【OS xv6】2 万字详解xv6如何启动和运行第一个进程(文档第二章文摘+相关源码分析)
【xv6详解】1 Operating system interfaces资料准备见第一篇。还是那句话,仅个人笔记仅记录注意点,完整详解得等后续看有无时间整理。
2 Operating system organization
2.1 Abstracting physical resources
为了做到隔离做了如下:
另一个例子是,Unix 进程使用 exec 来建立它们的内存映像,而不是直接与物理内存交 互。这使得操作系统可以决定将进程放在内存的什么位置;如果内存紧张,操作系统甚至可 能将进程的部分数据存储在磁盘上。Exec 还允许用户将可执行文件储存在文件系统中。
2.2 User mode, supervisor mode, and system calls
操作系统应该能够清理崩溃的应用程 序并继续运行其他应用程序。为了实现强隔离,操作系统必须安排应用程序不能修改(甚至 不能读取)操作系统的数据结构和指令,应用程序不能访问其他进程的内存。
机器模式仅在最开始启动时,后面就转为内核态(监督者模式)。用户态想特权时,会自动切到内核态阻止。
内核控制监督者模式的入口点是很重要的;如果应用程序可以决定内核的入口点,那么恶意应用程序就能够进入内核,例如,通过跳过参数验证而进入内核。
临界区: 要访问使用公共资源,肯定得通过一些代码指令去访问,这些代码指令就是临界区
2.3 Kernel organization
宏内核缺点是我们写bug时会导致系统崩溃。而微内核利用进程通信。
2.4 Code: xv6 organization

内核文件
2.5 Process overview
内核必须小心翼翼地实现进程抽象,因为一个错误或恶意的 应用程序可能会欺骗内核或硬件做一些不好的事情(例如,规避隔离)。
让每一个进程独立,使其有各自的地址(虚拟地址)
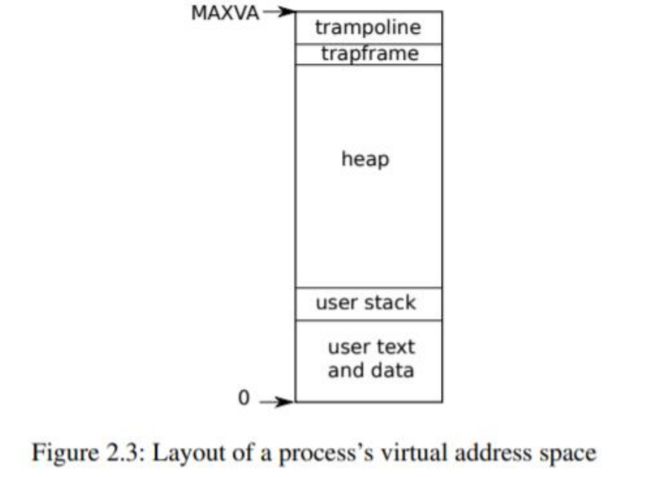
这是给每个进程的虚拟地址空间,从0开始,先放用户代码和数据,然后栈和堆,接下来(最后一页)是用户内核态切换汇编代码和映射进程 trapframe 。
每个进程 有两个栈:用户栈和内核栈(p->kstack)。当进程在执行用户指令时,只有它的用户栈在使 用,而它的内核栈是空的。当进程进入内核时(为了系统调用或中断),内核代码在进程的 内核栈上执行;当进程在内核中时,它的用户栈仍然包含保存的数据,但不被主动使用。进 程的线程在用户栈和内核栈中交替执行。内核栈是独立的(并且受到保护,不受用户代码的 影响),所以即使一个进程用户栈被破坏了,内核也可以执行。
一个进程可以通过执行 RISC-V ecall 指令进行系统调用。该指令提高硬件权限级别,并 将程序计数器改变为内核定义的入口点。入口点的代码会切换到内核栈,并执行实现系统调 用的内核指令。当系统调用完成后,内核切换回用户栈,并通过调用 sret 指令返回用户空 间,降低硬件特权级别,恢复执行系统调用前的用户指令
2.6 Code: starting xv6 and the first process
自己补充了解
qemu
Linux云计算底层技术之一文读懂 Qemu 模拟器 - 知乎 (zhihu.com)
纯软件,模拟硬件设备,虚拟机与qemu模拟出来的硬件打交道,qemu把指令转译给真正硬件。所以性能低,生产环境一般它只负责I/O虚拟化。
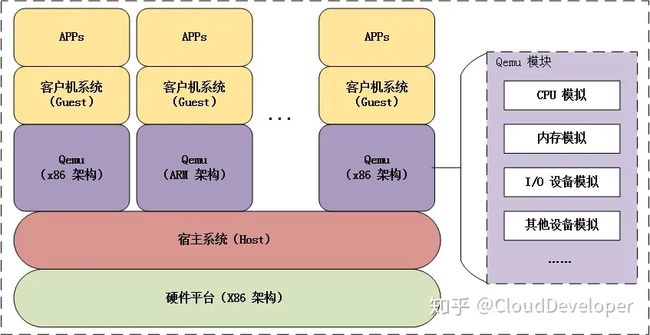
qemu结构
每个虚拟机对应主机上一个qemu进程,而虚拟机的执行线程(如 CPU 线程、I/O 线程等)对应 Qemu 进程的一个线程。
字节、字、字长
字节:即byte为8位,8位1节
字:计算机进行数据处理时,一次存取、加工和传送的数据长度称为字(word),字节整数倍。
计算机组成原理——机器字长、指令字长、存储字长_1.虚拟仿真环境的机器字长及存储字长各是多少位的?_白芷加茯苓的博客-CSDN博客
字长:字的长度,一般代指机器字长即微处理器对外数据通路的数据总线条数(CPU内部数据通路的宽度),也就是运算器进行定点数运算的字长。现代计算机的字长通常为16、32、64位。早期的微机字长一般是8位和16位,386以及更高的处理器大多是32位。市面上的计算机的处理器大部分已达到64位。(机器)字长直接反映了一台计算机的计算精度,为适应不同的要求及协调运算精度和硬件造价间的关系,大多数计算机均支持变字长运算,即机内可实现半字长、全字长(或单字长)和双倍字长运算。在其他指标相同时,字长越大计算机的处理数据的速度就越快(因为可以一次性处理更多位)。
机器字长通常与主存单元的位数一致(方便取),但也可以不同。不同的情况下,一般是主存储器字长小于机器字长,例如机器字长是32位,主存储器字长可以是32位,也可以是16位,当然,两者都会影响CPU的工作效率。
指令字长:一个指令位数。
早期计算机的存储字长一般和机器的指令字长与数据字长相等,故访问一次主存便可取一条指令或一个数据。随着计算机的应用范围的不断扩大,解题精度的不断提高,往往要求指令字长是可变的,数据字长也要求可变。为了适应指令和数据字长的可变性,其长度不由存储字长来确定,而用字节的个数来表示。1个字节(Byte)被定义为由8位(Bit)二进制代码组成。当然,此时存储字长、指令字长、数据字长三者可各不相同,但它们必须是字节的整数倍。
指令字长等于机器字长的指令,称为单字长指令;
指令字长等于半个机器字长的指令,称为半字长指令;
指令字长等于两个机器字长的指令,称为双字长指令。
例如,IBM370系列,它的指令格式有16位(半字)的,有32位(单字)的,还有48位(一个半字)的。
早期计算机使用多字长指令的目的,在于提供足够的地址来解决访问内存任何单元的寻址问题。但是使用多字长指令的缺点是必须两次或三次访问内存以取出一整条指令,这就降低了CPU的运算速度,同时又占用了更多的存储空间。
在一个指令系统中,如果各种指令字长是相等的,称为等长指令字结构,它们可以都是单字长指令或半字长指令。这种指令字结构简单,且指令字长度是不变的。如果各种指令字长度随指令功能而异,就称为变长指令字结构。这种指令字结构灵活,能充分利用指令长度,但指令的控制较复杂。随着技术的发展,指令字长度逐渐变成多于32位的固定长度。
指令字长固定:指令字长小于等于存储字长
指令字长可变:按字节的倍数变化
存储字长
存储字长:
一个存储单元存储二进制代码的位数。存储字长可以是8位、16位、32位等。早期计算机的存储字长一般和机器的指令字长与数据字长相等,故访问一次主存便可取一条指令或一个数据。随着计算机的应用范围的不断扩大,解题精度的不断提高,往往要求指令字长是可变的,数据字长也要求可变。为了适应指令和数据字长的可变性,其长度不由存储字长来确定,而由字节的个数来表示。
————————————————
版权声明:本文为CSDN博主「白芷加茯苓」的原创文章
原文链接: https://blog.csdn.net/qq_43627631/article/details/106738058
asm volatile
汇编可变,asm代表嵌入汇编语句,volatile代表不可被GCC优化掉,常见于内核源码,一般自己简单运算别轻易加,避免无法使用GCC优化。
asm volatile ( " instructions " ) 语法 - 简书 (jianshu.com)
C/C++里格式
asm volatile("InSTructiON List":Output:Input:Clobber/Modify);汇编命令可用','隔开多条,输入输出接口(C语言变量)可以写在Output:Input,可缺省,但如果要使用其中任意一个就都需要加上3个冒号;最后一个是“重写/修改”,指告诉GCC哪些变量、寄存器、内存如“memory”,会改变需要关注(前面Input和Output的寄存器声明了这里就可以不写),避免没修改成功而不一致。
int main(int __argc, char* __argv[])
{
int* __p = (int*)__argc;
(*__p) = 9999;
__asm__("":::"memory");//提醒GCC关注内存变化,而避免第6行直接被优化掉
if((*__p) == 9999)
return 5;
return (*__p);
}
//另外在linux内核中内存屏障也是基于它实现的include/asm/system.h中,主要是保证程序的执行遵循顺序一致性。
# define barrier() *asm__volatile*("": : :"memory")
int a=10, b;
asm ("movl %1, %%eax;
movl %%eax, %0;" //b=a,a是%1,b是%0;寄存器名前有两个%,操作数有一个%作为前缀。
:"=r"(b) /* output. "="表示它是输出操作数,且只能写。“r”告诉GCC使用任何寄存器来存储操作数。“asm”内部对“b”所做的更改应该反映在“asm”外部。*/
:"r"(a) /* input */
:"%eax" /* clobbered register %eax的值将在“asm”中修改,因此GCC不会使用这个寄存器来存储任何其他值。*/
);TLB
虚拟地址和物理地址
每个程序获得私有的虚拟地址空间,用来保存 经常访问的代码和数据 ,与其他程序隔离 。就是说在进程里不会直接用物理地址,物理地址也很碎,我们又往往想要完整连续内存,用虚拟地址封装会更好。同时我们不应该访问到其他进程和内容的物理地址,用虚拟地址映射会更好。这些空间存代码映射和数据。
从零开始写 OS (6) —— 页表简介 - 知乎 (zhihu.com)
大概搞清楚了,虚拟地址能更好的隔离(我们能打印和操作的)和利用切碎的物理内存段,那么需要页表映射二者(每个内存的进程都有一个在内存的页表;另外每页是固定大小,如4kb)。2种地址后12位都是偏移,虚拟内存前20位为VPN(virtual page number)虚页号,即页表序号;该页表序号对应的页表上的页表项即记录着对应物理地址所在页(该物理内存页我们一般称作帧),当然也会有其他状态位(引用、脏数据未写回等)。
内存说白就是大一点cache,那自然也会有miss的情况(该数据没在内存,还在磁盘),这时就是缺页(内存缺乏该页)[我觉得应该是后面没内存只能放磁盘了,每次虚拟内存要用只能跑到磁盘拿]。
PTE是页表。TLB是快表:地址变换高速缓存 Translation Look-aside Buffer 。就是针对页表映射的cache,让那些常用的地址映射保存。引用位表示近期有用过。
这些知识够用当前这个实验了,其余的就不再扩展了。
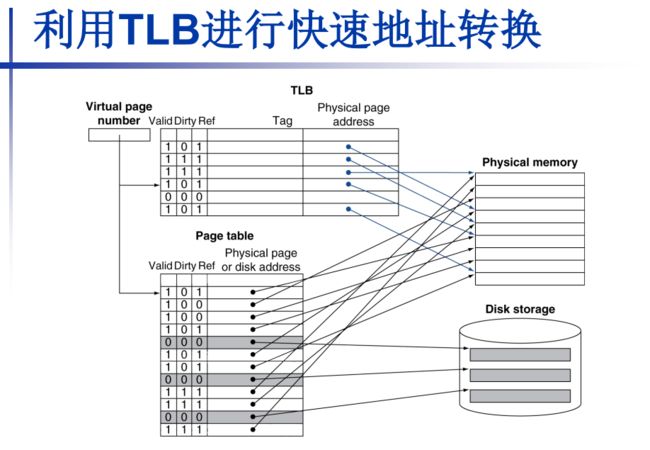
TLB快表/地址变换高速缓存 Translation Look-aside Buffer就是针对页表映射的cache,让那些常用的地址映射保存
这是虚拟地址前20位虚页号VPN会指向TLB和页表
内存管理机制-分页(页表) - 知乎 (zhihu.com)
当多个进程同时在运行时,每个进程的内存都会经历从磁盘换入内存,从磁盘换出内存的过程,为什么需要这种换入换出操作呢,原因是我们的内存空间是有限的,为了给活跃的进程腾出运行空间我们必须要将不活跃进程所占据的内存从物理内存中移出。
超硬核,进程在内存中的样子!以及进程的一生 - 知乎 (zhihu.com)
当一个进程要使用某块内存时,它会将自己世界里的一个内存地址告诉操作系统,剩下的事情就由操作系统接管了。操作系统中的内存管理策略将决定映射哪块真实的物理内存,供其使用。操作系统会竭尽全力满足所有进程合法的内存访问请求。一旦发现进程试图访问非法内存,操作系统会把进程杀死,防止它做“坏事”影响到系统或其它进程。
当用户在 Shell 下输入一条命令启动指定程序时,Shell 就是先 fork() 了自身进程,然后在子进程中使用 execve() 来运行指定的程序。
需要注意的是,exec 系列函数的返回值只在遇到错误的时候才有意义。如果新程序成功地被执行,那么当前进程的所有数据就都被新进程替换掉了,所以永远也不会有任何返回值。
对于执行 exec() 函数的应用,应该总是使用内核为文件提供的执行时关闭标志(FD_CLOEXEC)。设置了该标志之后,如果 exec() 执行成功,文件就会被自动关闭;如果 exec() 执行失败,那么文件会继续保持打开状态。使用系统调用 fcntl() 可以设置该标志。
3. 监控子进程状态
在 Linux 应用中,父进程需要监控其创建的所有子进程的退出状态,可以通过如下几个系统调用来实现。
pid_t wait(int * statua)
一直阻塞地等待任意一个子进程退出,返回值为退出的子进程的 ID,status 中包含子进程设置的退出标志。
pid_t waitpid(pid_t pid, int * status, int options)
可以用 pid 参数指定要等待的进程或进程组的 ID,options 可以控制是否阻塞,以及是否监控因信号而停止的子进程等。
int waittid(idtype_t idtype, id_t id, siginfo_t *infop, int options)
提供比 waitpid 更加精细的控制选项来监控指定子进程的运行状态。
wait3() 和 wait4() 系统调用
可以在子进程退出时,获取到子进程的资源使用数据。
更详细的信息请参考帮助手册。
重点讨论:即使父进程在业务逻辑上不关心子进程的终止状态,也需要使用 wait 类系统调用,原因如下:
在 Linux 的内核实现中,允许父进程在子进程创建之后的任意时刻用 wait() 系列系统调用来确定子进程的状态。
也就是说,如果子进程在父进程调用 wait() 之前就终止了,内核需要保留该子进程的终止状态和资源使用等数据,直到父进程执行 wait() 把这些数据取走。
在子进程终止到父进程获取退出状态之间的这段时间,这个进程会变成所谓的僵尸状态,在该状态下,任何信号都无法结束它。如果系统中存在大量此类僵尸进程,势必会占用大量内核资源,甚至会导致新进程创建失败。
如果父进程也终止,那么 init 进程会接管这些僵尸进程并自动调用 wait ,从而把它们从系统中移除。但是对于长期运行的服务器程序,这一定不是开发者希望看到的结果。所以,父进程一定要仔细维护好它创建的所有子进程的状态,防止僵尸进程的产生。
一般先fork()一个子进程,在子进程execve()用新程序替代该进程(写时复制可以避免浪费)。但需要保存关闭之前的数据。
启动和运行第一个进程
本来组内大佬师妹搞完了这部分了,我闲烦没细看,现在读到文档还是好好研究吧,遇到知识盲区进行补充查阅上面已经搞了,找到2篇不错的博客
xv6-riscv-源代码阅读.进程线程 | Banbao (banbao991.github.io)
xv6 系统启动代码分析(MIT 6.S081 FALL 2020)_xv6 entry.s_菜籽爱编程的博客-CSDN博客
外加师妹题解和官方文档,我对该部分源码做了解析。问了助教可以跳过汇编,那我们就看注释就行
当 RISC-V 计算机开机时,它会初始化自己,并运行一个存储在只读存储器中的 boot loader(引导加载程序,启动装载,存在 ROM 里面)。注意由于只有一个内核栈,内核栈部分的地址空间可以是固定,因此 xv6 启动的时候并没有开启硬件支持的 paging 策略,也就是说,对于内核栈而言,它的物理地址和虚拟地址是一样的。
Boot loader 将 xv6 内核加载到内存中。然后,在机器模式下,CPU 从 _entry (kernel/entry.S:6,如下)开始执行 xv6。
首先需要给内核开辟一个内核栈,从而可以执行 C 代码。
每一个 CPU 都应该有自己的内核栈(xv6 最多支持 8 个 CPU),开始每个内核栈的大小为 4096 byte,地址空间向下增长。
之所以将内核放在0x80000000 而不是 0x0,是因为地址范围 0x0-0x80000000 包含 I/O 设备。
kernel/entry.S注释解析
# kernel/entry.S
# qemu -kernel loads the kernel at 0x80000000【qemu -kernel装载内核到0x80000000】
# and causes each hart (i.e. CPU) to jump there.【然后让每个硬件线程(即真实CPU提供的一种模拟)跳到这里】
# kernel.ld causes the following code to【kernel.ld文件实现以上】
# be placed at 0x80000000.
.section .text
.global _entry
_entry:
# set up a stack for C.【设置C语言堆栈】
# stack0 is declared in start.c,【stack0在start.c里声明,它是全部核的栈】
# with a 4096-byte stack per CPU.
# sp = stack0 + (hartid * 4096)【栈指针到栈顶,向下扩张】
# la(加载地址或标号到寄存器中)加载了stack0的地址
# 然后用li(加载立即数到寄存器中)得到每个CPU所拥有栈空间的大小4096bytes
# 使用csrr指令获取当前CPU核心的ID(mhartid是寄存当前CPU核心ID的寄存器)。
# 使用addi指令将ID+1,这是因为ID从0开始
# 由于分配给每个CPU核心的地址是连续的,它们的栈也是连续的,只需将每个核心的堆栈大小乘ID+1,再加上初始的栈指针地址,即可得到指向这个CPU核心栈起始地址的指针。
la sp, stack0
li a0, 1024*4
csrr a1, mhartid
addi a1, a1, 1
mul a0, a0, a1
add sp, sp, a0
# jump to start() in start.c
call start
spin:
j spinkernek/start.c注释解析
#include "types.h"
#include "param.h"
#include "memlayout.h"
#include "riscv.h"
#include "defs.h"
//执行一些只有在机器模式下才允许的配置,然后切换到监督者模式。
void main();
void timerinit();
// entry.S needs one stack per CPU.【entry.s需要给每个CPU一个栈】它要求 16bit 对齐。【stack0就是全部CPU的栈数组,这里可以看到每个栈需要4096bytes字节(所以用char)】
__attribute__ ((aligned (16))) char stack0[4096 * NCPU];
// a scratch area per CPU for machine-mode timer interrupts.下面一行定义了共享变量,即每个 CPU 的缓存区scratch用于 machine-mode 定时器中断,它是和 timer 驱动之间传递数据用的。
uint64 timer_scratch[NCPU][5];
// assembly code in kernelvec.S for machine-mode timer interrupt.下一行声明了 timer 中断处理函数,在接下来的 timer 初始化函数中被用到。
extern void timervec();
// entry.S jumps here in machine mode on stack0.
void
start()
{
// set M Previous Privilege mode to Supervisor, for mret.首先将CPU的M模式设置为超级用户模式(设置寄存器 mstatus 中的 MPP 位为 supervisor mode),便于后续执行mret指令时为超级用户模式。
unsigned long x = r_mstatus(); //【获取mstatus寄存器】
x &= ~MSTATUS_MPP_MASK; //清空寄存器 mstatus 中的 MPP[12:11]
x |= MSTATUS_MPP_S; //设置寄存器 mstatus 中的 MPP 位为 supervisor mode(01)
w_mstatus(x); //保存(写寄存器)
// set M Exception Program Counter to main, for mret.将CPU的M异常程序计数器(MEPC)设置为main函数,用于后续mret函数跳转到main函数执行。
// requires gcc -mcmodel=medany 接下来的一行代码设置了汇编指令(将机器异常程序计数器写为main) mret 后 PC 指针跳转的函数,也就是 main 函数。
w_mepc((uint64)main);
// disable paging for now.禁用分页机制(虚拟地址页表)。即直接使用物理地址。便于在启动过程中忽略虚拟内存的配置。
w_satp(0);
// delegate all interrupts and exceptions to supervisor mode. 将所有中断异常处理设定在给 supervisor mode 下。再将所有的中断和异常委托给超级用户模式处理,便于让内核代码处理所有的中断和异常。
w_medeleg(0xffff);
w_mideleg(0xffff);
w_sie(r_sie() | SIE_SEIE | SIE_STIE | SIE_SSIE);
// configure Physical Memory Protection to give supervisor mode 配置物理内存保护(PMP),
// access to all of physical memory.让超级用户模式拥有对所有物理内存的访问权限。
w_pmpaddr0(0x3fffffffffffffull);
w_pmpcfg0(0xf);
// ask for clock interrupts.初始化时钟中断(用于进程轮换),请求时钟中断,也就是 clock 的初始化。便于操作系统在运行时定期接收时钟中断,实现系统调度和时间管理等。
timerinit();
// keep each CPU's hartid in its tp register, for cpuid().将 CPU 的 ID 值保存在寄存器 tp 中
int id = r_mhartid();
w_tp(id);
// switch to supervisor mode and jump to main().【换成内核态并跳到main()】
asm volatile("mret");
}
// arrange to receive timer interrupts.设置接收定时器中断
// they will arrive in machine mode at
// at timervec in kernelvec.S, 在机器模式进入kernel/kernelvec.S:timervec
// which turns them into software interrupts for
// devintr() in trap.c.从而转为软件中断去调用kernel/trap.c:devintr()
void
timerinit()
{
// each CPU has a separate source of timer interrupts.每个CPU都有一个单独的定时器中断源。
int id = r_mhartid(); //【当前核】
// ask the CLINT for a timer interrupt.设置中断时间间隔CLINT_MTIMECMP(id),这里设置的是 0.1 秒
int interval = 1000000; // cycles; about 1/10th second in qemu.
*(uint64*)CLINT_MTIMECMP(id) = *(uint64*)CLINT_MTIME + interval;
// prepare information in scratch[] for timervec.利用刚才在文件开头声明的 timer_scratch 变量,把刚才的 CPU 的 ID 和设置的中断间隔设置到 scratch 寄存器中,以供 clock 驱动使用。
// scratch[0..2] : space for timervec to save registers.
// scratch[3] : address of CLINT MTIMECMP register. CLINT MTIMECMP寄存器地址(时间间隔相关寄存器)
// scratch[4] : desired interval (in cycles) between timer interrupts.时间间隔
uint64 *scratch = &timer_scratch[id][0]; //【缓存区】
scratch[3] = CLINT_MTIMECMP(id);
scratch[4] = interval;
w_mscratch((uint64)scratch);
// set the machine-mode trap handler.设置中断处理函数
w_mtvec((uint64)timervec);
// enable machine-mode interrupts.打开中断
w_mstatus(r_mstatus() | MSTATUS_MIE);
// enable machine-mode timer interrupts.打开时钟中断
w_mie(r_mie() | MIE_MTIE);
}
大大总结的很好:

https://banbao991.github.io/2021/04/04/OS/xv6-source-code/02-Process-Thread/
kernel/main.c注释解析
#include "types.h"
#include "param.h"
#include "memlayout.h"
#include "riscv.h"
#include "defs.h"
volatile static int started = 0;
// start() jumps here in supervisor mode on all CPUs.main() 函数中首先进行很多属性的配置,然后通过 usetinit() 创建第一个进程。对任意一个 CPU,我们需要配置它一些系统属性
void
main()
{
if(cpuid() == 0){ //首先,判断当前的 CPU 的 ID 是否为主 CPU 。
consoleinit(); //控制台初始化(锁, uart寄存器配置)
printfinit(); //打印模块初始化,配置 printf 属性(锁)
printf("\n");
printf("xv6 kernel is booting\n");
printf("\n");
kinit(); // physical page allocator物理页分配策略的初始化(锁, 开辟空间)
kvminit(); // create kernel page table创建内核页表(19-20), 新建一个内核的物理页表, 调用 kalloc() 生成一个页表(4096 byte).通过调用 kvmmake() 设置一些固定的函数入口。对内核而言, 使用虚拟地址直接映射到物理地址的内核页表映射策略
kvminithart(); // turn on paging打开分页机制
procinit(); // process table创建进程表
trapinit(); // trap vectors初始化中断异常处理程序的一些配置(锁)
trapinithart(); // install kernel trap vector见40行
plicinit(); // set up interrupt controller设置响应外部中断的处理程序。23-25设置系统中断向量和系统中断初始化
plicinithart(); // ask PLIC for device interrupts设备中断初始化 3. 打开对外部中断的响应
binit(); // buffer cache磁盘缓冲初始化, 新建 cache, 双向链表形式组织, 锁
iinit(); // inode table磁盘节点的初始化,inode cache文件列表 cache, 锁
fileinit(); // file table文件系统的初始化,文件表(锁)
virtio_disk_init(); // emulated hard disk磁盘初始化
userinit(); // first user process创建第一个用户进程,第一个进程执行一个小程序 user/initcode.S ,该程序通过调用 exec 系统调用重新进入内核;
__sync_synchronize(); //gcc 提供的原子操作,保证内存访问的操作都是原子操作
started = 1; //设置初始化完成的标志
} else {
while(started == 0)
; //首先循环等待主 CPU 初始化完成,当主 CPU 初始化完成,则初始化完成标志 started 为 1 ,跳出循环。
__sync_synchronize();//gcc 提供的原子操作,保证内存访问的操作都是原子操作
printf("hart %d starting\n", cpuid());
kvminithart(); // turn on paging打开分页功能1. 打开硬件支持的 paging 策略。但是对于内核而言, 使用的策略是虚拟地址直接映射到相同的物理地址。通过 w_satp(MAKE_SATP(kernel_pagetable))
trapinithart(); // install kernel trap vector设置系统中断初始化 2. 装载中断处理函数指针, 内核态的中断处理程序设置为 kernelvec
plicinithart(); // ask PLIC for device interrupts设置设备的中断初始化 3. 打开对外部中断的响应
}
scheduler();
}
kernel/proc.c:userinit()
然后得来看一下userinit()(创建第一个用户进程,第一个进程执行一个小程序),在kernel/proc.c,那么还是绕不过看proc.c及proc.h,我发现里面的一些锁知识真的超纲了,只能将就的研究一下。
kernel/proc.h
首先先看proc.h,先是定义内核切换上下文结构体content,里面包含会用到的保护寄存器,包括返回地址ra、栈指针sp、和s0-s11共12个寄存器。接下来定义CPU结构体,里面记录了每个CPU的 状态,包括CPU上运行的进程,也可能无进程;上面说的上下文,所以每个CPU都有一套寄存器;noff是申请禁用中断的数目(未配对解禁),也即push_off()禁止中断调用的次数减去pop_off()取消中断的次数,剩余的禁止中断数目。这个部分是我们在操作进程的时候,每次上各种锁(acquire(lock))都需要强调一下禁止中断(硬中断可以打断进程上下文,所以进程上下文中访问共享数据需要禁止中断;考虑如下情况,当进程上下文中获取到锁,之后被硬中断打断,硬中断此时尝试获取锁,因为锁已经被进程上下文持有,硬中断获取不到,产生死锁;)。只有这些都取消“禁止中断”才是真的取消,才可以恢复到取消之前的中断使能情况(可能使能也可能不使能)。那么我们就需要在第一次调用push_off()[禁止中断]时(即noff==0)保留当时的未禁用前的中断使能情况在intena。每次调用push_off()则noff++,调用pop_off()则noff--,这样也能保证配对问题。当noff减为0时说明完全取消中断禁止,利用intena回复禁止前的使能状况(即当intena非0表示原为使能,那么进行使能操作)。
cpus是全部核数组。
接下来定义用于trampoline.S(用户内核态切换跳转汇编文件)的每个进程数据结构体trapframe【切换跳转帧】,trapframe 的作用是在用户态进入内核态的时候保存其所有的寄存器。它会被保存在用户页表最后一页,在trampoline的下边。它不用特意映射到内核页表,【因为它是用于用户态切到内核态】。
在trampoline.S(用户内核态切换跳转汇编文件)中,uservec会将用户寄存器保存在trapframe,然后初始化trapframe的kernel_satp(内核页表)、kernel_sp(进程内核栈栈顶)、kernel_hartid(内核id),并跳到kernel_trap(我怀疑这个存的是地址?)。
10. 自制操作系统: risc-v Supervisor寄存器sstatus/stvec/sip/sie_richard.dai的博客-CSDN博客
stvec
全称: Supervisor Trap Vector Base Address Register
stvec是一个SXLEN-bit 的读写寄存器,其保存trap向量,其中包括向量基地址(base)和向量模式(Mode)

BASE是一个WARL字段,可以填充有效的虚拟或者物理地址,对齐条件如下:
1、地址必须4字节对齐
2、direct之外的mode设置,可能对对齐条件产生额外的约束。

Mode的编码如上图。
1.Mode=Direct时,所有进入s-mode的traps,pc都将会设置为stvec中的BASE。
2.当Mode=Vectored时,
2.1 所有进入s-mode的同步异常,pc将设置为stvec的BASE
2.2 如果是产测了中断,pc将设置为中断源编码乘以4+BASE
————————————————
版权声明:本文为CSDN博主「richard.dai」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接: https://blog.csdn.net/dai_xiangjun/article/details/123967946
最后进程状态数组和进程结构体就不展开说了。
kernel/proc.c:userinit()
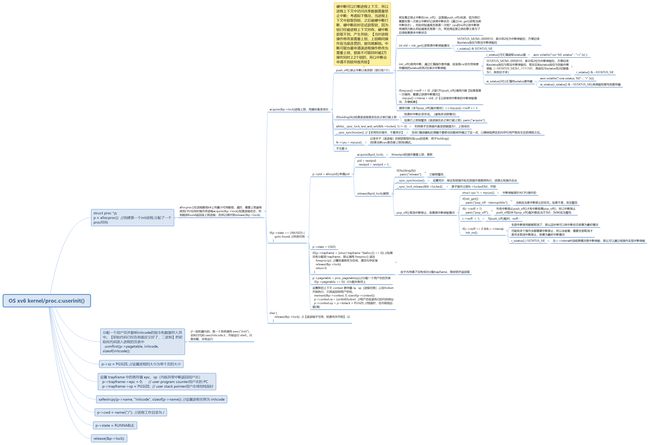
kernel/proc.c:userinit()
最后返回 kernel/main.c 中执行进程调度程序 scheduler()调度之后才开始运行上面加载的机器代码
之后如果想创建进程的化,都需要通过 shell 调用 exec() 实现
后言
唉,回炉重造2周这次是真的吃的透透了,只能说当年发明出os的真不是人,这么多逻辑不会把自己给绕死咩,单单看下就有种生无可恋的感觉。搞了快一周了,呜呜呜我的毕设怎么办啊来不及啊啊啊啊。