SpringBoot+Redis+Lua实现数据的处理
目录
前言
需求与分析
伪代码与实现
可能要考虑的问题
1. 集群的redis
2. 异常处理
优缺点
1. 使用Lua的优点
2. 使用Lua的缺点
前言
本文主要讨论下使用Lua脚本去对redis进行操作的一些想法。我将会通过一个具体的例子来进行分析。
背景:Lua是一种类C的语言,在这里我们使用它去编写一些语句,去操纵redis中的数据。一些背景知识,大家感兴趣的话,可以通过下面的Link去了解下。
- lua基本语法。Lua 教程 | 菜鸟教程
- springboot集成redis和lua。Springboot整合Redis以及Lua脚本的使用 - 奕锋博客 - 博客园
- redis的基本命令。Redis 教程 | 菜鸟教程
- redis集群 Redis集群 - -Finley- - 博客园
需求与分析
我在工作中遇到如下一个需求。需要对一些产品的库存节点进行清空操作。因为产品的库存是一个频繁访问和变更的数据。因此在我们的系统中,它是在redis和db各有一份。redis上的数据为最新数据。所以我的工作流程大概如下:

因为要操作的库存节点可能会有多个。如果使用循环的方式去call redis,考虑到网络IO的问题,它会变得很慢。同时,万一在循环的过程中,网络环境出现变化,也很难去保证数据的一致性。所以这里我考虑使用lua脚本,将要更新的库存节点id给到它,进行批量的处理。
伪代码与实现
所以思路清晰之后,就可以编码的。这里贴上对redis处理的Lua伪代码:
-- id 的common前缀
local invIdPrefix = KEYS[1]
-- n个节点id的值
local inventoryIds = ARGV
-- 以下为简写的伪代码,实际上并不能运行
local id2InvCount = {}
for id in inventoryIds
local beforeClearCount = redis.get(id)
redis.set(id, 0)
id2InvCount[id] = beforeClearCount
return id2InvCount
可能要考虑的问题
1. 集群的redis
上述的解法,在单节点的redis中,并没有任何的问题。但是目前较大的系统。一般都使用的redis集群。目前主流的有三种集群方式。这里我以Redis Cluster举例,看下可能出现的问题。
因为在Redis Cluster中,redis的数据是分散在各个节点上的。但是接收到Lua脚本的可能是其中的一个节点。例如我们要清空[id1,id2,id3,id4]的数量,如果执行Lua脚本的是节点1。在循环到id3的时候,因为id3的数据并不在当前的节点里面。那么它就会报错了。
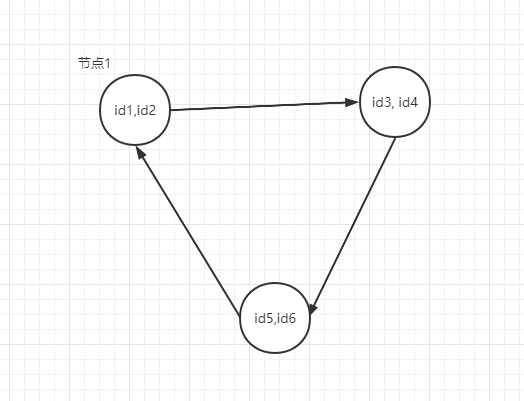
1.1 那我们能否让这些id在某一个节点内呢?
可以使用HashTag,因为在Redis Cluster中,redis是对key通过CRC16散列取模得到它所在的slot和节点中。
我们可以使用HashTag,即是在key里面拼上一段用{}包裹key的一个子串。例如
prod:{Inv}:kgjej345lj34i5445
prod:{Inv}:kgjej54353434i56
prod:{Inv}:kgje75654j34i565
这样散列的时候,它只会对Inv这个字符串去取值,显然,上述三个节点的值相同,那么他们就会进入到同一个节点中。那么分布图就会变成下面这样:
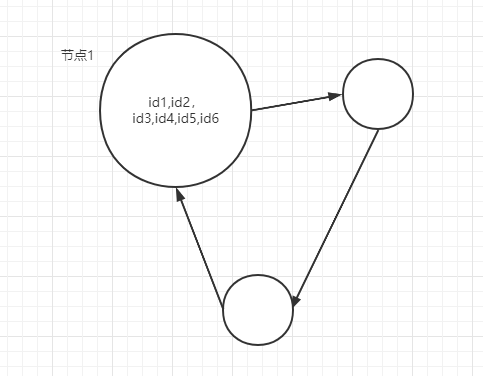
1.2 如何保证执行Lua的节点是节点1呢?
其实根据Debug,我们可以一层层的溯源。

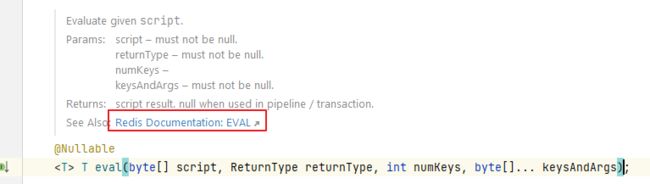
到这里,我们可以清晰的看到,spring底层。是通过eval命令去执行的Lua脚本。上方还附带了redis的文档。文档中很清晰的有这句话。
Important: to ensure the correct execution of scripts, both in standalone and clustered deployments, all names of keys that a script accesses must be explicitly provided as input key arguments. The script should only access keys whose names are given as input arguments. Scripts should never access keys with programmatically-generated names or based on the contents of data structures stored in the database.
所以对于redis cluster来说。我们需要将用到的key,放到执行的 List
2. 异常处理
人生总是充满了各种意外,代码也是。在后台开发中,我们一般采用的事务控制如下。我们会在外层包一个Transaction,这样当下层出现Exception时,可以及时去进行回滚,能够保证数据的一致性。 
但是,在这次的业务逻辑中,Lua脚本的执行是不受Transaction的限制的,所以如果在 保存操作历史 这一步出现了异常。DB层会回滚。这时redis上的库存已经更新了,DB却没有,并且也没有操作历史。就造成了Bug的产生。所以我们又引入了新的方式。
这里我们可以使用spring提供的TransactionalEventListener去实现事务的监控,具体如下:
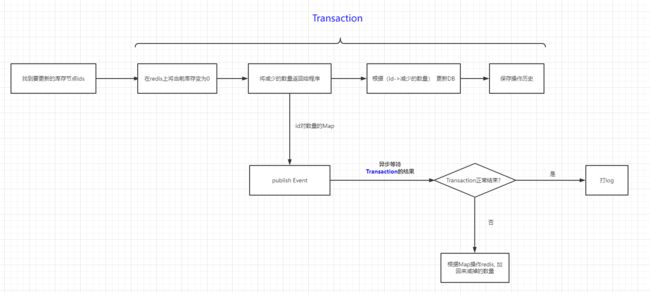
这样当出现Exception的时候,我们就可以将redis之前减少的数量再加回去。实现redis级别的“回滚”。但是细心的读者肯定发现了,万一在下图中这一步也出现了异常。该怎么办呢?因为每一步都有可能出现异常。异常的监听就是一个无限套娃的过程。在这里,我确实没有再做处理了,我默认为它出现异常的概率非常小。我仅仅在这一步加入了try...catch, 当出现问题时会有error log。如果有更好的方式,也欢迎大家与我交流。
优缺点
1. 使用Lua的优点
1. 相比传统的get,set方法来看。Lua脚本可以支持更加复杂的逻辑,扩展性强。
2. 减少网络IO的时间,例如上述对N个节点进行操作,就无需发送N个请求,可以一次解决。
3. Lua脚本缓存。从官方文档可以看到,当使用EVALSHA去执行脚本时,会将当前脚本缓存到redis里面,通过sha去摘要生成一个key。这样当第二次执行相同的脚本时。key相同,就可以直接去执行缓存中的脚本。这样客户端就不需要传递完整的脚本,只需要传递key即可。 详细的内容可以参考这里 。
那么spring是怎么做的呢?
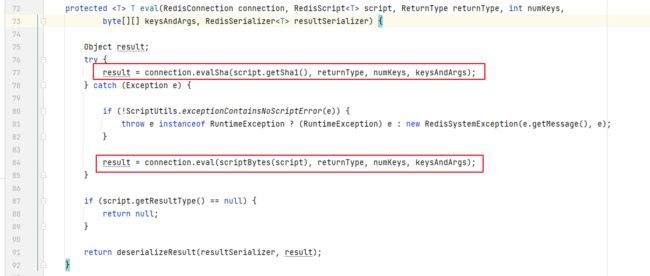
老方法,debug啦,我们可以看到这里。在执行eval方法时,spring会将lua脚本的sha串拿到,尝试去做一次evalSha执行。
- 如果没有报错,说明redis服务器中确实有当前脚本的缓存(77行),执行结束。
- 如果报错,那么再将完整的Lua脚本传递给redis(84行),去做eval命令。
2. 使用Lua的缺点
1.对集群操作不友好。前面的例子里面讲过hashTag,节点选择策略等等。都是为了在redis cluster中能够执行做的一些妥协性的操作。同时我们采用了hashTag之后,会将某个类型的数据集中放在一个节点上。万一这类数据较大(当然这个可能性不大),就会导致整体集群数据的不均衡。
2. 开发的消耗很大。例如我们在考虑数据库回滚之后,还要去想办法去回滚redis上的数据。
3. 原子性的理解。虽然Lua脚本支持事务。数据的set 错误,例如set了一个不存在的key, 对于redis来说并不算是Error。不会触发回滚。所以在写代码的过程中,要尤为小心数据的操作。参考