MariaDB缓冲区详解
以前对于各种引擎也稍微有点理解,可是却并没有深入研究过,最近打算看看Innodb引擎, InnoDB 存储引擎 前言: 数据库:物理操作系统文件或其他形式文件类型的集合, 数据库实例:有数据库后台进程/线程以及一个共享内存区组成 mysql被设计成了一个单进程多线程架构的数据库 开始: 1、默认的InnoDB存储引擎的后台线程有7个,4个IO thread ,1个master thread 1个锁监控 thread 1个错误监控thread,IO thread 的数量由配置文件的innodb_file_io_threads参数控制,默认是4,linux下面不可以调整,但是window下面可以 show engine innodb status \G;(root用户,或者你的用户有查看权限) show variables like 'innodb_version' \G; show variables like 'innodb_%io_threads' \G; 注释:我十分建议大家安装独立的mysql,不要用集成环境,因为出现问题会后悔死的 2、innodb存储引擎内存有以下部分: buffer pool 缓冲池 redo log buffer 重做日志缓冲池 additional memory pool 额外内存池 配置文件的innodb: # Comment the following if you are using InnoDB tables #skip-innodb innodb_data_home_dir = "D:/xampp/mysql/data" innodb_data_file_path = ibdata1:10M:autoextend innodb_log_group_home_dir = "D:/xampp/mysql/data" #innodb_log_arch_dir = "D:/xampp/mysql/data" ## You can set .._buffer_pool_size up to 50 - 80 % ## of RAM but beware of setting memory usage too high innodb_buffer_pool_size = 16M innodb_additional_mem_pool_size = 2M ## Set .._log_file_size to 25 % of buffer pool size innodb_log_file_size = 5M innodb_log_buffer_size = 8M innodb_flush_log_at_trx_commit = 1 innodb_lock_wait_timeout = 50
这是my.ini的配置,更多的InnoDB的配置,可以看my_innodb_heavy_4G.ini
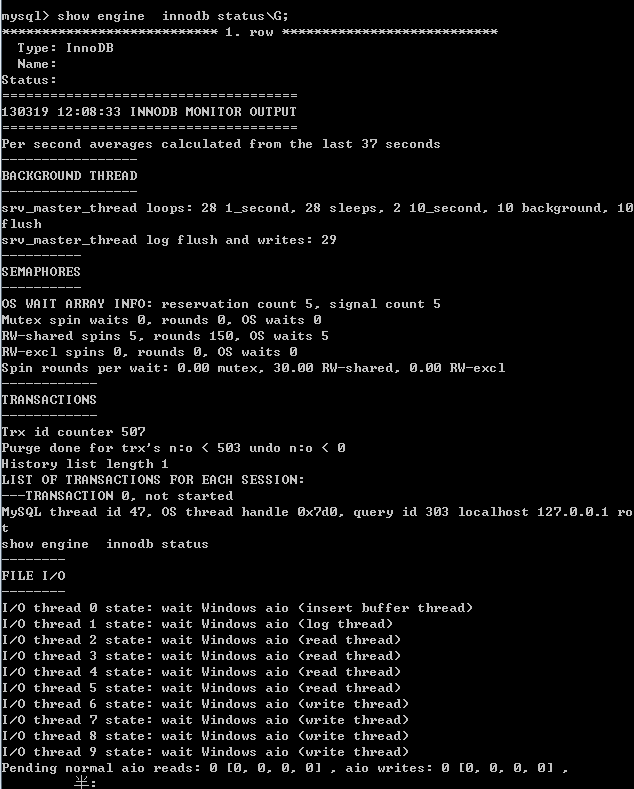
注释:配置文件的值可能会根据不同的环境更改,上面的配置文件是在我安装之后默认的 3、缓冲池是用来存放各种数据的缓存,InnoDB存储引擎的工作方式是将数据库文件按页(每页16K)读取到缓冲池,然后按照最近最少使用(LRU)的算法保留在缓冲池中的缓存数据 输入:show engine innodb status\G; 显示:

Dictionary memory allocated 22124 Buffer pool size 1024 //表示有多少缓冲帧 buffer frame 每个buffer frame 16k Free buffers 876 //当前空闲的 buffer frame Database pages 147 //已经使用的 buffer frame Old database pages 0 Modified db pages 0 //表示脏页的数量 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 0, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 144, created 3, written 37 0.00 reads/s, 0.00 creates/s, 0.00 writes/s No buffer pool page gets since the last printout Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.
注释:show engine innodb status 的命令显示的不是当前的状态,而是过去某个范围内的InnoDB存储引擎的状态 4、buffer pool里面的缓存的数据页类型有: 索引页 数据页 undo页 插入缓冲 insert buffer 自适应哈希索引 adaptive hash index InnoDB存储的锁信息 lock info 数据字典信息 data dictionary (DD) and so on; 5、在32位win下,参数innodb_buffer_pool_awe_mem_mb,可以启动地址窗口扩展(AWE)功能,突破32位下对内存使用的限制,但是一旦启动了AWE,InnoDB存储引擎将自动禁用adaptive hash index 6、日志缓冲将重做日志信息先放入这个缓冲区,然后按照一定的平率将其刷新到重做日志文件,不需要设置很大,保证每秒的产生事务量在这个缓冲大小即可 7、额外的内存池, 在Innodb存储引擎中,对内存的管理师通过一种被称为内存堆(heap)的方式进行的,对一些数据结构本身分配内存时,需要先从额外的内存池中申请,当内存不够时,才会从缓冲池中申请, innoDB的instance 会申请innodb_buffer_bool的space,
但是每个buffer pool 中的frame buffer(帧缓冲)还有对应的缓冲控制对象,buffer control block 因此当你的buffer pool足够大的时候,额外内存池也应该增大
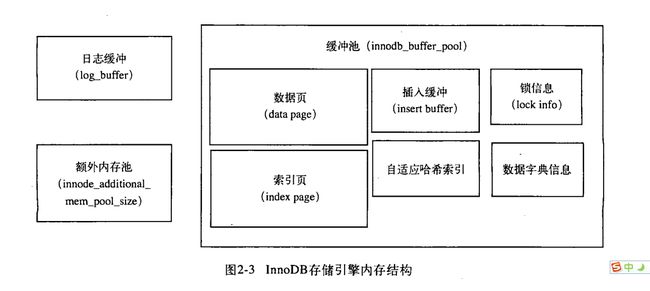
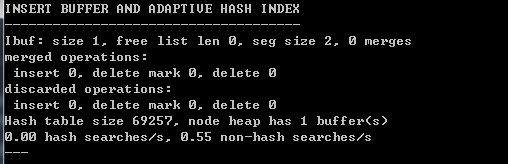
adaptive hash index :默认是开启的,哈希索引只能用来搜索等值的查询.对于其他查找类型,如范围查找,是不能使用的.
注释:我的数据时模拟的百万级数据,但是我还是没有捕捉到adaptive hash index 的有关应用
二、master Thread 源码分析: 1、master thread n内部组成: 主循环(loop) 后台循环(background loop) 刷新循环(flush loop) 暂停循环(suspend loop) master thread会在这几个状态中切换,在负载很大的时候可能造成延迟delay, 每秒一次的操作包括: 日志缓冲刷新到磁盘,即使这个事务还没有提交(总是) 合并插入缓冲(Maybe) 至多刷新100个Innodb的缓冲池中的脏页到磁盘(Maybe) 如果当前用户没有活动,则切换到background loop(Maybe) 脏页比例: buf_get_modified_ratio_pct 是否超过了innodb_max_dirty_pages_pct这个参数,默认是90(90%) 如果超过了这个阀值,InnoDB认为需要做磁盘同步操作,将100脏页写入磁盘 full purge :删除无用的Undo页 在full purge 的过程中,先判断当前事务系统中已被删除的行是否可以删除,如果可以,会即可删除, full purge 的时候,每次最多删除20个Undo页1_second :loop sleeps:睡眠 background:background loop flush:flush loop; InnoDB会对其内部进行一些优化,当压力大时并不是总是等待1秒钟,因为我们不可以认为1_seconds 和sleeps相同 某些情况下,二者只差可以被看做是数据库的负载压力 InnoDB的关键特性: 插入缓冲(insert buffer) //和data page 一样,是物理页的一个组成部分 两次写(double write) 自适应哈希索引(adaptive hash index) InnoDB的主键建立聚集(聚簇)索引,如果你的表不需要特殊的聚簇索引,一个好的做法就是使用代理主键(surrogate key)。 如果你的表没有主键,如果你的表里面存在not null并且 unique index,那么innodb就会选择该索引作为主键,否则就自己内建一个类似的rowid的列,6个字节的隐形字段 show table status from dbName;//查看数据库表的info
innodb_force_recovery :1-6;
1:SRV_FORCE_IGNORE_CORRUPT :忽略检查到corrupt页
2:SRV_FORCE_NO_BACKGROUND:阻止主线程的运行,如主线程需要full purge 操作,会导致crash
3:SRV_FORCE_NO_TRX_UNDO:不执行事务回滚操作
4:SRV_FORCE_NO_IBUF_MERAGE:不执行插入缓冲的合并操作
5:SRV_FORCE_NO_UNDO_LOG_SCAN:不查看撤销日志(undo log),Innodb存储引擎会将未提交的事务视为已提交
6:SRV_FORCE_NO_LOG_REDO:不执行前滚操作
if(innodb_force_recovery ){
you can do select ,create ,drop for table;
}
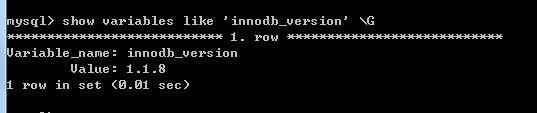
show variables like 'innodb_version'\G;查看innodb的varsion info
|
||