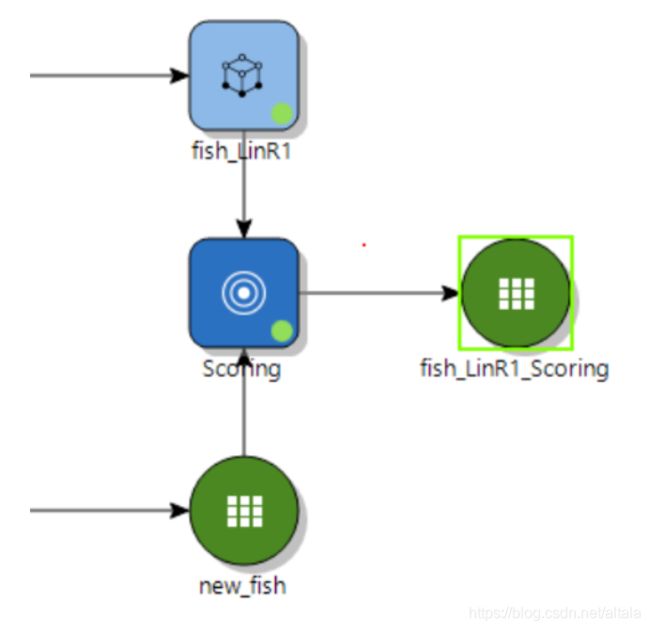
Variance Inflation Factors 是方差膨胀因子(VIF),VIF 越大,显示共线性越严重。经验判断方法表明:当0 这里年龄和温度的VIF均小于10,认为该模型不存在多重共线性。 最终模型结果为: 由于我们训练集只有41条数据。建模数据量的严重不足会出现模型过拟合问题。 过拟合指的是被创建出来的模型,仅仅在训练数据中变现良好,如果用在未知数据上,结果可能会很差。 这个时候我们可以通过交叉验证看是否存在过拟合现象。 交叉验证可以理解为:我们将原始数据复制成多个重复的样本,随后针对每一个样本做出分箱操作,建模并验证模型准确性。 通过这个步骤,我们可以让原始数据里面的每个记录都有机会作为建立模型的数据,与此同时,我们可以让每个记录都有机会作为验证模型的数据。 在 Evaluate 模块中选择 Cross Validation,将 fish_train 数据集和 linear regression 模型一起连过去,会发现该选项变蓝,双击点开。 这里 K-Fold validation 指的是我们准备复制多少次重复的样本,实施多少次类似的操作。这里我们选择默认值五次。随后点击 Next。 这张表可以修改各字节的名字。这里我们选择不修改。点击Run: 做完上述步骤后会出现一个html的report。双击点开: 从下面的结果途中,我们可以看到这五次验证的似然估计的均方误差(MSE)。发现每一次的MSE差别很大,说明之前模型拟合的不好,可能出现了过拟合现象。 接下来我们可能需要重新回到数据本身和模型本身,去调整参数,去更正数据再次建立别的预测模型。 假设我们已经找到了适合的模型,我们想要将模型结果落地,以供业务使用。Altair Knowledge Studio 主要提供了两种不同方案。 第一种是将模型的结果生成不同的代码。这些代码可以轻松的轻松的嵌入企业自身的IT系统中实现二次开发。我们可以从 Action 模块中选择 Generate Code 节点。 根据模型不同,企业自身的IT环境不同,我们可以最多从以下的代码中进行选择,常见的有Java,Python,SQL, PMML等。 第二种是,我们可以将新的数据导入到 Altair Knowledge Studio 平台中,并利用建立好的模型进行新数据打分。同样的,我们可以从 Action 模块中选择 Scoring 节点。 在结果数据集中,我们可以找到对每一个记录的模型预测值,以及相应的预测原因。 目前暂定下一篇会写逻辑回归模型,如果大家对数据分析或者模型感兴趣,关于数据分析这一块大家还对什么内容感兴趣,欢迎在文后留言交流,也欢迎大家提出意见和建议。 自 2018 年底进入中国市场以来,Altair 数据分析软件平台Altair Knowledge Works (前身为 Datawatch)一直致力于为用户提供易于访问和使用的数据平台,助力用户做出更创新、更明智的决策和洞见。 Altair Knowledge Works是一个完整的数据分析平台,涵盖数据准备、数据分析与预测以及数据可视化。 在以“数据”为中心的产品链或者解决方案中,Altair Knowledge Works 的各个产品都是以面向终端用户应用为宗旨。Knowledge Works与各主流数据库、数据应用,各种格式的数据文件、数据通信协议有直接的接口和支持。 遍布全球的100多个国家的上万家不同规模的单位或企业都使用Datawatch的产品与服务,其中包括《财富》100强中的93家。
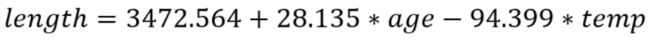
3.2.6 交叉验证
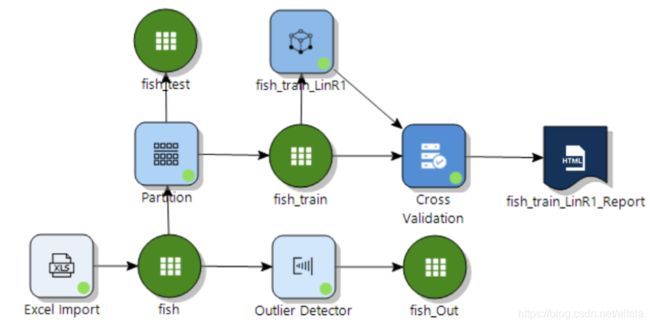
3.2.7 模型部署
4 结语
扫描下方二维码
可以免费申请试用Altair Knowledge Works:

5 关于Altair Knowledge Works™

长按扫码关注 Altair Knowledge Works
公司网址:www.altair.com.cn
商务咨询:[email protected]
技术咨询:[email protected]
试用链接:https://web.altair.com/zh/da-free-trial