详解之初识指针
详解之初识指针
- 1.指针是什么
-
- 1.1如何编址
- 2.指针和指针类型
- 3.野指针
-
- 3.1野指针的成因
- 3.2如何规避野指针
- 4.指针运算
-
- 4.1指针 +- 整数
- 4.2指针 - 指针
- 4.3指针的关系运算(比较大小)
- 5.指针和数组
- 6.二级指针
- 7.指针数组
1.指针是什么
在计算机科学中,指针(Pointer)是编程语言中的一个对象,利用地址,它的值直接
指向(points to)存在电脑存储器中另一个地方的值。由于通过地址能找到所需变
量单元,可以说,地址指向该变量单元。因此将地址形象化的称为"指针"。意思是通
它能找到以它为地址的内存单元。
简单点说:
内存是一块大大的空间,为了很好的使用内存,把内存划分成一个个小格子,在给每 个格子编个号,就像生活当中旅馆当中每个房间都用个编号一样,这个时候,再加上旅馆的街道房间编号,此时就组成了地址。
你也可以对比地图,在地图上找到一个地方,要找的这个地方首先的知道这个地方的地址。

此图:是以16进制的形式来展示的,如果是二进制形式来展示的话,地址展示会很长,不易展示,也不宜理解 一个内存单元的大小是一个字节。
下面我们看一段代码:
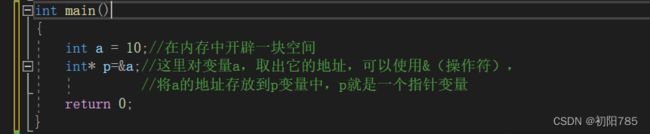
总的来说:指针其实是变量,变量里面存放着地址,也就可以说指针就是地址。
1.1如何编址
电脑上面有地址线,地址线上一但通电,就会产生电信号,把电视信号转换成数字信号,数字信号产生的二进制序列而对电来说就只有正点和负电,所以产生的数字信号无非就是0或1,把电信号转换成数字信号之后呢,这个数字信号就作为二进制序列的编号,这个编号就可以作为一个内存单元的编号了,此时这个二进制序列编号就称为一个内存单元的地址了。
对电脑来说,现在电脑普遍是32位的和64位的。
对于32为的机器,假设又32根地址线,那么假设每根地址线在寻址时产生一个电信号正电/负电(0/1)那么32根地址线产生的地址就会是:
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000
........
11111111 11111111 11111111 11111111
这里就有2的32次方个地址。
每个地址标识一个字节,那我们就可以给(2^32Byte == 2^32/1024KB == 2^23/1024/1024MB == 2^23/1024/1024/1024GB == 4GB),4G的空间进行编址。在这个32位的0 1序列中,存放一个地址只需要4个字节就可以了。
同样的方法,64为的机器也是如此。但是存放一个地址就存要8个字节
总结:
1.指针是用来存放地址的,地址是唯一标识一块地址空间的。
2.指针的大小在32为平台上是4个字节,在64为平台上是8个字节。
2.指针和指针类型
先来一段代码了解一下:

不难看出无论是什么类型的指针,他的大小都是一样的,都是8个字节(当前我的电脑是64位平台的,如果是32位平台的,那他们的值都是4个字节)。
这就引出一个问题,既然指针的大小都是一样的,都是4/8个字节,那指针为什么要区分类型呢?干脆不要区分类型不是更轻松?
但是我想说的是虽然指针的大小都是4/8个字节,但是它的类型都是有它的实际意义的。
下面我们看一段代码:

但是你看这里:地址输出结果相同,可见不管你是什么类型的,都可以很好的存放a的地址因为不管是pa,还是pc,都是指针变量,都是4/8个字节大小。
那区别到底在哪呢?我们只需要稍微改一下上面的代码就可以看出区别了。
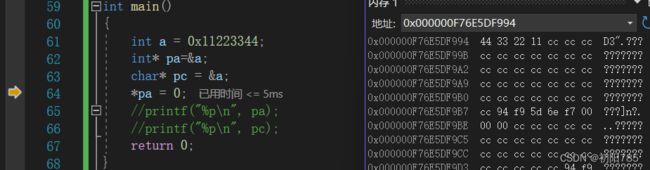

这是int* 类型的:不难看出到pa解引用* pa=0后a的值全部变成了0,也就是改变了4个字节。

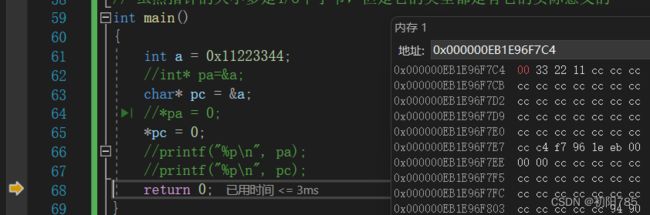
这是char* 类型的:而pc解引用* pc=0却值改变了一个值,也就是一个字节。
所以这就引出了指针类型的两个意义:
意义1:
指针类型决定了指针进行解引用操作的时候,能够访问空间的大小
例如:int* p:* p能够访问4个字节
char* p: * p 能够访问1个字节
double* p: *p能够访问8个字节
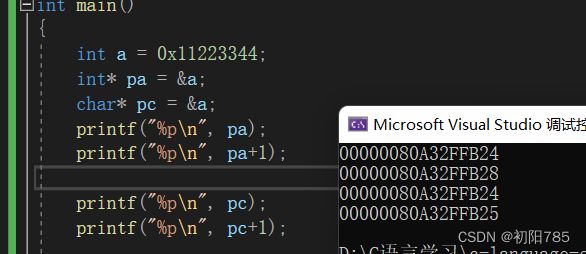
这里不难看出pa+1时跳过了4个字节,而pc+1只跳过了1个字节。
意义2:指针+-整数
指针类型决定了:指针走一步走多远(指针的步长)
int* p:p+1--->偏移4个字节
char* p: p+1--->偏移1个字节
double* p: p+1--->偏移8个字节
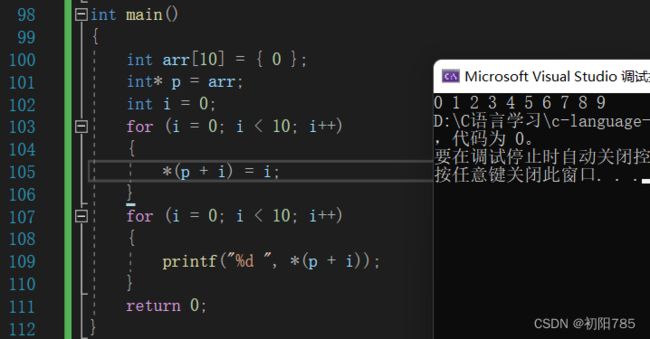
3.野指针
概念:野指针就是指针指向的位置是不可知的(随机的,不正确的,没有明确限制的)
3.1野指针的成因
1:指针未初始化:

2:指针越界访问:
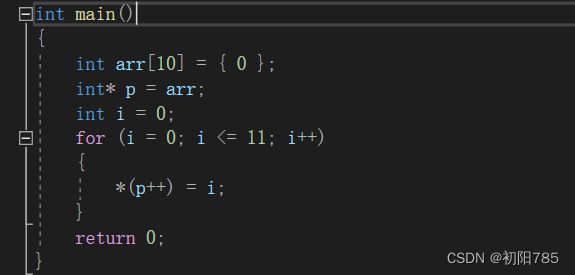
这里创建的数组arr的大小只有10,但是访问的时候却访问了12,属于越界访问了。
3:指针指向的空间释放:

3.2如何规避野指针
1:指针初始化:

2:小心指针越界:
在定义数组的时候即给定数组大小的时候,如果要进行访问,一定要检查其访问的范围,避免
界访问。
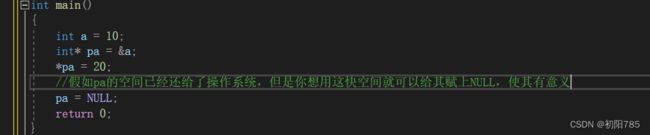
3:指针指向的空间释放即使置NULL:
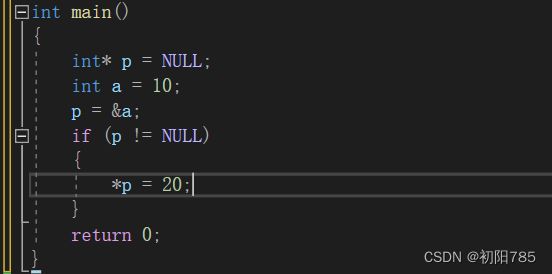
4:指针使用之前检查有效性:
就是当你使用指针的时候,万一后面你又不想用这个指针,就会习惯性的把指针赋值成NULL空指针
赋值成空指针后,这个指针就不能再访问了,这个空间就不在是可使用了,
所以在进行访问指针的时候会习惯性的加上条件语句 if(某指针 != NUll) 这样的条件语句
这样就可以避免访问到不能访问的指针,也就可以避免野指针的出现。
4.指针运算
4.1指针 ± 整数


4.2指针 - 指针
指针 - 指针得到的是元素个数:

切记不能这样使用:

指针 - 指针只能在相同的两个数组名之间进行相减,不同数组名之间的指针相减虽然可以得到结果,但是你不知道怎么来的。
现在来模拟实现strlen求字符串长度:

4.3指针的关系运算(比较大小)
接下来看两段代码:
1:
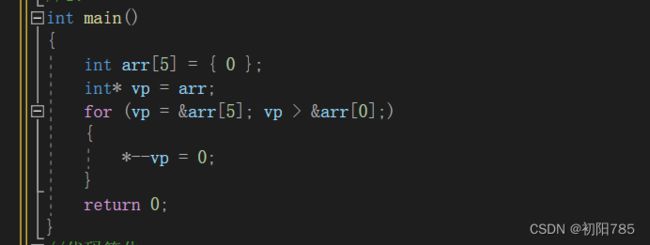
2:
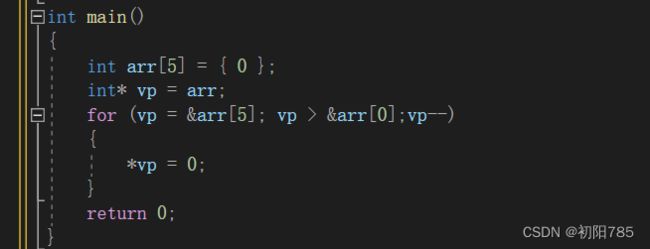
虽然这两段代码所表达的意思是一样的,但是如果非要在这两段代码当中选的话第一种是更好的,实际上绝大部分的编译器上可以顺利通过完成任务的,然而我们还是避免第2种写法,因为标准并不保证它可行。
规定标准:
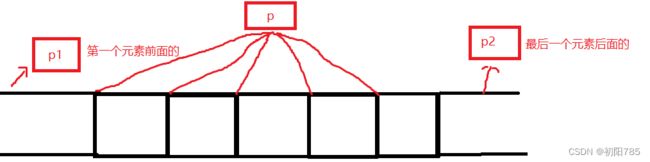
允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较
但是不允许与指向第一个元素之前的那个内存位置的指针进行比较。
5.指针和数组
数组名是什么?我们直接看一个例子:
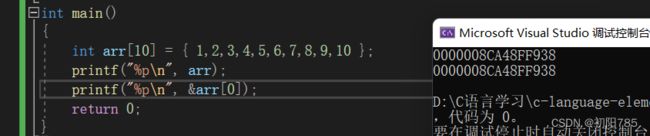
不难看出数组名在绝大多数就是首元素地址arr==&arr[0]。
但是有两个例外:
1:&arr - &数组名 - 数组名不是首元素的地址,而是表示整个数组,取出的是整个数组的地址。
2:sizeof(arr) - sizeof(数组名) - 数组名表示的是整个数组,计算的是整个数组的大小。
但是,请看下面一段代码:

不是说&数组名是取的整个数组的地址吗?为什么地址却和首元素地址相同呢?
那接下来请看这段代码:

不难看出arr+1与arr相差4个字节。
&arr[0]+1与&arr[0]相差也是四个字节,且与上上面一个相同。
但是&arr+1与&arr相差了28,但是这个28是16进制的28,转换成10进制的话就是40,也就是说它+1跳过的是整个数组,这样就能很清晰的看出&数组名代表的是整个数组的地址了。
这里还有一段代码,就可以跟好的将指针与数组名联系起来了:
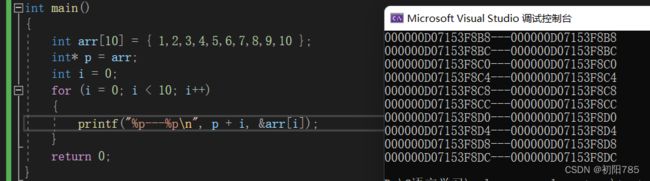
这里不难看出 p+i==arr[i] ,这样就更好的把指针与数组名联系起来了。
6.二级指针
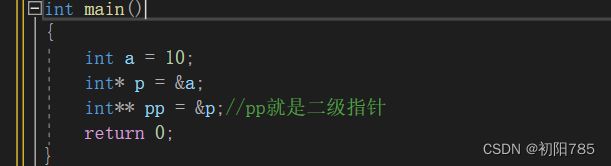
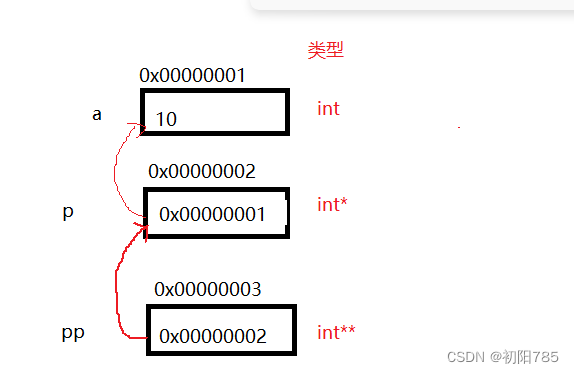
所谓二级指针就是套娃,一次类图,三级指针,四级指针都是一样的
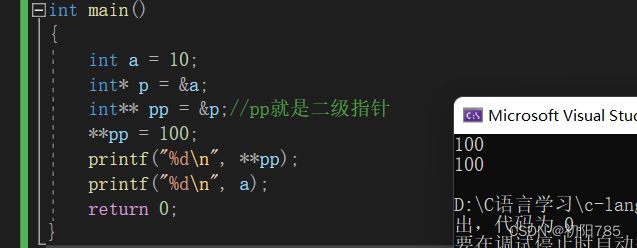
7.指针数组
指针数组本质上是数组 - 是存放指针的数组

以上就是我对初级指针的了解,如有错误地方或者又讲的不明白的地方,请大家多多指教。