MySQL—淘宝用户行为分析
文章目录
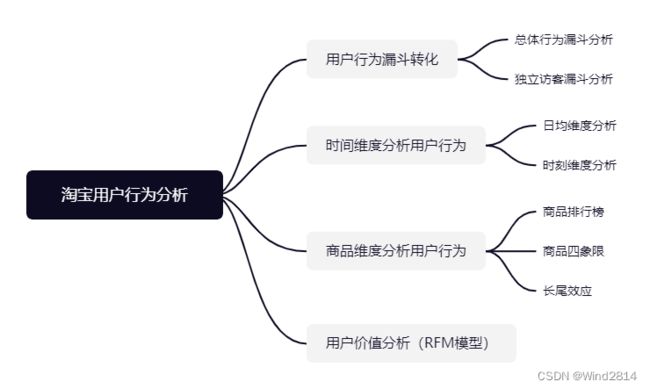
- 一、项目背景
- 二、结论先行
-
- 2.1用户行为漏斗转化分析
- 2.2时间维度分析用户行为
- 2.3商品维度分析用户行为
- 2.4RFM模型用户价值分析
- 三、数据分析
-
- 3.1数据来源
- 3.2数据说明
- 3.3字段说明
- 四、数据预处理
-
- 4.1导入数据
- 4.2选择子集
- 4.3列名重命名
- 4.4删除重复值
- 4.5缺失值处理
- 4.6一致化处理
- 4.7异常值处理
- 4.8检查数据
- 五、数据分析
-
- 5.1基于用户行为漏斗转化
-
- 5.1.1电商指标分析
-
- 5.1.1.1总体行为数据(uv、pv、pv/uv)
- 5.1.1.2复购率与跳失率
- 5.1.2用户行为模型漏斗转化
-
- 5.1.2.1总体行为漏斗分析
- 5.1.2.2独立访客漏斗分析
- 5.2从时间维度分析用户行为
-
- 5.2.1日均uv、pv、加购/收藏/成交量
- 5.2.2一天内uv、pv、加购/收藏/成交量
- 5.3从商品维度分析用户行为
-
- 5.3.1商品排行榜分析
-
- 5.3.1.1商品销量排行榜
- 5.3.1.2商品浏览排行榜
- 5.3.1.3商品销量与浏览量间的相关性分析
- 5.3.2商品四象限划分图
- 5.3.3互联网“长尾效应”分析
- 5.4基于RFM模型的用户价值分析
-
- 5.4.1R维度分析
- 5.4.2F维度分析
- 5.4.3用户分层
- 5.4.4RFM模型整体分析结果
一、项目背景
该数据初级分析报告跟据数据集已有字段分成四部分.
二、结论先行
2.1用户行为漏斗转化分析
- 综合复购率和跳失率来看,淘宝APP的用户忠诚度较高且内容质量高.
- 以独立用户分析维度,整体购买转化率较高,可满足大多数用户的需求,但整体用户行为漏斗分析点击转化率总体偏低.
优化方法:
- 重点维系用户忠诚度,可以吸引用户持续使用APP,从提高客服素质,简化购买流程,建立老客户社群,鼓励用户使用收藏,撰写评论等.最大程度地提高用户的参与感.
- 比对环节是提升重点,APP可以从推荐机制入手,以用户日常行为为依据,尽量精准推荐,并且需要匹配相关度更高的关键词,完善商品关键词设置制度和搜索算法,减少用户寻找商品的时间成本.
2.2时间维度分析用户行为
- 日期维度来看,周末或者周中的数据差异不是很大,但会受到购物节活动的影响,如第二个周末就双十二的影响导致用户点击和加购的行为数量明显增加.
- 时间维度上来看,一天内用户的各种行为数据差异较大.可作为参考制定营销策略.
优化方法
- 可以进一步扩大分析范畴,如以整年为单位进行环比分析,标注出各个比较大的购物节,重点关心购物节前后的用户行为数量变化,同时对每周末进行比较,分析购物节推广活动安排在周末/非周末对用户行为的影响.
- 用户的各种行为活跃高峰期都在晚间的21点左右,可以考虑在这个时间做一些力度较大的优惠活动,也可以将转化行为的时间安排在这个时间段,如直播带货等来进行用户的活跃度提升及转化.用户在晚间的行为更偏向于浏览商品,白天10点左右购买行为的比率较高,可以根据这个特性在晚间对商品进行宣传,然后在白天进行转化.
2.3商品维度分析用户行为
- 购买量与浏览量的相关性比较差.淘宝APP符合长尾效应,主要营收靠长尾效应的累积效应,而并非某种"爆款商品".
优化方法
- 根据四象限划分图的分析,应重点提升第二象限及第三象限的商品.
-
针对第二象限商品,需要分析商品特征与用户画像,收集该类商品的个性化信息和用户特征,分析 该商品是否属于垂直刚需商品,是否存在特定的消费群体.
- 若存在,商家可以针对该类用户推测出特定活动,做到精准推送,或建立该类商品受众的专属社群,提供用户交流平台,进一步增加用户粘性.
- 若不存在,则商家应该加大宣传力度,多做宣传,增加商品权重,设置高频率搜索关键词,设计亮眼的宣传图等,增加用户的浏览量,销量也会随之提升.
-
针对第三象限商品,可以尝试提高商品的曝光量,若提高商品曝光量后商品的销量还是比较低迷,就需要考虑商品本身是否是用户真正需要的,效果不好的商品也可以直接优化掉.
- 对于B端商家来说,也可以打造爆款商品来减少商品种类繁多的运营及库存成本.针对销量排行榜前面的商品可以增加其曝光率推荐率,在用户搜索时进行优先展现.
2.4RFM模型用户价值分析
- 对用户群体进行划分,挽留用户,易流失用户占比较高,发展用户,忠诚用户占比较少,可以根据不同的标签采取不同的运营策略.
优化方法
- 忠诚用户:重点关注,制定专属的运营策略进行维护,应该提高满意度,增加留存,保证用户粘性.
- 易流失用户和发展用户:可以举行折扣活动或捆绑销售来增加用户的购买频率,定期推送消息,对用户进行召回.
- 挽留用户占比最高,需要关注他们的购物习性,发掘潜在价值,定时促活,做到精准化营销,以提升他们的购买意愿,提升转化率.
三、数据分析
3.1数据来源
阿里云天池[数据集-阿里云天池 (aliyun.com)]
3.2数据说明
本数据集共有100万条左右数据,数据为淘宝APP2017年11月25日至12月3日期的用户行为数据,共计5列字段.
3.3字段说明
| 列名称 | 说明 |
|---|---|
| userID | 整数类型,序列化后的用户ID |
| itemID | 整数类型,序列化后的商品ID |
| categoryID | 整数类型,序列化后的商品所属类目ID |
| behaviour | 字符串,用户行为类别,包括(‘pv’,‘buy’,‘cart’,‘fav’) |
| Timestamp | 行为发生的时间戳 |
| 行为类别 | 说明 |
|---|---|
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
四、数据预处理
4.1导入数据
使用navicat导入数据.
新建数据库,导入外部数据
CREATE DATABASE IF not EXISTS 淘宝用户行为分析
4.2选择子集
查询发现导入的数据有1亿条,这次是取100w条进行分析,所以对100w以后的数据进行删除(由于版权问题使用navicat选择导入100W条数据,后使用vscode插件进行后续数据处理与分析)
导入的数据中第一个字段有重复值,所以增加一个ID标识列并设置为主键,便于删除.
#userID字段列含重复值,增加ID列设置主键,方便删除
ALTER TABLE `淘宝用户行为分析` ADD COLUMN
id INT(8) PRIMARY KEY AUTO_INCREMENT;
#筛选前100万条数据
DELETE FROM `淘宝用户行为分析` WHERE id>1000000;
#查看数据是否为100万条
SELECT COUNT(*) FROM `淘宝用户行为分析`;
#查看前二十行的表结构
SELECT * FROM `淘宝用户行为分析` LIMIT 20;
4.3列名重命名
使用表修改语法对列名与数据类型进行修改.
alter table `淘宝用户行为分析` change column 1 userID varchar;
alter table `淘宝用户行为分析` change column 2268318 itemID varchar;
alter table `淘宝用户行为分析` change column 2520377 categoryID varchar;
alter table `淘宝用户行为分析` change column pv behaviour varchar;
alter table `淘宝用户行为分析` change column 1511544070 Timestamp varchar;
4.4删除重复值
#检查是否存在重复值
SELECT
(SELECT COUNT(*)
FROM `淘宝用户行为分析`
GROUP BY userID,itemID,categoryID,behaviour,`Timestamp`
HAVING COUNT(*)>1)
AS 查询结果;
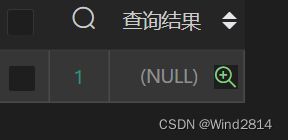
查询结果不存在重复值.
4.5缺失值处理
#检查个字段数据量是否相等
SELECT
COUNT(`userID`),COUNT(`itemID`),COUNT(`categoryID`),COUNT(`behaviour`),COUNT(TIMESTAMP),COUNT(`id`)
FROM `淘宝用户行为分析`;

各字段数量相等,不存在缺失值.
4.6一致化处理
目前时间列可读性较差,需要将其分为时间,日期,小时三列.
#利用FROM_UNIXTIME函数创建日期时间字段
ALTER TABLE `淘宝用户行为分析` ADD COLUMN `Datetime` TIMESTAMP(0) NULL;
UPDATE `淘宝用户行为分析` SET `Datetime`=FROM_UNIXTIME(`Timestamp`);
#创建日期字段
ALTER TABLE `淘宝用户行为分析` ADD COLUMN `Date` CHAR(10);
UPDATE `淘宝用户行为分析` SET `Date`=FROM_UNIXTIME(`Timestamp`,'%Y-%m-%d');
#创建时间字段
ALTER TABLE `淘宝用户行为分析` ADD COLUMN `Time` CHAR(3);
UPDATE `淘宝用户行为分析` SET `Time`= SUBSTR(`Datetime`,12,2);
4.7异常值处理
#查看时间是否在所需范围内(即2017年11月25日至2017年12月3日之间)
SELECT MAX(`Datetime`),MIN(`Datetime`)FROM `淘宝用户行为分析`;
#删除所需时间范围外的数据
DELETE FROM `淘宝用户行为分析` WHERE `Date`<'2017-11-25' OR `Date`>'2017-12-03';
4.8检查数据
#取前100条数据对整理后的数据进行检查
SELECT * FROM `淘宝用户行为分析` LIMIT 100;
五、数据分析
5.1基于用户行为漏斗转化
使用vscode进行数据分析,PowerBI进行数据转化.
5.1.1电商指标分析
5.1.1.1总体行为数据(uv、pv、pv/uv)
#整体数据
SELECT COUNT(DISTINCT `userID`) uv,
SUM(IF(`behaviour`='pv',1,0)) 点击,
SUM(IF(`behaviour`='buy',1,0)) 购买,
SUM(IF(`behaviour`='cart',1,0)) 加购,
SUM(IF(`behaviour`='fav',1,0)) 收藏,
ROUND(SUM(IF(`behaviour`='pv',1,0))/COUNT(DISTINCT `userID`)) 'pv/uv'
FROM `淘宝用户行为分析`;

可以得出:
访问用户数uv=9739
页面总点击量pv=895636
平均每人页面访问量pv/uv=92
5.1.1.2复购率与跳失率
复购率:在某时间窗口内重复消费用户(消费两次及以上的用户)在总消费用户中占比(按天去重).
跳失率:(顾客通过相应入口进入)只浏览一个页面就离开的访问次数 / 该页面的全部访问次数.
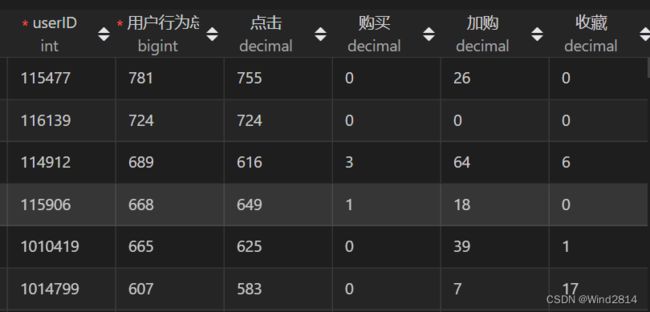
因为后面还会用到以用户ID分组的用户行为数据,所以先创建一个视图方便后续查询.
#以userID为分组的'用户行为数据'视图会用到userID、行为总数、各行为的数量等字段,并按照行为总数降序排列.
CREATE VIEW 用户行为数据 AS
SELECT `userID`,
COUNT(`behaviour`) 用户行为总数,
SUM(IF(`behaviour`='pv',1,0)) 点击,
SUM(IF(`behaviour`='buy',1,0)) 购买,
SUM(IF(`behaviour`='cart',1,0)) 加购,
SUM(IF(`behaviour`='fav',1,0)) 收藏
FROM `淘宝用户行为分析`
GROUP BY `userID`
ORDER BY 用户行为总数 DESC;
SELECT * FROM `用户行为数据`;
- 复购率
#复购率=购买1次以上的人数(复购人数)/有购买行为的总人数
SELECT SUM(IF(`购买`>1,1,0)) 复购人数,
SUM(IF(`购买`>0,1,0)) 购买总人数,
CONCAT(
ROUND(SUM(IF(`购买`>1,1,0))*100/SUM(IF(`购买`>0,1,0)),2)
,'%') 复购率
FROM 用户行为数据;

复购率取两位小数,使用concat函数与百分号连接提高可读性
可看到复购率高达66.21%,得出结论:淘宝用户忠诚度较高.
- 跳失率
即只有一个行为的用户.跳出率可以反映用户对APP\网站内容的认可程度,或者说网站\APP是否对用户有吸引力.网站\APP的内容是否能够对用户有所帮助留住用户也直接可以在跳出率中看出来,所以跳出率是衡量网站\APP内容质量的重要标准.SELECT COUNT(userID) AS 仅访问一次的用户数 FROM `用户行为数据` WHERE 用户行为总数=1;

查询可得在统计区间内(9天)仅访问APP一次的用户数量为0,即跳失率为零,说明商品内容、推荐机制等对用户有比较强的吸引力.
综合复购率和跳失率来看,淘宝APP的用户忠诚度较高,且内容质量高,可以吸引用户持续使用APP,可以重视用户关系,进一步培养用户忠诚度.
5.1.2用户行为模型漏斗转化
漏斗分析是一套流程式数据分析,它能够科学反映用户行为状态以及从起点到终点各阶段用户转化率情况的重要分析模型,可以帮助决策者找到用户流失的原因,以提升用户量、活跃度、留存率,并提升数据分析与决策的科学性等.
5.1.2.1总体行为漏斗分析
电商行业常用漏斗模型:APP/网站首页-商品详情页-添加购物车-购物车结算-核对订单-提交订单-选择支付方式-支付.
但是此次数据集只有商品详情页(pv)、加入购物车(cart)和支付(buy),
所以漏斗简化为点击-加购+收藏(都属于购买前阶段,所以合并为一个阶段)-购买
SELECT `behaviour`,COUNT(*) FROM `淘宝用户行为分析`GROUP BY`behaviour`;
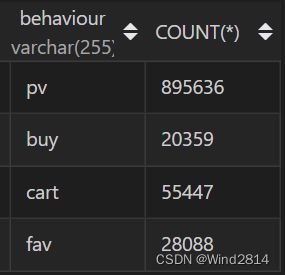
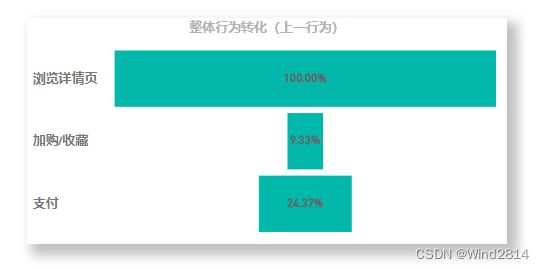

用户浏览详情页后,点击加购或者收藏的百分比在9.3%左右,最后支付的百分比为2.3%左右.
第二步到第三部剩余四分之一左右,但第一步到第二步仅剩9.3%,说明用户在浏览详情页以后大量流失.
5.1.2.2独立访客漏斗分析
SELECT
SUM(IF(`点击`>0,1,0)) 点击用户数,
SUM(IF(`加购`>0,1,0)) 加购用户数,
SUM(IF(`收藏`>0,1,0)) 收藏用户数,
SUM(IF(`购买`>0,1,0)) 购买用户数
FROM `用户行为数据`;
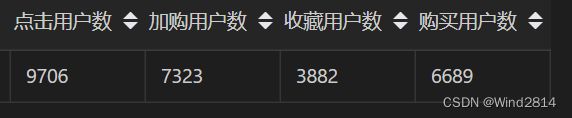

可以看出以独立用户为分析维度,用户并没有在点击以后大量流失,有75%的用户选择了加购,40%的用户选择了收藏,且到最后有68.92%的用户最后选择了支付,整体的购买转化率较高,说明APP整体生态健康,可以满足大多数用户的需求.
综合上面两个分析来看,造成总体从PV到有购买意向只有9.3%的原因是:
用户在产生购买意向之前会对商品进行大量的比对,在进行比对后才会产生购买意向,最后进行购买.所以比对环节是提升重点,APP可以从推荐机制入手,以用户日常行为为依据,尽量精准推荐,并且需要匹配相关度更高的关键词,完善商品关键词设置制度和搜索算法,减少用户寻找商品的时间成本.
5.2从时间维度分析用户行为
5.2.1日均uv、pv、加购/收藏/成交量
SELECT `Date`,
COUNT(DISTINCT `userID`) 每日用户数,
SUM(IF(`behaviour`='pv',1,0)) 点击,
SUM(IF(`behaviour`='cart',1,0)) 加购,
SUM(IF(`behaviour`='fav',1,0)) 收藏,
SUM(IF(`behaviour`='buy',1,0)) 购买 FROM `淘宝用户行为分析`
GROUP BY`Date`;
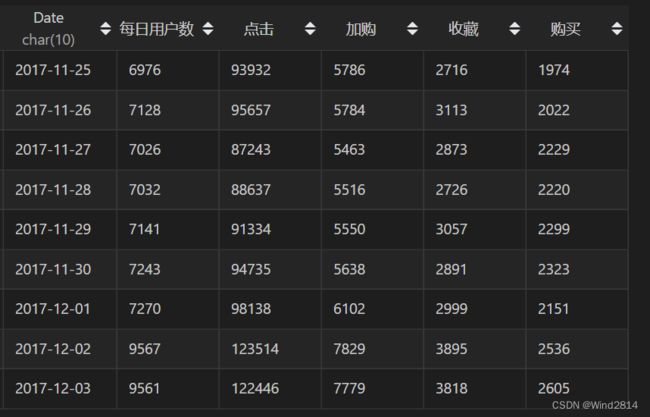
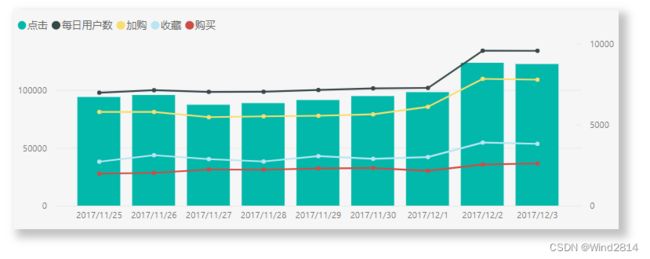
由上面的图可以看出,在11.25~12.1期间所有数据波动都比较小,表现平稳.
在12.2 ~12.3有小幅度的增加,查询日历可以发现这两天为周末,但11.25 ~26同为周末,所以第二个周末的增幅与周末的相关度较小,再看折线图,收藏与加购的增幅较为明显,所以12.2 ~12.3的用户行为增加,与淘宝的双十二预热有关,预热会使购买前置动作的收藏与加购行为量出现增长.
5.2.2一天内uv、pv、加购/收藏/成交量
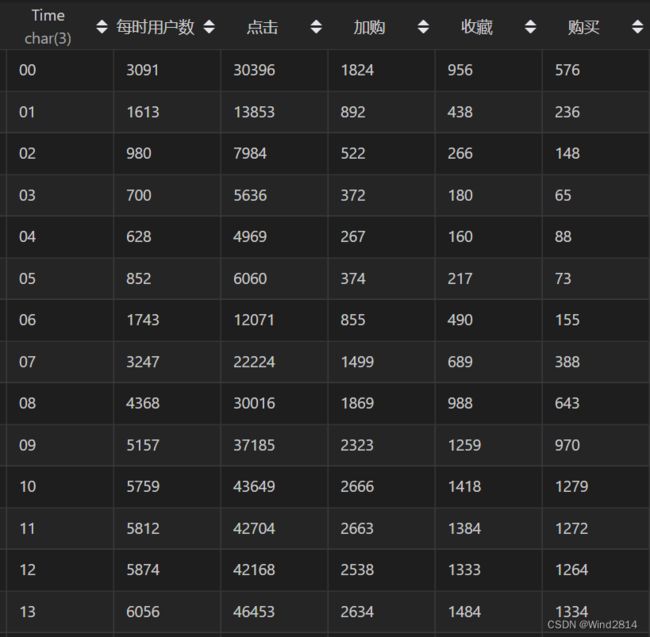
SELECT `Time`,
COUNT(DISTINCT `userID`) 每时用户数,
SUM(IF(`behaviour`='pv',1,0)) 点击,
SUM(IF(`behaviour`='cart',1,0)) 加购,
SUM(IF(`behaviour`='fav',1,0)) 收藏,
SUM(IF(`behaviour`='buy',1,0)) 购买
FROM `淘宝用户行为分析`
GROUP BY `Time`;
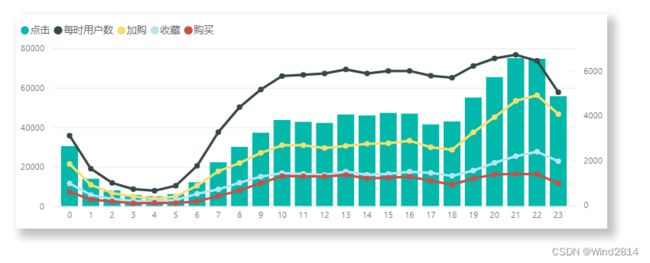
由上图可知,每天的0点到3点,各项指标都会快速降低,在4点左右降到一天内的最低值.从5点开始用户活跃度快速上升,从10点至18点用户活跃度平稳但是在12点和17点有小幅度下降(符合上班、上学人群作息规律),在18点以后又会有一个上升,持续到23点左右,在21点左右达到一天内达到峰值.
可以考虑在20~22点做一些力度较大的优惠活动以提高转化率,在制定运营策略时也可以考虑在这个时间段进行直播带货、拼单促销等活动.此外可以发现在晚间用户更偏向于进行浏览,白天10点左右时进行购买行为的比率较高,也可以根据这个特性在晚间更倾向于进行商品宣传活动,白天进行转化活动.
5.3从商品维度分析用户行为
5.3.1商品排行榜分析
5.3.1.1商品销量排行榜
#查询所有商品总销量
SELECT COUNT(`behaviour`) 总销量
FROM `淘宝用户行为分析`
WHERE`behaviour`='buy';
#查询销量前十的商品
CREATE VIEW 销售排行榜 AS
SELECT `itemID`,
SUM(IF(`behaviour`='buy',1,0)) 销量
FROM `淘宝用户行为分析`
GROUP BY`itemID`
ORDER BY SUM(IF(`behaviour`='buy',1,0)) DESC
LIMIT 10;
select * from 销售排行榜;
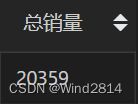
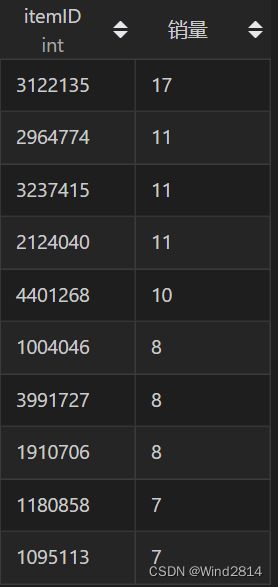
第一条语句得知所有商品总销量为20359,但是由排行榜得知最高购买量也只有17件,还有5件销量没超过10,可见没有爆款商品,,靠的还是商品的多样化满足客户需求,所以应将注意力放在如何增加商品的多样性,而非打造爆款商品.
5.3.1.2商品浏览排行榜
CREATE VIEW 浏览排行榜 AS
SELECT `itemID`,
SUM(IF(`behaviour`='pv',1,0)) 浏览量
FROM `淘宝用户行为分析`
GROUP BY`itemID`
ORDER BY SUM(IF(`behaviour`='pv',1,0)) DESC
LIMIT 10;
select * from 浏览排行榜;
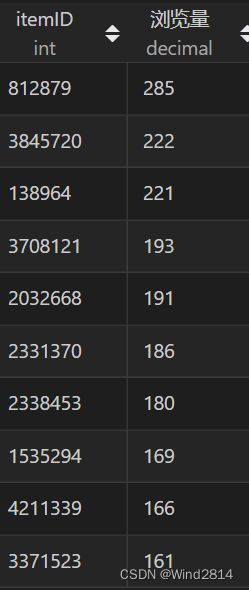
5.3.1.3商品销量与浏览量间的相关性分析
#对销售排行与浏览量排行视图进行左连接,查看相关性
SELECT a.itemID,a.销量,b.浏览量
FROM 销售排行榜 a
LEFT JOIN 浏览排行榜 b
ON
a.itemID=b.itemID;
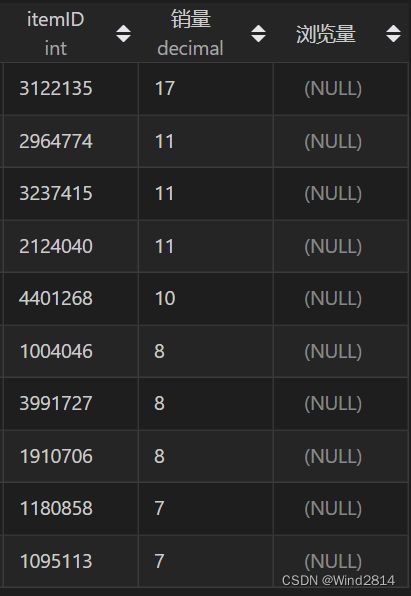
可以看到购买量前十的商品的浏览量都没有排到前十,说明购买量与浏览量的相关性比较差,销量高的产品不一定浏览量就会高.
5.3.2商品四象限划分图
以浏览量和销量作为分析维度来对商品进行四象限划分,由于商品数量过多,所以查询浏览量前500的商品以及对应销售量.
SELECT itemID 商品品类,
SUM(IF(`behaviour`='pv',1,0)) 浏览量,
SUM(IF(`behaviour`='buy',1,0)) 销售量
FROM `淘宝用户行为分析`
GROUP BY`itemID`
ORDER BY SUM(IF(`behaviour`='pv',1,0)) DESC
LIMIT 500;
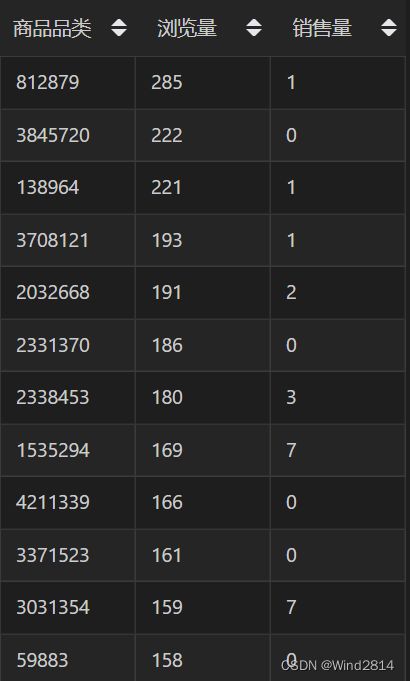
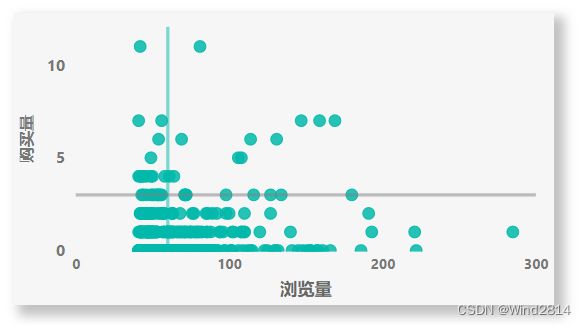
- 处于第Ⅰ象限的商品:此类商品的浏览量与销量都处于较高的水平,属于比较受用户欢迎的商品
优化方法:目的为提高此类商品的曝光量,平台加大推荐力度,从而提高浏览量,发掘潜在用户销量也会随之提升. - 处于第Ⅱ象限的商品:此类商品的销量高,但是浏览量低,说明该类商品
-
属于垂直领域,有特定受众会直接进行性购买,用户的购买目标明确.
-
商品本身转化率应该较高,但是曝光量过少,商家宣传力度小,用户接触到该类商品的渠道较少.
优化方法:需要分析商品特征与用户画像,收集该类商品的个性化信息和用户特征,分析该商品是否属于垂直刚需商品,是否存在特定的消费群体.
-
若存在,商家可以针对该类用户推测出特定活动,做到精准推送,或建立该类商品受众的专属社群,提供用户交流平台,进一步增加用户粘性.
-
若不存在,则商家应该加大宣传力度,多做宣传,增加商品权重,设置高频率搜索关键词,设计亮眼的宣传图等,增加用户的浏览量,销量也会随之提升.
-
处于第Ⅲ象限的商品:浏览量和销量都比较低,说明用户对商品不感兴趣,需要考虑流量入口和商品本身两方面的问题
优化方法
- 流量问题:是否对商品的宣传力度过小,用户没有渠道点进来此类商品?可以尝试提高商品的曝光量.
- 若提高商品曝光量后商品的销量还是比较低迷,就需要考虑商品本身是否是用户真正需要的,效果不好的商品也可以直接优化掉.
- 处于第Ⅳ象限的商品:商品浏览量高,但是销量低,说明商品整体的转化率很低,也可以从一下几方面分析问题所在
-
目标人群送达:可能是商品本身的宣传非常有吸引力,但是指向性不够明 确,导致很多非目标用户点击商品,但是没有进行购买.
-
商品定价:商品定价过高,同类可替代的高性价比商品太多,用户就会转向其他同类商品.
-
商品详情页、客服及评论区:用户无法从详情页和客服得到需要的的商品详细信息,或者商品评论有比较扎眼的差评,导致用户退出购买.
-
购买流程:可能是优惠券使用方式复杂,商品凑单购买流程复杂,让用户放弃购买.
优化方法:根据上述原因使用A/B测试、调研等方法,找出结果即可.
5.3.3互联网“长尾效应”分析
2004年10月,美国《连线》杂志主编克里斯·安德森(ChrisAnderson)他的文章中第一次提出长尾(Long Tail)理论,他告诉读者:商业和文化的未来不在热门产品,不在传统需求曲线的头部,而在于需求曲线中那条无穷长的尾巴.
WITH a AS
(SELECT DISTINCT `itemID` 商品品类,COUNT(`behaviour`) 购买次数
FROM `淘宝用户行为分析`
WHERE`behaviour`='buy'
GROUP BY `itemID`)
SELECT `购买次数`,
COUNT('商品品类')商品量
FROM a
GROUP BY `购买次数`
ORDER BY`购买次数`;
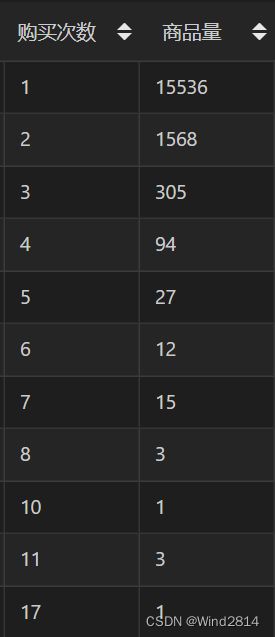
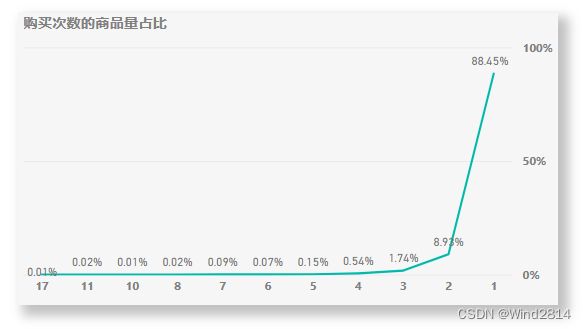
将数据可视化呈现发现购买一件商品的比例占到了88.45%,说明淘宝APP符合长尾效应,主要营收靠长尾效应的累积效应,而并非某种"爆款商品".
5.4基于RFM模型的用户价值分析
由于数据中没有金额字段,所以此次分析从R、F两个维度来进行分析,首先需要分别对两个维度进行统计,制定分级标准,然后进行打分,最终按照综合分数对用户分层.
5.4.1R维度分析
整个数据集时间区间为9天,每三天为一个区间.
0 ~ 2天为3;3 ~ 5为2;6~8为1
#由于后续需要再次用到数据所以在这里建立一个视图
CREATE VIEW r值 AS
SELECT `userID`,
MIN(DATEDIFF('2017-12-03',`Date`)) 时间间隔
FROM `淘宝用户行为分析`
WHERE`behaviour`='buy'
GROUP BY `userID`;
SELECT a.R,COUNT(a.R)
FROM
(
SELECT
(CASE WHEN `时间间隔`BETWEEN 0 AND 2 THEN 3
WHEN`时间间隔`BETWEEN 3 AND 5 THEN 2
ELSE 1 END ) R
FROM`r值`
) a
GROUP BY a.R
ORDER BY a.R;
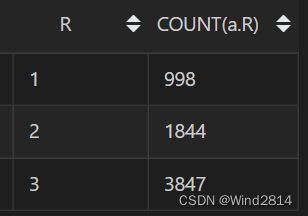
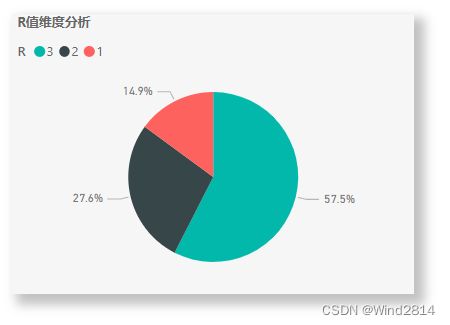
有超过半数的客户会在购买第二天后就再进行购买,说明淘宝APP现在已经有比较好的用户粘性.
5.4.2F维度分析
CREATE VIEW f值 AS
SELECT `userID`,
COUNT(`userID`) 购买次数
FROM `淘宝用户行为分析`
WHERE`behaviour`='buy'
GROUP BY `userID`
ORDER BY COUNT(`userID`) DESC;
SELECT b.F,COUNT(b.F)
FROM(
SELECT `userID`,
(CASE WHEN `购买次数` BETWEEN 1 AND 9 THEN 1
WHEN `购买次数` BETWEEN 10 AND 19 THEN 2
WHEN `购买次数` BETWEEN 20 AND 29 THEN 3
WHEN `购买次数` BETWEEN 30 AND 39 THEN 4
WHEN `购买次数` BETWEEN 40 AND 49 THEN 5
ELSE 6 END
) F
FROM `f值`
) b
GROUP BY b.F
ORDER BY b.F;
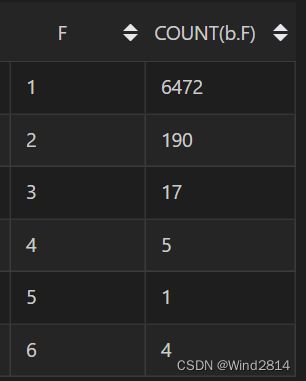
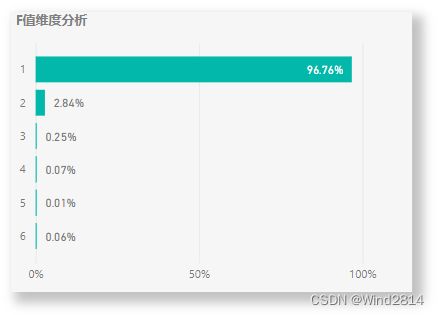
由图可见,在统计区间内,有近97%的人在淘宝消费了1~9次.
5.4.3用户分层
对R值、F值进行综合打分
#R打分
CREATE VIEW R打分 AS
SELECT `userID`,
(CASE WHEN `时间间隔`BETWEEN 0 AND 2 THEN 3 WHEN`时间间隔`BETWEEN 3 AND 5 THEN 2 ELSE 1 END ) R
FROM`r值`;
#F打分
CREATE VIEW F打分 AS
SELECT `userID`,
(CASE WHEN `购买次数`BETWEEN 1 AND 9 THEN 1
WHEN`购买次数`BETWEEN 10 AND 19 THEN 2
WHEN`购买次数`BETWEEN 20 AND 29 THEN 3
WHEN`购买次数`BETWEEN 30 AND 39 THEN 4
WHEN`购买次数`BETWEEN 40 AND 49 THEN 5
ELSE 6 END ) F
FROM`f值`;
#RF综合值
CREATE VIEW RF综合分析 AS
SELECT r.userID,r.R,f.F,r.R+f.F RF综合值
FROM R打分 r
INNER JOIN F打分 f
ON
r.userID=f.userID;
降序排列后发现9分为最高分值,2分为最低分值,所以按照每2分一个区间对用户进行分层:
2 ~ 3分:易流失用户
4 ~ 5分:挽留用户
6 ~ 7分:发展用户
8 ~ 9分:忠诚用户
然后统计各层级用户数量
#对用户进行分层
SELECT RF.`用户分层`,
COUNT(RF.`用户分层`) 人数
FROM
(SELECT userID,
(CASE WHEN RF综合值 BETWEEN 2 AND 3 THEN '易流失用户'
WHEN RF综合值 BETWEEN 4 AND 5 THEN '挽留用户'
WHEN RF综合值 BETWEEN 6 AND 7 THEN '发展用户'
WHEN RF综合值 BETWEEN 8 AND 9 THEN '忠实用户'
END ) 用户分层 FROM `RF综合分析` ) RF
GROUP BY RF.`用户分层`;
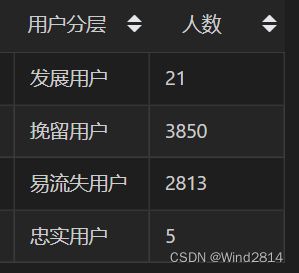
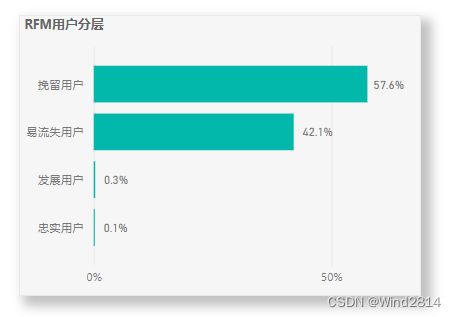
5.4.4RFM模型整体分析结果
-
在四个分类中,挽留用户的占比最高,这部分用户待挖掘的潜在价值很大,应该对这部分用户进行定时促活,如优惠发放、上新消息送达、提供更精准的商品推荐等,主要目的是留住用户,并提升消费品率,提高其转化率.
-
易流失用户占到了42%左右的比例,占比也比较高,可能是找到了同类的竞品APP或是产品体验不佳,可以对该部分用户进行调研找到其流失原因,及时进行新活动心有会推送,对用户进行召回.
-
发展用户占比较低,可以对这部分用户进行定期推送,发送优惠消息邮件通知,来增加消费频次.
-
忠诚用户的占比是最少的,这部分用户的价值极高,需要制定专属的运营策略来进行维护,如专属优惠、专属客服等,保证其较高的用户粘性.
此次用户分层效果分析整体效果不佳,可能有下面两个原因
1、区间划分不合理,不一定非要按照等差数列来划分区间,可以先看一下各个分数的用户人数并结合实际的业务场景进行区分.
2、两个维度划分的段数不同,且差异较大,相当于给两个部分赋予了不同的权重可以尝试进行四象限气泡图划分,可能效果会好一些.