C语言程序运行过程之预处理与预处理指令详解
本文主要阐述预处理的工作内容及常见预处理指令的用法等,相信看完本文以后,你对预处理的理解会步入一个新的台阶。
首先我们需要知道C语言程序在运行时需要经历的几个过程:
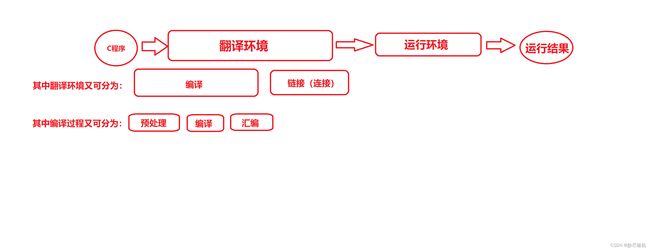
简单介绍一下各个阶段的作用:
预处理过程:完成了头文件的包含、#define定义的符号和宏的替换、删除了注释。
文件由 .c 结尾变为 .i 结尾
编译过程(指下面那个编译):将C语言代码转换为汇编代码。
文件由 .i 结尾变为 .s 结尾
汇编过程:将汇编代码转换为机器指令(即二进制指令)。
文件由 .s 结尾变为 .o(Linus)或 .obj(Windows) 结尾
链接过程:将所有的目标文件和链接库组织成一个可执行文件。
生成一个以 .exe 结尾的可执行文件
由于一个程序中往往有不止一个源文件,这些源文件分别经过编译后,形成了多个 .o 结尾的目标文件,在链接过程将它们连接起来。由于库函数是在链接库中定义的,所以还需要把链接库也连接进来。
链接库以 .a(Linus) 或 .lib(Windows) 结尾
运行环境:用于实际执行代码。
本文主要解释预处理阶段,我们先来了解一下几个常用的预处理指令
#define定义宏
宏定义的格式:
#define 宏名 宏定义字符串
define前面以#开始,表示它在编译预处理中起作用,而不是真正的C语句,因此行尾无需跟分号。
宏名的定义与C语言标识符的定义规则相同,一般为了与变量名,函数名区别,常采用大写字母串作宏名,宏名与宏定义字符串间用空格分割,因此宏名中间不能有空格。宏定义字符串是宏名对应的具体实现过程,可以是任意字符串,中间可以有空格,以回车作结束符。
宏后面如果带括号,那么被认为是宏的参数,括号内可以有空格,例如:
宏的实现过程:在程序预编译时,所有出现宏名的地方,都会用宏定义字符串来替代。所以宏又被称为宏替换。值得注意的是:如果宏定义字符串后面跟分号,编译预处理时会把分号也作为宏替换内容。

宏的用途包括:
1. 定义符号常量,如PI,数组大小定义,例如:

这样定义数组大小可以增加程序的灵活性,比如更改数组大小的时候就不必在多处修改了。
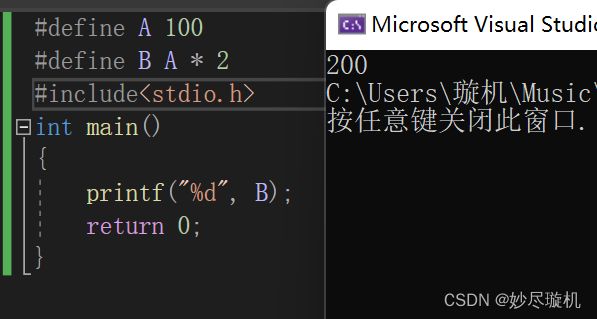
当然C语言也允许嵌套定义,例如:
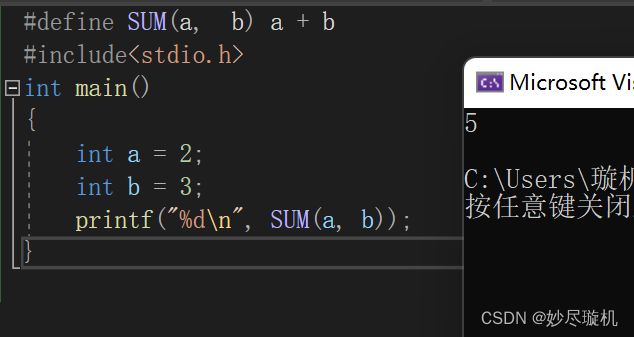
2. 简单的函数功能实现,宏的代码量有限,只能在一行内完成,因此它只能实现简单的函数功能,例如:
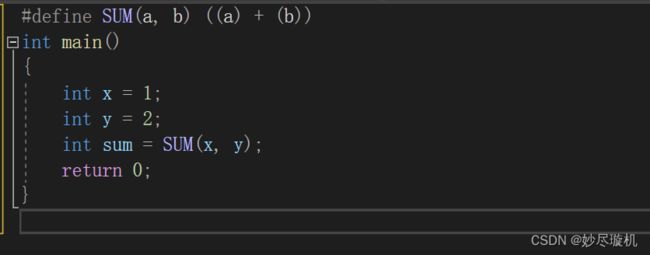
此处对于SUM(a,b),在预处理时,首先会用 x,y 替换掉 a,b ,然后再将SUM(x,y)替换为x+y。在这里需要注意的是,我们需要给每个参数都加上括号,最后再给整体加括号,如果不加,可能会造成意想不到的麻烦,举个例子: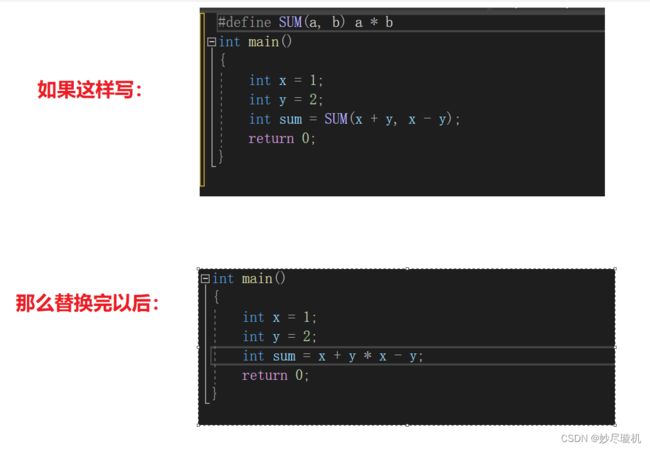

3. 当程序中需要多次书写一些相同内容时,不妨把它简写成宏,例如:

此处的“ \ ”表示该行未结束,与下一行合起来成为完整的一行。
当然我也有见过这样写的:

这样写确实方便,但会降低代码的可读性,循环的次数也无法更改,限制了语句的灵活性 。
#define定义函数 与 函数 的区别对比
1. 实现过程不同
如上所言,宏在编译预处理阶段先完成参数的替换,再完成宏的替换。而函数的实现需要到运行环境中执行,首先进行参数传递,把实参值复制给形参,然后暂停主函数的执行,去执行该函数,函数得出的结果用 return 返回(也可能不返回)
宏的替换是完完整整的替换,而函数调用时,如果实参是表达式,那么先计算表达式的值,再把值传过去。
如果运算较简单,那么用宏来完成效率更高,因为宏的替换过程较简单,而函数需要传参和返回,工作量就要大上许多
2. 参数类型的区别
当用宏实现函数功能时,你会发现宏的参数没有类型限制,而函数则有明确的类型限制:
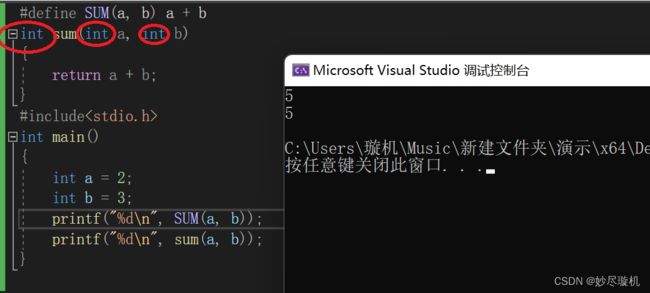
即宏没有类型限制 ,因此这里的宏可以完成任意类型的计算:
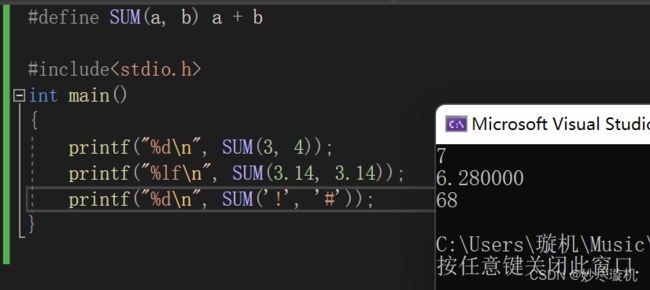
当传入字符时,所得到的值为两个字符的 ascll 码值之和。
所以宏的优缺点就显而易见了,没有类型限制,所以更灵活,也就不够严谨。
3. 宏可以做到函数做不到的事
比如:宏的参数可以出现类型,但函数做不到,比如这样:
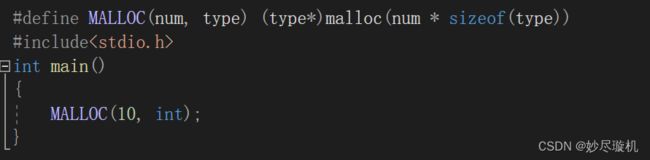
经过宏替换之后:

4. 宏替换可能会产生副作用
比如:

宏替换完成后:
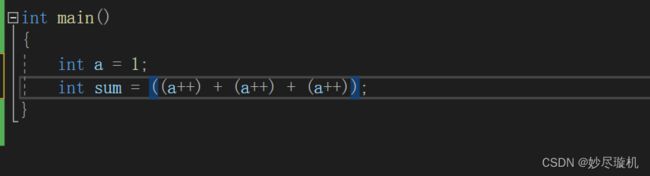
这样的代码是无法预测的,有歧义。
5. 其它方面
相比于函数,宏也有劣势。比如:宏无法调试等。
#include实现文件包含
以 .h 结尾的文件通常称为头文件,头文件有两种:一种是C语言给定的标准头文件(如 stdio.h),一种是自己定义的头文件。
#include 包含头文件同样有两种形式,一种是尖括号<>,一种是双引号 " " (英文中的双引号)
如果使用 <> ,那么程序会直接去 C系统设置好的 include 文件夹中把指定的文件包含进来,
如果使用 " " ,那么程序先去当前工作文件夹中寻找指定文件,若找不到,则再去C系统设置好的 include 文件夹找。
所以 <> 常用来包含C语言给定的标准头文件,而 " " 常用来包含自己定义的头文件。
当然,双引号也可以用来包含C语言给定的标准头文件,但是效率较低。
工作原理
在预处理阶段,将被包含的头文件内容插入到 #include 所在的位置,例如:

test.h 的内容如下:
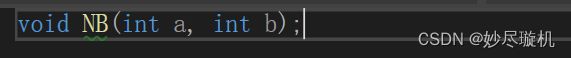
那么经过预处理以后:

如果包含的是库文件,那么把相应的库文件也替换按上述方式替换进来。
可能有人会问为什么我不在 test.h 中将函数完整地定义出来,那是因为:
头文件通常只声明函数,而函数的定义是在其它源文件中完成的。
理解了工作原理,那么相信你也能理解这样一个问题:
如果头文件被重复包含,那么经过预处理后生成的 .i 文件代码量会大大增加,效率就会大打折扣,而且可能存在宏名冲突的问题,比如:

而 test.h 的内容如下:

在这里 stdio.h 这个头文件就被包含了两次。
如何避免这种情况呢?
在头文件首行加入 #pragma once 可以避免该头文件被重复引用,例如现在将 test.h 的内容改为如下:

那么 test.h 这个头文件至多只能被包含一次,同时注意到 stdio.h 这个头文件被包含了两次,所以应在 test.c 中删去 #include
条件编译指令
条件编译指令主要有#if,#elif,#else, #endif 等,其基本格式为:
#if 表达式
语句段1
#elif 表达式
语句段2
#else
语句段3
#endif
下面直接来看例子:
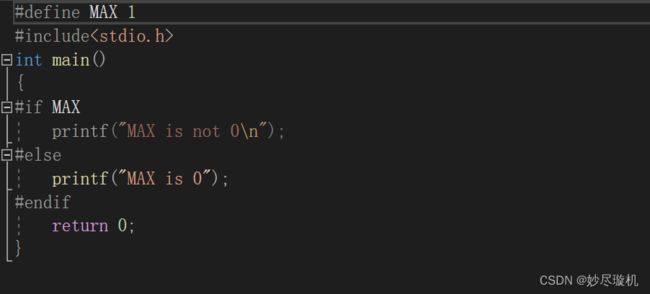
#if 后面的表达式为真, 语句段1被执行,语句段2不被执行,与 if-else 相似,类比推理即可,它与if-else不同的地方在于:
条件编译中:
不被执行的语句段在预处理阶段就被删去,只留下要被执行的语句段。
前面要加#。
else if 更改为 #elif。
程序段中有多条语句时,不必使用大括号{}。
末尾必须跟 #endif ,这样才知道要被处理的程序段是那一段。
下面介绍 #ifdef ,#ifndef,#undef。
#ifdef 使用的基本格式如下
#ifdef 表达式
语句段
#endif
如果表达式被定义,则语句段执行,如果未定义,则不执行,预处理阶段删去,例如:
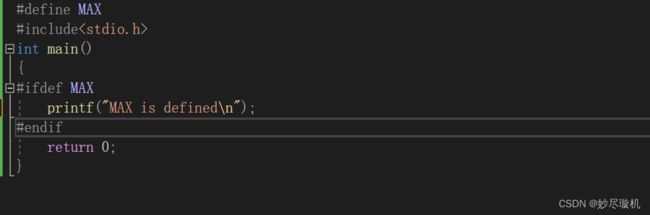
注意,只要表达式被定义了,那么语句段执行,不在乎表达式的值为真为假,结尾也要跟 #endif。

#ifndef 使用的基本格式如下
#ifndef 表达式
语句段
#endif
如果表达式未被定义,则语句段执行,如果已经定义,则不执行,预处理阶段删去,与 #ifdef 正好相反

#undef 的用法如下

对于前面定义的宏,如果使用 #undef 宏 那么这条语句后的宏就解除了定义,不能再使用。
到这里,本文就完结了,你学会了吗?