【数据库】SQL语法
目录
1. 常用数据类型
2. 约束
3. 数据库操作
4. 数据表操作
查看表
创建表格
添加数据
删除数据
修改数据
单表查询数据
多表查询数据
模糊查询
关联查询
连接查询
数据查询的执行顺序
5. 内置函数
1. 常用数据类型
- 整型:int
- 浮点型:float
- 字符型:varchar
- 年月日:data
- 年月日 时分秒:datatime
2. 约束
- primary key:主键,物理上的存储顺序,主键一定是非空、唯一的
- not null:此字段不允许为空
- unique:此字段不允许重复
- default:默认,当此字段无数据时,会填入默认值
- foreign key:对关系数据进行约束,当为关键字填写值时,会到关联的表中查询此值是否存在,如果存在则填写成功,如果不存在则填写失败并抛出异常
3. 数据库操作
--查看数据库
show databases;
--创建数据库
create database database_name;
--删除数据库
drop database database_name;
--选择数据库
use database_name;
--查看当前数据库
select database();4. 数据表操作
查看表
--查看当前数据库中的所有表
show tables;
--查看表结构
desc table_name;创建表格
--创建表格示例
create table if not exists `test_table`(
`id` int unsigned auto_increment comment '编号'
,`title` varchar(100) not null comment '标题'
, `author` varchar(100) not null comment '作者'
, `cdate` date comment '日期'
, primary key (`id`)
)engine=InnoDB default charset=utf8 comment='测试表格';
--if not exists `test_table`:如果 test_table 这张表不存在则新建
--auto_increment:从上一条数据自增 1
--comment:后面的字符串为注释
--not null:如果该字段无数据则默认为 null添加数据
--新增字段示例
alter table test_table add `position` varchar(100) not null comment '地区';
--写入数据
insert into test_table(
title
,author
,position
,cdate
)value('孔乙己', '鲁迅', '中国', '1919-4-1');
--批量写入
insert into test_table(
title
,author
,position
,cdate
)value('药', '鲁迅', '中国', '1919-4-25')
,('白夜行', '东野圭吾', '日本', '1998-8-1')
,('鲁宾逊漂流记', '笛福', '英国', '1719-4-25');删除数据
--删除表
drop table table_name;
--删除字段
alter table table_name drop column `字段名`;
--删除数据
drop from table_name where 条件;修改数据
--修改字段名示例
alter table test_table change `title` `book` varchar(100) not null comment '作品';
--更新数据示例
update test_table
set
book = '彷徨'
,cdate = '1926-8-1'
where id = 1;单表查询数据
--查询所有数据
select * from test_table;
--限制数量查询
select * from test_table
limit 3;
--查找指定字段数据
select
book
,author
from test_table;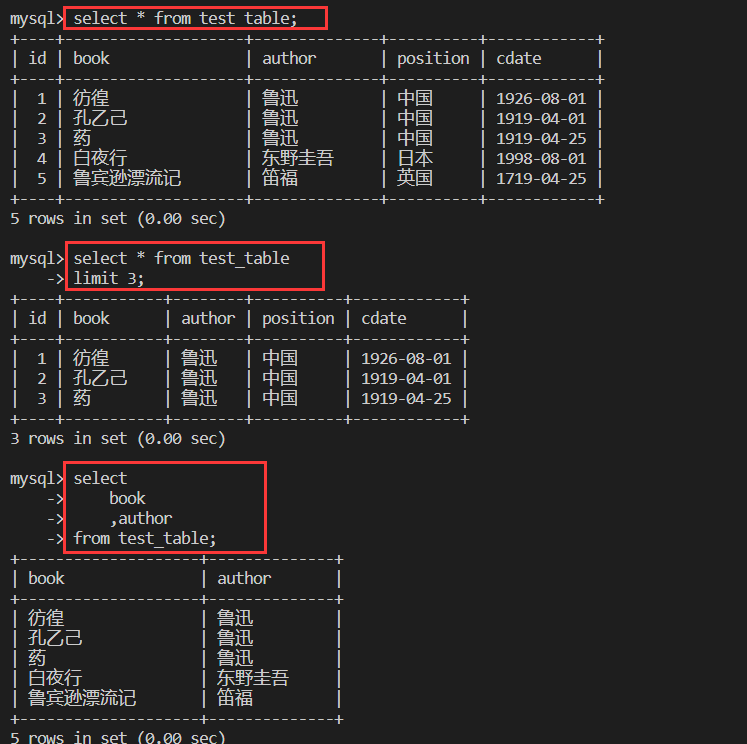
多表查询数据
--多表查询示例
--新建另一个测试表格test_01
--test_01的字段是 id title author cdate
--test_01存储影视信息
select
test_table.book
,test_table.author
,test_01.title
,test_01.author
from test_table, test_01;
--条件查询
select *
from table1, table2, ...
where 条件;
select *
from table1, table2, ...
where 条件1 --选定表格后,选择数据前继续筛选
having 条件2; --数据全部计算完之后进行筛选
--起别名示例
select
a.id
,a.book
,a.author
from test_table a;
--按字段数据去重查询示例
select distinct
a.author
from test_table as a;模糊查询
--模糊查询1示例
select *
from test_table
where author like '%鲁%'; -- % 可匹配任意字符,一个或多个,也可不匹配
--模糊查询2示例
select *
from test_table
where cdate between '1900-1-1' and '2000-1-1';
--模糊查询3示例
select *
from test_table
where author in ('鲁迅', '陈独秀', '李大钊');关联查询
--关联:将两张表拼接
--两张表的字段名可以不不相同,但字段数量字段类型要相同
--union distinct
select
id
,book
,author
from test_table
union
select
id
,title
,author
from test_01;
--排序
--默认是从小排到大,加上desc是从大到小
--每个字段后面的参数只代表这个字段的排序法则
select *
from test_table
order by cdate desc, id; --优先排序出版时间逆序,再根据编号正序排序
--聚合
--count(0) 统计数据条数
--min max avg 分别用于找最大值、最小值、平均数
select
count(0)
,min(cdate)
,max(cdate)
,avg(cdate)
from test_table;
--分组
select
book
,author
,count(0)
from test_table
group by book, author;
--用 group by 去重比 distinct 效率高
--分组统计
select
coalesce(字段1, 'total')
,coalesce(字段2, 'total')
from 表名
where 条件
group by 字段1, 字段2
with rollup;连接查询
连接查询
可同时关联两张表或多张表
内连接
join默认为内连接 inner join
内连接:保留两个关联表的交集
select
a.*
,b.*
from test_table as a
join test_01 as b
on a.id = b.id
and a.author = '鲁迅';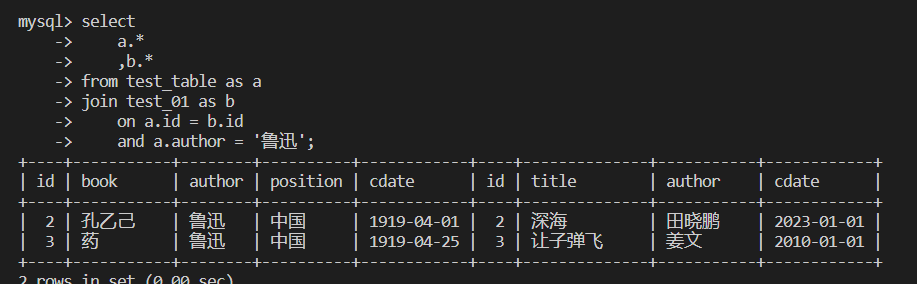
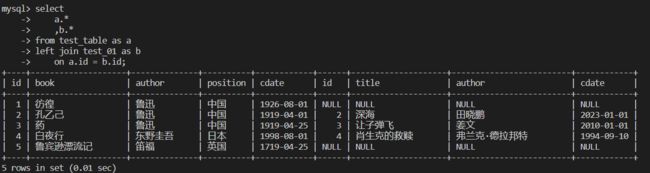
左连接
左连接 left join
保留主表的全部数据和关联表的交集数据
select
a.*
,b.*
from test_table as a
left join test_01 as b
on a.id = b.id;
右连接
右连接 right join
通过调换字段顺序可以将右连接改为左连接
select
a.*
,b.*
from test_01 as a
right join test_table as b
on a.id = b.id;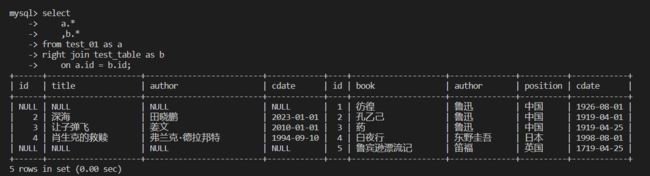
自关联
create table if not exists `city` (
`id` int not null comment '编号',
`name` varchar(100) comment '城市名称',
`pid` varchar(4) comment '父id',
primary key (`id`)
)engine=InnoDB default charset=utf8 comment='城市表格';
insert into city(id,name,pid) values
(1,'上海市',null),
(12,'闵行区',1),
(13,'浦东新区',1),
(2,'北京市',null),
(23,'朝阳区',2),
(24,'海淀区',2),
(25,'望京区',2),
(3,'广东省',null),
(31,'广州市',3),
(32,'东莞市',3),
(33,'珠海市',3),
(321,'莞城区',32);
select
a.ID,
a.name,
b.ID,
b.name,
c.ID,
c.name
from city a
left join city b
on a.ID = b.PID
left join city c
on b.ID = c.PID
where a.PID is null;
数据查询的执行顺序
--代码格式
select distinct
字段
from 表名
join
where
group by
having
order by
limit start, count
--执行顺序
from 表名
join
where
group by
select distinct 字段
having
order by
limit start, count5. 内置函数
常用默认函数
--当前日期
now()
--年
year(now())
--月
month(now())
--日
day(now())
--字段长度
length(字段) from table_name;
--设置返回值最小位数
select round(字段, 小数位数) from table_name;
--反转字符串
select reverse(字符串);
--截取字符串
select substring(字符串, start, length);
--判空 ifnull/nvl/coalesce
--如果对象为空,则用默认值代替
select ifnull(对象, 默认值)
条件判断
--条件判断
select
case when 条件1 then ...
when 条件2 then ...
else ...
end 新增字段
from table_name;
--示例
select
test_table.*
,case when author = '鲁迅' then '鲁迅文集'
when position = '日本' then '日本文学'
else '西方文学'
end '文化特色'
from test_table;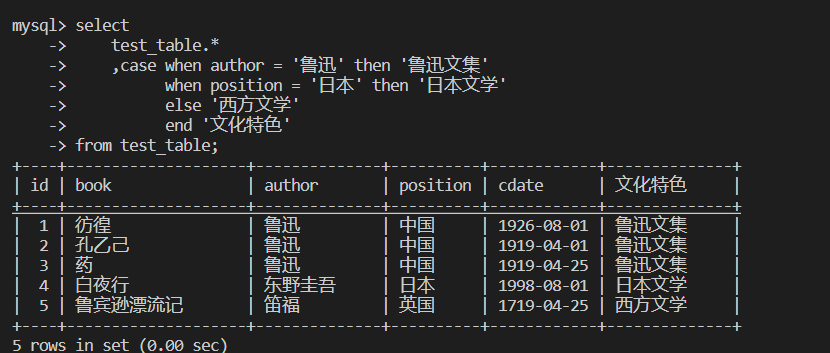
开窗函数
--开窗函数 partition by
--function(column) over(partition by 字段1, 字段2...) 新增字段
--function通常为聚合、排序函数
--分类统计不同作者、不同国家的人
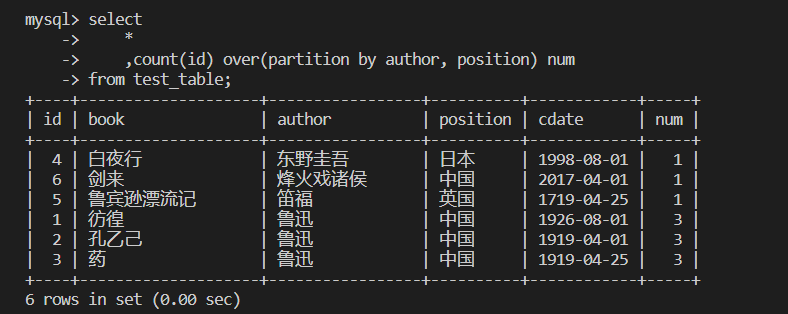
select
*
,count(id) over(partition by author, position) num
from test_table;
--排序函数
--row_number() 排序名次累加,并列也累加 1 2 3 4 5 6 ...
--rank() 排序名次可并列,遇到并列则跳过该名次 1 2 2 4 4 6 ...
--dense_rank() 排序名次可并列,遇到并列不跳过名次 1 2 2 3 3 4 ...
select row_number() over(order by 字段) 新增字段;
select rank() over(order by 字段) 新增字段;
select dense_rank() over(order by 字段) 新增字段;
--查询写入
insert into select ......
--将查询到数据写入另一个表格中,要求写入的数据一一对应