一文解读 redis 主从/哨兵/集群架构
主从
主从结构示意图: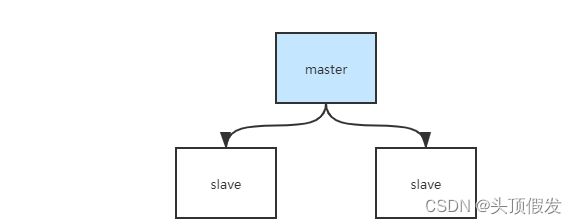
主从架构搭建,配置从节点:
- 复制 redis.conf 文件,并修改如下配置port 8001pidfile /var/redis_8001.pidlogfile 8001.logdir /usr/local/redis_8001/data
- 配置主从配置replicaof 172.0.0.1 8002replica-read-only yes
- 根据配置文件启动redisredis-server redis.conf
主从结构工作原理
master-slave数据同步过程:
全量同步:slave会发送一个PSYNC命令给master,master接收到该命令后,会立即进行持久化操作,通过命令bgsava生成一个RDB快照文件,持久化期间,如果客户端仍在写入数据,这部分数据会被保存在内存缓冲区(repl buffer)中,持久化完成以后,master会将RDB文件发送给slave,slave 将数据加载到内存中,然后master会将缓冲区的命令发送给slave节点。
断点续传:当master和slave由于某些原因断开时,slave重新连接时,会发送 PSYNC(offset) 包含一个下标的命令,表示断开之前同步到了哪儿。master节点在写入数据时,会将数据写入一个缓冲区(repl backlog buffer),当master接受到 PSYNC(offset) 命令时,会先去查看offset是否在缓冲区,如果在缓存区,会将offset后面的命令发送给slave,否则直接进行一次全量同步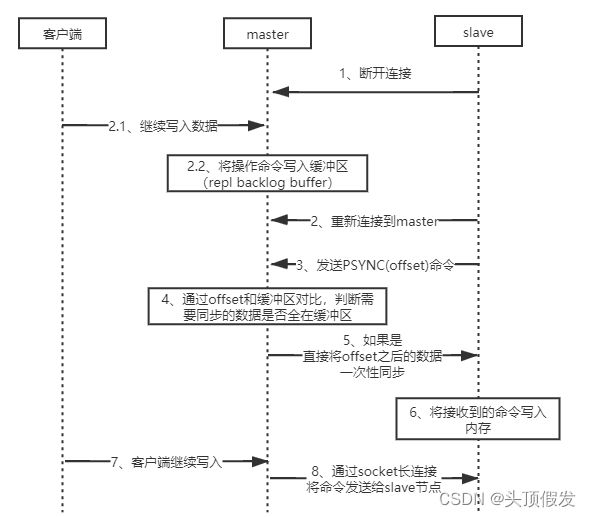
主从结构可能发生的问题:
主从复制风暴:多个从节点同时宕机重启后,全部需要进行全量同步,导致master节点压力过大
解决方案: 将将从节点挂载在某个从节点上,数据同步也从这个从节点复制。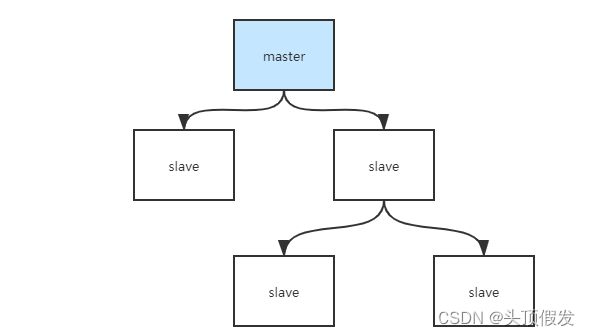
哨兵模式
哨兵模式结构示意图: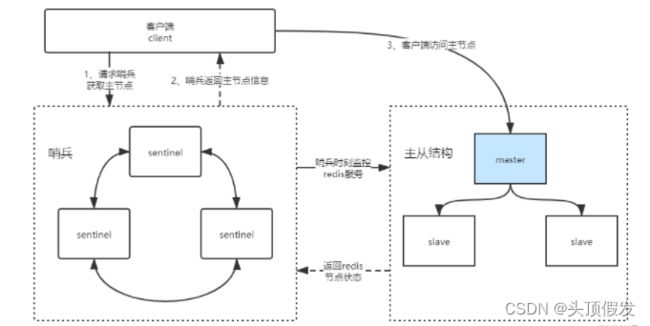
哨兵模式搭建,配置哨兵
- 复制 sentinel.conf 文件到conf目录,并修改如下配置port 26379daemonize yespidfile "/var/run/redis-sentinel.pid"logfile "redis_sentinel_26379.log"dir "/home/redis/redis-6.0.9/sentinel_26379"sentinel monitor mymaster 172.19.14.57 6379 2
- 启动哨兵src/redis-sentinel conf/sentinel.conf
哨兵的工作原理
sentinel 哨兵是特殊的redis服务,他不对外提供读写服务,只用于监控主从结构的状态。
哨兵模式下,client端第一次连接哨兵找出redis主节点并缓存到本地,之后直接访问redis主节点。
当redis节点状态发生改变,sentinel哨兵会第一时间感知到,并将新的主节点推送给客户端。(client端订阅sentinel,一有变动直接推送)
哨兵leader选举流程
当一个 master 服务器被某 sentinel[哨兵]视为下线状态后,该sentinel[哨兵] 会与其他 sentinel[哨兵] 协商选出新的master,进行故障转移工作。
每个发现master服务器进入下线状态的sentinel[哨兵]都可以要求其他sentinel[哨兵]选自己为“本次决策”的leader,选举是先到先得。
同时每个sentinel每次选举都会自增配置纪元(选举周期),每个纪元中只会选择一个sentinel的leader。如果所有超过一半的sentinel选举某sentinel作为leader。
之后由该sentinel[哨兵leader]进行故障转移操作,从存活的slave中选举出新的master,这个选举过程跟集群的master选举很类似【请查看下面redis集群模式的选举】。哨兵集群只有一个哨兵节点,redis的主从也能正常运行以及选举master,如果master挂了,那唯一的那个哨兵节点就是哨兵leader了,可以正常选举新master。不过为了高可用一般都推荐至少部署三个哨兵节点。为什么推荐奇数个哨兵节点原理跟集群奇数个master节点类似。
哨兵模式其实就是主从结构上加了一个哨兵,所以数据同步原理和主从结构一致
哨兵模式可能发生的问题:
访问瞬断:在主节点宕机时,哨兵会发起选举。在选举过程中,如果客户端发起请求,会发生异常。当主节点重新选举出来,又会恢复。该问题在哨兵模式下无法避免。
redis集群架构
集群图示: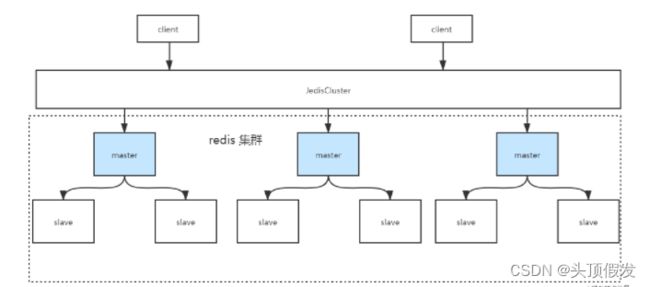
集群搭建
- 复制 sentinel.conf 文件到 redis_cluster/8001/redis.conf 目录,并修改如下配置port 8001daemonize yes ######## 守护进程pidfile /var/run/redis_8001.piddir /usr/local/redis-cluster/8001/replica-read-only yes ######## 从节点只读appendonly yes #######开启AOFcluster-enabled yes ########开启集群模式cluster-config-file nodes-8001.conf ########### 集群信息cluster-node-timeout 15000 ############ 集群master 节点失联多久开始选举requirepass zhouxh_z ########当前主机密码masterauth zhouxh_z ########访问其他主机密码
- 启动集群节点src/redis-server redis_cluster/8001/redis.conf
- 集群配置src/redis-cli -a zhouxh --cluster create --cluster-replicas 1 172.19.14.57:8001 172.19.14.57:8002 172.19.14.57:8003 172.19.14.57:8004 172.19.14.57:8005 172.19.14.57:8006
- 连接客户端src/redis-cli -a zhouxh -c -h 172.19.14.57 -p 8001
- 查看集群信息cluster info
- 查看节点列表cluster nodes
集群原理
集群下的每个小节点的同步复制,和主从一致。
槽位
并不是真实的物理空间,是一个虚拟的概念。
redisCluster 将内存虚拟划分为16384个槽位,分别分配到各个master节点中。redis在存储数据时,会对key进行Hash算法在对16383取余确保,key值必定存在集群槽位上。
取余算法
hash(key) = CRC16(key) % 16383
跳转重定位
在集群模式下,在客户向一个redis节点发起操作命令(如 set key value),会通过取余算法计算对应的槽位,如果发现对应的槽位不在目前节点上时,会自动进行跳转重定向。
如下:原本在 8001 端口的redis,发起set操作,通过取余算法计算key,发现zhouxh_1应该命中 8002 端口的redis所在的槽位,reids进行跳转重定向,自动将值set到了对应的槽位,并跳转到了8002 端口

网络抖动
网络波动可能导致部分master节点在短时间内连接不上,如果不进行限制,可能会发生频繁选举,进而导致脑裂问题。
cluster-node-timeout 15000
该配置可以使master节点在失联15000后,再进行选举。有效避免频繁选举问题
脑裂问题* 面试常问
由于网络问题导致master节点和其他节点断开连接,此时master(旧)节点并没有宕机,但是其他节点认为它已经宕机了,此时slave节点将发起选举,产生一个新的master(新)节点。此时存在两个master节点,客户端认为两个master节点都正常工作,此时会向这两个master节点写入数据。当网络重新连接时,由于存在两个master节点,此时集群会将master(旧)设置为从节点(slave),挂载到master(新)上,此时从节点相当于重启,需要从master节点同步数据,这就导致了之前客户端认为正常写入(master【久】)的数据丢失了。 解决方法:设置半数写入配置
min‐slaves‐to‐write 1
半数写入:即一半的节点认为写入成功才算成功
这里的 ”1“ 可变,计算方式:(小的主从节点数-1)/2
redis选举原理* 面试常问
- 当slave发现自己的master节点 挂了(fail)
- 将自己记录的集群 currentEpoch 加1,并广播 FAILOVER_AUTH_REQUEST 信息
- 其他节点接收到消息后,由主节点回复 FAILOVER_AUTH_ACK 信息,每个master节点只能发送一次
- 对应的slave节点,收集并统计 FAILOVER_AUTH_ACK 信息。
- 当收集到超过半数的ACK信息后,该节点自动升级为master节点。
- master(新)会播Pong消息通知其他集群节点,”我已经成功上位,你们可以歇歇了,赶紧更新你们的配置“。
第1步结束后,第2两步并不是马上执行,中间会有一个延迟时间,每个slave节点的延迟时间不同。
计算规则:500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
SLAVE_RANK:表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方 式下,持有最新数据的slave将会首先发起选举(理论上)。