【MySQL】联合查询

目录
1、前言
2、联合查询
3、内连接和外连接
4、案例演示
4.1 查询篮球哥每科的成绩
4.2 查询所有同学的总成绩及邮箱
5、自连接
5.1 显示所有计算机原理成绩比java成绩高的同学
6、子查询
6.1 查询出篮球哥的同班同学
6.2 多行子查询
7、合并查询
1、前言
在实际开发中,往往数据是来自不同的表,所以需要多表联合查询,多表查询是对多张表的数据取笛卡尔积。
这里就需要简单了解下笛卡尔积的概念了:
集合A {a1,a2,a3} 集合B {b1,b2},他们的 笛卡尔积 是 A*B = { (a1,b1), (a1,b2), (a2,b1), (a2,b2), (a3,b1), (a3,b2)}任意两个元素结合在一起。
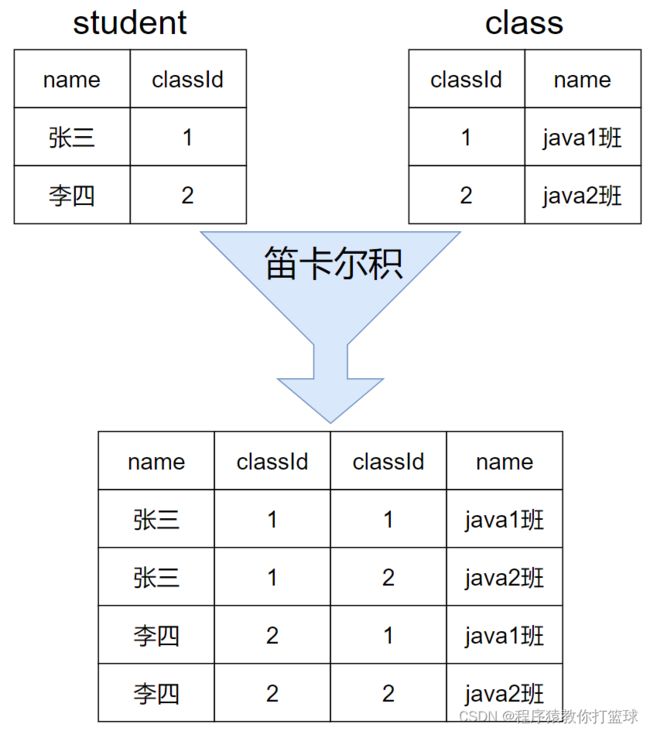
如上图所示,笛卡尔积就是把这两个表放到一起进行计算,分别取出第一张表的每一行,和第二张表的每一行配对,得到一个新的记录。
2、联合查询
有了上述笛卡尔积的认识,我们就来使用下联合查询,首先准备 student,class 这两张表,并且增加相关的数据:
create table student (
id int primary key,
name varchar(20),
classId int
);
create table class (
classId int primary key,
name varchar(20)
);
insert into student value
(23001, '张三', 1),
(23002, '李四', 2),
(23003, '王五', 1),
(23004, '赵六', 3),
(23005, '孙七', 3);
insert into class value
(1, 'java1班'),
(2, 'java2班'),
(3, 'java3班'); 
有了上述的数据后,我们就来进行简单的联合查询(通过 student class 表 查询出每个学生对应的班级):
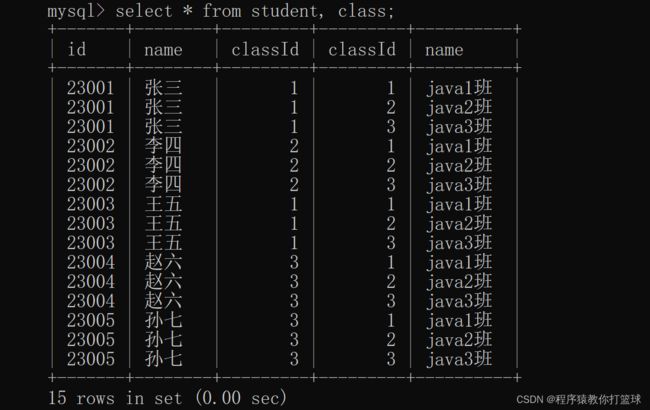
这里我们发现,同时查询两张表,进行了笛卡尔积,跟我们上述画的图是一样的效果,但是这里我们发现有很多无效的元素,按道理来说,张三的 classId 为 1,对应 class 表应该是 java1 班的,所以这里的数据是存在很多无效数据的,此时我们就可以使用 where 条件来进行筛选:
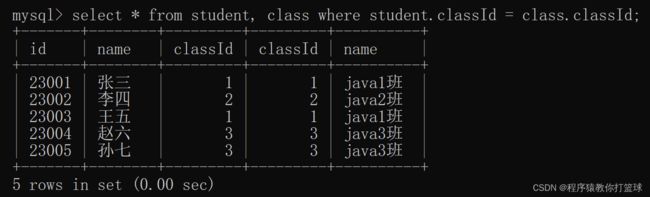
有了筛选条件后,显然发现就没有了那些无效的数据了,此时我们再次省略我们不想要的列,只保留学生姓名和班级名称就好了:
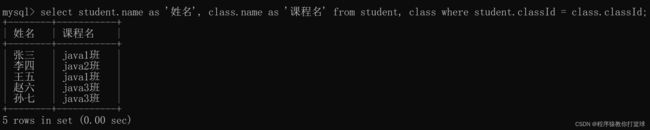
这样一来得到的结果就是我们想要的结果了。
上述可能有一个点之前没有说过,比如 student.classId 和 class.classId,这里为什么要加 表名. 前缀呢?由于我们进行的是多表查询,势必可能会出现不同表中存在相同的列名,这里我们就需要告诉 MySQL 是那个表中的列。如果不加表名,这时就区分不了是哪个表的列了,随之就会报错!
上述是最基础的多表查询,后面我们就来用案例来学习更复杂的多表查询。
3、内连接和外连接
在大多数情况下,都是没有啥区别的,比如要连接的两个表中,里面的数据都是一一对应的,这个时候就没有区别,如果不是一一对应,内连接和外连接就有区别了。

这里我们有这样的两张表,通过看数据可以发现,student表中张三在score表中是没有成绩的,而score表中studentId为4是没有对应学生的。我们就用上述两张表进行联合查询演示下外连接和内连接的区别:
select * from student, score where student.id = score.studentId;
select * from student join score on student.id = score.studentId;
-- 这两种的写法都是一样的效果
+------+--------+-----------+-------+
| id | name | studentId | java |
+------+--------+-----------+-------+
| 1 | 张三 | 1 | 89.00 |
| 2 | 李四 | 2 | 92.00 |
+------+--------+-----------+-------+上述的写法都属于内连接,此处查询结果中,最终剩下的就是两个表里都有的数据,都能关联上的数据,如果使用外连接,那么结果就不相同了。
● 左外连接:
select * from student left join score on student.id = score.studentId;● 右外连接:
select * from student right join score on student.id = score.studentId;
我们对比这两种两种连接方式,来观察他们的区别:
- 左外连接会把左表的结果都列出来,哪怕右表中没有相应的数据,就使用 NULL 来填充
- 右外连接会把右表的结果都列出来,哪怕左表中没有相应的数据,就使用 NULL 来填充
后续为了演示更复杂的多表查询,以及结合实际的情况,这里我们需要重新构建四张表:
create table classes (
id int primary key auto_increment,
name varchar(20),
synopsis varchar(100)
);
create table student (
id int primary key,
name varchar(20),
qq_mail varchar(20) ,
classes_id int
);
create table course (
id int primary key auto_increment,
name varchar(20)
);
create table score (
score decimal(3, 1),
student_id int,
course_id int
);由于插入数据部分代码太多,不方便放入文章里,大家可以自行录入,也可以去博主的主页去下载现成的 SQL 文件哦。
4、案例演示
4.1 查询篮球哥每科的成绩
此时要注意篮球哥的信息在 student 表中,而成绩在 score 表里,课程名又在 course 表中,而 score 表中包含了 sutdent_id 以及 course_id:
select student.name as '姓名', course.name as '课程名', score.score as '分数'
from student, score, course
where student.id = score.student_id and
score.course_id = course.id and
student.name = '篮球哥';
这里为了大家看的方便,就进行了换行,最终我们只需要显示三个字段,数据来源于 student,score,course 表,接下来就是 where 条件部分了,相信也是清晰明了的。

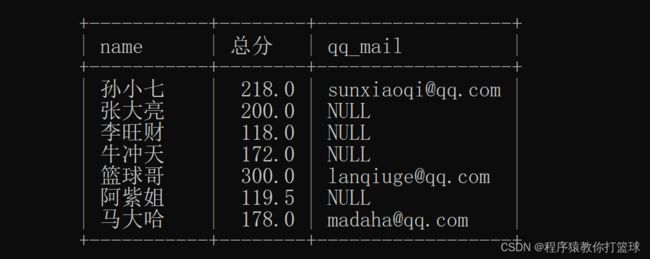
4.2 查询所有同学的总成绩及邮箱
此时要用到 student,score 这两个表,并且还要使用聚合函数进行求每个同学的总分,也就是要对每个同学的 id 进行分组后,成绩求和。
select student.name, sum(score) as '总分', student.qq_mail
from student, score
where student.id = score.student_id
group by student.id;
-- 成绩表对学生表是多对1关系,查询总成绩是根据成绩表的同学id来进行分组的这里交大家一个简单的方法读 sql 语句,select 后面最终显示的列,from 后面是数据来源的表,where 是进行筛选的条件,group by 是按照某个字段进行分组。这样一来就简洁明了了。
5、自连接
自连接就是自己跟自己笛卡尔积,这不是一个通用的解决方案,而是特殊问题的特殊处理方法,自连接的效果就是把 行 转换成 列,这里我们举个例子:
5.1 显示所有计算机原理成绩比java成绩高的同学
select * from score, score;
-- ERROR 1066 (42000): Not unique table/alias: 'score'这里发现直接自己跟自己笛卡尔积会报错,说名字重复了,不是唯一的,可以采用取别名的方式来解决这个错误:
select * from score as s1, score as s2;首先我们要明确这 java 和 计算机原理 的课程 ID 是多少:
select * from course;
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 3 | 计算机原理 |
| 4 | 语文 |
| 5 | 高阶数学 |
| 6 | 英文 |
+----+--------------------+
-- 6 rows in set (0.00 sec)得到了 java 和 计算机原理 的 id 之后,对 score 表自身进行笛卡尔积,就可以指定 s1.class_id = 1 and s2.class_id = 3 这样的条件,也就是将一行中 s1 表显示 java, s2 表显示计算机原理:
select * from score as s1, score as s2 where s1.course_id = 1 and s2.course_id = 3;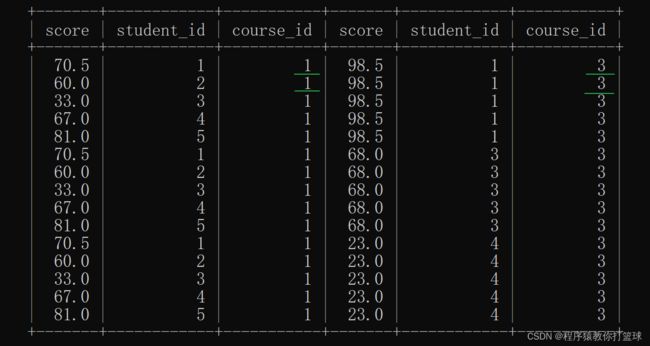
此查询结果还存在无效的数据,比如 s1.student_id 与 s2.student_id 应该是一样的, 因为我们查询的是谁的计算机原理比Java成绩高,所以我们还要加上一个条件:
select * from score as s1, score as s2
where s1.course_id = 1
and s2.course_id = 3
and s1.student_id = s2.student_id;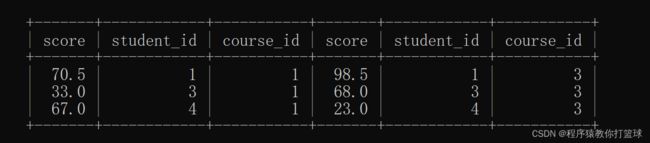 现在这个结果是满足 id 相等,同时满足了要比较的科目,现在就差一个条件了!就是 s1.score < s2.score 这就表示查询的是 java 成绩小于 计算机原理的同学:
现在这个结果是满足 id 相等,同时满足了要比较的科目,现在就差一个条件了!就是 s1.score < s2.score 这就表示查询的是 java 成绩小于 计算机原理的同学:
select * from score as s1, score as s2
where s1.course_id = 1
and s2.course_id = 3
and s1.student_id = s2.student_id
and s1.score < s2.score;
最后我们对这个结果保留想要的字段,并且增加 student.name 这个字段,注意增加 student.name 表示要多一个student 表一起进行笛卡尔积,所以我们还要加一个条件 student.id = s1.student_id,这样才是最终完整的结果:
select student.name, s1.score as Java, s2.score as 计算机原理
from student, score as s1, score as s2
where s1.student_id = s2.student_id
and s1.course_id = 1
and s2.course_id = 3
and s1.score < s2.score
and student.id = s1.student_id;
以上就完整的查询出了 计算机原理成绩大于Java成绩的同学了! 这个过程看似复杂,但不要着急,静下心来一步步分析,阅读 SQL,相信你能理解的!
6、子查询
子查询本质就是套娃,实际开发中,慎重使用,子查询可能会构造出非常复杂,非常不好理解的 SQL,对于代码的可读性就大大降低了,对于 SQL 的执行效率,也有可能是毁灭性的打击!
6.1 查询出篮球哥的同班同学
正常情况下,先查询出篮球哥的班级id,然后条件设置为 claases_id 跟 篮球哥的班级id 相同即可,并排掉篮球哥:
select classes_id from student where name = '篮球哥';
-- 1
select * from student where classes_id = 1 and name != '篮球哥';这样就能求出篮球哥的同班同学,但是子查询是如何写的呢?
select * from student where classes_id = (select classes_id from student where name = '篮球哥') and name != '篮球哥';
子查询的写法其实就是套娃!把一个查询的结果,作为另一个查询的一部分条件(此处作为另一个一部分查询条件的查询结果只能返回一条数据) 。
6.2 多行子查询
● 查询语文或英文课程的成绩信息
正常情况下,我们需要先查询出语文和英文的课程id,然后去成绩表中查询对应课程id 的成绩:
select id from course where name = '语文' or name = '英文';
-- 4 6
select * from score where course_id = 4 or course_id = 6;如果要用多行子查询就需要利用 in 关键字:
select * from score where course_id in (select id from course where name = '语文' or name = '英文');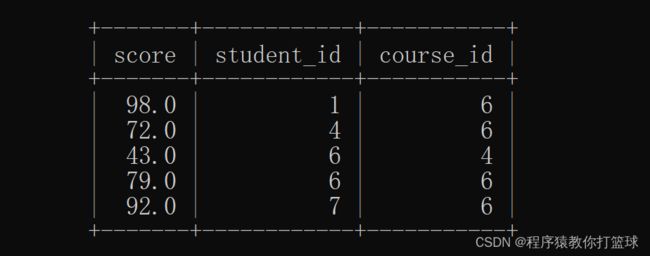
如果查询是排除语文英文信息呢?就使用 not in 就行,可以把 in 理解成再这个范围内,整体查询结果必须满足 in 后面子查询的结果范围。
这里的套娃是无穷无尽的,一般不建议这样做,实际上更推荐是直接多步完成查询就好,没必要强行合成一个!
7、合并查询
合并查询就比较简单了,本质上就是把两个查询的结果集合并成一个。
● 查询课程id小于3,或者课程名为英文的课程
select * from course where id < 3 union select * from course where name = '英文';
这里可能有小伙伴就很奇怪,这中间直接来个 or 不就行了吗?是的!
注意:这里的 union 是可以来自于不同的表,只要查询的结果的列匹配即可,而 or 只能是同一表。
除了 union 还有一个 union all,他们区别不大,union 是会进行去重(重复的行只会保留一份),而 union all 是不会去重的!