大数据数据表的水平分表与分区
1.需求描述
crm_msgqueue 每天会有大量的数据,数据量越来越大,从而数据库可能产生性能问题。需要对该表进行分表操作,来提高数据库性能。
2.方案参考
2.1 水平分表
将表中的数据按照水平分割的方式分配到多张表中。表的数据结构相同,数据不同,表的并集是全部数据。
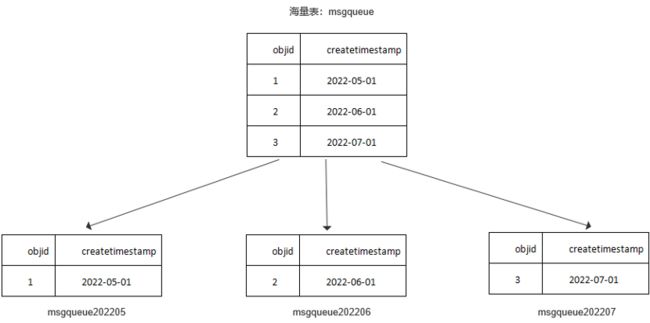 图 水平分表
图 水平分表
msgqueue是总表,下面是三个独立的分表。
取数据的时候我们可以通过总表来取。总表是没有myd,myi 这两个文件,它不是一张表,没有数据(可以理解成:总表是一个外壳,或者是连接池);
通过主表查询时,相当于将所有子表合在一起查询,这种不能体现分表的优势,建议还是查询子表;
2.2.1 优缺点
优点:
- 单表并发能力提高,总表可以根据不同的查询,将并发压力分到不同的小表里面;
- 提高磁盘的I/O性能, 原来一个很大的myd(表数据)文件分摊到了各个小表的myd中;
缺点:
- 产生较多的数据表;
- 子表查询方式需要在代码层进行操作;
- 需要手动创建子表;
2.2.2 具体步骤
根据月份切割数据表,查询时查询相应的子表。原数据表的表结构为:
TABLE `msgqueue` (
`objid` decimal(20, 0) NOT NULL,
`content` varchar(4000) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
`createtimestamp` datetime NOT NULL,
UNIQUE INDEX `MSGQUEUE`(`objid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;- 创建相应的数据库,crm_msgqueue202205、crm_msgqueue202206、crm_msgqueue202207。
DROP TABLE IF EXISTS `msgqueue202205`;
CREATE TABLE `msgqueue202205` (
`objid` decimal(20, 0) NOT NULL,
`content` varchar(4000) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
`createtimestamp` datetime NOT NULL,
UNIQUE INDEX `MSGQUEUE202205`(`objid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;crm_msgqueue202206、crm_msgqueue202207 类似创建该创建语句。
- 把数据分到分表中
INSERT INTO msgqueue202205 SELECT * FROM msgqueue WHERE createtimestamp >= '2022-05-01 00:00:00' AND createtimestamp <= '2022-05-31 23:59:59'crm_msgqueue202206、crm_msgqueue202207 类似创建该创建语句。
- 数据迁移结果对比
SELECT * FROM msgqueue T1
LEFT JOIN
(SELECT * FROM msgqueue202205) T2
ON T1.objid = T2.objid
WHERE (T1.createtimestamp >= '2022-05-01 00:00:00' AND T1.createtimestamp <= '2022-05-31 23:59:59')
AND (T2.objid IS NULL OR T2.createtimestamp IS NULL OR
T1.objid != T2.objid OR T1.content != T2.content OR T1.createtimestamp != T2.createtimestamp)crm_msgqueue202206、crm_msgqueue202207 类似创建该创建语句。
- 数据的插入与查询
插入:
String tableName = "msgqueue" + new SimpleDateFormat("yyyyMM").format(new Date()).toString()
String sql = "INSERT INTO" + tableName + "(objid,content, createtimestamp) VALUES(134556,'', '2022-07-01 12:00:00')"查询:
时间范围:2022-05-15 ~ 2022-07-31
String select1 = "SELECT * FROM msgqueue202205 WHERE createtimestamp >= 2022-05-15 00:00:00";
String select2 = "SELECT * FROM msgqueue202206 ";
String select3 = "SELECT * FROM msgqueue202207 WHERE createtimestamp <= 2022-07-31 00:00:00";
String sql = select1 + " UNION ALL " + select2 + " UNION ALL " + select3;2.2 水平分区
将一个数据表按照某种规则划分多个区块,各个区块所属的数据文件是相互独立的。分区之后的表还是一张表。
图 水平分区
2.2.1 限制条件
mysql版本: 5.1+;
range分区的字段必须是要包含在主键当中, 8.0版本可以使用DATE or DATETIME 作为 range 的分区字段;
MERGE引擎不支持分区,分区表也不支持merge;
FEDERATED引擎不支持分区。这限制可能会在以后的版本去掉;
CSV引擎不支持分区;
BLACKHOLE引擎不支持分区;
在NDBCLUSTER引擎上使用分区表,分区类型只能是KEY(or LINEAR KEY) 分区;
当升级MYSQL的时候,如果你有使用了KEY分区的表(不管是什么引擎,NDBCLUSTER除外),那么你需要把这个表dumped在reloaded;
不支持外键。MYSQL中,INNODB引擎才支持外键;
不支持FULLTEXT indexes(全文索引),包括MYISAM引擎;
不支持spatial column types;
分区键必须是INT类型,或者通过表达式返回INT类型,可以为NULL。唯一的例外是当分区类型为KEY分区的时候,可以使用其他类型的列作为分区键( BLOB or TEXT 列除外);
2.2.2优缺点
优点:
1)改善查询性能,对分区对象的查询可以仅搜索自己关心的分区,提高检索速度;
2)增强可用性,如果表的某个分析出现故障,表在其他分析的数据仍然可用;
3)维护方便,如果表某个分区出现故障,需要修复数据,只修复该分区即可;
4)均衡I/O,可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能;
5)不需要修改代码,只需要操作数据库;
缺点:
1)存放数据的区块变多;
2.3.3 具体步骤
版本要求: mysql 5.5+
按range分区,分区字段为createtimestamp,表结构:
TABLE `msgqueue` (
`objid` decimal(20, 0) NOT NULL,
`content` varchar(4000) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
`createtimestamp` datetime NOT NULL,
UNIQUE INDEX `MSGQUEUE`(`objid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;1.删除 objid 唯一索引:
DROP INDEX MSGQUEUE ON msgqueue;- 添加分区,按range分区,分区字段为createtimestamp
ALTER TABLE msgqueue
PARTITION BY RANGE COLUMNS(createtimestamp)
(
PARTITION msgqueue202205 VALUES less than ('2022-06-01 00:00:00'),
PARTITION msgqueue202206 VALUES less than ('2022-07-01 00:00:00'),
PARTITION msgqueue202207 VALUES less than ('2022-08-01 00:00:00')
)3 查看分区
select partition_name part, partition_expression expr, partition_description descr, table_rows from INFORMATION_SCHEMA.partitions where TABLE_SCHEMA="tempforcrm" AND TABLE_NAME="msgqueue";
图 msgqueue 分区情况
3.总结
3.1方案选择
3.1.1方案对比
| 方案 项目 |
水平分表 |
水平分区 |
| 实施情况 |
|
1、需要按月份创建分区; |
| 性能分析 |
1、在需求中,需通过content字段查询,需要主表查询,性能还是和分表之前一样; 2、在插入数据时有涉及到Java层的逻辑判断(判断插入哪张表); |
1、删除了objid 这个字段的索引,还未评估对性能的影响; |
3.1.2 个人建议
选择水平分区方案; 理由:
- 不需要改动Java代码;
- 不会产生额外的数据表;
- 性能上两者相似;