哈希表的概念(散列表)
文章目录
-
- 一、基本概念
- 二、常见散列函数
-
- 1. 除留取余法---H(key)=key%p
- 2.直接定址法---H(key)=a*key+b
- 3. 数字分析法---选取数码分布较为均匀的若干位作为散列地址
- 4.平方取中法---取关键字的平方值的中间几位作为散列地址
- 三、处理冲突的方法
-
- 1.拉链法
- 2.开放定址法
-
- (1) 线性探测法
- (2) 平方探测法
- (3) 伪随机序列法
一、基本概念
散列表特点 :
数据元素的关键字与存储地址直接相关
通过哈希函数建立“关键字”与“存储地址”的联系
若不同的关键字通过散列函数映射到同一个值,则称它们为 “同义词”
通过散列函数确定的位置已经存放了其他元素,则称这种情况为 “冲突”
二、常见散列函数
1. 除留取余法—H(key)=key%p
表长为m,取不大于m但最接近或等于m的质数
2.直接定址法—H(key)=a*key+b
适合 关键字分布基本连续 的情况
3. 数字分析法—选取数码分布较为均匀的若干位作为散列地址

4.平方取中法—取关键字的平方值的中间几位作为散列地址

散列查找是典型的 “用空间换时间” 的算法,只要散列函数设计的合理,则散列表越长,冲突的概率越低。
三、处理冲突的方法
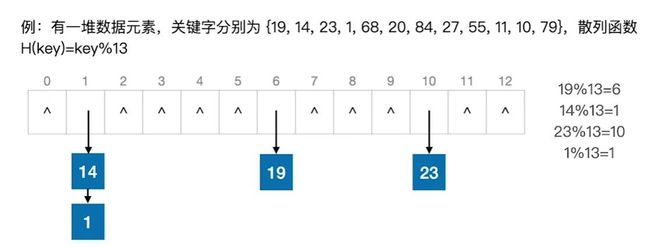
1.拉链法
用拉链法处理“冲突”:把所有“同义词”存储在一个链表中
2.开放定址法
空地址既对同义词开放,又向非同义词开放。其数学递推公式为
H i = ( H ( k e y ) + d i ) % m H_i=(H(key)+d_i)\%m Hi=(H(key)+di)%m
其中 i ∈ [ 0 , m − 1 ] i\in[0,m-1] i∈[0,m−1],m表示散列表表长, d i d_i di为增量序列;H(key)表示初始地址;i理解为“第i次发生冲突”
(1) 线性探测法
d i = 0 , 1 , 2 , . . . , m − 1 d_i=0,1,2,...,m-1 di=0,1,2,...,m−1
1存储操作
即发生冲突时,每次往后探测一个单元(向后挪1单元)。若为空,放入,若发生冲突,则接着挪
【易错点】
H ( k e y ) = k e y % p H(key)=key\%p H(key)=key%p
H i = ( H ( k e y ) + d i ) % m H_i=(H(key)+d_i)\%m Hi=(H(key)+di)%m
m和p不一定相等
例如:
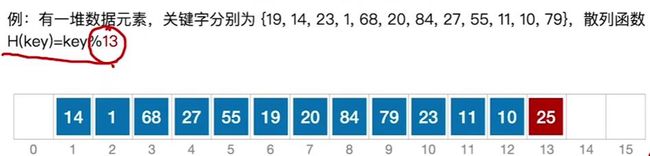
n=13;p为不大于n且与n互质的数,为13
m为表长为16
H ( 25 ) = 25 % 13 = 12 H(25)=25\%13=12 H(25)=25%13=12
H 1 = ( 12 + 1 ) % 16 = 13 H_1=(12+1)\%16=13 H1=(12+1)%16=13
查找操作与存储操作类同。当查找到第一个空位,仍未找到,则查找失败。(例如查找21,从位置8开始查找,直到位置13,仍未找到。查找失败)
缺点:
(2) 平方探测法
d i = 0 , 1 , − 1 , 2 2 , − 2 2 , 3 2 , − 3 2 . . . . d_i=0,1,-1,2^2,-2^2,3^2,-3^2.... di=0,1,−1,22,−22,32,−32....
存储操作
即发生冲突时,以H(key)为,向右向左探索。若为空,放入;若左右都冲突,探测下一个平方值,直至找到空位(eg. H(key)=9, 若10和8都冲突,探测13和5,以此类推)
【注意】:
- 在平方探测法中,由于偏移量有负,故要处理 H i = ( H ( k e y ) + d i ( i ) ) % m < 0 H_i=(H(key)+di(i))\%m<0 Hi=(H(key)+di(i))%m<0的情况。处理方法为:当 d i ( i ) < 0 时, H i = ( H ( k e y ) + d i ( i ) + m ) % m di(i)<0时,H_i=(H(key)+di(i)+m)\%m di(i)<0时,Hi=(H(key)+di(i)+m)%m
- 在平方探测法中,散列表长度m必须是一个可以表示为4j+3的素数,才能探测到所有位置
(3) 伪随机序列法
d i = 0 , 5 , 24 , 11 , . . d_i=0,5,24,11,.. di=0,5,24,11,..或其他给出的伪随机序列
与以上两种操作类同,不再赘述