flink 的 State
目录
一、前言
二、什么是State
2.1:什么时候需要历史数据
2.2:为什么要容错,以及checkpoint如何进行容错
2.3:state basckend 又是什么
三、有哪些常见的是 State
四、 State的使用
五、State backend
5.1 MemoryStateBackend:
5.2 FsStatebackend:
5.3 RocksDBStateBackend:
六、Checkpoint
七、 Deep
7.1 Checkpoint Barries
一、前言
首先State是flink中的一个非常基本且重要的概念,本文将介绍什么是State ,如何使用State,
State的存储和原理。以及State衍生的一些概念和应用。
二、什么是State
一种为了满足算子计算时需要历史数据需求的,使用checkpoint机制进行容错,存储在state backend 的数据结构。
首先state 其实就是一种数据结构。然后上面定义中隐含了三个基本知识点:
2.1:什么时候需要历史数据
去重:在流处理系统中,上游的系统数据可能会有重复,落到下游是希望把重复的数据去掉,此时就需要记录历史的数据。
窗口计算:在触发窗口计算函数前,需要将窗口中手机的数据保存起来,等到触发时进行计算。
机器学习/深度学习:如训练的模型以及当前模型的参数也是一种状态,机器学习可以每次都用一个数据集,需要在数据集上进行学习,对模型进行一个反馈。
2.2:为什么要容错,以及checkpoint如何进行容错
2.3:state basckend 又是什么
三、有哪些常见的是 State
最常见的是Keyed State 应用于keyedStreamh上,必须在KeyBy操作之后使用。它的特点是 同一个sub task 上的同一个 key 共享一个 state 。 另外还有 operator state ,顾名思义每一个operator state 都只有一个operation 的实列绑定。常见的 operation state 是 source state ,列如记录当前source 的 offset 。它的特点是 同一个 sub task 共享一个 state 。另外还有一种特殊的 operation state 称为 broadcast state , 它的特点是 同一个算子的多个 sub task 共享一个 state 。
四、 State的使用
这里以常用的 Keyed State 进行举例。前面说了 State 本质上就是一种用来存储数据的数据结构,那么作为 Keyed State,都支持哪些数据结构呢?以下列举了常见的几种数据结构:
ValueState 存储单个值,比如 Wordcount,用 Word 当 Key,State 就是它的 Count。这里面的单个值可能是数值或者字符串,作为单个值,访问接口可能有两种,get 和 set。在 State 上体现的是 update(T) / T value()。
MapState 的状态数据类型是 Map,在 State 上有 put、remove等。需要注意的是在 MapState 中的 key 和 Keyed state 中的 key 不是同一个。
ListState 状态数据类型是 List,访问接口如 add、update 等
flink官网的State :
Working with State | Apache FlinkWorking with State # In this section you will learn about the APIs that Flink provides for writing stateful programs. Please take a look at Stateful Stream Processing to learn about the concepts behind stateful stream processing.Keyed DataStream # If you want to use keyed state, you first need to specify a key on a DataStream that should be used to partition the state (and also the records in the stream themselves).https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/datastream/fault-tolerance/state/
class CountWindowAverage extends RichFlatMapFunction[(Long, Long), (Long, Long)] {
private var sum: ValueState[(Long, Long)] = _
/**
也可以使用 lazy 的方式对 state 进行初始化
lazy private val sum = getRuntimeContext.getState(
new ValueStateDescriptor[(Long, Long)]("average", createTypeInformation[(Long, Long)])
)
**/
override def flatMap(input: (Long, Long), out: Collector[(Long, Long)]): Unit = {
// access the state value
val tmpCurrentSum = sum.value
// If it hasn't been used before, it will be null
val currentSum = if (tmpCurrentSum != null) {
tmpCurrentSum
} else {
(0L, 0L)
}
// update the count
val newSum = (currentSum._1 + 1, currentSum._2 + input._2)
// update the state
sum.update(newSum)
// if the count reaches 2, emit the average and clear the state
if (newSum._1 >= 2) {
out.collect((input._1, newSum._2 / newSum._1))
sum.clear()
}
}
override def open(parameters: Configuration): Unit = {
sum = getRuntimeContext.getState(
new ValueStateDescriptor[(Long, Long)]("average", createTypeInformation[(Long, Long)])
)
}
}
object ExampleCountWindowAverage extends App {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.fromCollection(List(
(1L, 3L),
(1L, 5L),
(1L, 7L),
(1L, 4L),
(1L, 2L)
)).keyBy(_._1)
.flatMap(new CountWindowAverage())
.print()
// the printed output will be (1,4) and (1,5)
env.execute("ExampleKeyedState")
}以上代码的功能是对输入的流数据进行平均数计算,当输入的数据大于等于 2 个时,触发计算。这里有几点需要注意:
- 因为 state 的初始化需要用到运行时上下文,所以定义的类需要继承 RichXXFunction
- state 有两种初始化方式,一种是在成员变量初定义并在 open 函数中初始化。另一种是直接在成员变量处通过 lazy 的方式进行定义和初始化。
- 这里的例子中使用的是 ValueState,他的 get 和 put 方法分别是
.value()和.update() - state 除了需要我们自己维护状态更新,状态的删除也需要在合适的时间点通过调用 clear
方法实现。
使用 state 除了继承 RichXXFunction 外还可以直接使用系统提供的函数。如 keyBy 之后直接使用 flatMapWithState 。
五、State backend
前面介绍了 State 的类型和常见的数据结构,那么这些 state 存储的介质有哪些呢? Flink 提供了三种存储 State 的介质:
5.1 MemoryStateBackend:
- 构造方法:
MemoryStateBackend( int maxStateSize, boolean asynchronousSnapshots )- 存储方式:
- State: TaskManager 内存
- Checkpoint: Jobmanager 内存
- 使用场景:本地测试用,不推荐生产场景使用
5.2 FsStatebackend:
构造方法:
FaStateBackend( URI checkpointDataUri, boolean asynchronousSnapshots )存储方式:
- State:Taskmanager 内存
- Checkpoint: 外部文件系统( 本地或 HDFS )
使用场景:常规使用 State 的作业,可以在生产中使用
5.3 RocksDBStateBackend:
- 构造方法:
RocksDBStateBackend( URI checkpointDataUri, boolean enableIncrementalCheckpointing )- 存储方式:
State: TaskManager 上的 KV 数据库(实际使用内存 + 磁盘)
Checkpoint: 外部文件系统(本地或 HDFS )
- 使用场景:超大状态作业,对性能要求不高的生产场景
六、Checkpoint
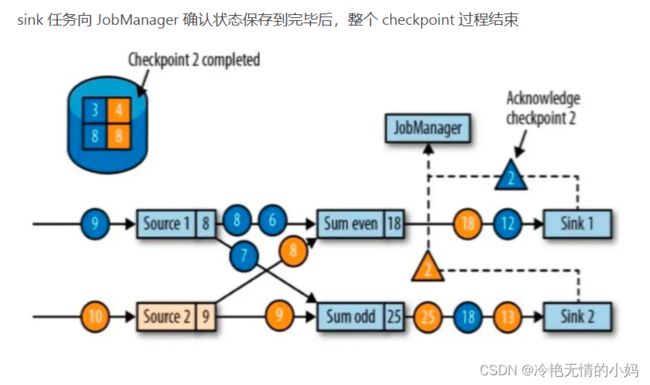
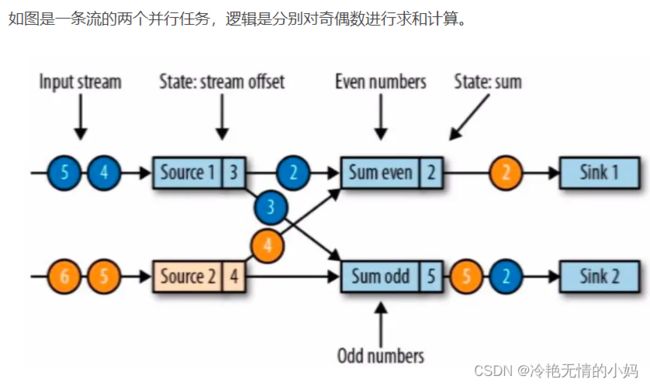
前面对 State 的使用中没有考虑容错的问题,当集群出现故障时进行恢复时,State 的值肯定不会从头开始计算,这就需要进行容错。State 使用 Checkpoint 机制进行容错。简单来说就是定时制作分布式快照,当出现故障需要进行恢复时,将所有 Task 恢复到最近一次成功的 Checkpoint 状态中,然后从那个点开始继续处理。Checkpoint 通过 Barries 对齐机制保证了恰好一次的一致性语义,关于 Barries 的原理后面将进行详细说明。
七、 Deep
7.1 Checkpoint Barries
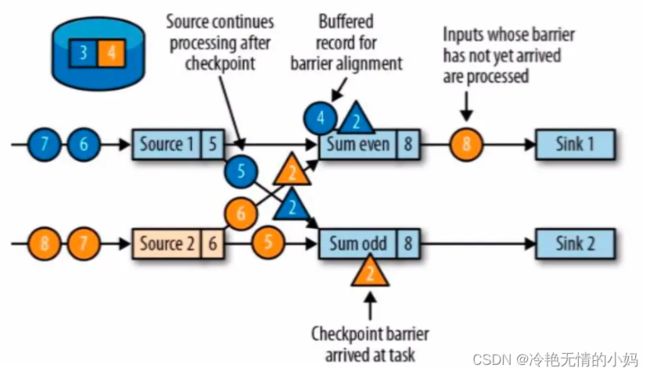
checkpoint 是 jobmanager 从 source 触发到下游所有节点完成的一次全局操作。checkpoint barriers 和 watermark 类似,都是一种特殊的事件。对某一 subtask 而言,checkpoint 表示所有 subtask 恰好处理完(不能多处理,也不能少处理。为了状态恢复时保持一致性)某个相同数据。watermark 表示这之前的数据已经接收完毕。
watermark在多 subtask 上游向下游传递时,是广播 + 取上游最小 watermark 作为当前 task 的watermark,不取最小 watermark 会丢数据。
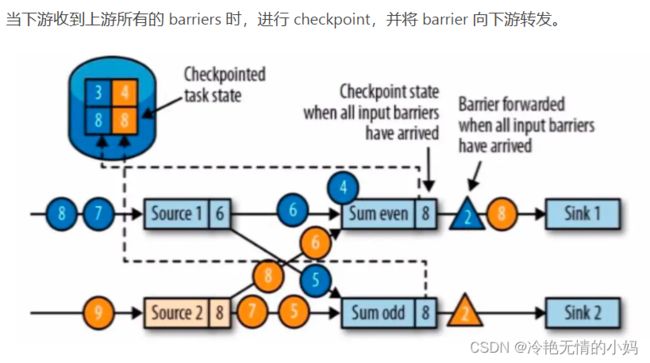
checkpoint barriers 在多 subtask 上游向下游传递时,是广播 + checkpoint barriers 对齐(alignment)。所谓对齐就是下游 subtask 会等待他上游所有分区的 subtask 的 checkpoint barriers 都到达才进行 checkpoint。上游已经到达 checkpoint barriers 的 substask 后续数据会缓存,没有到达 checkpoint barriers 的 subtask 数据会继续处理直到 checkpoint barriers 到达。

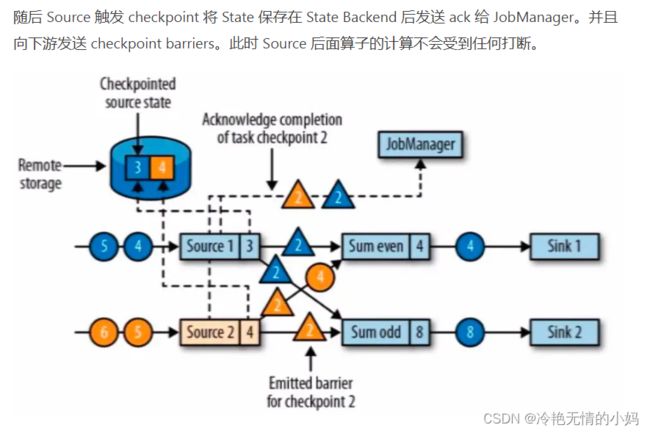
以 even 流的 Sum 算子为例,从图中可以看到先接收到 Source1 的 barrier 后接收到 Source2 的 barrier( 分别对应蓝色和黄色的三角 )。所以在接收到 Source1 的 barrier 后,对后面值为 4 的蓝流数据进行了缓存没有进行下一步计算,因为这个数据属于下一个 checkpoint。而在接收到 Source2 的 barrier 之前,对值为 4 的黄流数据照常进行计算直到接收到 Source2 的 barrier 为止。这就是所谓的 barriers alignment。