文献精读丨NP 小麦群体演化历史Population genomics unravels the Holocene history of bread wheat and its relatives
文献精读丨NP 面包小麦及其近缘种全新世群体演化历史
本期分享2023年3月17日发表于Nature Plant上的一篇关于面包小麦及其近缘种全新世群体演化历史的文章,讲述了小麦起源的故事,笔记总计约7000字,包含研究结果、方法、原理、工具等多个部分

原文链接:
Population genomics unravels the Holocene history of bread wheat and its relatives
https://www.nature.com/articles/s41477-023-01367-3
面包小麦是世界上最重要的粮食作物之一,养活了约35%的世界人口。同时,作为人类最早驯化的谷物之一,面包小麦及近缘种推动了人类从狩猎采集社会向农耕社会的转变,拉开了人类文明发展的序幕。
作者利用小麦属和粗山羊草属的25个小麦亚种共795份材料的全基因组测序数据,构建了升级版小麦属全基因组遗传变异图谱,通过大量精巧的基因组数据建模,系统重建了面包小麦及其近缘种的群体演化历史。
结果展示
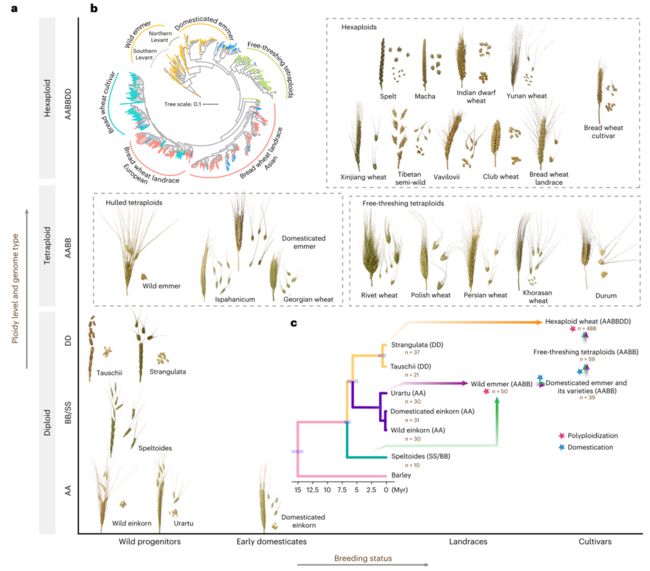 小麦的常见品种、穗形态、倍性水平、基因组类型及育种现状。本研究利用了795份小麦代表性材料的全基因组测序数据,其中包括本研究中新测序的50个进化关键节点的小麦样本,其余745份来自公开可用的数据库。
小麦的常见品种、穗形态、倍性水平、基因组类型及育种现状。本研究利用了795份小麦代表性材料的全基因组测序数据,其中包括本研究中新测序的50个进化关键节点的小麦样本,其余745份来自公开可用的数据库。
这795份材料的平均测序深度为约6.5 ×,为小麦的遗传变异数据挖掘提供了高质量的数据来源。通过个性化的跨倍性遗传变异挖掘流程,构建了升级版的小麦属级的遗传变异图谱(VMap 1.1),该图谱包含7,800万单核苷酸多态性位点。

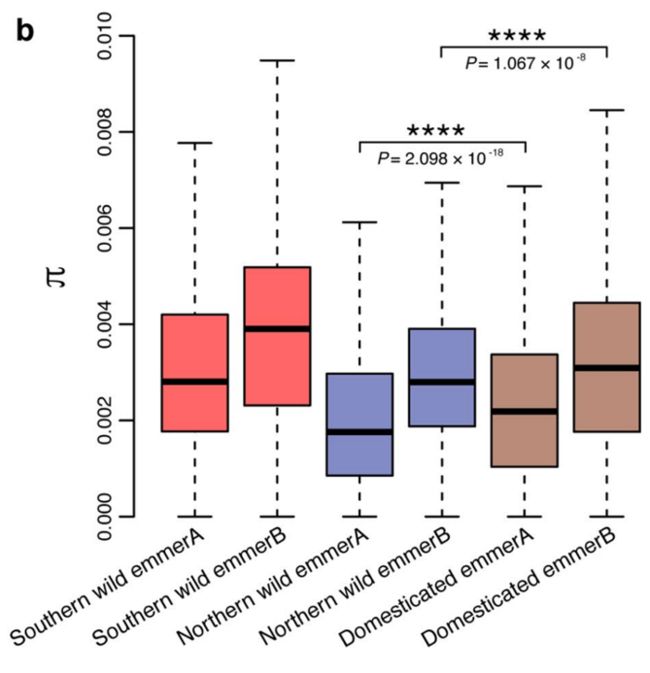
这795份材料来自小麦属和山羊草属的25个种/亚种,具有广泛的地理分布(73个国家)、复杂的倍性水平(二倍体、四倍体和六倍体)、涉及与面包小麦A、B和D亚基因组相关的基因组类型(AA、BB/SS、AABB、AABBDD和DD)、以及不同的育种水平(野生种,早期驯化种,地方品种和栽培品种)。  三个谱系亚种的群体分化指数:Fst数值越大,表明等位基因在各自亚群中越固定(频率越高),群体间分化程度越大
三个谱系亚种的群体分化指数:Fst数值越大,表明等位基因在各自亚群中越固定(频率越高),群体间分化程度越大
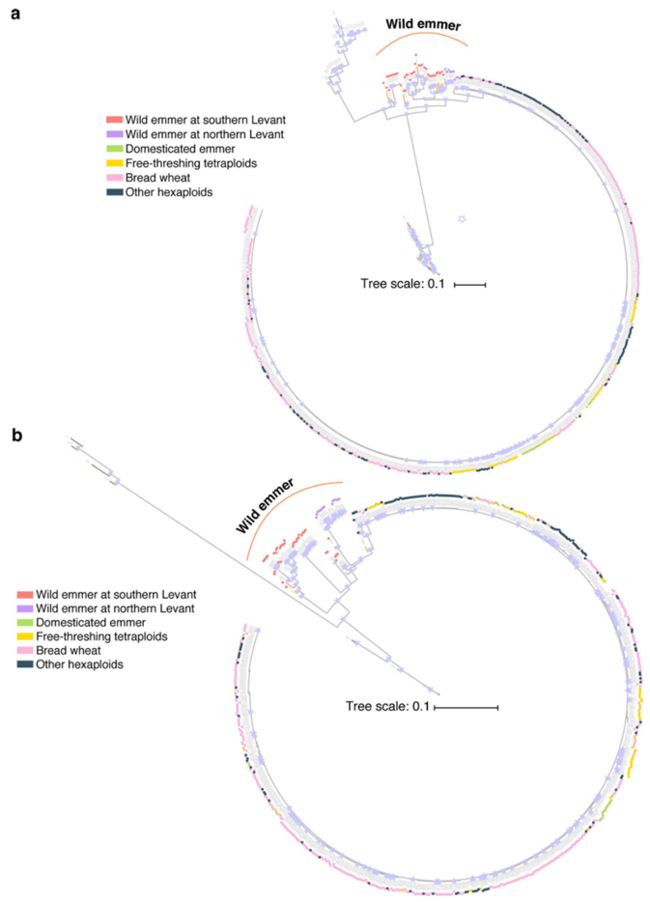 作物的驯化过程可以通过关键的驯化基因进行更为直接的研究,从断穗到不断穗是考古学家和遗传学家一致认为的小麦驯化的标志性表型
作物的驯化过程可以通过关键的驯化基因进行更为直接的研究,从断穗到不断穗是考古学家和遗传学家一致认为的小麦驯化的标志性表型
驯化位点处1mb区域内SNP的局部系统发育树,分表示是a和b亚基因组中同一基因(TtBtr1-A and TtBtr1-B),显示与levant地区的野生二粒小麦距离最近,清楚地显示出栽培小麦是来自于黎凡特北部的野生小麦的单系起源
栽培二粒小麦的地理起源
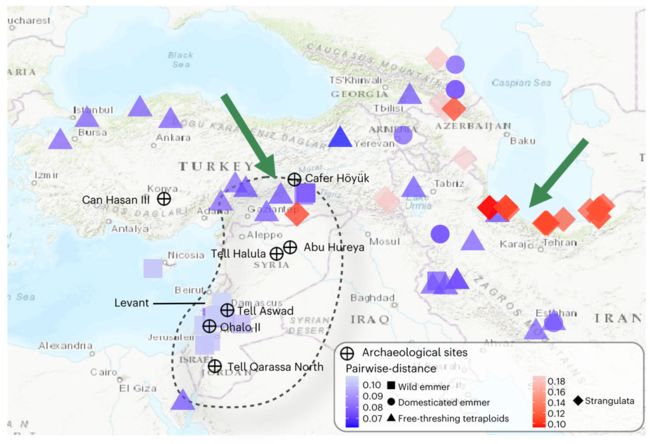 新石器时代早期的考古记录显示,栽培二粒小麦在距今约9,600-9,800年几乎同时出现在新月沃地古城黎凡特北部和黎凡特南部,这引发了一个有争议的问题,即二粒小麦最早是在哪里被驯化的?
新石器时代早期的考古记录显示,栽培二粒小麦在距今约9,600-9,800年几乎同时出现在新月沃地古城黎凡特北部和黎凡特南部,这引发了一个有争议的问题,即二粒小麦最早是在哪里被驯化的?
在本研究中,通过构建全基因组和关键驯化基因的系统发生树,结合考古学研究和过去三十年遗传学的证据,明确了面包小麦的单起源驯化过程,即栽培小麦的驯化全部发生在土耳其东南部的Karacadag地区。
同时,发现面包小麦与其二倍体供体距离最近地点是里海西南部,明确了面包小麦的形成发生在里海的西南部。
面包小麦的物种形成时间
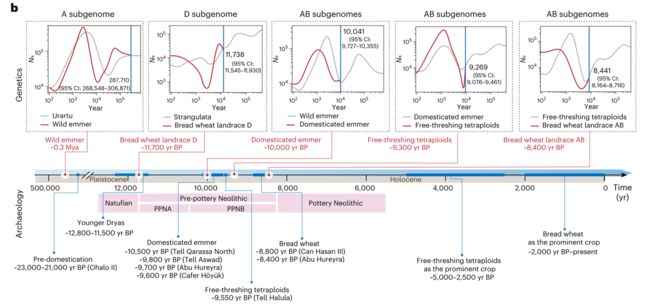 通过循序式马尔可夫溯祖(SMC)算法来进行小麦物种形成时间的推断。考虑到不同面包小麦AB和D亚基因组的进化轨迹的差异性,本研究分别计算了AB和D谱系的群体分歧时间。
通过循序式马尔可夫溯祖(SMC)算法来进行小麦物种形成时间的推断。考虑到不同面包小麦AB和D亚基因组的进化轨迹的差异性,本研究分别计算了AB和D谱系的群体分歧时间。
AB谱系的分析结果表明,栽培二粒小麦从野生二粒小麦分化的时间大约为距今10,041 ± 160年,裸粒四倍体从栽培二粒小麦分化的时间大约为距今9,269 ± 98年,以及从裸粒四倍体中分化出的面包小麦的时间估计为距今8,441 ± 140 BP

考虑到面包小麦的六倍体化同时涉及裸粒四倍体小麦和粗山羊草,理论上从AB谱系和D谱系推断的面包小麦的物种形成时间应该是一致的。然而,研究观察到两个时间估计之间有约3,300年的差距。
鉴于基因流可以改变种群分化的速度,本研究推测来自野生祖先的不对称基因渗入可能解释了从AB和D亚基因组推断面包小麦物种形成时间的差异。发现野生二粒小麦和栽培二粒向面包小麦的渗入是单向的,而且发生在物种形成的早期,估算时间分别是距今约8,919年和7,228年。
此外,预测了在面包小麦形成之后,裸粒四倍体与面包小麦之间一直有持续双向基因流。相比之下,从粗山羊草到面包小麦D亚基因组的渐渗发生的时间非常早,估计早于距今9,729年且非常微量。
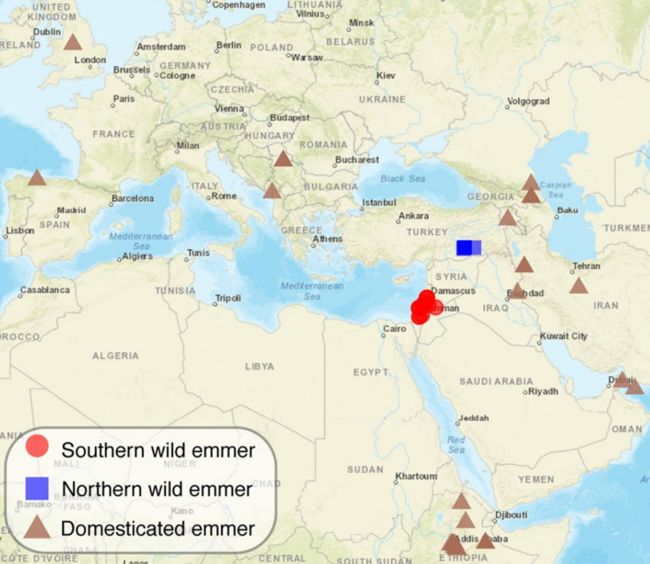 驯化二粒小麦从南黎凡特野生二粒小麦中获得了大量的基因片段, 核苷酸多样性分析,T检验发现在levant北部地区,驯化型的多样性高于野生型。
驯化二粒小麦从南黎凡特野生二粒小麦中获得了大量的基因片段, 核苷酸多样性分析,T检验发现在levant北部地区,驯化型的多样性高于野生型。
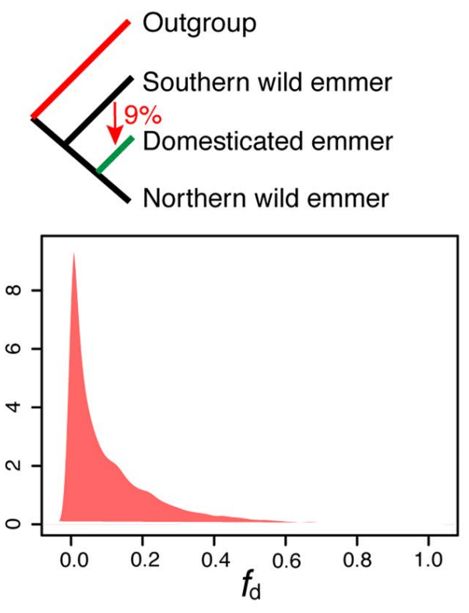
 南方小麦向驯化小麦的基因渗入程度较高,约占驯化小麦基因组的9%。
南方小麦向驯化小麦的基因渗入程度较高,约占驯化小麦基因组的9%。
 驯化二粒小麦基因组中发现了基因很多渗入片段,其中最大的一个片段位于染色体4B (200 ~ 350 Mb),占整个染色体的22.3%。这些结果说明了黎凡特南部野生二粒小麦的基因流进入驯化小麦的基因组
驯化二粒小麦基因组中发现了基因很多渗入片段,其中最大的一个片段位于染色体4B (200 ~ 350 Mb),占整个染色体的22.3%。这些结果说明了黎凡特南部野生二粒小麦的基因流进入驯化小麦的基因组
 这些结果表明,四倍体祖先特别是裸粒四倍体长期和大量的到AB亚基因组的基因流导致面包小麦物种形成缓慢。
这些结果表明,四倍体祖先特别是裸粒四倍体长期和大量的到AB亚基因组的基因流导致面包小麦物种形成缓慢。
这个过程持续了约3,300年,直到面包小麦独特的基因组形成之后才完全从裸粒四倍体中分离出来。
小麦跨欧亚大陆扩张的路线
- 南喜马拉雅路线
从巴基斯坦出发,经过印度、缅甸和云南省,进入中国腹地。
- 河西走廊路线
被称为早期丝绸之路路线,这条路线从中亚出发,通过亚洲内陆山地的绿洲和河西走廊到达中国内地。这条路线因有丰富的考古遗址证实,是描述小麦在中国传播的最流行的假说。
- 草原路线
基于人类青铜文明和草原文化传播提出的,此外,研究也观察到黄河下游地区出土的小麦的考古标定时间早于上游地区出土的小麦。这表明除了河西走廊途径之外,还有一条通过蒙古草原进入中国的北方路线。
 中国西南地区地方种的混合祖先成分(R9)首次证明了南喜马拉雅路线的存在。
中国西南地区地方种的混合祖先成分(R9)首次证明了南喜马拉雅路线的存在。
黄河下游地区(R4)和华东地区(R5)的两个种群是由杂交事件演化而来的,而它们其中一个亲本群体可能是来自草原路线的分支,该草原传播路线可能与4,000至5,000年前阿尔泰山附近的阿凡纳谢沃人遭遇全球气温骤降后向南迁移有关。
系统发育关系表明,在小麦群体中有3个六倍体亚种聚类到了四倍体分支中。同样,也有一个四倍体亚种聚类到了六倍体的分支中。
作者发现了斯佩耳特小麦,玛卡小麦,新疆小麦和波斯小麦源于面包小麦传播过程中和当地已存在的四倍体小麦进行的同域杂交。
 RDA冗余分析,遗传变异与环境变量之间的相关性,研究发现,这些变量解释了基因组遗传变异总方差的13.44%,这表明迁徙过程中环境因素对形成面包小麦适应的遗传多样性具有重要意义
RDA冗余分析,遗传变异与环境变量之间的相关性,研究发现,这些变量解释了基因组遗传变异总方差的13.44%,这表明迁徙过程中环境因素对形成面包小麦适应的遗传多样性具有重要意义
西亚的环境变量对遗传变异方差的解释最小,此外,温度、降水和海拔解释遗传变异方差的相对比例在上述5个地区也存在差异。这表明面包小麦在传播的过程中,形成了一个高度多样化的环境适应性特征。
面包小麦早花表型的趋同进化
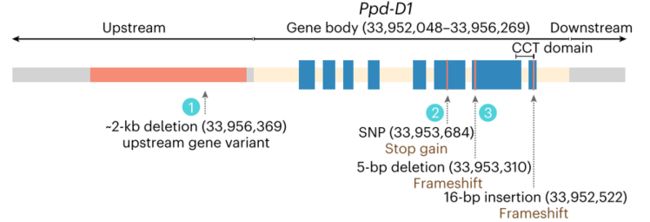
小麦中共有三个功能丧失的Ppd-D1等位基因,其中两个是因果变异位点,包括基因上游~2 kb的缺失和CCT结构域上游第7个外显子5 bp的缺失,还有一个是在此次研究中新发现的单位点终止密码子突变,该突变富集在青藏高原附近的面包小麦群体中

通过中亚(IA)和喜马拉雅南部群体(SH)之间的XP-CLR分析观察到了Ppd-D1上的选择足迹,发现了喜马拉雅南部群体中新发现的无义突变的频率增加,因此推测该变异帮助面包小麦适应高海拔地区寒冷短生育期的环境。

为了验证这个推测,将喜马拉雅南部群体分为高海拔和低海亚群进行XP-CLR比较分析,结果显示Ppd-D1在高海拔和低海拔亚群的显著程度(高于全基因组99.75%的值)高于中亚和喜马拉雅南部群体(高于全基因组97.61%的值),并且这个无义突变的等位基因频率与喜马拉雅南部群体的海拔高度之间存在很强的相关性,表明Ppd-D1的这个新的无义突变的确参与了高海拔适应
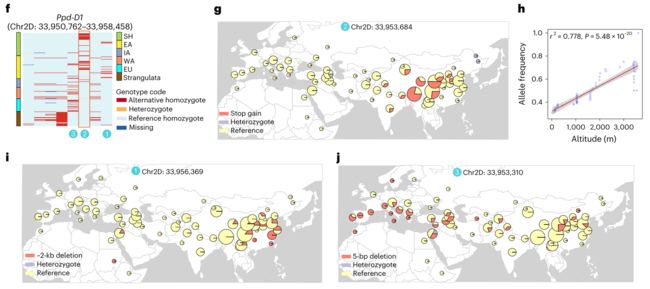 Ppd-D1基因的这三个因果变异有互补的地理分布:新发现的无义突变在南亚和青藏高原出现,~2 kb缺失变异在东亚富集,5 bp缺失变异在欧洲出现,但是他们都呈现相似的进化方向。
Ppd-D1基因的这三个因果变异有互补的地理分布:新发现的无义突变在南亚和青藏高原出现,~2 kb缺失变异在东亚富集,5 bp缺失变异在欧洲出现,但是他们都呈现相似的进化方向。
说明面包小麦在传播过程中通过开花时间主效调控基因Ppd-D1上独立的三个功能缺失变异,实现对开花时间趋同的调控,获得了跨欧亚大陆分布的基础。作物中大多数已知的趋同进化基因都与驯化相关,Ppd-D1基因是作物中首个被发现的环境适应过程中产生趋同进化的案例
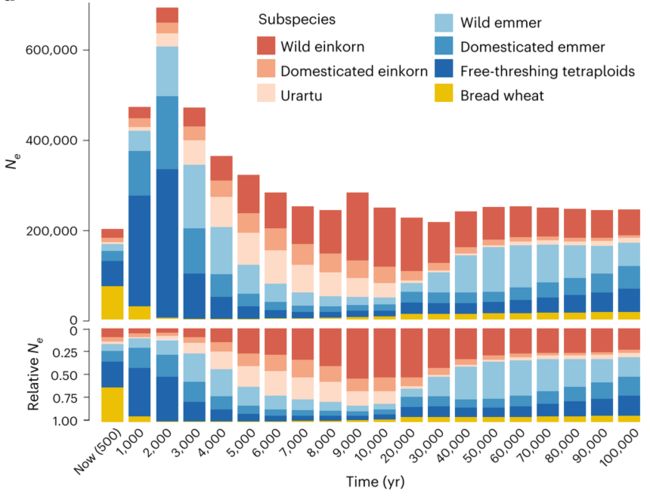 小麦及近缘种从过去到未来的种群规模波动情况研究发现在全新世演化过程中野生近缘种普遍出现有效群体规模减小;而历史上的栽培种及地方种,例如一粒小麦、二粒小麦等,则经历了群体扩张再收缩的过程。
小麦及近缘种从过去到未来的种群规模波动情况研究发现在全新世演化过程中野生近缘种普遍出现有效群体规模减小;而历史上的栽培种及地方种,例如一粒小麦、二粒小麦等,则经历了群体扩张再收缩的过程。
这种群体涨落的过程在不同亚种间出现了逐渐替代、时间线互补的关系,反映出人类对麦类作物饮食选择的不断变化。作为面包小麦重要遗传资源的二粒小麦和一粒小麦,其有效群体在过去2,000年下降了82%
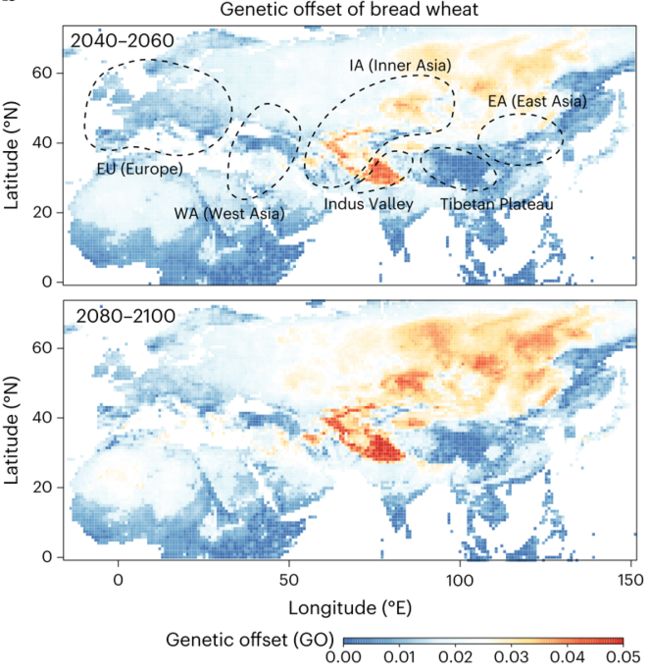
为评价面包小麦及其近缘种在未来环境的适应能力,研究利用机器学习方法建立了小麦气候响应模型,预测了不同地区面包小麦在2050年及2100年气候条件下的适应能力。
计算了本地地方种群在当前和未来气候条件下的等位基因频率偏移,即遗传偏移(GO),发现不同面包小麦地方群体表现出不同程度的遗传偏移,其中印度河谷区域和内亚地区最容易受到气候变化的影响
 物种分布模型(SDM)来预测野生小麦的未来分布区的变化情况,预测出面包小麦近缘种在未来将会出现分布区缩小或者逐渐远离赤道带的现象
物种分布模型(SDM)来预测野生小麦的未来分布区的变化情况,预测出面包小麦近缘种在未来将会出现分布区缩小或者逐渐远离赤道带的现象
补充一点:野生二粒小麦是面包小麦遗传多样性的最重要来源,分布区缩小可能使其在几十年内成为濒危植物
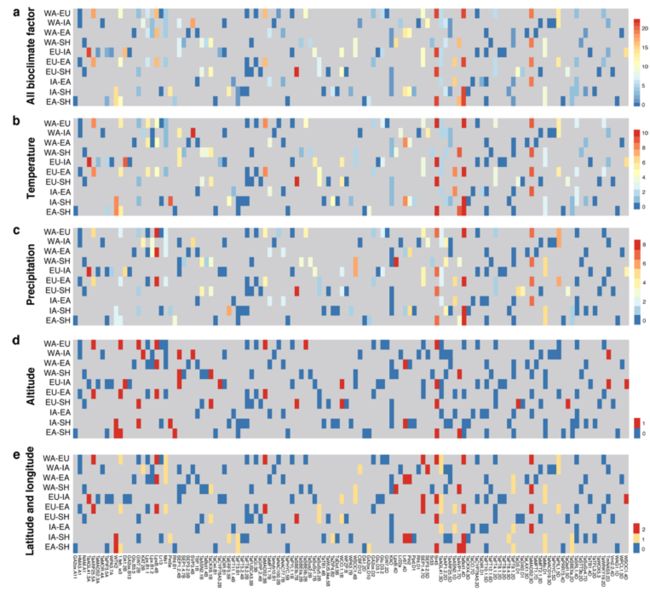
颜色代表与基因相关的环境变量的数量,越红说明相关基因越多。
A:所有22个环境因子,包括11个温度相关变量,8个降水相关变量,海拔、纬度和经度
B:温度相关变量Temperature
C:降水相关的变量Precipitation
D:海拔高度Altitude
个人总结
研究方法与数据分析工具
遗传图谱的重建
- 寻找同源基因
- 同源基因的局部组装
首先,从25个亚种的bam文件中提取同源基因的 fastq 序列。
其次,用 SRAssembler 对25个亚种的每个基因进行了fastq序列组装。
第三,将组装好的片段固定在面包小麦的参考基因组上。
最后,使用了MUSCLE进行多序列比对,最终的4806个互反基因序列只保留大于1000bp的序列比对。
重新建树:
BEAST2、TreeAnnotator v2.5.1、Markov chain Monte Carlo (MCMC)、Hasegawa–Kishino–Yano substitution model、ape、ggtree
- 种群系统发育分析:
从亚基因组中选择了 15 万个随机 SNPs 进行系统发育重建,使用RAxML重构各组的系统发育树(在GTRGAMMA模型中进行100次 bootstrap复制)、iTOL中绘制输出树,RAxML参数为‘-f a -m GTRGAMMA -p 12,346 -x 12,346 -# 100’
- 物种形成时间估计:
SMC++ v1.15.4,参数为OMP_NUM_THREADS = 1 smc++ split
通过联合模拟推断群体历史:
fastsimcoal v2.6
- 数据准备和处理:
easySFS转换vcf为SFS格式,MUMmer4、参数为–maxmatch -g 1,000 -c 90 -l 40
- 模型选择与模型拟合:
早期基因流、无基因流、近期基因流、不同基因流矩阵和恒定基因流五种方法,采用SFS对观测数据进行聚类模拟,拟合模型参数,
对于每个模型,使用fastsimcoal2中实现的复合似然方法,可以最大化对观察到的SFS的拟合,该方法有以下选项:' -N 100,000 -L 50 ',对所有参数估计使用对数均匀分布的宽搜索范围,并假设生成时间为 1 年,突变速率为 6.5 × 10−9,每一代每个位点的突变。
随后,对每个模型进行了 100 次独立的 fastsimcoal2 运行,以确定最大似然的参数估计。比较了 AB系和D系不同的基因流动情景,得到了最佳拟合模型。
Bootstrap 分析:
通过对 50 个 bootstrap 数据集的参数估计,估计了具有极大似然的模型的置信区间。bootstrap数据集是通过在特定的亚群体中随机重采样20次获得的,以匹配原始数据集的大小。
然后,对于每个 bootstrap 数据集,使用 easySFS软件获得SFS。
接下来,使用与原始数据集相同的设置重新估计参数,但由于计算限制,使用 20次复制运行,而不是 100次。为了获得95%的置信区间,计算了用R获得的估计分布的 2.5%和97.5%的百分比。
群体结构预测:ADMIXTURE
选择了D谱系中的 snp108,利用Plink ‘–indep-pairwise 50 10 0.2’去除连锁不平衡度在 0.2 以上的 snp和等位基因频率(MAF)≥0.05 的 snp。
使用cluster 包 hclust 函数实现了经纬度聚类,空间预测基于高斯模型,假设协方差矩阵是平稳的。 在R中使用 rworldmap 包 mapPie 函数实现了地图投影。
EEMS投影:
首先计算了欧亚大陆所有区域的迁移表面等高线。然后对500,000次MCMC迭代(包括300,000次老化迭代)运行MCMC分析,并使用不同的随机数种子重复该过程,以确保默认参数的 MCMC 链的收敛。
使用 EEMS 提供的R脚本生成了最终的空间可视化图,以说明迁移表面。rEEMSplots 包EEMS.PLOT函数。为了测试模型的稳健性,采用抽样方法,在迭代排除单个地区的隔离物后,重复EEMS运行。
Admixture图形构建:
根据EEMS的结果,重新分为10个亚群,然后重新绘制admixture图。
- 使用以下标准对数据集进行筛选:
Plink ‘–indep-pairwise 50 10 0.2’,去除连锁不平衡大于 0.2 的 snp,缺失 数据不超过 5%
- AdmixTools软件CONVERTF函数和qpgraph函数,用来评估模型是否符合数据要求,使用西亚群体作为外群
- 为了探索所有可能的admixture结果,使用了qpbrute实现启发式搜索算法,拟合了61,214种可能的admixture模型,使用 admixturegraph包找到最佳拟合图
系统发育网络分析:
推断物种杂交事件使用基因树拓扑的比例定位过去的杂交在一个系统发育存在不完全谱系排序,通过以下三个步骤推断小麦的杂交事件
- 得到单个同源基因树,RAxML和GTRGAMMA substitution model构建最大似然基因树
- 利用PHYLONET v.3.6.1进行基于伪极大似然方法的物种网络不完全谱系排序和基因流建模,参数为
InferNetwork_MPL - 利用至少 75%自举支持度的根极大似然基因树中的节点进行网络搜索,实现 0-4个网状结构,优化伪似然下回归物种网络的分枝长度和遗传概率
非生物变量收集与冗余分析
- 气象数据来源:
https://www.worldclim.org/
- 地理数据分析:
RASTER v.3.3.13 R包 EXTRACT函数
- RDA:解释面包小麦地方品种 SNP 变异重要的多个气候变量,作者自己构建的新变量
- 利用 2万个随机选择的无缺失 SNPs 子集进行RDA,响应变量的MAF为> 0.05
- 利用RDA进行方差划分,量化20个非生物变量所解释的全基因组SNP变异的比例
- 为了确定与不同地区基因组差异相关的非生物变量,利用 3 个显著变量(温度、降水和海拔)对不同地区进行了RDA分析,包括西亚(WA)、欧洲(EU)、中亚(IA)、东亚(EA)和南喜马拉雅(SH)组
- VEGAN R包:
https://github.com/vegandevs/vegan,用于进行RDA分析
小麦不同区域选择性扫描检测
使用XP-CLR方法,根据地理、遗传和生态差异,将欧亚面包小麦地方种划分为五个亚群(西亚、欧洲、内亚、东亚和南喜马拉雅),并计算了每对亚群的选择性横扫。
-
XP-CLR在网格大小为 10 kb 的情况下运行,窗口内的最大 SNPs 数量为 500 个,相关水平为 0.95。
-
R包GenWin:检测基因组区域边界,平滑度2000,方法4,将每个种群统计结果的前5%作为选择扫描的阈值,并对不同的亚基因组计算不同的阈值。
面包小麦的环境关联分析
- Bayenv 2.0:识别了当地环境与 SNP 频率之间的关联
- 通过气象网站获得了 20 个环境变量(11 个温度变量,8 个降水变量和海拔高度)
- 使用cluster R包中的k-means方法根据地理和环境变量确定了13个小麦群体
- 为了控制种群结构,使用 A、B和D谱系的连锁不平衡独立SNPs (‘–indep-pairwise 50 10 0.2’)估计了13个种群的协方差 矩阵,经过 100,000 次迭代。
- 150 万个 SNP 和 20 个环境变量之间的关联通过对每个SNP的10,000次迭代进行了测试。
- 利用 5次独立的 Bay-env 运行数据计算每个 SNP的贝叶斯因子中值。将 Bayes 因子的前 5% 值作为阈值,对20个环境变量分别进行环境相关snp的选择
检测与适应相关的SNP和基因
- XP-CLR评分和环境相关 SNPs得分前5%的区域被确定为适应相关区域,这些区域的基因被认为是适应性相关的候选基因
- 使用snpEff v5.0在IWGSC gtf v1.1基础上进行基因注释,预测其功能效应
- 对于 Ppd-D1 基因:从包含 indel 变异的原始VMap 1.1 中提取了已知的功能性 5 bp 缺失(33,953,310)和 16 bp 插入(33,952,522)位点基因型。通过分析每个样本全基因组测序数据中的 reads 深度来确定上游 2kb的缺失
群体规模随时间波动: 使用SMC++推测面包小麦和野生近缘属种的历史
估算未来气候下遗传偏置(GO)
- 生物地理模型被用来识别对等位基因频率变化重要的环境因素,并检测等位基因频率如何沿着这些因素移动
- 13个群体、从 225 个样本中随机选择 30,000 个SNP,创建了一个SNP集,另一种是从之前描述的与适应相关的 SNPs中随机挑 选出30000个SNPs,产生两个数据集
- 扩展了梯度森林分析用于预测遗传偏置,基于NorESM1-M Global Climate Model (GCM 全球气候模式),在WorldClim获取了4 种不同温室气体情景下的 2050(2040-2060)和 2090(2080-2100)未来气候变化情况
- 代表性浓度路径(RCP2.6、RCP4.5、RCP6.0和RCP8.5)。这四个 rcp 代表了不同的气体排放情景,反映了中等(RCP2.6)到极端(RCP8.5)的情况
根据使用梯度森林模型预测基因组变异的重要性,对每个栅格中来自当前和预测气候的 19个生物气候变量进行了转换
当前值和预测的未来值之间的欧几里德距离是个体群体的GO遗传偏置,GO 是使用软件包 gradientForest、R软件包 rasterVis
物种分布模拟
- SDMs 结合了物种分布的观察和环境估计,利用美国国家植物种质资源系统(https://npgsweb.ars-grin.gov/gringlobal/)等在线种质数据库中面包小麦及其野生近缘种的地理坐标,构建相关物种分布模型
- 最 终 的 SDM 建 模 中 使 用 了 从 WorldClim获得的19 个环境预测因子,然后用dismo软件包生成sdm,采用了三种模型:广义加性模型,广义线性模型,随机森林。
- 物种发生数据与研究区域内随机生成的50个假缺失数据相结合,模型用70%的数据进行训练,用剩余的30%进行测试
- 每个建模算法运行100次,并通过真实的技能统计数据进行评估。最后的模型用于每个物种,以预测当前和预测的未来气候条件(2040-2060 年和 2080-2100年)下每个物种的潜在分布。
开源数据获取方式
作者将研究中的部分数据上传至数据库,以下为索引号,方便下载学习:
- PRJCA005979
- GVM000272
- PRJNA663409
- PRJNA439156
- PRJNA476679
- PRJNA596843
重要名词补充提示
- emmer:二粒小麦
- einkorn:单粒小麦
- Domesticated emmer:驯化二粒小麦
- Durum:硬质小麦
- Barley:大麦
- Urartu:乌拉尔图小麦
- cultivar:栽培品种
- landrace:地方品种
- Hexaploids:六倍体
- tetraploids:四倍体
- Diploid:二倍体
- Polyploidization:多倍化
- Polyploidization:驯化
- introgression:基因渗入
- hybridization:杂交
- Spelt:斯皮尔特小麦
- Persian:波斯小麦
- Steppe route:草原路线
- Hexi corridor route:河西走廊路线
- Southern Himalaya route:南喜马拉雅路线
- Mediterranean route:地中海路线
研究完整重现了面包小麦及其近缘种在整个全新世的群体演化历史,彻底解决了有关面包小麦演化的种种争议和谜题,并系统刻画了面包小麦与近缘种之间遗传和生态互作关系。
同时,该研究对小麦演化过程中的环境适应机制进行了初步探索,发现了首个作物环境适应过程中基因水平上产生趋同进化的案例(Ppd-D1),并通过建立基因型-环境模型预测了面包小麦及近缘种在未来气候变化条件下的适应能力。
该研究为小麦重要性状形成与演化规律解析奠定了坚实的基础,为小麦遗传资源的保护和高效利用提供了重要依据。 同时,该研究也将成为探索所有作物的适应性进化机制的研究范式,为通过遗传育种帮助作物应对气候变化挑战提供新的思路。
参考资料: https://mp.weixin.qq.com/s/uv9OwQqU8MBwPqszI55E4w https://blog.sciencenet.cn/blog-3423233-1380768.html
本文由 mdnice 多平台发布