猫狗分类下引用原生vit对比rensnet50
VIT(Visual Transformer)原生对比rensnet50在猫狗分类中acc提升明显(3090显卡训练)
!pip -q install vit_pytorch linformer
导入环境包
from __future__ import print_function
import glob
from itertools import chain
import os
import random
import zipfile
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from linformer import Linformer
from PIL import Image
from sklearn.model_selection import train_test_split
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets, transforms
from tqdm.notebook import tqdm
#from vit_pytorch.efficient import ViT
from vit_pytorch import ViT
print(f"Torch: {torch.__version__}")
device = torch.device('cuda:0') # 显卡序号信息
GPU_device = torch.cuda.get_device_properties(device) # 显卡信息
print(f"VIT vs rensnet50 torch {torch.__version__} device {device} ({GPU_device.name}, {GPU_device.total_memory / 1024 ** 2}MB)\n")
Torch: 1.12.1+cu116
VIT vs rensnet50 torch 1.12.1+cu116 device cuda:0 (NVIDIA GeForce RTX 3090, 24575.5MB)
# Training settings
batch_size = 64
epochs = 20
lr = 3e-5
gamma = 0.7
seed = 42
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
seed_everything(seed)
device = 'cuda'
读取数据(下载地址)
下载地址:
https://download.csdn.net/download/qq_37401291/87391094
百度下载
链接:https://pan.baidu.com/s/1r_Z1B9pw_cKZJU-hjfDaSA
提取码:p7s9
–来自百度网盘超级会员V6的分享
os.makedirs('data', exist_ok=True)
train_dir = 'data/train'
test_dir = 'data/test'
# with zipfile.ZipFile('data/train.zip') as train_zip:
# train_zip.extractall('data')
# with zipfile.ZipFile('data/test.zip') as test_zip:
# test_zip.extractall('data')
train_list = glob.glob(os.path.join(train_dir, '*.jpg'))
test_list = glob.glob(os.path.join(test_dir, '*.jpg'))
print(f"Train Data: {len(train_list)}")
print(f"Test Data: {len(test_list)}")
Train Data: 25000
Test Data: 12500
labels = [path.split('/')[-1].split('\\')[-1].split('.')[0] for path in train_list]
#print(labels)
print(train_list[0])
print(labels[0])
data/train\cat.0.jpg
cat
随机 Plots
random_idx = np.random.randint(1, len(train_list), size=9)
fig, axes = plt.subplots(3, 3, figsize=(16, 12))
for idx, ax in enumerate(axes.ravel()):
img = Image.open(train_list[idx])
ax.set_title(labels[idx])
ax.imshow(img)
划分数据集
train_list, valid_list = train_test_split(train_list,
test_size=0.2,
stratify=labels,
random_state=seed)
print(f"Train Data: {len(train_list)}")
print(f"Validation Data: {len(valid_list)}")
print(f"Test Data: {len(test_list)}")
Train Data: 20000
Validation Data: 5000
Test Data: 12500
图片数据增强
train_transforms = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]
)
val_transforms = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]
)
test_transforms = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]
)
读取数据集
class CatsDogsDataset(Dataset):
def __init__(self, file_list, transform=None):
self.file_list = file_list
self.transform = transform
def __len__(self):
self.filelength = len(self.file_list)
return self.filelength
def __getitem__(self, idx):
img_path = self.file_list[idx]
img = Image.open(img_path)
img_transformed = self.transform(img)
label = img_path.split("/")[-1].split('\\')[-1].split(".")[0]
label = 1 if label == "dog" else 0
return img_transformed, label
train_data = CatsDogsDataset(train_list, transform=train_transforms)
valid_data = CatsDogsDataset(valid_list, transform=test_transforms)
test_data = CatsDogsDataset(test_list, transform=test_transforms)
train_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=True)
print(len(train_data), len(train_loader))
20000 313
print(len(valid_data), len(valid_loader))
5000 79
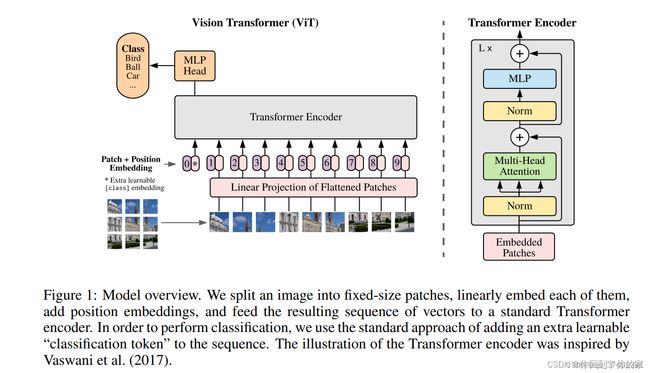
Visual Transformer
# vit_large = ViT(
# image_size = 224,
# patch_size = 16,
# num_classes = 2,
# dim = 768,
# depth = 12,
# heads =12,
# mlp_dim = 3072,
# dropout = 0.1,
# emb_dropout = 0.1
# ).to(device)
# vit_huge = ViT(
# image_size = 224,
# patch_size = 16,
# num_classes = 2,
# dim = 768,
# depth = 12,
# heads =12,
# mlp_dim = 3072,
# dropout = 0.1,
# emb_dropout = 0.1
# ).to(device)
model = ViT(
image_size=224,
patch_size=32,
num_classes=2,
dim=1024,
depth=24,
heads=16,
mlp_dim=4096,
dropout=0.1,
emb_dropout=0.1
).to(device)
#model.load_state_dict(torch.load('vit_base_patch16_224_r.pth'), strict=False)
ResNet 需要可以自己对比训练普遍acc 0.74-0.76
# import torchvision
#
# model = torchvision.models.resnet50(pretrained=False).to(device)
# model.fc = nn.Sequential(
# nn.Linear(2048, 2)
# ).to(device)
E:\Miniconda3\envs\paper\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and will be removed in 0.15, please use 'weights' instead.
warnings.warn(
E:\Miniconda3\envs\paper\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and will be removed in 0.15. The current behavior is equivalent to passing `weights=None`.
warnings.warn(msg)
Training
# # loss function
# criterion = nn.CrossEntropyLoss()
# # optimizer
# optimizer = optim.Adam(model.parameters(), lr=lr)
# # scheduler
# scheduler = StepLR(optimizer, step_size=1, gamma=gamma)
# for epoch in range(epochs):
# epoch_loss = 0
# epoch_accuracy = 0
#
# for data, label in tqdm(train_loader):
# data = data.to(device)
# label = label.to(device)
#
# output = model(data)
# loss = criterion(output, label)
#
# optimizer.zero_grad()
# loss.backward()
# optimizer.step()
#
# acc = (output.argmax(dim=1) == label).float().mean()
# epoch_accuracy += acc / len(train_loader)
# epoch_loss += loss / len(train_loader)
#
# with torch.no_grad():
# epoch_val_accuracy = 0
# epoch_val_loss = 0
# for data, label in valid_loader:
# data = data.to(device)
# label = label.to(device)
#
# val_output = model(data)
# val_loss = criterion(val_output, label)
#
# acc = (val_output.argmax(dim=1) == label).float().mean()
# epoch_val_accuracy += acc / len(valid_loader)
# epoch_val_loss += val_loss / len(valid_loader)
#
# print(
# f"Epoch : {epoch + 1} - loss : {epoch_loss:.4f} - acc: {epoch_accuracy:.4f} - val_loss : {epoch_val_loss:.4f} - val_acc: {epoch_val_accuracy:.4f}\n"
# )
太多了只保留最后的
0%| | 0/313 [00:00swin trans
# --------------------------------------------------------
# Swin Transformer
# Copyright (c) 2021 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ze Liu
# --------------------------------------------------------
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
import logging
import math
from copy import deepcopy
from typing import Optional
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
# 注意版本
# !pip install timm==0.5.4
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.helpers import build_model_with_cfg, overlay_external_default_cfg
from timm.models.layers import PatchEmbed, Mlp, DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import checkpoint_filter_fn, _init_vit_weights
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic', 'fixed_input_size': True,
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
# patch models (my experiments)
'swin_base_patch4_window12_384': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22kto1k.pth',
input_size=(3, 384, 384), crop_pct=1.0),
'swin_base_patch4_window7_224': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22kto1k.pth',
),
'swin_large_patch4_window12_384': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22kto1k.pth',
input_size=(3, 384, 384), crop_pct=1.0),
'swin_large_patch4_window7_224': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window7_224_22kto1k.pth',
),
'swin_small_patch4_window7_224': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth',
),
'swin_tiny_patch4_window7_224': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth',
),
'swin_base_patch4_window12_384_in22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22k.pth',
input_size=(3, 384, 384), crop_pct=1.0, num_classes=21841),
'swin_base_patch4_window7_224_in22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth',
num_classes=21841),
'swin_large_patch4_window12_384_in22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22k.pth',
input_size=(3, 384, 384), crop_pct=1.0, num_classes=21841),
'swin_large_patch4_window7_224_in22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window7_224_22k.pth',
num_classes=21841),
}
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
#print(x.shape)
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 window with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
return flops
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
#print(mask_windows.shape)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, "f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# W-MSA/SW-MSA
nW = H * W / self.window_size / self.window_size
flops += nW * self.attn.flops(self.window_size * self.window_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
return flops
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
def flops(self):
flops = 0
for blk in self.blocks:
flops += blk.flops()
if self.downsample is not None:
flops += self.downsample.flops()
return flops
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[
1], f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
class SwinTransformer(nn.Module):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def flops(self):
flops = 0
flops += self.patch_embed.flops()
for i, layer in enumerate(self.layers):
flops += layer.flops()
flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
flops += self.num_features * self.num_classes
return flops
def _create_swin_transformer(variant, pretrained=False, default_cfg=None, **kwargs):
if default_cfg is None:
default_cfg = deepcopy(default_cfgs[variant])
overlay_external_default_cfg(default_cfg, kwargs)
default_num_classes = default_cfg['num_classes']
default_img_size = default_cfg['input_size'][-2:]
num_classes = kwargs.pop('num_classes', default_num_classes)
img_size = kwargs.pop('img_size', default_img_size)
if kwargs.get('features_only', None):
raise RuntimeError('features_only not implemented for Vision Transformer models.')
model = build_model_with_cfg(
SwinTransformer, variant, pretrained,
default_cfg=default_cfg,
img_size=img_size,
num_classes=num_classes,
pretrained_filter_fn=checkpoint_filter_fn,
**kwargs)
return model
@register_model
def swin_base_patch4_window7_224(pretrained=False, **kwargs):
""" Swin-B @ 224x224, pretrained ImageNet-22k, fine tune 1k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer('swin_base_patch4_window7_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_base_patch4_window12_384(pretrained=False, **kwargs):
""" Swin-B @ 384x384, pretrained ImageNet-22k, fine tune 1k
"""
model_kwargs = dict(
patch_size=4, window_size=12, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer('swin_base_patch4_window12_384', pretrained=pretrained, **model_kwargs)
model = model = swin_base_patch4_window7_224(pretrained=True).to(device)
E:\Miniconda3\envs\paper\lib\site-packages\torch\functional.py:478: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\TensorShape.cpp:2895.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
# loss function
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = optim.Adam(model.parameters(), lr=lr)
# scheduler
scheduler = StepLR(optimizer, step_size=1, gamma=gamma)
for epoch in range(epochs):
epoch_loss = 0
epoch_accuracy = 0
for data, label in tqdm(train_loader):
data = data.to(device)
label = label.to(device)
output = model(data)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = (output.argmax(dim=1) == label).float().mean()
epoch_accuracy += acc / len(train_loader)
epoch_loss += loss / len(train_loader)
with torch.no_grad():
epoch_val_accuracy = 0
epoch_val_loss = 0
for data, label in valid_loader:
data = data.to(device)
label = label.to(device)
val_output = model(data)
val_loss = criterion(val_output, label)
acc = (val_output.argmax(dim=1) == label).float().mean()
epoch_val_accuracy += acc / len(valid_loader)
epoch_val_loss += val_loss / len(valid_loader)
print(
f"Epoch : {epoch + 1} - loss : {epoch_loss:.4f} - acc: {epoch_accuracy:.4f} - val_loss : {epoch_val_loss:.4f} - val_acc: {epoch_val_accuracy:.4f}\n"
)
0%| | 0/313 [00:00