【教学类-07-03】20221106《破译电话号码-图形版(2类)+自制(PDF打印)》(大班主题《我要上小学》)
效果图
1、PDF合并打印版本
2、第1个号码用“黑色圆圈替代“
3、第2个号码用各种”几何实心图案“
4、第3个号码幼儿自己尝试编写、
背景需求:
2022年2月份,马先生帮我编写了一套《破译电话号码-图形固定列不重复》《破译电话号码-图形固定列重复》,把手机号码数字专为图案保存到EXCEL内,再用{{}}和Shpae代码在Word模板内添加图案,顺利 完成了比赛需求,幼儿操作中出现了一些对于图案的迷惑,于是把图案全部改成黑色实心、并且都是圆形、三角、正方等几何形(不用有乐府、云朵)

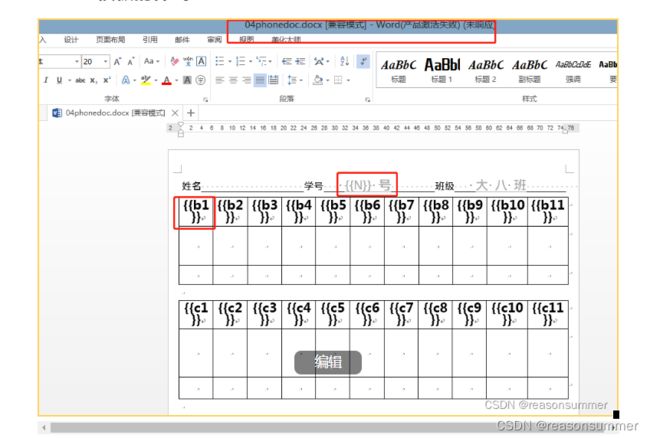
最近我在思考,是否可以不用”{{}}“的方式,直接在终端生成图案,组成列表。然后直接写入Word。花费一天实验后,终于实现了目标。


材料准备:
路径:r"C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码、
家长电话号码.xlsx
破译电话号码模板.docx
页边距 上下左右1CM,版式:横向

py代码:放在任意位置,不影响运行
代码设计——有学号和班级
'''
作者:阿夏
时间:2022年11月5日 破译电话号码-图形版-学号和班级(不需要分列,直接导入word)
'''
import openpyxl
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
import os
classroom=input('班级名称(如大1)\n')
print('----------第2步:新建一个临时文件夹------------')
# 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\零时Word')
print('------------读取excle表单--------------')
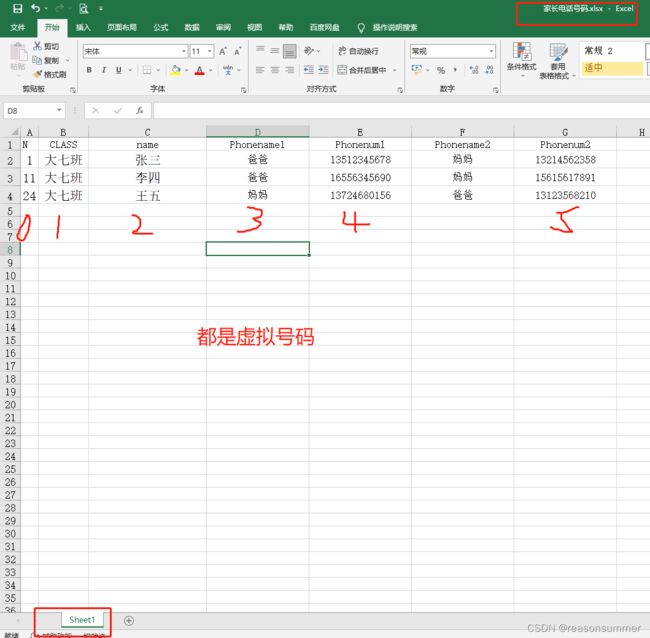
wb = openpyxl.load_workbook(r'C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\家长电话号码.xlsx')# wb=用openpyxl打开存有号码的ExcelEx
phone = wb.active #phone=获取wb里面的数据
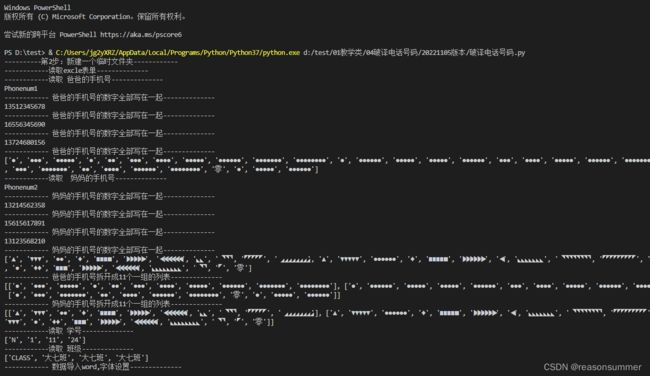
print('------------读取 爸爸的手机号--------------')
symbol_1=['●','●','●', '●', '●', '●','●', '●','●','●','●']
father=[]
for i in list(phone.columns)[4]:# 第3列是爸爸的手机号
phonestr = str(i.value)# 电话字符串 = 第二列的数字的值的字符串形式
print(phonestr)# 打印电话字符串
# Phonenum1
# 13512345678
# 16556345690
# 13724680156
print('------------ 爸爸的手机号的数字全部写在一起--------------')
col = 0 #
for k in phonestr:# 在电话字符串里面循环遍历 取各种数字
if i.value!= 'Phonenum1':# 如果电话号码的值不等于'dad' 不要第一行C1
if int(k) != 0:# 如果取出的数字不等于0 等于1-9
str_temp =int(k) * symbol_1[col]# 结果等于 取出的数字的整数 乘以 符号列表的相应列数的符号(批量几个符号)
else:# 如果取出的数字=于0
str_temp = '零'# 0=零
# print( str_temp)
father.append(str_temp)
col +=1
print(father)
['●', '●●●', '●●●●●', '●', '●●', '●●●', '●●●●', '●●●●●', '●●●●●●', '●●●●●●●', '●●●●●●●●', '●', '●●●●●●', '●●●●●', '●●●●●', '●●●●●●', '●●●', '●●●●', '●●●●●', '●●●●●●', '●●●●●●●●●', '零', '●', '●●●', '●●●●●●●', '●●', '●●●●', '●●●●●●', '●●●●●●●●', '零', '●', '●●●●●', '●●●●●●']
print('------------读取 妈妈的手机号--------------')
mother=[]
symbol_2 = ['▲','▼','●','♦','■','▶','◀','◣','◥','◤','◢']#
for j in list(phone.columns)[6]:
phonestr = str(j.value)
print(phonestr)
# Phonenum2
# 13214562358
# 15615617891
# 13123568210
print('------------ 妈妈的手机号的数字全部写在一起--------------')
col = 0# 第一个字符串的起始列 123数下去 mum电话的第一位数在第O列=15列
for _ in phonestr[:]:
if j.value != 'Phonenum2':
if int(_) != 0:
str_temp = int(_) * symbol_2 [col]
else:
str_temp = '零'
mother.append(str_temp)
col +=1
print(mother)
# ['▲', '▼▼▼', '●●', '♦', '■■■■', '▶▶▶▶▶', '◀◀◀◀◀◀', '◣◣', '◥◥◥', '◤◤◤◤◤', '◢◢◢◢◢◢◢◢', '▲', '▼▼▼▼▼', '●●●●●●', '♦', '■■■■■', '▶▶▶▶▶▶', '◀', '◣◣◣◣◣◣◣', '◥◥◥◥◥◥◥◥', '◤◤◤◤◤◤◤◤◤', '◢', '▲', '▼▼▼', '●', '♦♦', '■■■', '▶▶▶▶▶', '◀◀◀◀◀◀', '◣◣◣◣◣◣◣◣', '◥◥', '◤', '零']
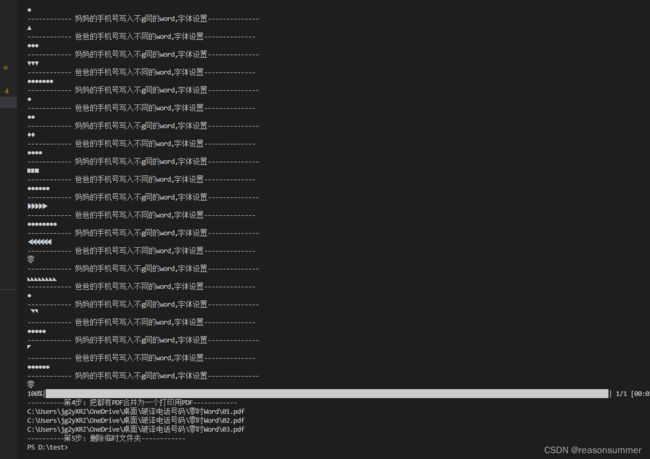
print('------------ 爸爸的手机号拆开成11个一组的列表--------------')
father_all=[]
for i in range(0,int(len(father)/11)):
b=father[i*11:i*11+11]
father_all.append(b)
print(father_all)
# [['●', '●●●', '●●●●●', '●', '●●', '●●●', '●●●●', '●●●●●', '●●●●●●', '●●●●●●●', '●●●●●●●●'], # ['●', '●●●●●●', '●●●●●', '●●●●●', '●●●●●●', '●●●', '●●●●', '●●●●●', '●●●●●●', '●●●●●●●●●', '零'],['●', '●●●', '●●●●●●●', '●●', '●●●●', '●●●●●●', '●●●●●●●●', '零', '●', '●●●●●', '●●●●●●']]
print('------------ 妈妈的手机号拆开成11个一组的列表--------------')
mother_all=[]
for i in range(0,int(len(mother)/11)):
b=mother[i*11:i*11+11]
mother_all.append(b)
print(mother_all)
# [['▲', '▼▼▼', '●●', '♦', '■■■■', '▶▶▶▶▶', '◀◀◀◀◀◀', '◣◣', '◥◥◥', '◤◤◤◤◤', '◢◢◢◢◢◢◢◢'],
# ['▲', '▼▼▼▼▼', '●●●●●●', '♦', '■■■■■', '▶▶▶▶▶▶', '◀', '◣◣◣◣◣◣◣', '◥◥◥◥◥◥◥◥', '◤◤◤◤◤◤◤◤◤', '◢'],
# ['▲', '▼▼▼', '●', '♦♦', '■■■', '▶▶▶▶▶', '◀◀◀◀◀◀', '◣◣◣◣◣◣◣◣', '◥◥', '◤', '零']]
print('------------读取 学号或者姓名--------------')
N=[]
for i in list(phone.columns)[0]:# 学号-0 姓名1
phonestr = str(i.value)# 电话字符串 = 第二列的数字的值的字符串形式
N.append(phonestr)
print(N)# ['N', '1', '11', '24']
print('------------读取 班级--------------')
C=[]
for i in list(phone.columns)[1]:# 第3列是爸爸的手机号
phonestr = str(i.value)# 电话字符串 = 第二列的数字的值的字符串形式
C.append(phonestr)
print(C)#['CLASS', '大七班', '大七班', '大七班']
print('------------ 数据导入word,字体设置--------------')
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
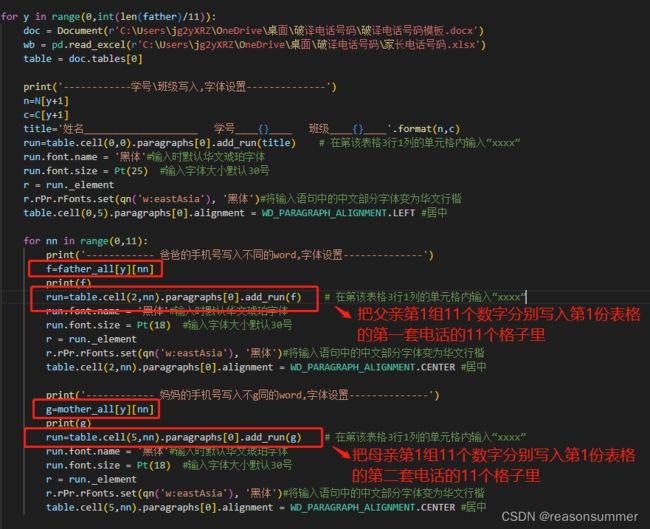
for y in range(0,int(len(father)/11)):
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\破译电话号码模板(图案).docx')
wb = pd.read_excel(r'C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\家长电话号码.xlsx')
table = doc.tables[0]
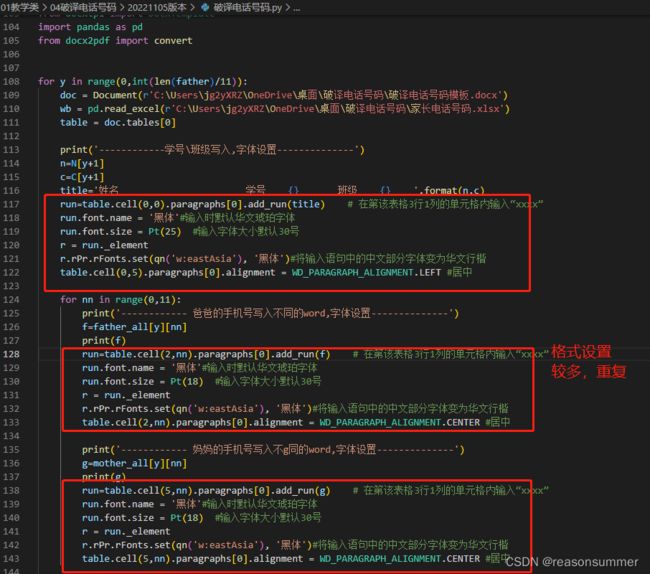
print('------------学号\班级写入,字体设置--------------')
n=N[y+1]
run=table.cell(0,6).paragraphs[0].add_run(n) # 这里的可以代表学号或者名字,把上面连接的数字改掉 姓名02 学号06 班级08
run.font.name = '黑体'#输入时默认华文琥珀字体
run.font.color.rgb = RGBColor(220,220,220) #设置颜色浅灰
run.font.size = Pt(50) #输入字体大小默认30号
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(0,6).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
c=C[y+1]
run=table.cell(0,8).paragraphs[0].add_run(c) # 班级08
run.font.name = '黑体'#输入时默认华文琥珀字体
run.font.color.rgb = RGBColor(220,220,220) #设置颜色浅灰
run.font.size = Pt(50) #输入字体大小默认30号
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(0,8).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
for nn in range(0,11):
print('------------ 爸爸的手机号写入不同的word,字体设置--------------')
f=father_all[y][nn]
print(f)
run=table.cell(2,nn).paragraphs[0].add_run(f) # 在第该表格3行1列的单元格内输入“xxxx”
run.font.name = '黑体'#输入时默认华文琥珀字体
run.font.size = Pt(18) #输入字体大小默认30号
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(2,nn).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
print('------------ 妈妈的手机号写入不g同的word,字体设置--------------')
g=mother_all[y][nn]
print(g)
run=table.cell(5,nn).paragraphs[0].add_run(g) # 在第该表格3行1列的单元格内输入“xxxx”
run.font.name = '黑体'#输入时默认华文琥珀字体
run.font.size = Pt(18) #输入字体大小默认30号
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(5,nn).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\零时Word\{}.docx'.format('%02d'%(y+1)))#保存为XX学号的电话号码word
# docx 文件另存为PDF文件
inputFile = r"C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\零时Word\{}.docx".format('%02d'%(y+1)) # 要转换的文件:已存在
outputFile = r"C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\零时Word\{}.pdf".format('%02d'%(y+1)) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = r"C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\零时Word"
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write(r"C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\(打印合集)破译电话号码-图案版-学号和班级({}班-{}份).pdf".format(classroom,int(len(father)/11)))
file_merger.close()
# doc.Close()
print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree(r"C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\零时Word") #递归删除文件夹,即:删除非空文件夹
终端运行:

重点说明:
 感悟:
感悟:
1、代码段更长。
原有代码段有149行,本代码有175行,并没有变得更精炼
2、模板格式改变。
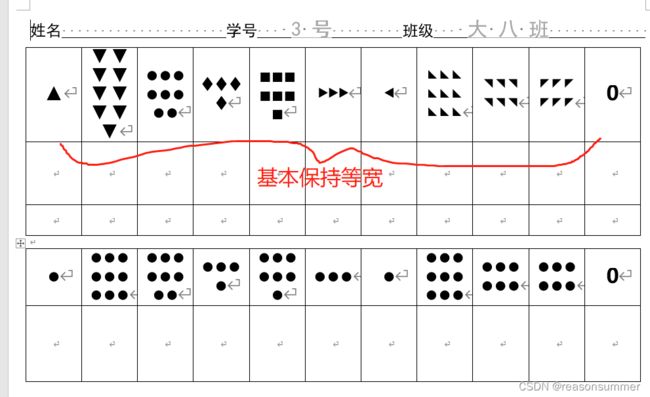
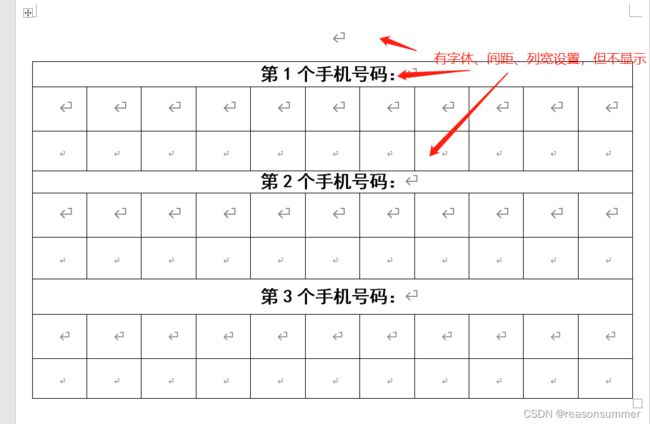
由于是直接插入,并在代码里更改格式,所以导入的图案后,word表格框不再等宽。

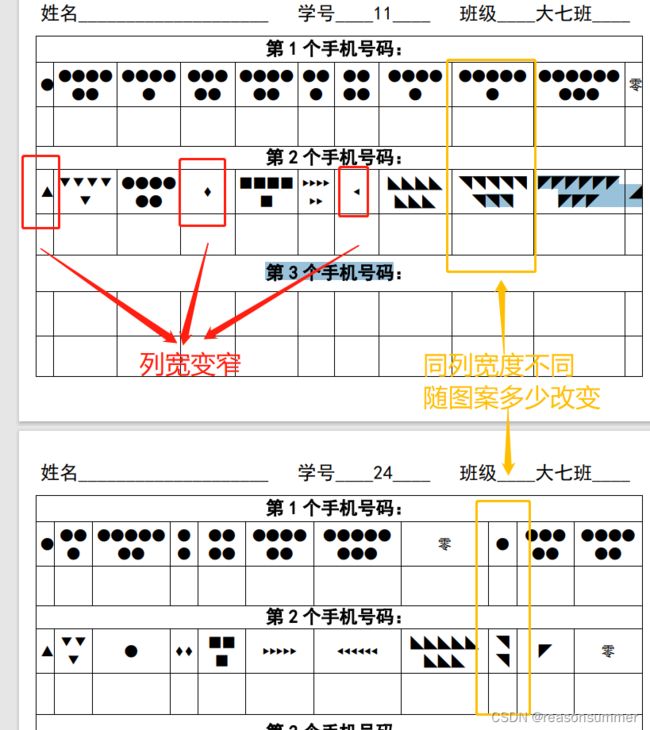
但是用原来的模板,可以实现表格导入图案后依旧等宽。
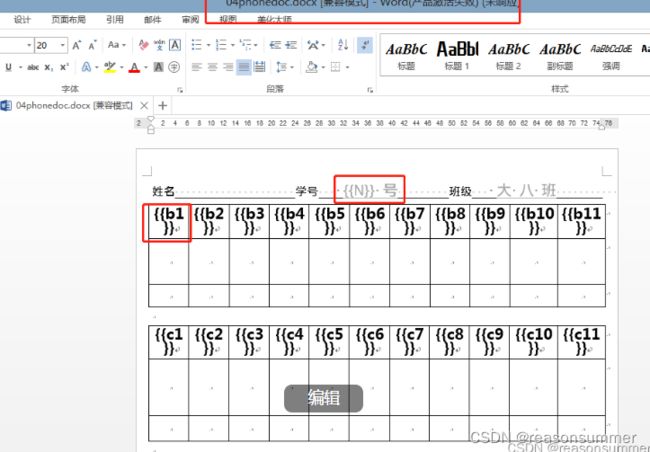
 3、学号和班级信息无法变灰色
3、学号和班级信息无法变灰色
原来的模板预先设定好字体的大小、字体样式、字体颜色,
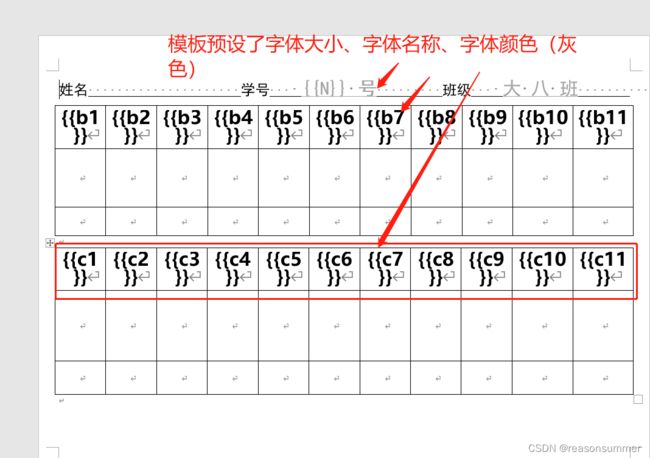
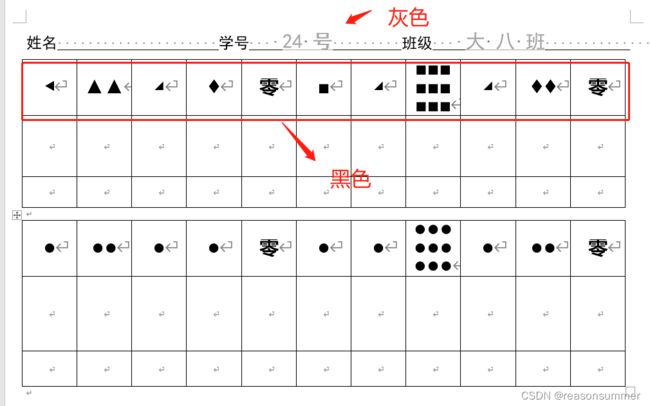
本代码的模板中虽然设置的字体、大小、字号,但都不显示。导入字体的格式都是靠代码内设置
本代码生成的学号和班级默认是黑色字体,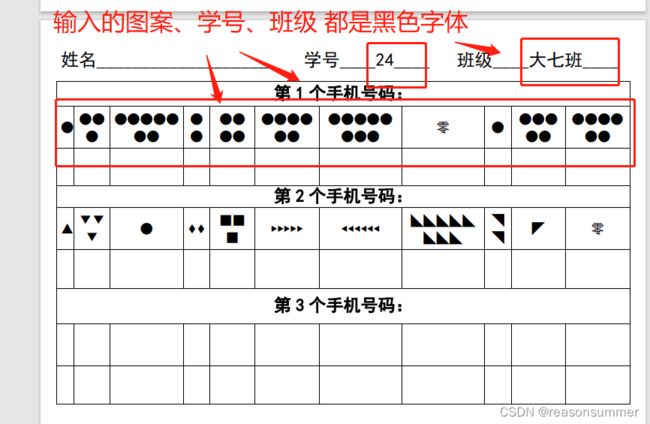
需要在代码里加入灰色的字体的设置 ——幼儿描字帖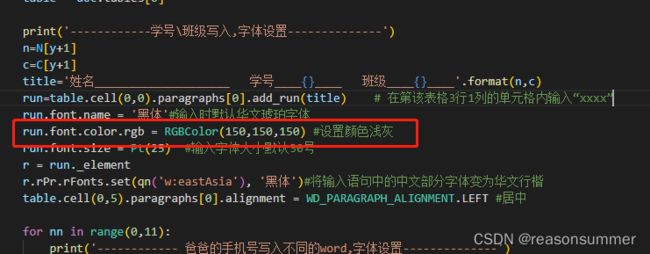

4、打印更便利
唯一的优势大概就是打印方便吧,原来的是打包RAR,现在做成了合并PDF。

教学展示:
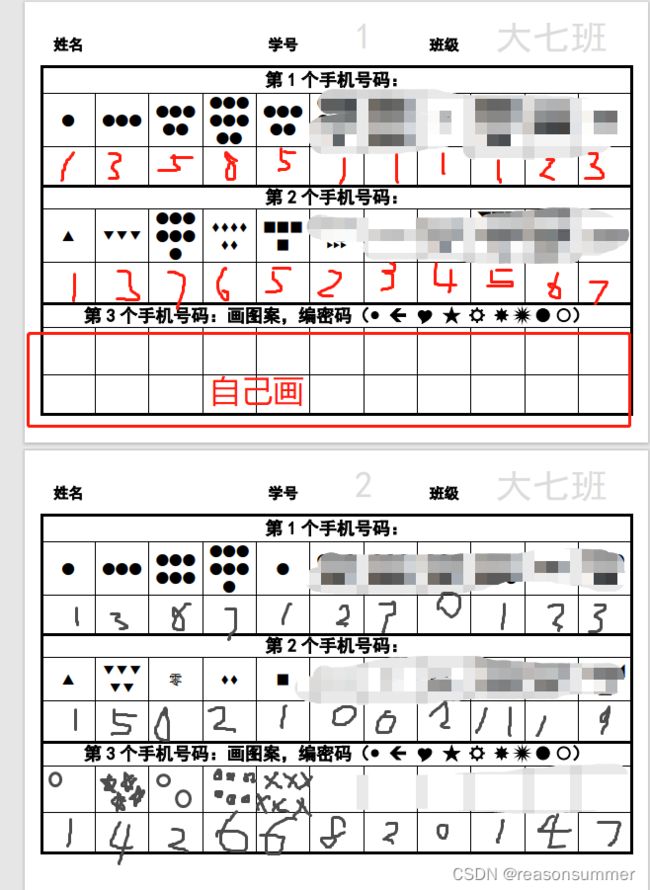
实际教学的大1班。这并不是我自己的班级(代班),我不清楚幼儿的学号(没有学号),但知道幼儿的名字和家长手机号码(1-5个),因此微调代码,个人信息部分显示的是名字和班级(无学号)
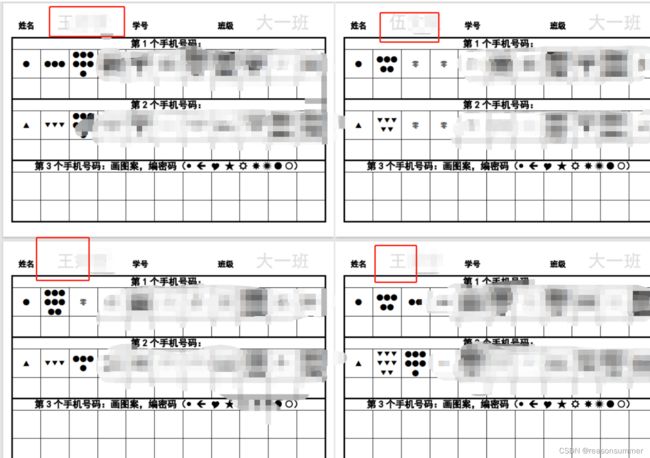
(按姓名首字母排序 B-Z,王姓最多)
实际教学中,因为有灰色打印的姓名和班级,所以幼儿通过描字都写出了自己的名字(2位幼儿不会写名字)和班级(描画感知 大一班三个字的样式)
教学用的代码:(有名字和班级,无学号)
'''
作者:阿夏
时间:2022年11月5日 破译电话号码-图形版-名字和班级(不需要分列,直接导入word)
'''
import openpyxl
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
import os
classroom=input('班级名称(如大1)\n')
print('----------第2步:新建一个临时文件夹------------')
# 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\零时Word')
print('------------读取excle表单--------------')
wb = openpyxl.load_workbook(r'C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\家长电话号码.xlsx')# wb=用openpyxl打开存有号码的ExcelEx
phone = wb.active #phone=获取wb里面的数据
print('------------读取 爸爸的手机号--------------')
symbol_1=['●','●','●', '●', '●', '●','●', '●','●','●','●']
father=[]
for i in list(phone.columns)[4]:# 第3列是爸爸的手机号
phonestr = str(i.value)# 电话字符串 = 第二列的数字的值的字符串形式
print(phonestr)# 打印电话字符串
# Phonenum1
# 13512345678
# 16556345690
# 13724680156
print('------------ 爸爸的手机号的数字全部写在一起--------------')
# for i in phonestr:
col = 0 #
for _ in phonestr:# 在电话字符串里面循环遍历 取各种数字
if i.value!= 'Phonenum1':# 如果电话号码的值不等于'dad' 不要第一行C1
if int(_) != 0:# 如果取出的数字不等于0 等于1-9
str_temp = int(_) * symbol_1[col] # 结果等于 取出的数字的整数 乘以 符号列表的相应列数的符号(批量几个符号)
else:# 如果取出的数字=于0
str_temp = '零'# 0=零
# print( str_temp)
father.append(str_temp)
col +=1
print(father)
# ['●', '●●●', '●●●●●', '●', '●●', '●●●', '●●●●', '●●●●●', '●●●●●●', '●●●●●●●', '●●●●●●●●', '●', '●●●●●●', '●●●●●', '●●●●●', '●●●●●●', '●●●', '●●●●', '●●●●●', '●●●●●●', '●●●●●●●●●', '零', '●', '●●●', '●●●●●●●', '●●', '●●●●', '●●●●●●', '●●●●●●●●', '零', '●', '●●●●●', '●●●●●●']
print('------------读取 妈妈的手机号--------------')
mother=[]
symbol_2 = ['▲','▼','●','♦','■','▶','◀','◣','◥','◤','◢']#
for j in list(phone.columns)[6]:
phonestr = str(j.value)
print(phonestr)
# Phonenum2
# 13214562358
# 15615617891
# 13123568210
print('------------ 妈妈的手机号的数字全部写在一起--------------')
col = 0# 第一个字符串的起始列 123数下去 mum电话的第一位数在第O列=15列
for _ in phonestr[:]:
if j.value != 'Phonenum2':
if int(_) != 0:
str_temp = int(_) * symbol_2 [col]
else:
str_temp = '零'
mother.append(str_temp)
col +=1
print(mother)
# ['▲', '▼▼▼', '●●', '♦', '■■■■', '▶▶▶▶▶', '◀◀◀◀◀◀', '◣◣', '◥◥◥', '◤◤◤◤◤', '◢◢◢◢◢◢◢◢', '▲', '▼▼▼▼▼', '●●●●●●', '♦', '■■■■■', '▶▶▶▶▶▶', '◀', '◣◣◣◣◣◣◣', '◥◥◥◥◥◥◥◥', '◤◤◤◤◤◤◤◤◤', '◢', '▲', '▼▼▼', '●', '♦♦', '■■■', '▶▶▶▶▶', '◀◀◀◀◀◀', '◣◣◣◣◣◣◣◣', '◥◥', '◤', '零']
print('------------ 爸爸的手机号拆开成11个一组的列表--------------')
father_all=[]
for i in range(0,int(len(father)/11)):
b=father[i*11:i*11+11]
father_all.append(b)
print(father_all)
# [['●', '●●●', '●●●●●', '●', '●●', '●●●', '●●●●', '●●●●●', '●●●●●●', '●●●●●●●', '●●●●●●●●'], # ['●', '●●●●●●', '●●●●●', '●●●●●', '●●●●●●', '●●●', '●●●●', '●●●●●', '●●●●●●', '●●●●●●●●●', '零'],['●', '●●●', '●●●●●●●', '●●', '●●●●', '●●●●●●', '●●●●●●●●', '零', '●', '●●●●●', '●●●●●●']]
print('------------ 妈妈的手机号拆开成11个一组的列表--------------')
mother_all=[]
for i in range(0,int(len(mother)/11)):
b=mother[i*11:i*11+11]
mother_all.append(b)
print(mother_all)
# [['▲', '▼▼▼', '●●', '♦', '■■■■', '▶▶▶▶▶', '◀◀◀◀◀◀', '◣◣', '◥◥◥', '◤◤◤◤◤', '◢◢◢◢◢◢◢◢'],
# ['▲', '▼▼▼▼▼', '●●●●●●', '♦', '■■■■■', '▶▶▶▶▶▶', '◀', '◣◣◣◣◣◣◣', '◥◥◥◥◥◥◥◥', '◤◤◤◤◤◤◤◤◤', '◢'],
# ['▲', '▼▼▼', '●', '♦♦', '■■■', '▶▶▶▶▶', '◀◀◀◀◀◀', '◣◣◣◣◣◣◣◣', '◥◥', '◤', '零']]
print('------------读取 学号或者姓名--------------')
N=[]
for i in list(phone.columns)[2]:# 学号-0 班级1 姓名2
phonestr = str(i.value)# 电话字符串 = 第二列的数字的值的字符串形式
N.append(phonestr)
print(N)# ['N', '1', '11', '24']
print('------------读取 班级--------------')
C=[]
for i in list(phone.columns)[1]:# 班级
phonestr = str(i.value)#
C.append(phonestr)
print(C)#['CLASS', '大七班', '大七班', '大七班']
print('------------ 数据导入word,字体设置--------------')
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
for y in range(0,int(len(father)/11)):
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\破译电话号码模板(图案).docx')
wb = pd.read_excel(r'C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\家长电话号码.xlsx')
table = doc.tables[0]
print('------------学号\班级写入,字体设置--------------')
n=N[y+1]
run=table.cell(0,2).paragraphs[0].add_run(n) # 这里的可以代表学号或者名字,把上面连接的数字改掉 姓名02 学号06 班级08
run.font.name = '黑体'#输入时默认华文琥珀字体
run.font.color.rgb = RGBColor(220,220,220) #设置颜色浅灰
run.font.size = Pt(45) #输入字体大小默认30号
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(0,2).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
c=C[y+1]
run=table.cell(0,8).paragraphs[0].add_run(c) # 班级08
run.font.name = '黑体'#输入时默认华文琥珀字体
run.font.color.rgb = RGBColor(220,220,220) #设置颜色浅灰
run.font.size = Pt(45) #输入字体大小默认30号
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(0,8).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
for nn in range(0,11):
print('------------ 爸爸的手机号写入不同的word,字体设置--------------')
f=father_all[y][nn]
print(f)
run=table.cell(2,nn).paragraphs[0].add_run(f) # 在第该表格3行1列的单元格内输入“xxxx”
run.font.name = '黑体'#输入时默认华文琥珀字体
run.font.size = Pt(18) #输入字体大小默认30号
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(2,nn).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
print('------------ 妈妈的手机号写入不g同的word,字体设置--------------')
g=mother_all[y][nn]
print(g)
run=table.cell(5,nn).paragraphs[0].add_run(g) # 在第该表格3行1列的单元格内输入“xxxx”
run.font.name = '黑体'#输入时默认华文琥珀字体
run.font.size = Pt(18) #输入字体大小默认30号
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(5,nn).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\零时Word\{}.docx'.format('%02d'%(y+1)))#保存为XX学号的电话号码word
# docx 文件另存为PDF文件
inputFile = r"C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\零时Word\{}.docx".format('%02d'%(y+1)) # 要转换的文件:已存在
outputFile = r"C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\零时Word\{}.pdf".format('%02d'%(y+1)) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = r"C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\零时Word"
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write(r"C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\(打印合集)破译电话号码-图案版-名字和班级({}班-{}份).pdf".format(classroom,int(len(father)/11)))
file_merger.close()
# doc.Close()
# print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree(r"C:\Users\jg2yXRZ\OneDrive\桌面\破译电话号码\零时Word") #递归删除文件夹,即:删除非空文件夹
教学照片








作品展示:
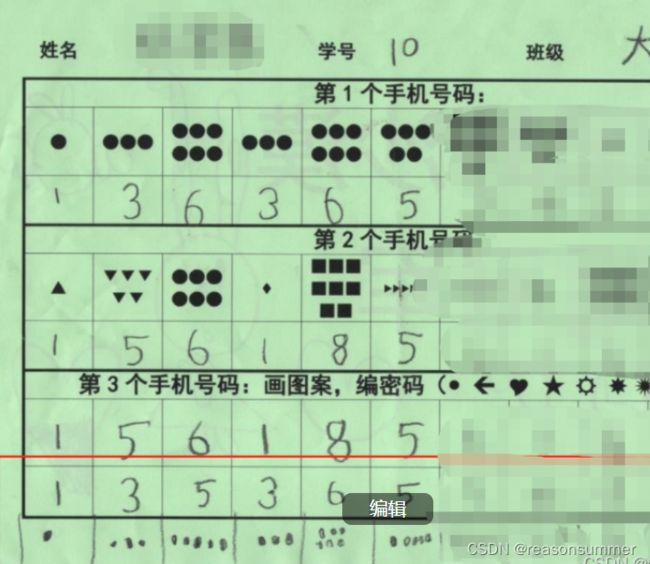
1、幼儿能够完成点数写字
大班幼儿能够根据图形数量点数号码,2位幼儿说“这是我爸爸的号码”“第2个号码是我妈妈的”
2、幼儿愿意尝试自己编号码
(1)图案→数字:随便画图案数量,然后写数字


(2)数字→图案:先写数字,再根据数字画等量的图形


3、图案样式:
(1)单一样式:全部是三角形、实心圆
 (2)多图样式: (几何形、爱心等)
(2)多图样式: (几何形、爱心等)


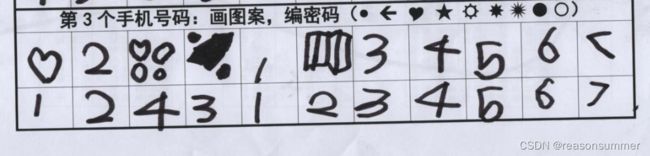 5、画不下怎么办?
5、画不下怎么办?
活动前讲解要求时,就有一位女孩目测判断,提到“这么小的地方不够画”
同伴提出建议:“画小点”“画少一点”
老师建议:画简单的图案,如空心圆、实心圆、纯三角等
(1)超过7个图案挤在一起(只有幼儿自己数的清楚) 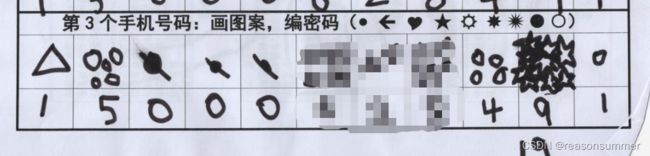

(2)数字多的时候,就用“点”图案。画累了,后面都用1-2个图案填满

(3)幼儿求助老师:“8和9画不下怎么办?”
教师用铅笔给最后两个格子画了九宫格框线,提示幼儿在框线里画简单的图形(圆形,尽量不要五角星)

6、其他:镜像字
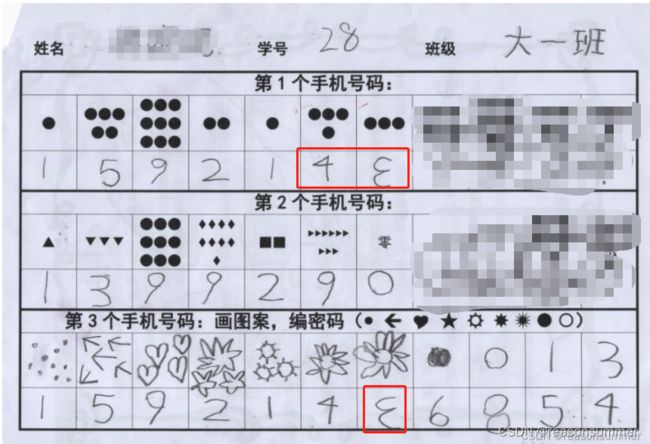
后续思考:
1、限定位置:幼儿自己绘画的图案所在的框线内可以直接用虚线画九宫格,便于幼儿掌握自制图形的大小位置。(但图案必须画简单一点。对幼儿的多图设计有思维限制)
2、列式题破译:其实大班教学参考书上的破译电话号码是“破解加减法数学题”,不是点数图案破译数字,因此我希望把图形替换成“10以内加法题、10以内减法题”。