VS2010编译libcurl库并简单使用(c语言)
libcurl是什么?
libcurl主要功能就是用不同的协议连接和沟通不同的服务器~也就是相当封装了的sockPHP 支持libcurl(允许你用不同的协议连接和沟通不同的服务器)。 libcurl当前支持http, https, ftp, gopher, telnet, dict, file, 和ldap 协议。libcurl同样支持HTTPS证书授权,HTTP POST, HTTP PUT, FTP 上传(当然你也可以使用PHP的ftp扩展), HTTP基本表单上传,代理,cookies,和用户认证。
一、编译
libcurl使用前需要根据自己的代码编辑器情况进行编译,否则会出现各种各样不适配的问题。
1)到官网下载压缩包(自行选择合适的版本)
网址:( curl - Download )

2)解压压缩包,进入加压后的文件夹,运行buildconf.bat
这一步是为了后续编译作预备工作。注意:错过该步骤,后续编译可能会有异常。
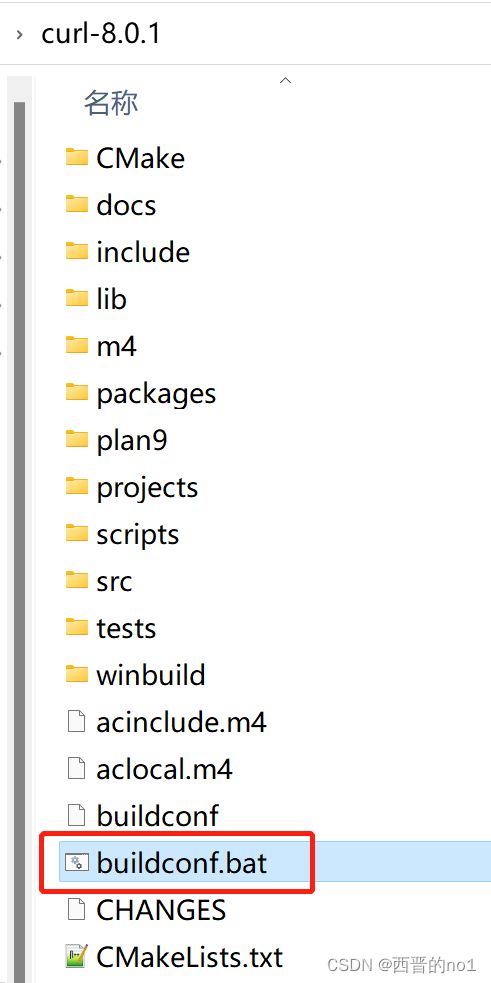
3)在开始菜单栏,找到VS2010,以管理员身份运行x64本机工具命令提示。
4)切换到你的curl库的winbuild 文件夹下
cd C:\Users\xijin001\Desktop\libcrul\curl-8.0.1\winbuild 
5)根据将要在哪个VS版本下使用,输入对应的编译命令,开始编译,等待编译完成。
下述是编译VS2010版本下使用的64位release的静态库的编译命令
nmake /f Makefile.vc mode=static VC=10 MACHINE=x64 DEBUG=no若要编译32位,将x64改为x86;若要编译debug版本,将no改为yes;若编译动态库,将static改为dll;若为其他版本的VS,将10改为你VS版本对应的VC版本值。
vs发布版本与vc版本的对应关系
| VS发布包版本 |
vc版本 |
| Visual Studio 6 |
VC6 |
| Visual Studio 2003 |
VC7 |
| Visual Studio 2005 |
VC8 |
| Visual Studio 2008 |
VC9 |
| Visual Studio 2010 |
VC10 |
| Visual Studio 2012 |
VC11 |
| Visual Studio 2013 |
VC12 |
| Visual Studio 2015 |
VC14 |
| Visual Studio 2017 |
VC15 |
| Visual Studio 2019 |
VC16 |
| Visual Studio 2022 |
VC17 |
成功编译完成的界面

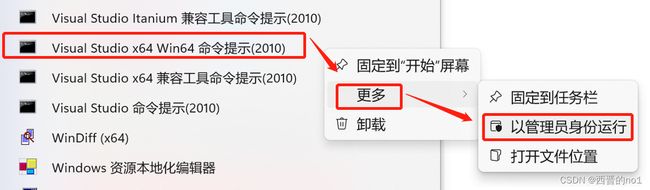
6)至此,库已经编译完成。
编译后的文件会在builds文件夹下

二、配置
1)在vs2010下新建一个控制台项目
可以参考下述链接中的第二部分【二、使用Visual Studio 2010编写C语言 Hello World 程序】内容
VS2022 和 VS2010 C语言控制台输出 Hello World_vs控制台输出_西晋的no1的博客-CSDN博客
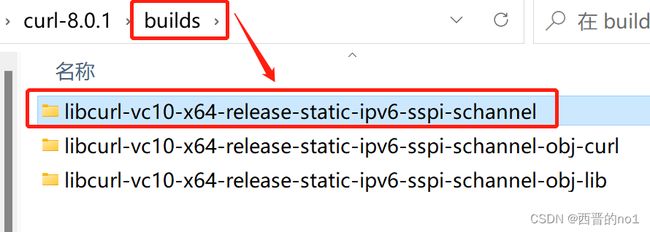
2)将【一、编译】生成的库复制到此项目demo.cpp所在的文件夹中,如下图:
如果是项目工程有多个其它库包含的话,最好把这两个目录重命名一下,例如改成Curl_inc和Curl_lib(后面配置需要跟着改)
3)选择项目名,点击鼠标右键,选择弹出菜单中的属性,进入项目属性页

4)在项目属性页选择与【一、编译】生成的库对应的配置和平台
配置选择Release,平台选择x64,这里的选择是因为【一、编译】编译库时的配置参数是Release,x64,如要debug或x86,请根据【一、编译】重新编译,这里选择对应配置。
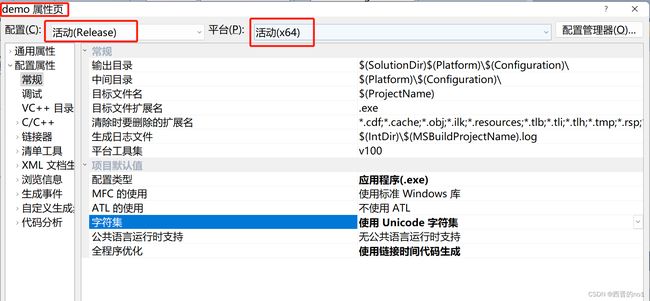
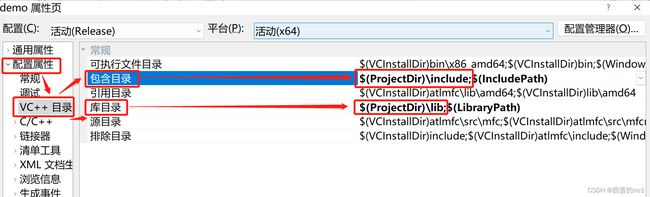
5)在项目属性页的配置属性->VC++目录下分别设置包含目录和库目录
包含目录添加:
$(ProjectDir)\include;库目录添加:
$(ProjectDir)\lib;$(ProjectDir)是项目目录的变量,这样即使移动工程到不同文件夹也不会受影响
6)添加预处理器定义
项目属性页的配置属性->C/C++->预处理器->预处理器定义:添加:
CURL_STATICLIB本项目是静态编译,所以需要将CURL_STATICLIB添加至工程。

7)添加其它需要的库
项目属性页的配置属性->链接器->输入->附加依赖项:
libcurl_a.lib;Ws2_32.lib;Wldap32.lib;winmm.lib;Crypt32.lib;Normaliz.lib;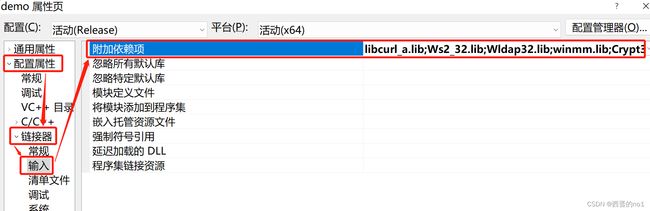
8)C++运行库一般选择/MD。
项目属性页的配置属性->C/C++->代码生成->运行库

至此,完成配置。
注意最后要点击确定,使得上述配置生效。

三、验证上述编译和配置操作成功与否
下面使用一个简单的示例,验证上述【一、编译】和【二、配置】操作是否成功。
将下述代码放到demo.cpp文件中,编译运行,能成功运行并获取到数据,则表明上述【一、编译】和【二、配置】操作成功。
#include
int main() {
CURL* curl = curl_easy_init();
if (curl) {
CURLcode res;
curl_easy_setopt(curl, CURLOPT_URL, "https://www.baidu.com");
res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
return 0;
} 运行截图:

上图中乱码是因为没有对中文进行处理。
处理中文乱码问题,参考链接: https://blog.csdn.net/xijinno1/article/details/130050416
四、更多使用实例
1)最简单的用libcurl库获取网页源码并保存到文件
#include "curl/curl.h"
// 这是libcurl接收数据的回调函数,相当于recv的死循环
// 其中stream可以自定义数据类型,这里我传入的是文件保存路径
static size_t write_callback( void *ptr, size_t size, size_t nmemb, void *stream )
{
int len = size * nmemb;
int written = len;
FILE *fp = NULL;
fp = fopen( (char*) stream, "wb" );
if (fp)
{
fwrite( ptr, size, nmemb, fp );
}
return written;
}
int GetUrl( const char *url, char *savepath )
{
CURL *curl;
CURLcode res;
struct curl_slist *chunk = NULL;
curl = curl_easy_init();
if ( curl ) {
curl_easy_setopt( curl, CURLOPT_VERBOSE, 0L );
curl_easy_setopt( curl, CURLOPT_URL, url );
//指定回调函数
curl_easy_setopt( curl, CURLOPT_WRITEFUNCTION, write_callback);
//这个变量可作为接收或传递数据的作用
curl_easy_setopt( curl, CURLOPT_WRITEDATA, savepath );
res = curl_easy_perform( curl );
if (res == CURLE_OK)
{
return 1;
}
}
return 0;
}
int main( void )
{
if ( GetUrl( "www.baidu.com", "1.txt" ) )
{
printf( "OK\n" );
}
return 0;
}2)获取网页源码并保存变量中,输出到控制台
#include
#include
#include
#include
#include
struct MemoryStruct {
char *memory;
size_t size;
};
static size_t
WriteMemoryCallback(void *contents, size_t size, size_t nmemb, void *userp)
{
size_t realsize = size * nmemb;
struct MemoryStruct *mem = (struct MemoryStruct *)userp;
// 注意这里根据每次被调用获得的数据重新动态分配缓存区的大小
char *ptr = (char *)realloc(mem->memory, mem->size + realsize + 1);
if(!ptr) {
/* out of memory! */
printf("not enough memory (realloc returned NULL)\n");
return 0;
}
mem->memory = ptr;
memcpy(&(mem->memory[mem->size]), contents, realsize);
mem->size += realsize;
mem->memory[mem->size] = 0;
return realsize;
}
int main(void)
{
SetConsoleOutputCP(CP_UTF8);
CURL *curl_handle;
CURLcode res;
struct MemoryStruct chunk;
chunk.memory = (char*)malloc(sizeof(char)); /* will be grown as needed by the realloc above */
chunk.size = 0; /* no data at this point */
curl_global_init(CURL_GLOBAL_ALL);
/* init the curl session */
curl_handle = curl_easy_init();
/* specify URL to get */
curl_easy_setopt(curl_handle, CURLOPT_URL, "https://www.baidu.com");
/* send all data to this function */
// 对于同一次阻塞的curl_easy_perform而言,在写完获取的数据之前,会多次调用 WriteMemoryCallback
curl_easy_setopt(curl_handle, CURLOPT_WRITEFUNCTION, WriteMemoryCallback);
/* we pass our 'chunk' struct to the callback function */
curl_easy_setopt(curl_handle, CURLOPT_WRITEDATA, (void *)&chunk);
/* some servers do not like requests that are made without a user-agent
field, so we provide one */
curl_easy_setopt(curl_handle, CURLOPT_USERAGENT, "libcurl-agent/1.0");
/* get it! */
// 对于同一次阻塞的curl_easy_perform而言,在写完获取的数据之前,会多次调用 WriteMemoryCallback
res = curl_easy_perform(curl_handle);
/* check for errors */
if(res != CURLE_OK) {
fprintf(stderr, "curl_easy_perform() failed: %s\n",
curl_easy_strerror(res));
}
else {
/*
* Now, our chunk.memory points to a memory block that is chunk.size
* bytes big and contains the remote file.
*
* Do something nice with it!
*/
printf("%lu bytes retrieved\n", (unsigned long)chunk.size);
printf("%s", (unsigned long)chunk.memory);
}
/* cleanup curl stuff */
curl_easy_cleanup(curl_handle);
free(chunk.memory);
/* we are done with libcurl, so clean it up */
curl_global_cleanup();
return 0;
}