常用异常检测模型的应用
常用异常检测模型的应用
描述
异常数据检测不仅仅可以帮助我们提高数据质量,同时在一些实际业务中,异常数据往往包含有价值的信息,如异常交易、网络攻击、工业品缺陷等,因此异常检测也是数据挖掘的重要手段。常用的异常检测模型包括IsolationForest(孤立森林)、OneClassSVM(一类支持向量机)、LocalOutlierFactor(LOF,局部离群因子)等。
本任务的主要实验内容包括:
1、分别使用IsolationForest(孤立森林)、OneClassSVM(一类支持向量机)、LocalOutlierFactor(LOF,局部离群因子)进行异常数据检测。
2、比较上述异常检测模型用法的区别,熟悉选择原则。
源码下载
环境
-
操作系统:Windows 10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库列表
scikit-learn 0.24.2 matplotlib 3.3.4 numpy 1.19.5
分析
本任务涉及以下环节:
A)创建包括正常样本和异常样本的数据集、并可视化
B)使用孤立森林模型进行异常检测
C)使用OneClassSVM进行异常检测
D)使用LOF模型进行异常检测
实施
1、创建数据集,并可视化
import numpy as np
import matplotlib.pyplot as plt
rd = np.random.RandomState(99) # 设置随机状态
X_1 = 0.3 * rd.randn(100, 2) # 生成正常数据
X_2 = rd.uniform(-4, 4, size=(20, 2)) # 生成噪音数据
plt.title('Data') # 标题
plt.xlim(-5, 5) # x轴刻度
plt.ylim(-4, 3) # y轴刻度
plt.scatter(X_1[:, 0], X_1[:, 1], s=50, c='g', edgecolor='k', label='normal') # 画正常点
plt.scatter(X_2[:, 0], X_2[:, 1], s=50, c='w', edgecolor='k', label='outlier') # 画异常点
plt.legend()
plt.show()
结果如下:
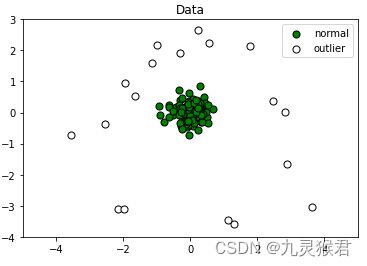
说明:Normal为正常数据,Outlier为噪音点(异常点),接下来使用异常检测模型进行检测,熟悉其调用方法、参数及效果。
2、使用孤立森林(IsolationForest)进行异常检测
from sklearn.ensemble import IsolationForest
X = np.concatenate((X_1, X_2), axis=0) # 合并数据
# IsolationForest
clf = IsolationForest(contamination=0.16) # 创建模型
y_pred = clf.fit_predict(X) # 拟合并预测
plt.title('IsolationForest') # 标题
plt.xlim(-5, 5) # x轴刻度
plt.ylim(-4, 3) # y轴刻度
plt.scatter(X[:, 0], X[:, 1], c=y_pred, s=50, edgecolor='k') # 可视化预测结果
plt.show()
结果如下(左图):
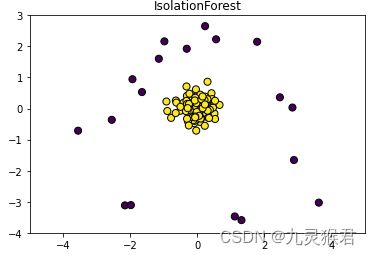
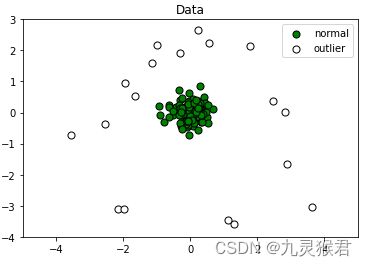
说明:与原数据(右图)对比发现,通过简单调参,独立森林(iForest)算法较好地检测出了原数据中的异常点。
3、使用OneClassSVM(一类支持向量机)进行异常检测
from sklearn.svm import OneClassSVM
# OneClassSVM
clf = OneClassSVM(nu=0.02).fit(X_1) # 拟合训练数据(注意:这里是X_1,不含噪音点)
y_pred = clf.predict(X) # 预测
plt.title('OneClassSVM')
plt.xlim(-5, 5) # x轴刻度
plt.ylim(-4, 3) # y轴刻度
plt.scatter(X[:, 0], X[:, 1], c=y_pred, s=50, edgecolor='k')
plt.show()
结果如下:
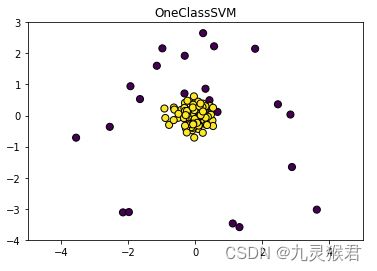
说明:OneClassSVM 本质上属于奇异点检测(Novelty Detection),要求训练数据中不包含噪音点,在未被污染的数据上建立模型,然后在新数据中寻找异常点。
4、使用LocalOutlierFactor(LOF)进行异常检测
from sklearn.neighbors import LocalOutlierFactor
# LocalOutlierFactor
clf = LocalOutlierFactor(contamination=0.16) # 创建模型
y_pred = clf.fit_predict(X) # 拟合数据并预测
plt.title('LocalOutlierFactor') # 标题
plt.xlim(-5, 5) # x轴刻度
plt.ylim(-4, 3) # y轴刻度
plt.scatter(X[:, 0], X[:, 1], c=y_pred, s=50, edgecolor='k') # 预测结果可视化
plt.show()
结果如下:
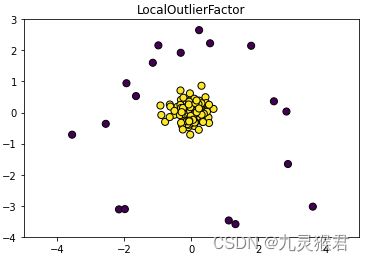
说明:通过调参,LocalOutlierFactor(LOF-局部离群因子)模型也较好地检测出了原数据中的异常点。
“异常值比例”是上述三种异常检测模型共同的参数,决定了正常数据和异常数据的分界线,通常需要根据具体的任务数据调参确定。模型的选择原则是:如果训练集不包含异常样本,则选择OneClassSVM;如果训练集中包括异常样本并且训练集能基本覆盖正常样本,则选择LOF,其他情况使用IsolationForest(孤立森林)。孤立森林的适用性较强,在数据情况不明时可以优先尝试。