网络性能优化思路
网络性能优化思路
文章目录
- 网络性能优化思路
- 前言
- 一、确定优化目标
- 二、网络性能工具
-
- 网络性能优化
- 应用程序
- 套接字
- 传输层
- 网络层
- 链路层
- 总结
前言
网络问题比我们前面学过的 CPU、内存或磁盘 I/O 都要复杂。无论是应用层的各种 I/O 模型,冗长的网络协议栈和众多的内核选项,抑或是各种复杂的网络环境,都提高了网络的复杂性。不过,也不要过分担心,只要你掌握了 Linux 网络的基本原理和常见网络协议的工作流程,再结合各个网络层的性能指标来分析,你会发现,定位网络瓶颈并不难。找到网络性能瓶颈后,下一步要做的就是优化了,也就是如何降低网络延迟,并提高网络的吞吐量,优化网络性能问题的思路和一些注意事项。
一、确定优化目标
跟 CPU 和 I/O 方面的性能优化一样,优化前,我会先问问自己,网络性能优化的目标是什么?换句话说,我们观察到的网络性能指标,要达到多少才合适呢?
实际上,虽然网络性能优化的整体目标,是降低网络延迟(如 RTT)和提高吞吐量(如 BPS 和 PPS),但具体到不同应用中,每个指标的优化标准可能会不同,优先级顺序也大相径庭。对于数据库、缓存等系统,快速完成网络收发,即低延迟,是主要的性能目标。而对于我们经常访问的 Web 服务来说,则需要同时兼顾吞吐量和延迟。所以,为了更客观合理地评估优化效果,我们首先应该明确优化的标准,即要对系统和应用程序进行基准测试,得到网络协议栈各层的基准性能。Linux 网络协议栈,是我们需要掌握的核心原理。它是基于 TCP/IP 协议族的分层结构,我用一张图来表示这个结构。
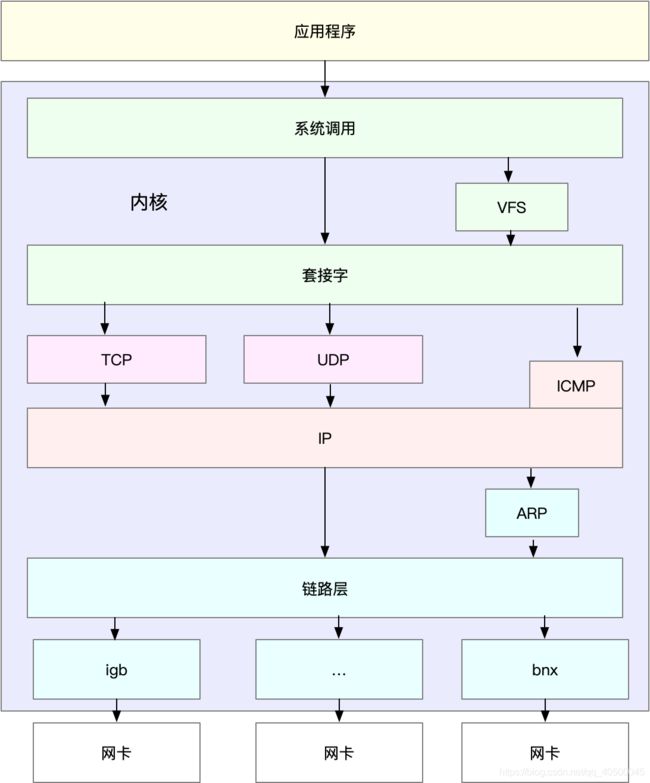
明白了这一点,在进行基准测试时,我们就可以按照协议栈的每一层来测试。由于底层是其上方各层的基础,底层性能也就决定了高层性能。所以我们要清楚,底层性能指标,其实就是对应高层的极限性能。我们从下到上来理解这一点。
首先是网络接口层和网络层,它们主要负责网络包的封装、寻址、路由,以及发送和接收。每秒可处理的网络包数 PPS,就是它们最重要的性能指标(特别是在小包的情况下)。你可以用内核自带的发包工具 pktgen ,来测试 PPS 的性能。
再向上到传输层的 TCP 和 UDP,它们主要负责网络传输。对它们而言,吞吐量(BPS)、连接数以及延迟,就是最重要的性能指标。你可以用 iperf 或 netperf ,来测试传输层的性能。不过要注意,网络包的大小,会直接影响这些指标的值。所以,通常,你需要测试一系列不同大小网络包的性能。
最后,再往上到了应用层,最需要关注的是吞吐量(BPS)、每秒请求数以及延迟等指标。你可以用 wrk、ab 等工具,来测试应用程序的性能。不过,这里要注意的是,测试场景要尽量模拟生产环境,这样的测试才更有价值。比如,你可以到生产环境中,录制实际的请求情况,再到测试中回放。总之,根据这些基准指标,再结合已经观察到的性能瓶颈,我们就可以明确性能优化的目标。
二、网络性能工具
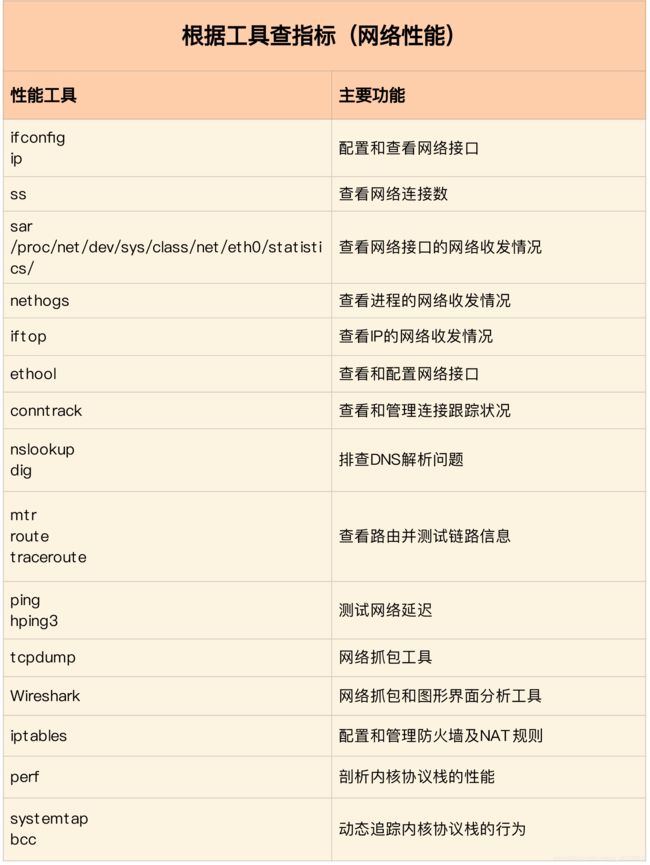
同前面学习一样,我建议从指标和工具两个不同维度出发,整理记忆网络相关的性能工具。第一个维度,从网络性能指标出发,你更容易把性能工具同系统工作原理关联起来,对性能问题有宏观的认识和把握。这样,当你想查看某个性能指标时,就能清楚知道,可以用哪些工具。
这里,我把提供网络性能指标的工具,做成了一个表格,方便你梳理关系和理解记忆。你可以把它保存并打印出来,随时查看。当然,你也可以把它当成一个“指标工具”指南来使用。

再来看第二个维度,从性能工具出发。这可以让你更快上手使用工具,迅速找出想要观察的性能指标。特别是在工具有限的情况下,我们更要充分利用好手头的每一个工具,用少量工具也要尽力挖掘出大量信息。
同样的,我也将这些常用工具,汇总成了一个表格,方便你区分和理解。自然,你也可以当成一个“工具指标”指南使用,需要时查表即可。
网络性能优化
总的来说,先要获得网络基准测试报告,然后通过相关性能工具,定位出网络性能瓶颈。再接下来的优化工作,就是水到渠成的事情了。
当然,还是那句话,要优化网络性能,肯定离不开 Linux 系统的网络协议栈和网络收发流程的辅助。
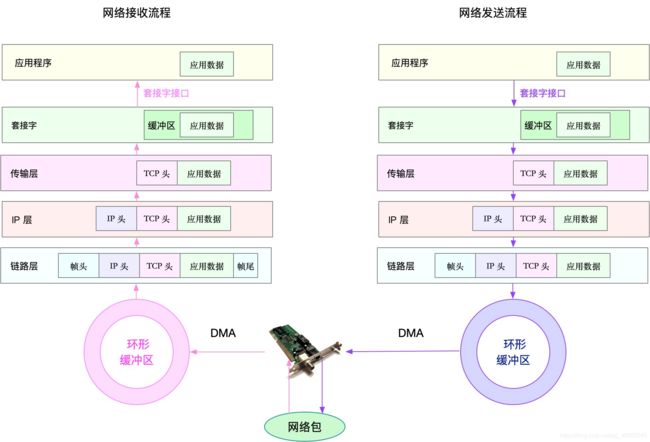
接下来,我们就可以从应用程序、套接字、传输层、网络层以及链路层等几个角度,分别来看网络性能优化的基本思路。
应用程序
应用程序,通常通过套接字接口进行网络操作。由于网络收发通常比较耗时,所以应用程序的优化,主要就是对网络 I/O 和进程自身的工作模型的优化。
从网络 I/O 的角度来说,主要有下面两种优化思路。
- 第一种是最常用的 I/O 多路复用技术 epoll,主要用来取代 select 和 poll。这其实是解决 C10K问题的关键,也是目前很多网络应用默认使用的机制。
- 第二种是使用异步 I/O(Asynchronous I/O,AIO)。AIO 允许应用程序同时发起很多 I/O 操作,而不用等待这些操作完成。等到 I/O 完成后,系统会用事件通知的方式,告诉应用程序结果。不过,AIO 的使用比较复杂,你需要小心处理很多边缘情况。
而从进程的工作模型来说,也有两种不同的模型用来优化。
- 第一种,主进程 + 多个 worker 子进程。其中,主进程负责管理网络连接,而子进程负责实际的业务处理。这也是最常用的一种模型。
- 第二种,监听到相同端口的多进程模型。在这种模型下,所有进程都会监听相同接口,并且开启 SO_REUSEPORT 选项,由内核负责,把请求负载均衡到这些监听进程中去。
除了网络 I/O 和进程的工作模型外,应用层的网络协议优化,也是至关重要的一点。我总结了常见的几种优化方法。
- 使用长连接取代短连接,可以显著降低 TCP 建立连接的成本。在每秒请求次数较多时,这样做的效果非常明显。
- 使用内存等方式,来缓存不常变化的数据,可以降低网络 I/O 次数,同时加快应用程序的响应速度。
- 使用 Protocol Buffer 等序列化的方式,压缩网络 I/O 的数据量,可以提高应用程序的吞吐。
- 使用 DNS 缓存、预取、HTTPDNS 等方式,减少 DNS 解析的延迟,也可以提升网络 I/O 的整体速度。
套接字
套接字可以屏蔽掉 Linux 内核中不同协议的差异,为应用程序提供统一的访问接口。每个套接字,都有一个读写缓冲区。
- 读缓冲区,缓存了远端发过来的数据。如果读缓冲区已满,就不能再接收新的数据。
- 写缓冲区,缓存了要发出去的数据。如果写缓冲区已满,应用程序的写操作就会被阻塞。
所以,为了提高网络的吞吐量,你通常需要调整这些缓冲区的大小。比如:
- 增大每个套接字的缓冲区大小net.core.optmem_max;
- 增大套接字接收缓冲区大小 net.core.rmem_max 和发送缓冲区大小net.core.wmem_max;
- 增大 TCP 接收缓冲区大小 net.ipv4.tcp_rmem 和发送缓冲区大小 net.ipv4.tcp_wmem。
至于套接字的内核选项,我把它们整理成了一个表格,方便你在需要时参考:

不过有几点需要你注意。
- tcp_rmem 和 tcp_wmem 的三个数值分别是 min,default,max,系统会根据这些设置,自动调整 TCP 接收 /发送缓冲区的大小。
- udp_mem 的三个数值分别是 min,pressure,max,系统会根据这些设置,自动调整 UDP 发送缓冲区的大小。
当然,表格中的数值只提供参考价值,具体应该设置多少,还需要你根据实际的网络状况来确定。比如,发送缓冲区大小,理想数值是吞吐量 * 延迟,这样才可以达到最大网络利用率。
除此之外,套接字接口还提供了一些配置选项,用来修改网络连接的行为:
- 为 TCP 连接设置 TCP_NODELAY 后,就可以禁用 Nagle 算法;
- 为 TCP 连接开启 TCP_CORK 后,可以让小包聚合成大包后再发送(注意会阻塞小包的发送);
- 使用 SO_SNDBUF 和 SO_RCVBUF ,可以分别调整套接字发送缓冲区和接收缓冲区的大小。
传输层
传输层最重要的是 TCP 和 UDP 协议,所以这儿的优化,其实主要就是对这两种协议的优化。我们首先来看 TCP 协议的优化。TCP 提供了面向连接的可靠传输服务。要优化 TCP,我们首先要掌握 TCP 协议的基本原理,比如流量控制、慢启动、拥塞避免、延迟确认以及状态流图(如下图所示)等。

掌握这些原理后,你就可以在不破坏 TCP 正常工作的基础上,对它进行优化。
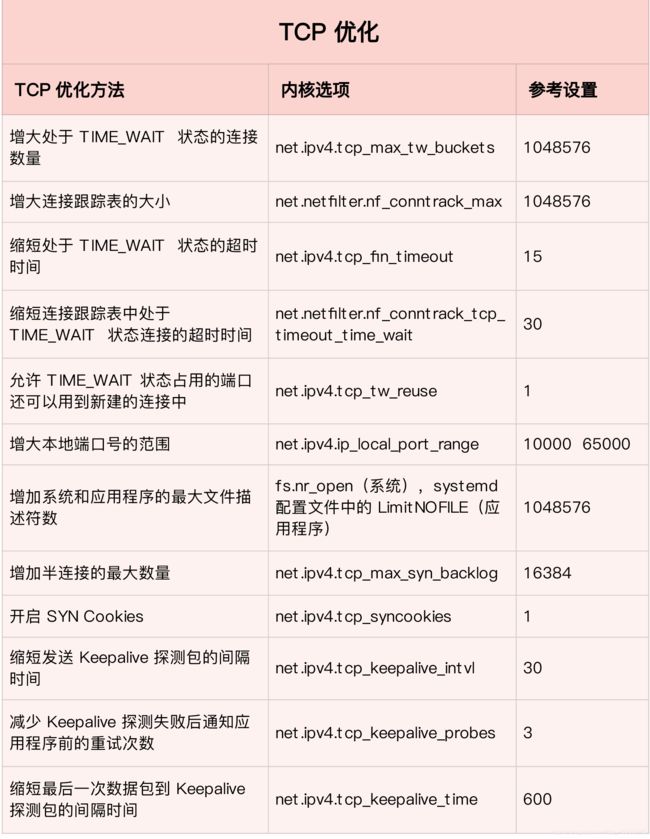
下面,我分几类情况详细说明。第一类,在请求数比较大的场景下,你可能会看到大量处于 TIME_WAIT 状态的连接,它们会占用大量内存和端口资源。这时,我们可以优化与 TIME_WAIT 状态相关的内核选项,比如采取下面几种措施。
- 增大处于 TIME_WAIT 状态的连接数量 net.ipv4.tcp_max_tw_buckets ,并增大连接跟踪表的大小net.netfilter.nf_conntrack_max。减小 net.ipv4.tcp_fin_timeout 和net.netfilter.nf_conntrack_tcp_timeout_time_wait ,让系统尽快释放它们所占用的资源。
- 开启端口复用 net.ipv4.tcp_tw_reuse。这样,被 TIME_WAIT 状态占用的端口,还能用到新建的连接中。
- 增大本地端口的范围 net.ipv4.ip_local_port_range 。这样就可以支持更多连接,提高整体的并发能力。
- 增加最大文件描述符的数量。你可以使用 fs.nr_open 和 fs.file-max ,分别增大进程和系统的最大文件描述符数;或在应用程序的 systemd 配置文件中,配置 LimitNOFILE ,设置应用程序的最大文件描述符数。
第二类,为了缓解 SYN FLOOD 等,利用 TCP 协议特点进行攻击而引发的性能问题,你可以考虑优化与 SYN 状态相关的内核选项,比如采取下面几种措施。
- 增大 TCP 半连接的最大数量 net.ipv4.tcp_max_syn_backlog ,或者开启 TCP SYN Cookiesnet.ipv4.tcp_syncookies ,来绕开半连接数量限制的问题(注意,这两个选项不可同时使用)。
- 减少 SYN_RECV状态的连接重传 SYN+ACK 包的次数 net.ipv4.tcp_synack_retries。
第三类,在长连接的场景中,通常使用 Keepalive 来检测 TCP 连接的状态,以便对端连接断开后,可以自动回收。但是,系统默认的 Keepalive 探测间隔和重试次数,一般都无法满足应用程序的性能要求。所以,这时候你需要优化与 Keepalive 相关的内核选项,比如:
- 缩短最后一次数据包到 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_time;
- 缩短发送 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_intvl;
- 减少 Keepalive 探测失败后,一直到通知应用程序前的重试次数 net.ipv4.tcp_keepalive_probes。
讲了这么多 TCP 优化方法,我也把它们整理成了一个表格,方便你在需要时参考(数值仅供参考,具体配置还要结合你的实际场景来调整):
优化 TCP 性能时,你还要注意,如果同时使用不同优化方法,可能会产生冲突。比如,服务器端开启 Nagle 算法,而客户端开启延迟确认机制,就很容易导致网络延迟增大。
另外,在使用 NAT 的服务器上,如果开启 net.ipv4.tcp_tw_recycle ,就很容易导致各种连接失败。实际上,由于坑太多,这个选项在内核的 4.1 版本中已经删除了。
说完 TCP,我们再来看 UDP 的优化。
UDP 提供了面向数据报的网络协议,它不需要网络连接,也不提供可靠性保障。所以,UDP 优化,相对于 TCP 来说,要简单得多。这里我也总结了常见的几种优化方案。
- 跟上篇套接字部分提到的一样,增大套接字缓冲区大小以及 UDP 缓冲区范围;
- 跟前面 TCP 部分提到的一样,增大本地端口号的范围;
- 根据MTU 大小,调整 UDP 数据包的大小,减少或者避免分片的发生。
网络层
接下来,我们再来看网络层的优化。网络层,负责网络包的封装、寻址和路由,包括 IP、ICMP 等常见协议。在网络层,最主要的优化,其实就是对路由、 IP 分片以及 ICMP 等进行调优。
第一种,从路由和转发的角度出发,你可以调整下面的内核选项。
- 在需要转发的服务器中,比如用作 NAT 网关的服务器或者使用 Docker 容器时,开启 IP 转发,即设置 net.ipv4.ip_forward = 1。
- 调整数据包的生存周期 TTL,比如设置 net.ipv4.ip_default_ttl = 64。注意,增大该值会降低系统性能。
- 开启数据包的反向地址校验,比如设置 net.ipv4.conf.eth0.rp_filter = 1。这样可以防止 IP 欺骗,并减少伪造 IP 带来的 DDoS 问题。
第二种,从分片的角度出发,最主要的是调整 MTU(Maximum Transmission Unit)的大小。通常,MTU 的大小应该根据以太网的标准来设置。以太网标准规定,一个网络帧最大为 1518B,那么去掉以太网头部的 18B 后,剩余的 1500 就是以太网 MTU 的大小。在使用 VXLAN、GRE 等叠加网络技术时,要注意,网络叠加会使原来的网络包变大,导致 MTU 也需要调整。比如,就以 VXLAN 为例,它在原来报文的基础上,增加了 14B 的以太网头部、 8B 的 VXLAN 头部、8B 的 UDP 头部以及 20B 的 IP 头部。换句话说,每个包比原来增大了 50B。所以,我们就需要把交换机、路由器等的 MTU,增大到 1550, 或者把 VXLAN 封包前(比如虚拟化环境中的虚拟网卡)的 MTU 减小为 1450。另外,现在很多网络设备都支持巨帧,如果是这种环境,你还可以把 MTU 调大为 9000(DPDK优化方式),以提高网络吞吐量。
第三种,从 ICMP 的角度出发,为了避免 ICMP 主机探测、ICMP Flood 等各种网络问题,你可以通过内核选项,来限制 ICMP 的行为。
- 比如,你可以禁止 ICMP 协议,即设置 net.ipv4.icmp_echo_ignore_all = 1。这样,外部主机就无法通过ICMP 来探测主机。
- 或者,你还可以禁止广播 ICMP,即设置 net.ipv4.icmp_echo_ignore_broadcasts
= 1。
链路层
网络层的下面是链路层,所以最后,我们再来看链路层的优化方法。链路层负责网络包在物理网络中的传输,比如 MAC 寻址、错误侦测以及通过网卡传输网络帧等。自然,链路层的优化,也是围绕这些基本功能进行的。接下来,我们从不同的几个方面分别来看。
由于网卡收包后调用的中断处理程序(特别是软中断),需要消耗大量的 CPU。所以,将这些中断处理程序调度到不同的 CPU 上执行,就可以显著提高网络吞吐量。这通常可以采用下面两种方法。
- 为网卡硬中断配置 CPU 亲和性(smp_affinity),或者开启 irqbalance 服务 (DPDK方式)。
- 开启 RPS(Receive Packet Steering)和 RFS(Receive Flow Steering),将应用程序和软中断的处理,调度到相同 CPU 上,这样就可以增加 CPU 缓存命中率,减少网络延迟。
另外,现在的网卡都有很丰富的功能,原来在内核中通过软件处理的功能,可以卸载到网卡中,通过硬件来执行。
- TSO(TCP Segmentation Offload)和 UFO(UDP Fragmentation Offload):在TCP/UDP 协议中直接发送大包;而 TCP 包的分段(按照 MSS 分段)和 UDP 的分片(按照 MTU 分片)功能,由网卡来完成 (DPDK优化方式)。
- GSO(Generic Segmentation Offload):在网卡不支持 TSO/UFO 时,将 TCP/UDP 包的分段,延迟到进入网卡前再执行。这样,不仅可以减少 CPU 的消耗,还可以在发生丢包时只重传分段后的包(DPDK优化方式)。
- LRO(Large Receive Offload):在接收 TCP 分段包时,由网卡将其组装合并后,再交给上层网络处理。不过要注意,在需要 IP 转发的情况下,不能开启 LRO,因为如果多个包的头部信息不一致,LRO 合并会导致网络包的校验错误。
- GRO(Generic Receive Offload):GRO 修复了 LRO 的缺陷,并且更为通用,同时支持 TCP 和 UDP(DPDK优化方式)。
- RSS(Receive Side Scaling):也称为多队列接收,它基于硬件的多个接收队列,来分配网络接收进程,这样可以让多个 CPU 来处理接收到的网络包(DPDK优化方式)。
- VXLAN 卸载:也就是让网卡来完成 VXLAN 的组包功能(DPDK优化方式)。
最后,对于网络接口本身,也有很多方法
- 比如,你可以开启网络接口的多队列功能。这样,每个队列就可以用不同的中断号,调度到不同 CPU 上执行,从而提升网络的吞吐量。
- 再如,你可以增大网络接口的缓冲区大小,以及队列长度等,提升网络传输的吞吐量(注意,这可能导致延迟增大)。
- 你还可以使用 Traffic Control 工具,为不同网络流量配置 QoS。
到这里,我就从应用程序、套接字、传输层、网络层,再到链路层,分别介绍了相应的网络性能优化方法。通过这些方法的优化后,网络性能就可以满足绝大部分场景了。最后,别忘了一种极限场景。还记得我们学过的的 C10M 问题吗?在单机并发 1000 万的场景中,对 Linux 网络协议栈进行的各种优化策略,基本都没有太大效果。因为这种情况下,网络协议栈的冗长流程,其实才是最主要的性能负担。
这时,我们可以用两种方式来优化。
- 第一种,使用 DPDK 技术,跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网络请求。同时,再结合大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率。
- 第二种,使用内核自带的 XDP 技术,在网络包进入内核协议栈前,就对其进行处理,这样也可以实现很好的性能。
总结
今天,我们一起梳理了常见的 Linux 网络性能优化方法。在优化网络性能时,你可以结合 Linux 系统的网络协议栈和网络收发流程,然后从应用程序、套接字、传输层、网络层再到链路层等,进行逐层优化。当然,其实我们分析、定位网络瓶颈,也是基于这些进行的。定位出性能瓶颈后,就可以根据瓶颈所在的协议层进行优化。比如,今天我们学了应用程序和套接字的优化思路:
- 在应用程序中,主要优化 I/O 模型、工作模型以及应用层的网络协议
- 在套接字层中,主要优化套接字的缓冲区大小。
- 在传输层中,主要是优化 TCP 和 UDP 协议;
- 在网络层中,主要是优化路由、转发、分片以及 ICMP 协议;
- 最后,在链路层中,主要是优化网络包的收发、网络功能卸载以及网卡选项。