【Golang开发面经】字节跳动(三轮技术面)
一面
epoll、select、poll 区别
select 机制刚开始的时候,需要把 fd_set 从用户空间拷贝到内核空间,并且检测的 fd 数是有限制的,由 FD_SETSIZE 设置,一般是1024。数组实现。
poll 的实现和 select 非常相似,只是描述 fd集合 的方式不同,poll使用 pollfd结构 而不是 select的 fd_set 结构,其他的都差不多。链表实现。
epol l引入了 epoll_ctl系统调用,将高频调用的 epoll_wait 和低频的 epoll_ctl 隔离开。epoll_ctl 通过(EPOLL_CTL_ADD、EPOLL_CTL_MOD、EPOLL_CTL_DEL)三个操作来分散对需要监控的fds集合的修改,做到了有变化才变更,将select或poll高频、大块内存拷贝(集中处理)变成epoll_ctl的低频、小块内存的拷贝(分散处理),避免了大量的内存拷贝。 epoll使用 红黑树 来组织监控的fds集合
epoll 的水平触发和边缘触发的区别
Edge Triggered (ET) 边沿触发:
- socket 的接收缓冲区状态变化时触发读事件,即空的接收缓冲区刚接收到数据时触发读事件。
- socket 的发送缓冲区状态变化时触发写事件,即满的缓冲区刚空出空间时触发读事件。
- 仅在缓冲区状态变化时触发事件。
Level Triggered (LT) 水平触发:
- socket 接收缓冲区
不为空,有数据可读,则读事件一直触发。 - socket 发送缓冲区
不满可以继续写入数据,则写事件一直触发。
TCP 的流量控制
因为我们总希望数据传输的更快一些。但如果发送方把数据发得过快,接收方就可能来不及接收,这就会造成数据的丢失。流量控制(flow control)就是让发送方的发送速率不要太快,要让接收方来得及接收。
利用滑动窗口机制可以很方便地在 TCP连接上实现发送方流量控制。通过接收方的确认报文中的窗口字段,发送方能够准确地控制发送字节数。
为什么有了流量控制还要有拥塞控制?
流量控制是避免发送方的数据填满接收方的缓存,但并不知道网络中发生了什么。
计算机网络是处在一个共享的环境中。因此也有可能会发生网络的拥堵。在网络出现拥堵时,如果继续发送大量的数据包,可能会导致数据包时延、丢失,这时 TCP 就会重传数据,但是⼀重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包。
控制的目的就是避免发送方的数据填满整个网络。为了在发送方调节所要发送数据的数据量,定义了⼀个叫做「拥塞窗口」的概念。拥塞窗口 cwnd 是发送方维护的⼀个的状态变量,它会根据网络的拥塞程度动态变化的。
TCP 不是可靠传输吗?为什么会丢包呢?
TCP的可靠传输是会在丢包的时候进行重传,来形成可靠的传输,丢包这是网络的问题,而不是TCP机制的问题。
那你介绍一下拥塞控制的算法?
拥塞控制一共有四个算法:
- 慢启动:TCP 在刚建立连接完成后,首先是有个慢启动的过程,这个慢启动的意思就是⼀点⼀点的提高发送数据包的数量。慢启动的算法规则:当
发送方每收到⼀个 ACK,拥塞窗⼝ cwnd 的大小就会加 1。 - 拥塞避免:当拥塞窗口 cwnd「超过」
慢启动门限 ssthresh就会进⼊拥塞避免算法。那么进⼊拥塞避免算法后,它的规则是:每当收到⼀个 ACK 时,cwnd 增加 1/cwnd。 - 快重传:当接收方发现丢了⼀个中间包的时候,
发送三次前⼀个包的ACK,于是发送端就会快速地重传,不必等待超时再重传。 - 快恢复:快重传和快恢复⼀般同时s使用,快速恢复算法是认为,你还能
收到 3 个重复的 ACK说明网络也不那么糟糕,所以没有必要像 RTO 超时那么强烈。进⼊快速恢复之前, cwnd 和 ssthresh 已被更新了:cwnd = cwnd/2 ,也就是设置为原来的⼀半; ssthresh = cwnd 。
进程、线程的区别
| 进程 | 线程 |
|---|---|
| 系统中正在运行的一个应用程序 | 系统分配处理器时间资源的基本单元 |
| 程序一旦运行就是进程 | 进程之内独立执行的一个单元执行流 |
| 资源分配的最小单位 | 程序执行的最小单位 |
进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。
线程有自己的堆栈和局部变量,但线程没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些 要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程
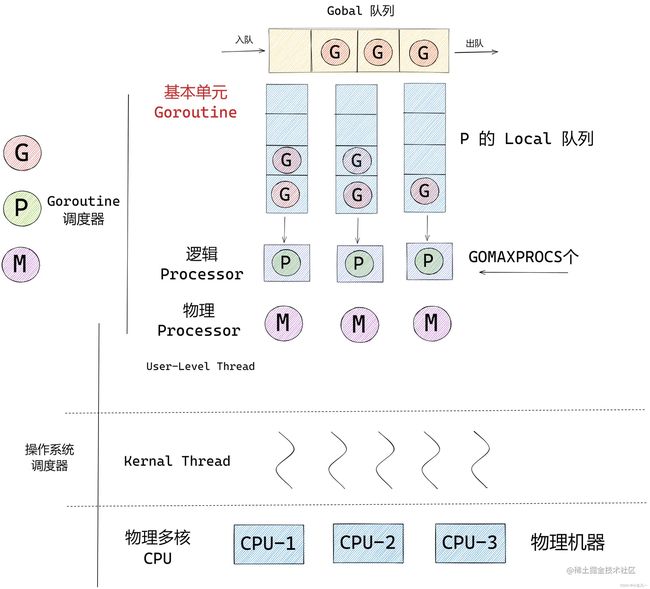
Go里面GMP模型是怎么样的?
G:表示goroutine,存储了goroutine的执行stack信息、goroutine状态以及goroutine的任务函数等;另外G对象是可以重用的。 P:表示逻辑processor,P 的数量决定了系统内最大可并行的 G 的数量(前提:系统的物理cpu核数 >= P的数量);P的最大作用还是其拥有的各种G对象队列、链表、一些cache和状态。 M:M 代表着真正的执行计算资源,物理 Processor。
G 如果想运行起来必须依赖 P,因为 P 是它的
逻辑处理单元,但是 P 要想真正的运行,他也需要与 M 绑定,这样才能真正的运行起来,P 和 M 的这种关系就相当于 Linux 系统中的用户层面的线程和内核的线程是一样的。
算法:旋转矩阵,牛客上写过,easy,秒
二面
上来就一个算法,结束又一个算法,难受。。
如何用栈实现队列
我们可以通过切片来模拟出队列。 只需要完成简单的 push,pop,再判断是否为空即可!
package test_queue
import (
"fmt"
"testing"
)
//结构体,包含两个一维切片
type GoQueue struct {
stack []int
back []int
}
//初始化,
func NewQueue() GoQueue {
return GoQueue{
stack: make([]int, 0),
back: make([]int, 0),
}
}
func (q *GoQueue) Push(x int) {
q.stack = append(q.stack, x)
}
func (q *GoQueue) Pop() int {
if len(q.back) == 0 {
for len(q.stack) != 0 {
val := q.stack[len(q.stack)-1]
q.stack = q.stack[:len(q.stack)-1] //切片,更新栈
q.back = append(q.back, val)
}
}
val := q.back[len(q.back)-1]
q.back = q.back[:len(q.back)-1]
return val
}
func (q *GoQueue) Empty() bool {
return len(q.back) == 0 && len(q.stack) == 0
}
func TestQueue(t *testing.T) {
q := NewQueue()
q.Push(1)
q.Push(2)
q.Push(3)
for !q.Empty() {
fmt.Println(q.Pop())
}
}
复制代码如何判断一个链表有没有环?
- 用hash来判断是否存在相同的值,也就是环。
- 快慢指针:快指针走两步,慢指针走一步,最终会相遇。
那为什么快慢指针一定能够相遇?
因为当快指针出现在慢指针后面之后,每一次快指针往前走两步、慢指针往前走一步,相当于快指针和慢指针之间的相对距离减少1步。当快指针刚刚绕到慢指针后面时,快指针离慢指针有 n 步。那么,对于接下来的每一次快指针往前走两步、慢指针往前走一步,快指针和慢指针之间的距离由 n 步变成 n-1 步、由 n-1 步变成 n-2 步、……、由 3 步变成 2 步、由 2 步变成 1 步、由 1 步变成 0 步。最终相遇。
- 快慢指针第一次相遇的时候,慢指针少走了多少?
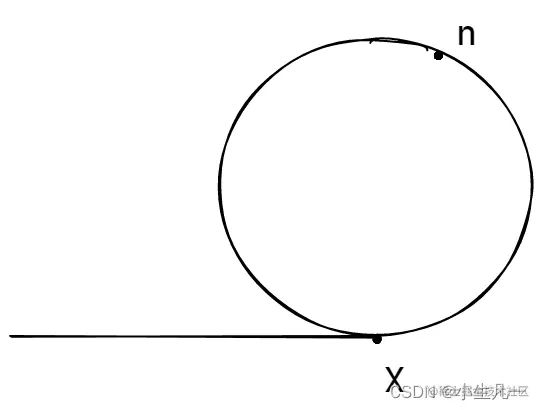
我们设从起点到 X 点的距离是 x,因此当在第一次相遇的时候,在n点,慢指针的路程是 x+n ,而因为快指针的速度是慢指针的一倍,它们从头开始,运动时间就是完全一致的,因此当二者发生相遇的时候,有如下几点值得注意:
- 当二者发生相遇时,慢指针一定已经进入了环中;
- 快指针一定先于慢指针进入环中;
- 快指针移动过的路程累计是慢指针的1倍,也就是
2 * ( x + n ),其中早在路程为x时,快指针已经进入了环,它在环中运动了x+2n的路程。
在 n 点时,慢指针的路程是 x+n,快指针的路程是2*(x+n),说明此时快指针比慢指针多走了 x+n,这同时也说明,从 n 处开始,继续往后推移 x+n 个距离,可以再次回到Z点,因此 x+n 的距离至少是环巡距离的一倍。慢指针和快指针在环中第一次相遇时的路程差值,是环路程的倍数。 所以慢指针少走了环巡距离的一倍。
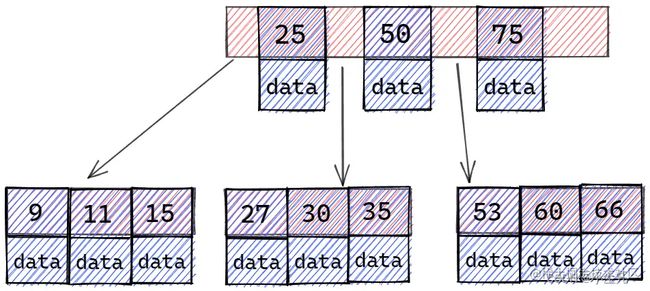
你用的是 mysql 是吧,那 B树 和 B+树 的区别是?
B 树
B+树
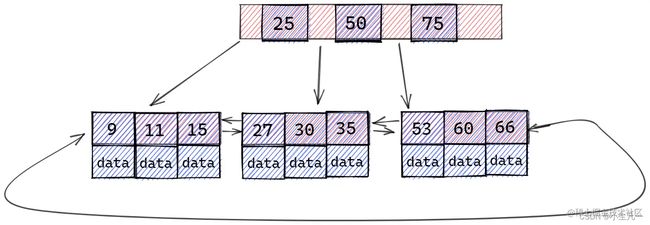
- B+ 树内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为
log (n)。而 B-树 查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)。 - B+ 树叶节点两两相连可大大增加区间访问性,可使用在范围查询等,而 B- 树 每个节点 key 和 data 在一起,则无法区间查找。同时我们访问某数据后,可以将
相近的数据预读进内存,这是利用了空间局部性。 - B+ 树更适合
外部存储。由于内节点无 data 域,每个节点能索引的范围更大更精确。
介绍一下死锁产生的必要条件
互斥条件,请求和保持条件,不剥夺条件,环路等待条件。
如何实现互斥锁?
一个互斥锁需要有阻塞和唤醒功能,所以需要一下几个情况。
- 需要有一个标记锁状态的 state 变量。
- 需要记录哪个线程持有了锁。
- 需要有一个队列维护所有的线程。
如何实现自旋锁?
当时真不会,只磕磕绊绊说了一些自旋锁的东西。。
大家可以看这篇博客 自旋锁C++实现方式
算法:三数之和。秒
三面
kafka 和 其他消息队列,比如 rocketmq,rabbitmq ,有什么优势?
kafka 具备非常高可靠的分布式架构,功能简单,只支持一些主要的MQ功能,像一些消息查询,消息回溯等功能没有提供。时效是在ms级别以内的。
kafka如何保证消息不丢失?
那我们可以从两个方面也就是生产者,消费者以及 broker ,来说说
- 生产者:生产者(Producer) 调用
send 方法发送消息之后,消息可能因为网络问题并没有发送过去。Kafka提供了同步发送消息方法,会返回一个Future对象,调用get()方法进行阻塞等待,就可以知道消息是否发送成功。如果消息发送失败的话,可以通过Producer 的 retries(重试次数)参数进行设置,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显。 - 消费者:消息在被追加到 Partition(分区) 的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。 Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。 可以通过enable.auto.commit设置为false,关闭自动提交 offset,每次在真正消费完消息之后之后再自己手动提交 offset。 - broker:当消息发送到了分区的leader副本,leader 副本所在的 broker 突然挂掉,那么就要从 follower 副本重新选出一个 leader ,但是 leader 的数据还有一些没有被 follower 副本的同步的话,就会造成消息丢失。解决办法就是
将producer设置 acks = all。
https为什么是安全的?
因为 https 是基于 ssl 和 tls 加密而成的,https 的 s 就代表 ssl 和 tls。
ssl/tls 是怎么保证安全的?经过几次握手?
经过四次握手,客户端向服务器端索要并验证公钥,双方协商生成"对话密钥",双方采用"对话密钥"进行加密通信。 四次握手主要是交换以下信息:
- 数字证书:该证书包含了公钥等信息,一般是由服务器发给客户端,接收方通过验证这个证书是不是由信赖的CA签发,或者与本地的证书相对比,来判断证书是否可信;假如需要双向验证,则服务器和客户端都需要发送数字证书给对方验证;
- 三个随机数:这三个随机数构成了后续通信过程中用来对数据进行对称加密解密的“对话密钥”。
首先客户端先发第一个随机数N1,然后服务器回了第二个随机数N2(这个过程同时把之前
提到的证书发给客户端),这两个随机数都是明文的;而第三个随机数N3,客户端用数字证书的公钥进行非对称加密,发给服务器; 而服务器用只有自己知道的私钥来解密,获取第三个随机数。 这样,服务端和客户端都有了三个随机数N1+N2+N3,然后两端就使用这三个随机数来生成“对话密钥”,在此之后的通信都是使用这个“对话密钥”来进行对称加密解密。 因为这个过程中,服务端的私钥只用来解密第三个随机数,从来没有在网络中传输过,这样的话,只要私钥没有被泄露,那么数据就是安全的。
- 加密通信协议:就是双方商量使用哪一种加密方式,假如两者支持的加密方式不匹配,则无法进行通信;
事务的四大特性?
原子性、隔离性、一致性、持久性
用过哪些排序?
快排,堆排,归并比较常用。
快排一定最快吗?
不一定,当待排序的序列已经有序,不管是升序还是降序。此时快速排序最慢,一般当数据量很大的时候,用快速排序比较好,为了避免原来的序列有序。
场景题:如果我有100G文件,但是只有 500 M 的内存,这些文件存着一行行的数字,如何获取最小的10个?
这是经典的 Top K 问题,分治+堆排,我们可以先进行一个将文件进行分治,将100G的文件的分成一个个的 500 M,以此放到内存中每个500M的文件取出进行最小堆的排序,取出前10个写到新文件中。再对着一个个的新文件进行合并成 500 M 再进行最小堆的排序,最终获取最小的10个数字。
算法:最长有序括号,常见题,秒
参考链接
[1] blog.csdn.net/weixin_3597… [2] www.cnblogs.com/yaochunhui/…