sparkSQL----sql简介 创建DataFrame sparksql读取各种文件 Dataset的Encoder
sparksql简介
Spark SQL是Spark用来处理结构化数据的
RDD + Schema = 可以先生成逻辑计划(DAG), 在优化后生成物理计划(Task)
Dataset: 更加智能的RDD, 有Encoder并且在Encoder有Schema和序列化和反序列化方法, 还带有执行计划
有执行计划, 先根据你对Dataset的操作生成逻辑计划, 然后在生成优化过的逻辑计划, 最后生成进一步优化的物理计划
强数据类型, 将数据放在堆外内存, 效率更高, 更加节省空间, 内存管理起来更加灵活高效
DataFrame: 是Dataset[Row]的一种特殊格式
DataFrame相当于RDD+Schema, 有了更多的描述信息
有rowEncoder, 并且还有schema
强数据类型, 将数据放在堆外内存, 效率更高, 更加节省空间, 内存管理起来更加灵活高效
网站(spark.apache.org/sql)
1. 什么是DataFrames?
与RDD类似, DataFrame也是一个分布式数据容器[抽象的], 然而DataFrame更像传统数据库的二维表格, 除了RDD的描述数据以外, 还记录数据的结构信息, 即 schema,
与hive相似, DataFrame也支持嵌套数据类型(struct, array和map)
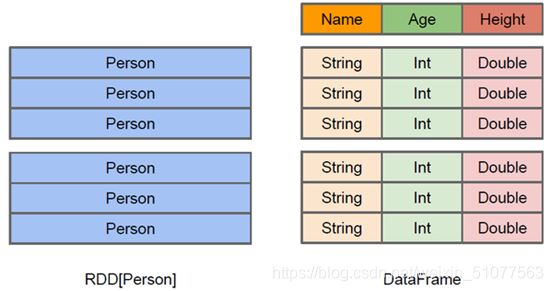
DataFrame = RDD + Schema【更加详细的结构化描述信息】,以后在执行就可以生成执行计划,进行优化,是Dataset的一种特殊格式
2. sparksql特性
1) 易整合
Spark SQL使得在spark编程中可以混搭SQL和算子API编程
2) 统一的数据格式
Spark SQL为各类不同数据源提供统一的访问方式,可以跨各类数据源进行愉快的join;所支持的数据源包括但不限于: Hive / Avro / CSV / Parquet / ORC / JSON / JDBC等;
3) 兼容Hive
Spark SQL支持HiveQL语法及Hive的SerDes、UDFs,并允许你访问已经存在的Hive数仓数据;
4) 标准的数据连接
Spark SQL的server模式可为各类BI工具提供行业标准的JDBC/ODBC连接,从而可以为支持标准JDBC/ODBC连接的各类工具提供无缝对接;(开发封装平台很有用哦!)
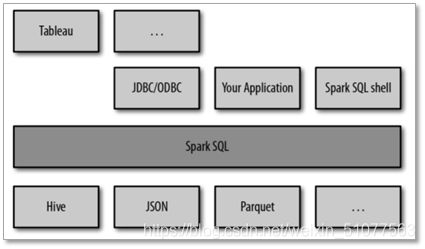
SparkSQL可以看做一个转换层,向下对接各种不同的结构化数据源,向上提供不同的数据访问方式
创建DataFrame (常用第一种和第三种, 第三种是最正宗的写法)
第一种创建方法: 将RDD关联case class创建DataFrame
package cn.doit.spark.sql01
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/*
将RDD关联Case class创建DataFrame
+------+-------+------+
| name|subject|scores|
+------+-------+------+
|孙悟空| 数学| 95|
| 娜娜| 语文| 94|
|孙悟空| 语文| 87|
| 宋宋| 数学| 86|
| 婷婷| 数学| 85|
| 娜娜| 英语| 84|
| 宋宋| 英语| 84|
| 婷婷| 英语| 78|
|孙悟空| 英语| 68|
| 婷婷| 语文| 65|
| 宋宋| 语文| 64|
| 娜娜| 数学| 56|
+------+-------+------+
*/
object DataFrameCreateDemo01 {
def main(args: Array[String]): Unit = {
//创建SparkConf, 然后创建SparkContext
//使用SparkContext创建RDD
//调用RDD的算子(Transformation和Action')
//释放资源 sc.stop
//创建SparkSession builder(构建) getOrCreate(创建)
val spark: SparkSession = SparkSession.builder()
.appName("DataFrameCreateDemo01")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/tb_stu")
val rdd2: RDD[User] = rdd1.map(e => {
val fields = e.split("\t")
User(fields(0), fields(1), fields(2).toInt)
})
//导入隐式转换
import spark.implicits._
//将RDD转成特殊的数据集
val df: DataFrame = rdd2.toDF()
//使用两种风格的API
//使用SQL风格
//创建一个临时的视图
df.createTempView("tb_stu")
val df2: DataFrame = spark.sql("SELECT name, subject, scores FROM tb_stu ORDER BY scores DESC, name ASC" )
//默认最多20行
df2.show()
//使用DSL(特定领域语法)
// val df3: Dataset[Row] = df.select("name", "subject", "scores").orderBy($"scores".desc, $"name".asc)
// df3.show()
}
case class User(name: String, subject: String, scores: Int)
}
第二种方式创建: 将RDD关联scala class创建DataFrame
package cn.doit.spark.sql01
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.beans.BeanProperty
//将RDD关联scala class创建DataFrame
object DataFrameCreateDemo02 {
def main(args: Array[String]): Unit = {
//创建sparkSession
val spark: SparkSession = SparkSession.builder()
.appName("DataFrameCreateDemo02")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/tb_stu")
val rdd2: RDD[User] = rdd1.map(e => {
val fields = e.split("\t")
new User(fields(0), fields(1), fields(2).toInt)
})
//导入隐式转换
import spark.implicits._
//将RDD转成特殊的数据集
val df: DataFrame = spark.createDataFrame(rdd2, classOf[User])
//查询
val df2 = df.select("name", "subject", "scores").orderBy($"scores".desc)
df2.show()
}
class User(@BeanProperty
val name: String,
@BeanProperty
val subject: String,
@BeanProperty
val scores: Int)
}
第三种方式创建(正宗写法): 将RDD中的数据转化成row,并关联schema
package cn.doit.spark.sql01
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
//将RDD中的数据转成row, 并关联schema
object DataFrameCreateDemo03 {
def main(args: Array[String]): Unit = {
//创建sparkSession
val spark: SparkSession = SparkSession.builder()
.appName("DataFrameCreateDemo03")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/tb_stu")
//row的字段没有类型,没有名称
val rowRdd: RDD[Row] = rdd1.map(e => {
val fields = e.split("\t")
Row(fields(0), fields(1), fields(2).toInt)
})
//关联schema(字段名称, 数据类型, 是否可以为空)
val schema = StructType(
Array(
StructField("name", StringType),
StructField("subject", StringType),
StructField("scores", IntegerType)
)
)
//将RowRDD和StructType类型的Schema进行关联
val df: DataFrame = spark.createDataFrame(rowRdd, schema)
df.printSchema()
df.show()
}
}
package cn.doit.spark.sql01
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
//将RDD中的数据转成row, 并关联schema
object DataFrameCreateDemo03 {
def main(args: Array[String]): Unit = {
//创建sparkSession
val spark: SparkSession = SparkSession.builder()
.appName("DataFrameCreateDemo03")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/tb_stu")
//row的字段没有类型,没有名称
val rowRdd: RDD[Row] = rdd1.map(e => {
val fields = e.split("\t")
Row(fields(0), fields(1), fields(2).toInt)
})
//关联schema(字段名称, 数据类型, 是否可以为空)
val schema = StructType(
Array(
StructField("name", StringType),
StructField("subject", StringType),
StructField("scores", IntegerType)
)
)
//将RowRDD和StructType类型的Schema进行关联
val df: DataFrame = spark.createDataFrame(rowRdd, schema)
df.printSchema()
df.show()
}
}
sparksql读取各种文件
1. sparksql读写json数据
优点: 数据中自带schema, 数据格式丰富,支持嵌套类型
缺点: 传输,存储了很多冗余的数据
package cn.doit.spark.sql01
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object CreateDataFrameReadJSON {
def main(args: Array[String]): Unit = {
//创建sparkSession
val spark: SparkSession = SparkSession.builder()
.appName("CreateDataFrameFromJSON")
.master("local[*]")
.getOrCreate()
//RDD数据从哪里读取
//schema: 字段名称, 类型(json文件中自带schema属性)
val df: DataFrame = spark.read.json("hdfs://linux01:8020/user.json")
df.createTempView("tb_user")
// val df2: DataFrame = spark.sql("select name, age, fv from tb_user where _corrupt_record is null")
import spark.implicits._
val df2: Dataset[Row] = df.select("name", "age", "fv").where($"_corrupt_record".isNull)
df2.show()
}
}
package cn.doit.spark.sql01
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DoubleType, IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object CreateDataFrameWriteJSON {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName("CreateDataFrameWriterJSON")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/tb_stu")
val rowRdd: RDD[Row] = rdd1.map(e => {
val fields = e.split("\t")
Row(fields(0), fields(1), fields(2).toInt)
})
val schema: StructType = StructType(
Array(
StructField("name", StringType),
StructField("subject", StringType),
StructField("scores", IntegerType)
)
)
//关联schema
val df: DataFrame = spark.createDataFrame(rowRdd, schema)
df.write.json("D://b.json")
df.show()
}
}
2. sparksql读写jdbc
package cn.doit.spark.sql01
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDataFrameReadJDBC {
def main(args: Array[String]): Unit = {
//创建sparkSession
val spark: SparkSession = SparkSession.builder()
.appName("CreateDataFrameReadJDBC")
.master("local[*]")
.getOrCreate()
//获取用户名密码
val props = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "123456")
/*
一定要有schema信息
在执行时调用read.jdbc方法一定要获取数据库表的信息
read.jdbc是在Driver端跟数据库查询, 返回指定的schema信息作为DataFrame的信息
*/
val df: DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/sys?characterEncoding=utf-8", "products", props)
df.show()
}
}
package cn.doit.spark.sql01
import java.util.Properties
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SaveMode, SparkSession}
object CreateDataFrameWriteJDBC {
def main(args: Array[String]): Unit = {
//创建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName("CreateDataFrameWriteJDBC")
.master("local[*]")
.getOrCreate()
//读取文件
val sc: SparkContext = spark.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/tb_stu")
val rowRdd: RDD[Row] = rdd1.map(e => {
val fields = e.split("\\s+")
Row(fields(0), fields(1), fields(2).toInt)
})
//创建schema
val schema: StructType = StructType(
Array(
StructField("name", StringType),
StructField("subject", StringType),
StructField("scores", IntegerType)
)
)
//关联rowRdd和schema
val df: DataFrame = spark.createDataFrame(rowRdd, schema)
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password", "123456")
/*
mode(SavaMode.ErrorIfExists): 如果输出的目录或表已经存在就报错
mode(SaveMode.append):追加
mode(SaveMode.Ignore): 有数据就不写,没数据就往里写
mode(SaveMode.Overwrite): 将原来的目录或数据库表删除,然后在新建目录或表将数据写入
*/
df.write.mode(SaveMode.Overwrite)jdbc("jdbc:mysql://localhost:3306/doit_19?characterEncoding=utf-8", "tb_stu", prop)
df.show()
}
}
3. sparksql读写parquet
Parquet是SparkSQL的最爱
数据中自带schema(头尾信息: 数据的描述信息), 数据格式丰富, 支持嵌套类型.
数据存储紧凑(支持压缩), 查询快(按需查询, 快速定位)
package cn.doit.spark.sql01
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDataFrameReadParquet {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName("CreateDataFrameReadParquet")
.master("local[*]")
.getOrCreate()
val df: DataFrame = spark.read.parquet("data/outPar/part-00000-379ec9d2-35d8-4110-98e2-3bcbf56561b0-c000.snappy.parquet")
df.show()
}
}
package cn.doit.spark.sql01
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object CreateDataFrameWriteParquet {
def main(args: Array[String]): Unit = {
//创建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName("CreateDataFrameWriteParquet")
.master("local[*]")
.getOrCreate()
//读取文件
val sc = spark.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/tb_stu")
val rowRdd: RDD[Row] = rdd1.map(e => {
val fields = e.split("\\s+")
Row(fields(0), fields(1), fields(2).toInt)
})
//创建schema(字段名称, 数据类型, 是否可以为空)
val schema: StructType = StructType(
Array(
StructField("name", StringType),
StructField("subject", StringType),
StructField("scores", IntegerType)
)
)
//关联rowRdd和schema
val df: DataFrame = spark.createDataFrame(rowRdd, schema)
df.write.parquet("data/outPar")
df.show()
}
}
4. sparksql读写CSV
特点: 数据存储相对比较紧凑
缺点: schema信息不完整, 数据格式比较单一
package cn.doit.spark.sql01
import org.apache.spark.sql.SparkSession
object CreateDataFrameReadCSV {
def main(args: Array[String]): Unit = {
//创建sparkSession
val spark: SparkSession = SparkSession.builder()
.appName("CreateDataFrameReadCSV")
.master("local[*]")
.getOrCreate()
//读取csv文件
val df = spark.read
.option("header", "true") //把第一行当做表头
.option("inferSchema", "true") //推断数据类型(不好)
.csv("data/user.csv")
//创建视图
df.createTempView("tb_user")
//指定列的名称
// val df2 = df.toDF("name", "age", "fv_value")
df.printSchema()
df.show()
}
}
package cn.doit.spark.sql01
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.sql.types.{DoubleType, IntegerType, StringType, StructField, StructType}
object CreateDataFrameWriteCSV {
def main(args: Array[String]): Unit = {
//创建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName("CreateDataFrameWriteCSV")
.master("local[*]")
.getOrCreate()
//读取文件
val sc = spark.sparkContext
val rdd1: RDD[String] = sc.textFile("data/user.csv")
val rowRdd: RDD[Row] = rdd1.map(e => {
val fields = e.split(",")
Row(fields(0), fields(1).toInt, fields(2).toDouble)
})
//创建schema
val schema: StructType = StructType(
Array(
StructField("name", StringType),
StructField("age", IntegerType),
StructField("fv_value", DoubleType)
)
)
//关联rdd和schema
val df: DataFrame = spark.createDataFrame(rowRdd, schema)
df.write.csv("data/out")
df.printSchema()
df.show()
}
}
5. sparksql读写ORC
package cn.doit.spark.sql01
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDataFrameReadORC {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName("CreateDataFrameReadORC")
.master("local[*]")
.getOrCreate()
val df: DataFrame = spark.read.orc("data/outOrc")
df.show()
}
}
package cn.doit.spark.sql01
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object CreateDataFrameWriteORC {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName("CreateDataFrameWriteORC")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/tb_stu")
val rowRdd: RDD[Row] = rdd1.map(e => {
val fields = e.split("\\s+")
Row(fields(0), fields(1), fields(2).toInt)
})
//创建schema
val schema: StructType = StructType(
Array(
StructField("name", StringType),
StructField("subject", StringType),
StructField("scores", IntegerType)
)
)
//关联
val df: DataFrame = spark.createDataFrame(rowRdd, schema)
df.write.orc("data/outOrc")
df.show()
}
}
Dataset的Encoder
package cn.doit.spark.sql02.Encoder
import org.apache.spark.sql.catalyst.encoders.{ExpressionEncoder, RowEncoder}
import org.apache.spark.sql.types.{DoubleType, IntegerType, StringType, StructType}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object EncoderTest {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
// val lines: RDD[String] = spark.sparkContext.textFile("data/user.txt")
val lines = spark.read.textFile("data/user.txt")
val schema = new StructType()
.add("name", StringType)
.add("age", IntegerType)
.add("fv", DoubleType)
//如果要对Dataset别的类型进行操作,需要导入一个Encoder,基本类型有自己的Encoder,只需要导包隐式转换就可以
//Encoder中需要传入数据类型,一定有schema和序列化反序列化方式,还带有执行计划
implicit val rowEncoder: ExpressionEncoder[Row] = RowEncoder(schema)
//import spark.implicits._
//可以后面直接跟Encoder或者创建Encoder的时候变成柯里化方法
val rowDf: Dataset[Row] = lines.map(e => {
val fields = e.split(",")
val f1 = fields(0)
val f2 = fields(1).toInt
val f3 = fields(2).toDouble
Row(f1, f2, f3)
})//(rowEncoder)
rowDf.show()
}
}