【视觉SLAM】An Improved ORB-SLAM2 in Dynamic Scene with Instance Segmentation
Cite: H. Qian and P. Ding.An Improved ORB-SLAM2 in Dynamic Scene with Instance Segmentation[C].2019 Workshop on Research, Education and Development of Unmanned Aerial Systems (RED UAS).Cranfield, UK. 2019:185-191.
Keyword: 特征提取,图像运动分析,图像分割,移动机器人,姿势估计,机器人视觉,SLAM (机器人)
论文目录
- 摘要
- 一、介绍
- 二、动态环境下基于实例分割的ORB-SLAM2
-
- A.Traditional ORB-SLAM2
- B. Mask-RCNN
- C Mask R-CNN Optimizing ORB-SLAM2
- 三、实验结果
-
- A. Experiment 1
- B. Experiment 2
- 四、结论
摘要
为了提高动态环境下ORB-SLAM2位姿估计的精度,针对运动的欺骗性,提出一种实例分割方法去除分布在人体上的运动特征点,提高姿态精度。该方法从输入图像中提取ORB特征点,并对图像进行分割,得到图像中像素的位置。然后去除分布在人体上方的特征点,利用移除后相对稳定的特征点估计位置和姿态。改进的方法用于在TUM数据集上进行测试。结果表明,改进的系统能够显著降低动态环境下姿态估计的绝对误差和相对漂移,证明与传统的ORB-SLAM2系统相比,该方法能显著提高动态环境下姿态估计的精度。
作者在Abstract中高度概况了本文的主旨,讲述了改进的方法点,数据集上的实验结果,方法的有效性。少有的简洁。
一、介绍
位置是移动机器人导航的重要组成部分。在未知环境中,机器人通过传感器获取外部环境信息,获取自己的位置,并将当前的观测结果与地图进行比较。地图应通过观察构建,并且应知道每个观察的位置[1]。 通常的方法是交替进行定位和建图,实现姿态估计并逐步构建环境模型,然后建立自己的全局定位过程,称为同步定位和建图(SLAM)[ 2]。
视觉SLAM基于相机采集的序列图像数据。根据图像信息以及环境与摄像机之间的关系,随着摄像机的移动,它逐步确定周围的环境图,并输出摄像机在环境中的位置[3]。 根据视觉SLAM的一般处理流程,可分为前端处理、后端处理和闭环检测[4] ,如图1 所示。前端处理负责序列图像数据与环境地标[5] 之间的数据关联和参数初始化。目前主要的方式是通过序列图像的特征提取和匹配,对序列图像上同名的特征点进行跟踪,然后将序列图像上同名的观测结果与环境地标相关联,初始化系统的状态参数[6]。 它是构建增量和自主连续定位的必要前提。前端处理算法的适应性直接决定了视觉猛击方法的鲁棒性。后端处理负责对环境图结果和观测数据的定位参数进行优化估计,从而获得高精度的定位和测绘结果[7]。 闭环检测是在SLAM系统中判断环境地标是否已被观察到的过程[8]。 它是构建闭环约束以消除长距离运动后误差累积的基础。以上三部分,完成了视觉SLAM中的数据关联、环境图和位置参数估计以及闭环优化。

图1 一般视觉SLAM的流程图
视觉里程计(VO)作为SLAM系统中最关键的部分,需要根据相邻帧之间相关像素的位置来估计两帧的相对位移,从而估计相机在相邻图像之间的运动和局部地图的外观,从而还原场景的空间结构[9] .但是,视觉里程计的计算是基于一个严格的条件:用于计算关联像素的三个空间点的位置不变,并且这些点参与位姿计算,那么这些点将继续给系统带来误差,最终导致定位失败[10]。
图像分割是将前景与背景分离并在前景中对对象进行分类的过程[11]。 图像实例分割作为深度学习的一个重要分支,近年来在自动驾驶、场景识别和医学图像分析中得到了广泛的应用[12]。 室内场景中的实例分割旨在将图像分割为常见的类别,例如人、猫、狗、杯子、椅子、桌子、计算机等,如图 2 所示。

图2 图像实例分割
实例分割和 SLAM 似乎是两个独立的模块,但在许多应用程序中,它们相互补充。一方面,实例分割的信息可以帮助SLAM提高建图和定位的准确性,特别是对于复杂的动态场景。传统的SLAM地图和定位大多基于像素级别的几何匹配。借助实例分割信息,我们可以将数据关联从传统的像素级升级到对象级,提高复杂场景的准确率[13 , 14]。 另一方面,利用SLAM技术计算物体之间的位置约束,可以一致约束同一物体在不同角度时间的识别结果,从而提高场景理解的准确性[15]。 该文提出一种通过实例分割优化SLAM系统的方法。首先,通过实例分割获得图像中人和动物像素的位置;然后,将分布在人和动物身体上的像素从将涉及姿势估计的像素中移除,然后使用残差像素计算下一个姿势。基于开源系统ORB-SLAM2,Mask R-CNN嵌入到系统的视觉里程表中,并在TUM数据集中进行测试。
首先介绍了VSLAM的框架,包含传感器输入——>视觉里程计(前端)——>优化(后端),闭环——>建图。然后介绍了实例分割这一深度学习算法,将实例分割与SLAM结合,可以将数据关联从像素级提升到对象级。
二、动态环境下基于实例分割的ORB-SLAM2
A.Traditional ORB-SLAM2
说到视觉SLAM,许多研究人员首先想到的是A.J.戴维森的MonoSLAM工作。戴维森教授是视觉SLAM研究领域的先驱。他在2007年提出的单目SLAM是第一个实时单目视觉SLAM系统[16]。 近年来,很多新颖优秀的SLAM开源解决方案也出现在人们的视野中。如表1 所示。
表一 常见的开源SLAM解决方案

ORB-SLAM2 是一个实时 SLAM 系统,可以在基于 ORB 特征点的 CPU 上运行。它包含三个主线程:跟踪线程 [17] ,如图 3 所示。跟踪线程提取和匹配 ORB 特征点,然后通过最小化重新投影误差来估计两帧之间的相对姿势。局部建图线程针对 BA(束调整、设置数字调整)优化局部地图中所有帧和路标点的位姿。闭环检测线程通过关键帧检测整个地图是否有闭环,并通过优化位姿图[18] 来纠正累积误差。

图3 ORB-SLAM2系统的螺纹和结构
在SLAM中,姿势是机器人在整个环境地图中的空间位置和姿势。空间位置是机器人的XYZ坐标。视觉姿态是指机器人的前进方向(一般是相机的方向)相对于xyz的三个方向的偏差角。在ORB-SLAM2中,机器人的位置和姿势由平移和旋转四元数组成的七个元素表示[19] ,如下所示:
![]()
前三个元素是平移向量,后四个元素是表示旋转的四元数。
跟踪线程的任务是根据图像的变化计算两个相邻帧的位置和姿势。也就是说,后一帧与前一帧相比有多少平移和旋转[20]。 然后将计算结果给出后端,后端累积并优化两帧之间的相对姿态,最终得到机器人当前姿态并实现定位。
求解两帧之间相对姿态的原理如图4 所示,两帧图像P1和P2被相机获取。特征提取后,特征点P1在 I 中获得 1 和特征点P2在 I 中获得 2。假设P1和 P2根据特征匹配结果为距离较近的点对,则P1和 P2是同一三维点在两帧图像上的投影。
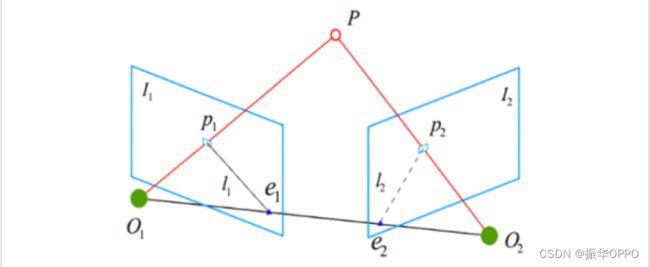
图4 对极几何约束
K 是相机的内部参数矩阵。当相机处于不同位置时,投影P 1和 P 2是点P通过内部参数矩阵变换得到的不同像素坐标。 T 是 I 的姿势 2相对于 I 1。假设两帧之间可以匹配多组点对,则可以通过从这些点对构造方程来求解相对姿势。它可以通过求解基本矩阵和相应的矩阵来解决[21]。
但是,在空间点P相对于整个环境静止的条件下,T的计算必须有效。如果点在姿态估计过程中移动, 公式(2)将不再成立,并且会出现错误。最坏的情况是,姿势估计中的所有像素都将执行与相机相同的运动,并且 SLAM 估计的姿势将始终为 0。
B. Mask-RCNN
Mask R-CNN是He等人在Faster Mask R-CNN的基础上开发的深度神经网络模型。它在物体识别和单个图像分割方面的优异性能使其成为目前最好的技术之一[22]。
整个掩码R-CNN算法非常灵活。它将FCN添加到原始的Fast R-CNN算法中,以生成相应的MASK分支。但最终还是能达到5fps的速度,和原来的Fast R-CNN的速度差不多。提出了相应的ROI对齐策略和FCN精确像素掩码,使得获得高精度成为可能。Mask R-CNN算法可用于完成许多任务,包括目标分类,目标检测,语义分割,实例分割,人类手势识别等许多任务。它具有良好的可扩展性和易用性。
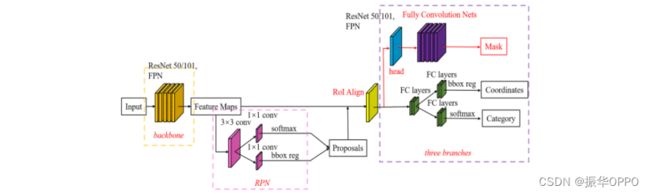
C Mask R-CNN Optimizing ORB-SLAM2
为了提高ORB-SLAM2系统在动态场景中的姿态估计精度,并考虑到室内环境中大多数移动像素来自人和动物,提出了一种利用Mask R-CNN去除分布在人体上的动态像素的方法,并将去除的像素用于估计ORB-SLAM2系统的位置和姿态[23]。 Mask R-CNN 实例分割嵌入在 ORB-SLAM2 的跟踪线程中 [24] 。改进的跟踪线程如图 6 所示。
 图6 使用掩码 R-CNN 跟踪线程
图6 使用掩码 R-CNN 跟踪线程
本文在ORB-SLAM2系统的跟踪线程中增加了实例分割功能。同时,对原始图像进行分割,得到人和动物像素的坐标。然后,将分布在人或动物身上的一些特征点从原始特征点中移除,然后利用这些特征点进行特征匹配和姿态估计,摆脱了可能移动的像素干扰。ORB-SLAM2在动态场景中表现出更好的抗干扰性能,精度大大提高。
先介绍原始的ORB-SLAM2框架,然后介绍Mask RCNN,最后利用Mask RCNN在关键帧提取ORB特征点的同时进行Instance Segmentation,对照着分割结果,将特征点落在动态对象上的进行剔除。
三、实验结果
本文进行了两个实验:实验1是从单帧图像中去除动态特征点,然后比较传统ORB-SLAM2和改进ORB-SLAM2的特征匹配结果。实验2运行TUM通用数据集的改进系统,并将其与原始系统进行比较。
本文使用的数据集来自 TUM 的rgbd_dataset_freiburg3_walking_xyz数据集。该数据集旨在评估SLAM系统或测程计算方法在具有快速移动动态对象的场景中的鲁棒性。数据集的真实轨迹由八个高速(100Hz)摄像机组成的运动捕捉系统获得。
Evo是Python SLAM系统的评估工具,用于对里程表和SLAM算法的轨迹输出进行处理、评估和比较。
它可以计算绝对姿势误差(APE)和相对姿势误差(RPE)。
绝对姿态误差直接计算相机姿态的真实值与SLAM系统的估计值之差。程序首先根据姿势的时间戳将真实值与估计值对齐,然后计算每对姿势之间的差异值,最后以图表的形式输出。该标准非常适合两次相同的评估和计算。同样,时间戳对齐后,实际姿势和位置估计值计算同一时间间隔的位置和姿态变化,然后做出差值以获得相对姿态误差。该标准适用于估计系统的漂移。
A. Experiment 1
在实验1中,在数据集中随机选择单帧图像。Mask R-CNN和ORB用于去除不匹配和除人体的外部点。如图 7 所示。利用Mask R-CNN算法获取识别后的目标轮廓信息和标签信息,去除图像人类轮廓中的特征点。

图7 通过实例分割消除异常值
图8是传统ORB-SLAM2系统和改进的ORB-SLAM2系统中的特征匹配结果。在改进的系统中,消除了分布在人体上的特征点,在匹配过程中忽略了这些特征点,从而达到了消除它们的目的。

图8 传统ORB-SLAM2系统和改进ORB-SLAM2系统的特征提取和匹配结果
B. Experiment 2
本实验分别在上述数据集上运行传统的ORB-SLAM2和改进的ORB-SLAM2。在精度方面,使用数据集给出的真实位姿情况.txt用于比较ground_truth、ORB-SLAM2和改进的ORB-SLAM2,跟踪比较的结果如图9 所示。图10和表2是绝对姿势误差(APE)的输出结果,图11和 表3是相对姿势误差(RPE)的输出结果。

图9 ground_truth、传统 ORB-SLAM2 和 improved_ORB-SLAM2 的轨道对比图

图10 绝对姿势误差
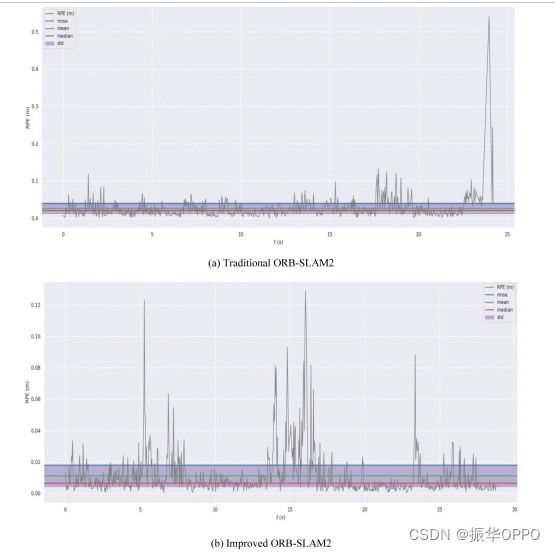
图11 相对姿势误差
与绝对位姿误差(APE)相比,改进后的系统在误差的代表性值上优于传统系统,说明与传统系统相比,改进的系统性能有了很大的提高。同样,与相对位姿误差(RPE)相比,改进的系统在数据方面优于传统系统,即改进的系统在克服漂移方面有了很大的改进。

综上所述,改进的ORB-SLAM2在动态环境中的性能明显高于传统的ORB-SLAM2。
在TUM的rgbd_dataset_freiburg3_walking_xyz数据集进行两组实验。第一组实验是提取和匹配特征点,改进后的,我们叫做Mask ORB-SLAM2能够去除动态物体像素上的特征点,从而去除动态物体的匹配。第二组实验,比较的是最常用的APE和RPE,绝对和相对位姿误差。实验结果画图做表,图中注意y轴的尺度,可以看到小了一个量级。当然表有时候比图还直观,比较数值大小就行。
四、结论
基于传统的ORB-SLAM2,针对动态场景中姿态估计不准确的问题。本文采用实例分割法去除动态特征点,并对常用数据集进行实验验证。结果表明,改进的系统在动态环境下能够显著降低位置姿态估计误差和相对漂移,从而提高整个系统的精度。
本文基于ORB-SLAM2改进了特征提取和匹配的方法,去除了环境中的动态物体。具体而言,在传感器图像传入后,分别提取特征点和实例分割,再根据实例分割结果,将动态物体像素上的特征点去除,只匹配剩下的静态物体特征点。然后进行局部建图,BA优化,检测闭环。在TUM数据集上进行了两组实验,实验结果表明能够有效处理动态物体,在动态环境下显著降低位姿估计误差和累积漂移。方法思路简单,效果好。