【综述】半监督语义分割
转载:2023最新半监督语义分割综述 | 技术总结与展望! (qq.com)

Title: A Survey on Semi-Supervised Semantic Segmentation
Paper: https://arxiv.org/pdf/2302.09899.pdf
导读

语义分割与实例分割结果对比
图像分割是最古老、研究最广泛的计算机视觉 (CV) 问题之一。图像分割是指将图像划分为不同的非重叠区域,并将相应的标签分配给图像中的每个像素,最终获得ROI区域位置及其类别信息。一般,我们将分割任务分为语义分割和实例分割,前者是将每个像素与相应的语义类别进行分类,从而为属于该类别的所有对象或图像区域赋予相同的类别标签;后者则更进一步,试图区分出同一类别的不同实例(如上图所示)。本文主要围绕语义分割进行展开介绍。
总所周知,传统图像分割方法(如阈值法、聚类法)能有效应对固定场景,但对复杂多变的场景缺乏鲁棒性。随着深度学习方法的出现,分割性能有了质的提升,处理复杂场景变得游刃有余。然而,深度学习方法需要大量的数据与标记,尤其是像素级别的标记,这需要耗费巨大的人力和时间成本。因此,基于半监督学习的方法深得科研与从业者喜爱。
这些半监督方法以有监督的方式从标记数据中提取知识,并以无监督的方式从无标记数据中提取知识,从而减少了全监督场景中所需的标记工作,并获得了比无监督场景更好的结果。
本文主要贡献总结如下:
-
我们提供了半监督语义分割方法的新分类及其描述。
-
我们对文献中使用最广泛的数据集进行了一系列最先进的半监督分割方法的实验。
-
对取得的结果、当前方法的优点和缺点、挑战和该领域未来的工作路线进行讨论。
半监督语义分割方法
分类

半监督语义分割方法分类树状图
根据半监督语义分割文献中现有方法的主要特征,我们将方法分为五类,如上图所示。此外,下面的表格列出了更详细的方法划分。

半监督语义分割方法分类
第一类为类似 GAN 结构和在两个网络之间进行对抗性训练的方法,一个作为生成器,另一个作为鉴别器。
第二类为一致性正则化方法。 这些方法在损失函数中包含一个正则化项,以最小化同一图像的不同预测之间的差异,这些差异是通过对图像或相关模型应用扰动获得的。
第三类为伪标记方法。一般而言,这些方法依赖于先前对未标记数据所做的预测,以及在标记数据上训练的模型以获得伪标签。
第四类为基于对比学习的方法。 这种学习范式将相似元素分组,并将它们与特定表示空间中的不同元素分开。
最后一类为混合方法,即将一致性正则化、伪标记和对比学习等方法组合构成。
对抗学习方法
生成对抗网络 (GAN)已经成为一个非常流行的框架,因为它们在图像生成、目标检测或语义分割等众多任务中展示了良好的性能。一个典型的 GAN 框架由两个网络组成,分别为生成器和鉴别器。 生成器的目的是学习目标数据的分布,从而允许从随机噪声中生成合成图像。鉴别器的目的是区分真实图像(属于真实分布)和假图像(由生成器生成)。 这些网络的训练过程以对抗方式进行。 生成器试图混淆鉴别器,生成与目标分布越来越相似的图像,而鉴别器则试图增加其区分真假图像的能力。 这个对抗训练过程正式定义如下:

等式 1 为求解鉴别器 D 和生成器 G 的最小最大值。公式第一项的目的是最大化 D 获得的准确性,而第二项试图提高 G 生成的图像的质量。
基于半监督语义分割的对抗训练方法存在两个子类。区分这些方法的关键方面是在训练过程中包含或不包含生成模型。下面我们将详细介绍这两种类别中的不同方法。
包含生成器的对抗方法

基于生成对抗方法的半监督语义分割框架图
N. Souly等人于2017提出了一种基于GAN的半监督语义分割框架[1]。该框架一方面旨在从大量未标记数据中处理和提取知识,另一方面旨在通过图像的合成生成来增加可用的训练示例数量。具体来说,该方法包括一个生成网络来近似目标图像的分布,从而实现生成新训练样例的能力。分割网络承担鉴别器的角色,并将真实标记和合成标记作为输入的图像,如上图所示。用于优化(L_G)的损失函数和作为判别器(L_D)的损失公式定义如下:

鉴别器损失函数 L_D(等式 2)由三项组成。当模型将真实样本标记为假样本时,第一项会对模型进行惩罚。当模型将假样本标记为真实样本时,第二项会对模型进行惩罚。最后一项是负责监督项,它试图强制将标记集的每个像素正确分类到其对应的类别中。γ 是训练过程中监督项的权重。此外,生成器损失函数 L_G(等式 3)试图通过在 f_θ 检测到合成图像时惩罚 G 来提高生成图像的质量。
不包含生成器的对抗方法

不包括生成器的对抗学习网络框架
另一方面,我们将那些使用对抗训练且具有与 GAN 相似结构但不包括生成模型的方法归为一类。我们在这个子类别下分组的所有方法都具有用分割网络代替经典 GAN 的特征。它的输出指向一个区分真实分割图和由分割网络生成的分割图的鉴别器。
这种类似 GAN 的语义分割架构最初是在该网络[2] 中提出的。作者提出了一个全卷积鉴别器,其接收两个分割图(一个来自标记,另一个由分割模型预测获得)。通过将判别网络与分割模型一起进行对抗训练,最终网络能够区分出真实标签图和预测图。通过这种方式,这个置信度图表明了某个区域的分割质量,因此在训练过程中,可以使用高置信度的预测图来代替标记。这种网络结构如上图所示。这些方法中涉及的损失函数的公式如下所示:
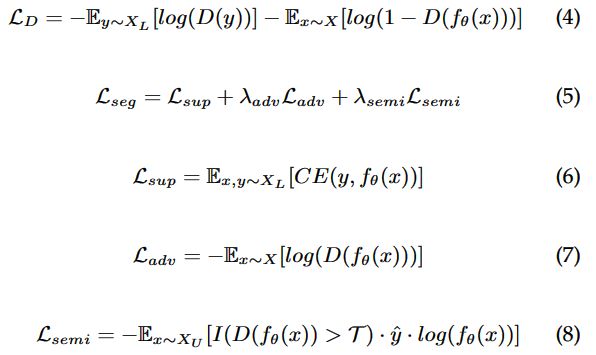

基于此,S4GAN[3] 使用一种更简单的鉴别器,该鉴别器不再预测每个像素而是整体分割区域。此外,它还使用了一个额外的处理分支用于训练分类器。对抗网络[4]方法还结合了图像级鉴别器,并通过添加方差正则化项来改进生成器损失函数。还有一些方法[5]提出使用两个鉴别器,一个在图像级别,另一个在像素级别,两者一起使用以提高图像中置信区域定义的准确性。
纠错监督(ECS)[6] 和引导协作训练(GCT)[7] 均是基于协作策略,这是一种与原始对抗策略非常相似的策略。这些方法引入了一个新的网络来承担鉴别器的角色,在 ECS 的情况下称为校正网络,在 GCT 的情况下称为缺陷检测器。除了像素级别的置信度图之外,这些方法还提供对置信度低的那些区域的校正。
其他对抗性方法将注意力模块与建模远程语义依赖关系的目标结合起来。 该网络[8]就是这种情况,它还结合了频谱归一化以减少训练过程中的不稳定性。 另一种方法[9] 提出将注意力模块与稀疏表示模块结合使用,能够增强模型对目标位置与边缘信息的感知。
一致性正则化

Mean Teacher网络框架
一致性正则化方法基于平滑度假设[10],即对于输入空间中附近的两个点,它们的标签必须相同。从这个意义上说,基于一致性正则化的半监督学习方法通过对未标记数据应用扰动来利用它们,并训练不受这些扰动影响的模型。这是通过向损失函数添加正则化项来实现的,该损失函数测量原始预测和扰动预测之间的距离:


这些方法均是基于Mean Teacher[11],其核心思想是强制学生网络和教师网络的预测一致性。教师网络的权重是通过学生网络权重的指数移动平均值 (EMA) 计算得出的,网络结构如上图所示。
基于半监督语义分割的一致性正则化方法之间的主要区别为:扰动合并数据的方式。基于此,我们可以将这些方法分为四种类别。第一种,基于输入扰动的方法。这些方法使用数据增强技术将扰动直接应用于输入图像。他们强制模型为原始图像和增强图像预测相同的标签。 第二种,基于特征扰动的方法,将扰动内部纳入分割网络,从而获得修改后的特征。 第三种,基于网络扰动的方法,它通过使用不同的网络获得扰动预测,例如具有不同起始权重的网络。 最后一种结合了前面三种类型的扰动。
数据扰动

基于数据扰动的一致性正则化方法框架
首先,我们对那些使用数据增强技术将扰动直接应用在未标记的输入图像的一致性正则化方法进行分组。然后,这些方法训练一个对这些输入扰动不敏感的分割模型,并预测原始图像及其增强版本尽可能相似的分割图。区分这些方法的关键方面是它们对数据进行修改的方式。我们可以在文献中找到已应用于半监督语义分割问题的数据增强技术的不同方式。这些基于数据增强的方法中包含的一致性术语定义如下:


该方法[12]将 CutOut 和 CutMix 技术应用到了半监督语义分割。关键思路如下,首先 CutOut 在训练过程中丢弃了 mask 标记的矩形部分。然后,原始图像和修改图像的预测之间的一致性由正则化项强制执行。 另一方面,CutMix使用矩形mask将两幅图像合并,得到一幅新图像,其中mask标记的部分属于其中一张原始图像,其余部分属于另一张图像。另一种方法[13] 通过向损失函数添加一个新项来扩展以前的方法,称为一致性结构损失,它结合了结构化知识蒸馏[14]的概念。
ClassMix[15] 是专门针对语义分割问题进行设计的。此技术与以前的 CutMix 技术的不同之处在于应用于混合图像的蒙版形式。在这种情况下,掩模标记的部分与图像中属于同一类的区域重合,因此完全属于一个类的部分被复制到另一幅图像中,从而生成新的增强图像。原始预测和增强预测之间的差异的计算方式与先前使用正则化项的技术相同。进一步地,ComplexMix[16]提出结合使用以前的数据增强技术 CutMix 和 ClassMix。
除了提出用于分割的特定数据增强技术外,其他方法[17] 使用经典的数据增强技术(例如裁剪、颜色抖动或翻转)来获得原始图像的扰动版本。
特征扰动

基于特征扰动的一致性正则化方法框架
在训练过程中引入扰动的第二种方法是扰动分割网络的内部特征。交叉一致性训练(CCT)[18]被提出用于解决遵循该思想的半监督语义分割问题,其网络结构扩展了具有编码器-解码器结构(例如 DeepLabV3+)和一些辅助解码器的监督分割模型。首先,使用主解码器对可用的标记数据进行监督训练。接着,为了利用未标记的数据,对编码器的输出进行不同方式的扰动,得到相同特征的不同版本,这些版本被定向到不同的辅助解码器。最后,辅助解码器的输出之间的一致性得到加强,有利于对编码器输出特征的不同扰动版本进行类似的预测。
这些基于特征扰动的方法中包含的一致性项定义如下:

其中h是主解码器,h_k是第k个辅助解码器,K是辅助解码器的数量。
网络扰动

基于网络扰动的一致性正则化方法框架
在训练过程中引入扰动的另一种方法是使用不同的分割网络,网络之间的差异构成了结果预测中的扰动。交叉伪监督 (CPS)[19]遵循类似于 Mean Teacher 的训练过程,但两个网络的训练以并行和独立的方式进行,而不是根据另一个网络的 EMA 更新一个网络。此外,尽管两个网络共享相同的体系结构,但它们使用不同的随机权重进行初始化,从而增加了它们之间的差异。 在该方法[20]中可以看到训练过程包括三个网络的上述方法的扩展。另一种方法[21]强调跨网络实施多样性的重要性,并提出使用对抗性样本和重采样策略来训练不同集合上的模型。
与其他一致性正则化方法一样,未标记图像所涉及的网络预测之间的一致性由损失函数中包含的正则化项强制执行。 该正则化项定义如下(针对使用两个网络的情况):

其中 f_θ 和 g_φ 是独立训练的不同网络。
联合扰动
最后介绍的是上述几种不同类型扰动的联合方法。
该方法[22] 提出了一种提出输入、特征和网络扰动组合的方法。这种方法强调了如果预测不够准确,更多种类和强度的扰动可能会导致更多问题。从这个意义上说,为了确保对未标记图像的准确预测,该方法通过添加置信度加权交叉熵损失函数来扩展 Mean Teacher 方法,而不是经典 Mean Teacher 方法使用的均方误差 (MSE)。 此外,它还提出了一种通过虚拟对抗训练[23]进行特征扰动的新方法。
该方法[24]提出了输入扰动的组合,特别是 CutMix 技术和特征扰动。与在 CCT 中添加不同的辅助解码器不同,该方法提出直接在特征上应用扰动。
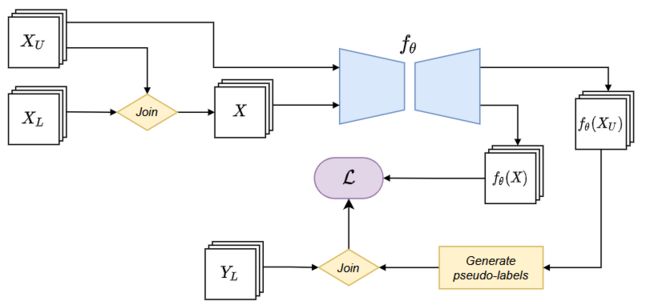
伪标记方法
伪标记方法是最广为人知的方法之一,也是最早出现的半监督方法[25]。伪标记方法背后的思想很简单:根据先前在标记数据上训练的模型所做的预测,生成未标记图像的伪标签。然后,使用这些新的图像和伪标签对扩展标记数据集,并在这个新数据集上训练新模型。伪标记方法的损失函数如下:
![]()
其中 y^ 是图像x 的伪标签,由分割模型f_θ 的预测概率生成,通常是由单热编码生成的,λ 是对损失函数的无监督部分进行加权的参数。
基于训练过程中涉及的模型之间的差异和伪标签的生成方式,本文区分了两种类型的伪标签方法。第一种是自训练方法,仅基于一个监督基础模型并代表最简单的伪标签形式,其中伪标签是从它们自己生成的的高置信度预测。 第二种是互训练方法,它涉及多个具有明显差异的模型,例如不同的初始化权重或在数据集的不同视图上进行训练。每个模型都使用未标记的图像和过程中涉及的其他模型生成的相应伪标签进行再训练。
自训练
基于自训练的伪标记方法框架
自训练方法是最简单的伪标记和半监督方法,首先在该方法[26]中提出,在该综述[27]中进行了详细描述,并在该方法[28] 中首次应用于深度神经网络。这些方法包括通过用自己的预测反馈训练集来重新训练基础监督模型。典型的自训练过程包括以下步骤:
1. 监督模型在可用的标记数据上进行训练。
2. 使用先前训练的模型从未标记的数据中获得预测。那些置信度高于预定义阈值的预测成为未标记数据的伪标签,并包含在标记数据集中。
3. 使用由标记数据和伪标记数据组成的新数据集对监督模型进行再训练。
可以迭代方式重复此过程,使用步骤 3 产生的模型获得新的伪标签,在每次迭代中改进伪标签的质量,直到没有预测超过需要处理的置信度阈值作为伪标签。
下面将介绍基于自训练的半监督语义分割方法,它们中的每一个都为提高学习能力的原始算法贡献了一些变体。 例如,该方法[29] 提出的方法使用质心采样技术扩展了原始的自训练过程,目的是解决伪标签中类不平衡的问题。
还有一些方法在自训练过程中添加一些辅助网络。例如,在 该方法[30] 中,作者通过添加残差网络来扩展自训练过程。该网络使用标记图像进行训练,随后用于细化分割模型获得的伪标签。 模型预测的伪标签可能与真实标签空间有很大不同。 在训练具有两个标签输入的模型时,这可能是一个问题,因为它可能导致不同的梯度方向,从而导致混乱的反向传播过程。 该方法[31] 中提括使用共享编码器(即 ResNet101)并合并两个不同解码器的分割模型,每个解码器对应一个标签空间。
在不同的方法中也提出了在自我训练过程中集成数据增强技术。 ST++[32] 在自训练过程中对未标记图像应用数据增强技术。这与一个选择阶段相结合,在这个阶段,在自训练过程的每次迭代中,那些具有可靠伪标签的图像被优先考虑,而那些在伪标签中出现错误的概率更高的图像被丢弃。
然而,数据增强的应用可能会改变批量归一化中均值和方差的分布。 为了解决这个问题,该方法[33] 提出了使用特定于分布的批量归一化。此外,该方法还集成了一个自校正损失函数,该函数基于置信度执行动态重新加权,以避免过度拟合嘈杂的标签和最困难的类别的学习不足。
这类方法面临的一个常见问题是真实标签和伪标签之间的分布不匹配,其中后者通常偏向于多数类。为了获得无偏伪标签,改方法[34]提出了一种分布对齐和随机抽样的策略,并结合了数据增强技术。
另一项提案侧重于在自我训练过程中使用的实际标记数据和伪标记数据之间定义最佳比例的困难。 从这个意义上讲,提出了两种策略来在迭代再训练过程中接近该最优值,其中一种基于随机搜索(RIST),另一种采用贪心算法(GIST)[35]。
互训练

基于互训练的伪标记方法框架
先前描述的自我训练方法的主要缺点之一是缺乏检测自身错误的机制。 互学习[36]方法不是从自己的预测中学习,而是扩展自我训练方法并涉及多个学习模型,每个模型都使用其他模型生成的伪标签进行训练。参与模型之间存在的多样性是此类方法正确执行的关键[37]。 这就是为什么不同的现有方法试图在构成协同训练方法的基础监督模型之间明确地引起差异,例如,通过使用不同的预训练权重初始化此类模型或通过使用不同的视图训练每个模型或训练集的子集。在其他研究中,类似的方法被归类为基于分歧的策略[38],因为它们主要依赖于利用所涉及模型、多视图训练[39] 或协同训练[40] 之间的预测差异。
动态相互训练 (DMT) 是一种适用于半监督场景和语义分割问题的互学习方法,旨在利用模型之间的分歧来检测生成的伪标签中的错误。该方法通过损失函数将这些差异考虑在内,该损失函数在训练期间根据两个不同模型之间的差异动态重新加权,这些模型是使用另一个模型生成的伪标签独立训练的。因此,特定像素中的差异越大表示错误的概率越大,因此它在损失函数中的权重较低,并且与图像中存在差异的其他像素或区域相比,对训练的影响较小。
另一种方法是用伪标签增强策略扩展以前的方法 (DMT)[41]。为了在整个训练过程中保持所获得的知识,并避免模型对最后学习的类产生偏见,作者提出了一种策略,该策略考虑了先前阶段生成的伪标签来改进当前的伪标签。
对比学习
对比学习侧重于高级特征,使得网络在没有真实标记的情况下能够很好地区分类别。换句话说,这些类型的方法将相似的样本分组,并将它们从特征空间中的不同样本中移除。在许多对比学习方法中,要比较的目标样本称为query,而相似和不相似的样本分别称为positive和negative keys。 由于数据中缺少注释,在训练过程中被认为相似的样本是同一样本的增强版本,而其余数据被认为是不同的样本。 具体来说,在最相关的对比方法中,通常以不同的方式获得成对的增强图像。 其中一些应用数据增强技术(例如裁剪、颜色抖动或翻转),如 SimCLR 方法[42]。 其他方法将图像划分为不同的重叠子块,并像 CPC 方法一样将这些块视为独立图像[43]。
由于这类方法的成功,甚至在某些特定问题上优于其监督方法,近年来提出了一系列专门为语义分割设计的对比学习方法。ReCo[44]是语义分割领域的第一个基于对比学习的方法之一。 该方法包括在分割模型编码器之上链接一个辅助解码器,该解码器将输入特征映射到更高维的表示空间,其中执行查询和键的采样。通过所提出的对比损失函数,查询被强制靠近表示空间中的正键,并远离负键。由于使用高维图像的所有像素来计算对比损失函数是不切实际的,因此 ReCo 方法结合了一种主动采样策略,该策略对图像中的总像素进行采样不到 5%。 一方面,这种方法使那些通常与查询类混淆的类的像素被选为关键负值的概率更高。 另一方面,它依赖于预测置信度来选择那些对于分割模型来说更难分类的像素作为查询像素。
为半监督语义分割提出的另一种对比学习方法是基于纯正对比学习[45],其仅对正键进行采样。该方法的关键元素是创建和动态更新包含标记集中样本子集的记忆体。选择预测置信度较高的样本进行存储。 随后,对比损失函数确保样本的特征接近存储在内存库中的同类样本的特征。
混合方法
本章最后要介绍是前几类方法的集成方法。该种方法尝试同时利用伪标记和一致性正则化方法的优势来优化模型。例如,该方法[46]提出了一个三阶段自训练框架,中间阶段是一致性正则化。具体来说,在自训练过程中集成了一个多任务模型,它使用一致性正则化(任务 1)在分割问题上进行训练,并将统计信息从伪标签引入优化过程(任务 2)。
同样地,自适应均衡学习(AEL)[47]也结合了一致性正则化和伪标记方法的特点。 AEL 方法基于 FixMatch[48],这是一种广泛使用的混合方法,最初是为图像分类提出的。在分割问题中,模型在某些类中表现不佳是很常见的,这主要是由于它们相对于其余类的难度或负不平衡。为此,该方法提出了一个置信度bank,可以在训练期间动态存储每个类别的表现。 数据增强技术和自适应均衡采样被用来支持对那些弱势群体的训练。
Pseudo-Seg[49]还集成了一致性正则化和伪标记方法的特点。作者强调了一个事实,即获取伪标签的常用方法(从经过训练的分割模型的输出和应用置信度阈值)可能会失败并导致低质量的伪标签。 为了解决这个问题,提出了一种专注于执行伪标签的结构化和质量设计的方法。 该方法从两个不同的来源生成伪标签:一方面是分割模型的输出,另一方面是类激活图算法的输出[50]。与寻求获得密集和准确预测的分割任务不同,类激活算法只需要预测较粗粒度的输出。
半监督分割方法的一个关键瓶颈可能是在训练期间分别处理标记和未标记数据。这是混合 GuidedMix-Net [51]提出的问题并给出了改善方案:通过标记和未标记图像对之间的插值来实现捕获两者之间的交互。
最近,对将一致性正则化与对比学习相结合的方法也相当热门。定向上下文感知(DCA)[52]指出了在半监督环境中模拟难以拟合,其中给定对象的上下文仅限于标记图像的缩减集中。这可能会导致分割模型过于重视这些特定的上下文,而没有关注要分割的对象的一些重要特征。为了解决这个问题,DCA 方法结合了一种新的数据增强技术,可以对具有重叠区域的同一图像进行两次切割。 通过这种方式,它模拟了该区域的两个不同上下文,并通过对比损失函数强制执行两个切片之间的一致性。
该方法[53] 尝试实现相同的两个属性:预测空间的一致性和特征空间的对比。一方面,他们使用 l2 损失在未标记图像的两个增强版本的预测之间加强一致性。 另一方面,他们通过对比损失函数整合对比学习,使特征空间中的正(相似)对更近,负(不同)对更远。此外,C3-SemiSeg[54]不但利用了一致性正则化和对比学习的方法,并且还集成了跨集(cross-set)对比学习以提高特征表示能力。
该方法[55]提出了一种方法将基于跨教师培训 (CCT) 的一致性正则化框架与两个互补的对比学习模块相结合。CCT 框架减少了教师和学生网络之间的错误积累,而对比学习模块促进了特征空间中的类分离。该方法[56]提出了一种试图保持图像上下文的数据增强技术。此外,还提出了一种新的对抗性双学生框架,以提高经典 Mean Teacher 的性能。
实验

标记与未标记数据比例
PASCAL VOC 2012数据集有三种标记规模:1/100、1/50、1/20以及1/8;Cityscapes数据集仅有一种:1/8。

在PASCAL VOC分割任务上的分割性能对比
在标记/未标记比例为1/100、1/50和1/20的配置下,DMT均获得了最高的精度,比次优方法平均高出1~3%。在比例为1/8配置下获得了第二高精度,比最高精度仅低了0.5%。

在Cityscapes数据集上的分割结果可视化对比(1)

在Cityscapes数据集上的分割结果可视化对比(2)
可以清晰地观察到,DMT的分割结果更接近真实标记。相比两外两种方法,DMT分割的目标区域更加完整,目标区域之间的边界把握得更准确。
挑战以及展望
评估标准:我们在半监督语义分割文献中发现的不同研究没有提出相同的实验框架(即使用不同的数据集、不同的数据分区、不同的实现等)。提出一个所有研究人员都可以采用的标准和现实的实验和评估框架将是该研究领域发展的关键点。
具有改进潜力的方法族:我们强调了两个在未来研究中可能具有更大潜力的类别。首先,我们强调了伪标记方法,特别是互训练的子类别,它在我们的实验分析中取得了最好的结果。 然而,这个子类别中只存在两个半监督分割方法,因此我们认为它有很大的改进和发展余地。此外,我们还将混合方法视为未来研究的一个非常有前景的类别,因为它们具有新颖性和不同组合的可能性。
基本模型的多样性:许多方法都采用了多个基础模型,这些模型的多样性可能是获得良好最终模型的关键因素。然而,这些方法通常仅限于选择最先进的监督分割模型获得了一组多样性差的模型,并且没有尝试更深入地研究这个决定。未来可能的研究方向可以侧重于研究模型间多样性对半监督分割方法最终结果的影响。
评估更现实的场景:在全监督和半监督分割问题中使用最广泛的一些数据集是以目标为中心的图像数据集(例如,PASCAL VOC 2012)。这种类型的图像代表了一个非常受控的场景,与现实世界中的场景差异较大。这可能会导致模型在此类数据集中获得良好结果,但在实际应用中可能没有用。新出现的数据集(例如,Cityscapes)呈现出较少受控的图像和类之间更多的语义依赖。这些类型的数据集需要新的方法来处理控制较少的图像和建模类之间的语义依赖。
新趋势:Transformers[57]是一种特定类型的网络架构,最初是为自然语言处理问题而提出的,其编码理念与 CNN 有很大差异。 最近,这些模型开始应用于 CV 问题。这些模型可以学习类之间的语义关系,甚至是在图像中彼此相距很远的类之间的语义关系。这在此类关系丰富的真实情况下是可取的。 尽管transformers最近开始应用于有监督的语义分割并取得了令人满意的结果,但只有少数方法试图将它们引入半监督学习场景。 因此,这种新方法在半监督语义分割中的应用可以被认为是未来最有前途的研究方向之一。
总结
本文旨在围绕半监督分割方法构建,并提出挑战和未来的研究趋势。
本文的主要贡献之一是新的分类方式,它将所有以前的工作(总共 43 个最近发表的与该领域相关的方法)分为五类:对抗性方法、一致性正则化、伪标记、约束 学习和混合方法。 通过这种方式,我们为读者提供了一种快速准确的方式来了解该领域的最新技术,以及对每种现有方法的详细描述。
对最新技术和定义的分类法的分析得到了一项实验研究的补充,该实验研究比较了同质实验条件下的所有不同类别的方法(使用该领域两个最常见的数据集:PASCAL VOC 2012 和 Cityscapes)。 这使读者对它们每个的性能有一个直觉。 该实验由 10 种方法组成,我们将属于互训练类别(即 DMT)的方法总结为提供最佳性能的方法。
最后,我们反思了半监督分割的当前挑战和潜在的未来研究方向,强调了实验和评估框架标准化的必要性、使用复杂场景图像且语义丰富的现实基准的便利性与类之间的依赖关系,以及最近应用于 CV的视觉transformer在半监督场景中的巨大潜力。
References
[1]Semi supervised semantic segmentation using generative adversarial network: .
[2]Semantic segmentation using adversarial networks: .
[3]“Semi-supervised semantic segmentation with high- and low-level consistency: .
[4]Semi-supervised semantic segmentation based on confrontation network: .
[5]Semi-supervised semantic image segmentation using dual discriminator adversarial networks: .
[6]Semi-supervised segmentation based on errorcorrecting supervision: .
[7]Guided collaborative training for pixel-wise semi-supervised learning: .
[8]Stable selfattention adversarial learning for semi-supervised semantic image segmentation: .
[9]Semi-supervised semantic segmentation using an improved generative adversarial network: .
[10]Semi-supervised learning: .
[11]Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results: .
[12]Semi-supervised semantic segmentation needs strong varied perturbations: .
[13]Structured consistency loss for semi-supervised semantic segmentation,: .
[14]“Structured knowledge distillation for semantic segmentation,: .
[15]Classmix: Segmentation-based data augmentation for semi-supervised learning,: .
[16]Complexmix:Semi-supervised semantic segmentation via mask-based data augmentation,: .
[17]Semi-supervised semantic segmentation constrained by consistency regularization,: .
[18]emi-supervised semantic segmentation with cross-consistency training: .
[19]Semi-supervised semantic segmentation with cross pseudo supervision,: .
[20]Deep tri-training for semi-supervised image segmentation,: .
[21]Deep co-training for semi-supervised image segmentation: .
[22]Perturbed and strict mean teachers for semi-supervised semantic segmentation,: .
[23]Virtual adversarial training: A regularization method for supervised and semi-supervised learning,: .
[24]Perturbation consistency and mutual information regularization for semi-supervised semantic segmentation: .
[25]Semi-supervised learning literature survey: .
[26]Unsupervised word sense disambiguation rivaling supervised methods,: .
[27]Self-labeled techniques for semi-supervised learning: taxonomy, software and empirical study,: .
[28]Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks: .
[29]Improving semantic segmentation via efficient self-training,: .
[30]A residual correction approach for semi-supervised semantic segmentation: .
[31]Digging into pseudo label: a low-budget approach for semi-supervised semantic segmentation: .
[32]t++: Make self-training work better for semi-supervised semantic segmentation: .
[33]A simple baseline for semi-supervised semantic segmentation with strong data augmentation: .
[34]Re-distributing biased pseudo labels for semi-supervised semantic segmentation: A baseline investigation: .
[35]The gist and rist of iterati e self-training for semi-supervised segmentation: .
[36]Deep mutual learning,: .
[37]A new analysis of co-training: .
[38]A survey on deep semi-supervised learning: .
[39]An overview of deep semi-supervised learning: .
[40]A survey on semi-supervised learning: .
[41]“Pseudoseg: Designing pseudo labels for semantic segmentation: .
[42]A simple framework for contrastive learning of visual representations: .
[43]epresentation learning with contrastive predictive coding: .
[44]Bootstrapping semantic segmentation with regional contrast: .
[45]Exploring simple siamese representation learning: .
[46]A three-stage self-training framework for semi-supervised semantic segmentation,: .
[47]Semi-supervised semantic segmentation via adaptive equalization learning: .
[48]“Fixmatch: Simplifying semi-supervised learning with consistency and confidence: .
[49]Pseudoseg: Designing pseudo labels for semantic segmentation: .
[50]Grad-cam: Visual explanations from deep networks via gradient-based localization: .
[51]Guidedmix-net: Learning to improve pseudo masks using labeled images as reference,: .
[52]Semi-supervised semantic segmentation with directional context-aware consistency: .
[53]Pixel contrastive-consistent semi-supervised semantic segmentation,: .
[54]C3-semiseg: Contrastive semi-supervised segmentation via cross-set learning and dynamic class-balancing: .
[55]Semi-supervised semantic segmentation with cross teacher training: .
[56]Adversarial dual-student with differentiable spatial warping for semi-supervised semantic segmentation: .
[57]An image is worth 16 x16 words: Transformers for image recognition at scale: .